Een professionele gegevensset voor spraaktraining toevoegen
Wanneer u klaar bent om een aangepaste tekst naar spraak te maken voor uw toepassing, is de eerste stap het verzamelen van audio-opnamen en bijbehorende scripts om het spraakmodel te trainen. Zie de zelfstudie voor meer informatie over het opnemen van spraakvoorbeelden. De Speech-service gebruikt deze gegevens om een unieke stem te maken die overeenkomt met de stem in de opnamen. Nadat u de stem hebt getraind, kunt u beginnen met het synthetiseren van spraak in uw toepassingen.
Alle gegevens die u uploadt, moeten voldoen aan de vereisten voor het gegevenstype dat u kiest. Het is belangrijk om uw gegevens correct op te maken voordat ze worden geüpload, zodat de gegevens nauwkeurig worden verwerkt door de Speech-service. Zie Trainingsgegevenstypen om te controleren of uw gegevens correct zijn opgemaakt.
Notitie
- Gebruikers van een Standard-abonnement (S0) kunnen vijf gegevensbestanden tegelijk uploaden. Als u de limiet bereikt, wacht u totdat ten minste één van uw gegevensbestanden is geïmporteerd. Probeer het opnieuw.
- Het maximum aantal gegevensbestanden dat per abonnement mag worden geïmporteerd, is 500 .zip bestanden voor standaardgebruikers van abonnementen (S0). Raadpleeg de quota en limieten van de Speech-service voor meer informatie.
Uw gegevens uploaden
Wanneer u klaar bent om uw gegevens te uploaden, gaat u naar het tabblad Trainingsgegevens voorbereiden om uw eerste trainingsset toe te voegen en gegevens te uploaden. Een trainingsset is een set audio-utterances en de bijbehorende toewijzingsscripts die worden gebruikt voor het trainen van een spraakmodel. U kunt een trainingsset gebruiken om uw trainingsgegevens te organiseren. De service controleert de gereedheid van gegevens per trainingsset. U kunt meerdere gegevens importeren in een trainingsset.
Voer de volgende stappen uit om trainingsgegevens te uploaden:
- Meld u aan bij Speech Studio.
- Selecteer Aangepaste stem> Uw projectnaam> Trainingsgegevens uploaden>voorbereiden.
- Kies een gegevenstype in de wizard Gegevens uploaden en selecteer vervolgens Volgende.
- Selecteer lokale bestanden op uw computer of voer de URL voor Azure Blob Storage in om gegevens te uploaden.
- Selecteer onder De doeltrainingsset opgeven een bestaande trainingsset of maak een nieuwe set. Als u een nieuwe trainingsset hebt gemaakt, controleert u of deze is geselecteerd in de vervolgkeuzelijst voordat u doorgaat.
- Selecteer Volgende.
- Voer een naam en beschrijving in voor uw gegevens en selecteer vervolgens Volgende.
- Controleer de uploadgegevens en selecteer Verzenden.
Notitie
Dubbele id's worden niet geaccepteerd. Uitingen met dezelfde id worden verwijderd.
Dubbele audionamen worden uit de training verwijderd. Zorg ervoor dat de gegevens die u selecteert, niet dezelfde audionamen bevatten in het .zip-bestand of in meerdere .zip-bestanden. Als utterance-id's (in audio- of scriptbestanden) duplicaten zijn, worden deze geweigerd.
Gegevensbestanden worden automatisch gevalideerd wanneer u Verzenden selecteert. Gegevensvalidatie omvat reeks controles op de audiobestanden om de bestandsindeling, grootte en samplingfrequentie te controleren. Als er fouten zijn, herstelt u deze en verzendt u deze opnieuw.
Nadat u de gegevens hebt geüpload, kunt u de details controleren in de detailweergave van de trainingsset. Op de detailpagina kunt u het uitspraakprobleem en het ruisniveau voor elk van uw gegevens verder controleren. De uitspraakscore op zinsniveau varieert van 0-100. Een score onder de 70 geeft normaal gesproken aan dat een spraakfout of script niet overeenkomt. Uitingen met een algehele score lager dan 70 worden geweigerd. Een zwaar accent kan uw uitspraakscore verminderen en de gegenereerde digitale stem beïnvloeden.
Problemen met gegevens online oplossen
Na het uploaden kunt u de gegevensdetails van de trainingsset controleren. Voordat u verdergaat met het trainen van uw spraakmodel, moet u proberen om gegevensproblemen op te lossen.
U kunt gegevensproblemen per uiting identificeren en oplossen in Speech Studio.
Ga op de detailpagina naar de pagina Geaccepteerde gegevens of Geweigerde gegevens . Selecteer afzonderlijke utterances die u wilt wijzigen en selecteer Vervolgens Bewerken.
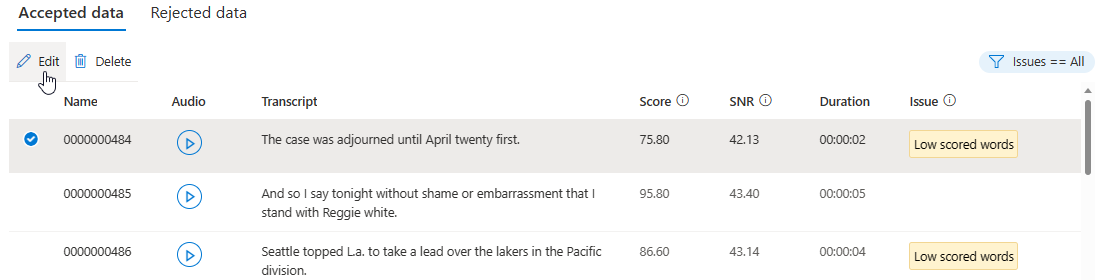
U kunt kiezen welke gegevensproblemen moeten worden weergegeven op basis van uw criteria.
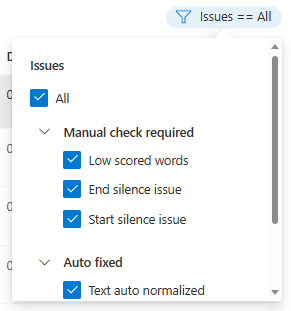
Het venster Bewerken wordt weergegeven.
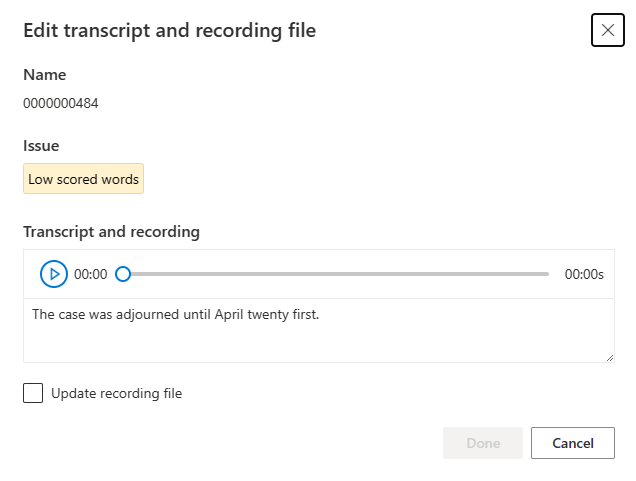
Werk transcriptie of opnamebestand bij volgens de beschrijving van het probleem in het bewerkingsvenster.
U kunt transcriptie bewerken in het tekstvak en vervolgens Gereed selecteren
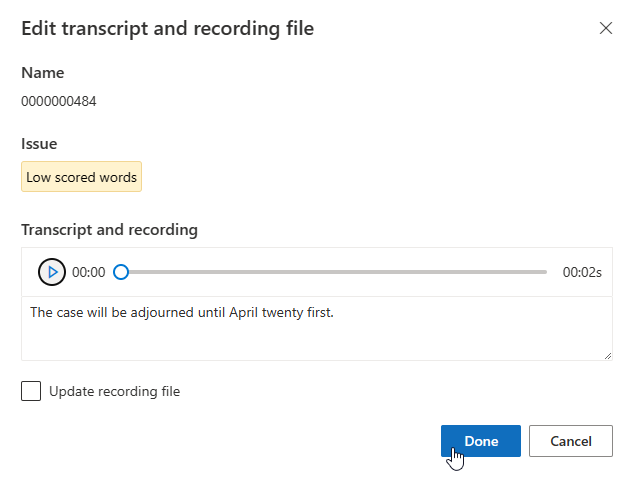
Als u het opnamebestand wilt bijwerken, selecteert u Opnamebestand bijwerken en uploadt u het vaste opnamebestand (.wav).
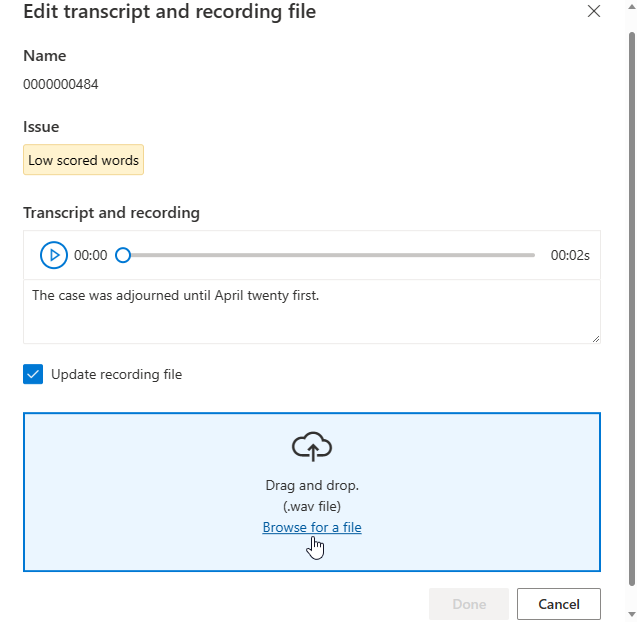
Nadat u wijzigingen hebt aangebracht in uw gegevens, moet u de gegevenskwaliteit controleren door op Gegevens analyseren te klikken voordat u deze gegevensset gebruikt voor training.
U kunt deze trainingsset niet selecteren voor het trainingsmodel voordat de analyse is voltooid.
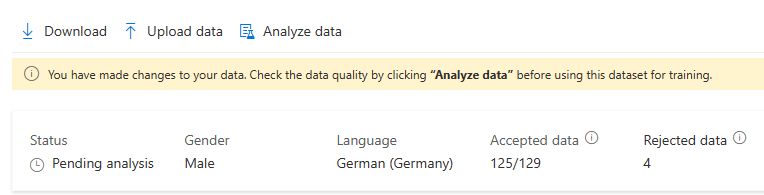
U kunt ook utterances met problemen verwijderen door ze te selecteren en op Verwijderen te klikken.
Veelvoorkomende problemen met gegevens
De problemen zijn onderverdeeld in drie typen. Raadpleeg de volgende tabellen om de respectieve typen fouten te controleren.
Automatisch geweigerd
Gegevens met deze fouten worden niet gebruikt voor training. Geïmporteerde gegevens met fouten worden genegeerd, dus u hoeft ze niet te verwijderen. U kunt deze gegevensfouten online oplossen of de gecorrigeerde gegevens opnieuw uploaden voor training.
| Categorie | Name | Beschrijving |
|---|---|---|
| Script | Ongeldig scheidingsteken | U moet de uitings-id en de scriptinhoud scheiden met een Tab-teken. |
| Script | Ongeldige script-id | De scriptregel-id moet numeriek zijn. |
| Script | Gedupliceerd script | Elke regel van de scriptinhoud moet uniek zijn. De regel wordt gedupliceerd met {}. |
| Script | Script te lang | Het script moet minder dan 1000 tekens bevatten. |
| Script | Geen overeenkomende audio | De id van elke uiting (elke regel van het scriptbestand) moet overeenkomen met de audio-id. |
| Script | Geen geldig script | Er is geen geldig script gevonden in deze gegevensset. Los de scriptregels op die worden weergegeven in de gedetailleerde lijst met problemen. |
| Audio | Geen overeenkomend script | Geen audiobestanden komen overeen met de script-id. De naam van de .wav-bestanden moet overeenkomen met de id's in het scriptbestand. |
| Audio | Ongeldige audio-indeling | De audio-indeling van de .wav-bestanden is ongeldig. Controleer de .wav bestandsindeling met behulp van een audiohulpprogramma zoals SoX. |
| Audio | Lage steekproefsnelheid | De steekproefsnelheid van de .wav bestanden mag niet lager zijn dan 16 KHz. |
| Audio | Te lang geluid | De audioduur is langer dan 30 seconden. Splits de lange audio in meerdere bestanden. Het is een goed idee om uitingen korter te maken dan 15 seconden. |
| Audio | Geen geldig geluid | Er is geen geldig geluid gevonden in deze gegevensset. Controleer uw audiogegevens en upload opnieuw. |
| Wanverhouding | Lage score utterance | Uitspraakscore op zinsniveau is lager dan 70. Controleer het script en de audio-inhoud om ervoor te zorgen dat ze overeenkomen. |
Automatisch opgelost
De volgende fouten worden automatisch opgelost, maar u moet de correcties correct controleren en bevestigen.
| Categorie | Name | Beschrijving |
|---|---|---|
| Wanverhouding | Stilte automatisch opgelost | De stilte van de start is korter dan 100 ms en is automatisch uitgebreid tot 100 ms. Download de genormaliseerde gegevensset en controleer deze. |
| Wanverhouding | Stilte automatisch opgelost | De eindstilte wordt gedetecteerd korter dan 100 ms en is automatisch uitgebreid tot 100 ms. Download de genormaliseerde gegevensset en controleer deze. |
| Script | Automatisch genormaliseerde tekst | Tekst wordt automatisch genormaliseerd voor cijfers, symbolen en afkortingen. Controleer het script en de audio om ervoor te zorgen dat ze overeenkomen. |
Handmatige controle vereist
Niet-opgeloste fouten die in de volgende tabel worden vermeld, zijn van invloed op de kwaliteit van de training, maar gegevens met deze fouten worden niet uitgesloten tijdens de training. Voor hoogwaardige training is het een goed idee om deze fouten handmatig op te lossen.
| Categorie | Name | Beschrijving |
|---|---|---|
| Script | Niet-genormaliseerde tekst | Dit script bevat symbolen. Normaliseer de symbolen zodat deze overeenkomen met de audio. Bijvoorbeeld normaliseren / om te slashen. |
| Script | Onvoldoende vraaguitingen | Ten minste 10 procent van de totale uitingen moet vraagzinnen zijn. Dit helpt het spraakmodel om een vraagtoon goed uit te drukken. |
| Script | Onvoldoende uitroeptekens | Ten minste 10 procent van de totale uitingen moet uitroeptekens zijn. Dit helpt het spraakmodel om een opgewonden toon goed uit te drukken. |
| Script | Geen geldige eindpunctie | Voeg een van de volgende waarden toe aan het einde van de regel: volledige stop (halve breedte '.' of '。 '), uitroepteken (halve breedte '!' of '!' of vraagteken ( halve breedte '?' of volledige breedte '?'). |
| Audio | Lage steekproefsnelheid voor neurale spraak | Het wordt aanbevolen dat de steekproeffrequentie van uw .wav bestanden 24 KHz of hoger moet zijn voor het maken van neurale stemmen. Als het lager is, wordt deze automatisch verhoogd tot 24 KHz. |
| Volume | Algemeen volume te laag | Volume mag niet lager zijn dan -18 dB (10 procent van het maximumvolume). Bepaal het gemiddelde volumeniveau binnen het juiste bereik tijdens de voorbeeldopname of gegevensvoorbereiding. |
| Volume | Volumeoverloop | Overlopend volume wordt gedetecteerd bij {}s. Pas de opnameapparatuur aan om te voorkomen dat het volume overloopt bij de piekwaarde. |
| Volume | Probleem met stilte starten | De eerste 100 ms stilte is niet schoon. Verminder het opnamegeluidsniveau en laat de eerste 100 ms aan het begin stil. |
| Volume | Probleem met stilzwijgen beëindigen | De laatste 100 ms stilte is niet schoon. Verminder het geluidsvloerniveau van de opname en laat de laatste 100 ms aan het einde stil. |
| Wanverhouding | Weinig gescoorde woorden | Controleer het script en de audio-inhoud om er zeker van te zijn dat ze overeenkomen en beheer het niveau van de ruisvloer. Verminder de lengte van lange stilte of splits de audio in meerdere uitingen als deze te lang is. |
| Wanverhouding | Probleem met stilte starten | Er werd voor het eerste woord extra audio gehoord. Controleer het script en de audio-inhoud om ervoor te zorgen dat ze overeenkomen, beheer het niveau van de ruisvloer en maak de eerste 100 ms stil. |
| Wanverhouding | Probleem met stilzwijgen beëindigen | Er is na het laatste woord extra audio gehoord. Controleer het script en de audio-inhoud om ervoor te zorgen dat ze overeenkomen, beheer het niveau van de ruisvloer en maak de laatste 100 ms stil. |
| Wanverhouding | Lage signaalruisverhouding | Audio-SNR-niveau is lager dan 20 dB. Ten minste 35 dB wordt aanbevolen. |
| Wanverhouding | Geen score beschikbaar | Kan spraakinhoud in deze audio niet herkennen. Controleer de audio en de scriptinhoud om te controleren of de audio geldig is en overeenkomt met het script. |
Volgende stappen
U hebt een trainingsgegevensset nodig om een professionele stem te maken. Een trainingsgegevensset bevat audio- en scriptbestanden. De audiobestanden zijn opnamen van het spraaktalent dat de scriptbestanden leest. De scriptbestanden zijn de tekst van de audiobestanden.
In dit artikel maakt u een trainingsset en haalt u de resource-id op. Vervolgens kunt u met behulp van de resource-id een set audio- en scriptbestanden uploaden.
Een trainingsset maken
Als u een trainingsset wilt maken, gebruikt u de TrainingSets_Create bewerking van de aangepaste spraak-API. Bouw de aanvraagbody volgens de volgende instructies:
- Stel de vereiste
projectIdeigenschap in. Zie Een project maken. - Stel de vereiste
voiceKindeigenschap in opMaleofFemale. Het type kan later niet meer worden gewijzigd. - Stel de vereiste
localeeigenschap in. Dit moet de landinstelling van de gegevens van de trainingsset zijn. De landinstelling van de trainingsset moet gelijk zijn aan de landinstelling van de toestemmingsverklaring. De landinstelling kan later niet meer worden gewijzigd. Hier vindt u de lijst met taalinstellingen voor tekst. - Stel desgewenst de
descriptioneigenschap in voor de beschrijving van de trainingsset. De beschrijving van de trainingsset kan later worden gewijzigd.
Maak een HTTP PUT-aanvraag met behulp van de URI, zoals wordt weergegeven in het volgende TrainingSets_Create voorbeeld.
- Vervang door
YourResourceKeyuw Spraak-resourcesleutel. - Vervang door
YourResourceRegionuw spraakresourceregio. - Vervang door
JessicaTrainingSetIdeen trainingsset-id van uw keuze. De hoofdlettergevoelige id wordt gebruikt in de URI van de trainingsset en kan later niet meer worden gewijzigd.
curl -v -X PUT -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"description": "300 sentences Jessica data in general style.",
"projectId": "ProjectId",
"locale": "en-US",
"voiceKind": "Female"
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/trainingsets/JessicaTrainingSetId?api-version=2024-02-01-preview"
U ontvangt een antwoordtekst in de volgende indeling:
{
"id": "JessicaTrainingSetId",
"description": "300 sentences Jessica data in general style.",
"projectId": "ProjectId",
"locale": "en-US",
"voiceKind": "Female",
"status": "Succeeded",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
Trainingsetgegevens uploaden
Als u een trainingsset audio en scripts wilt uploaden, gebruikt u de TrainingSets_UploadData bewerking van de aangepaste spraak-API.
Voordat u deze API aanroept, slaat u opname- en scriptbestanden op in Azure Blob. In het onderstaande voorbeeld zijn opnamebestanden *.wav, scriptbestanden *https://contoso.blob.core.windows.net/voicecontainer/jessica300/.txt.https://contoso.blob.core.windows.net/voicecontainer/jessica300/
Bouw de aanvraagbody volgens de volgende instructies:
- Stel de vereiste eigenschap in
kindopAudioAndScript. Het type bepaalt het type trainingsset. - Stel de vereiste
audioseigenschap in. Stel in deaudioseigenschap de volgende eigenschappen in:- Stel de vereiste
containerUrleigenschap in op de URL van de Azure Blob Storage-container die de audiobestanden bevat. Shared Access Signatures (SAS) gebruiken voor een container met zowel lees- als lijstmachtigingen. - Stel de vereiste eigenschap in
extensionsop de extensies van de audiobestanden. - Stel desgewenst de
prefixeigenschap in om een voorvoegsel in te stellen voor de blobnaam.
- Stel de vereiste
- Stel de vereiste
scriptseigenschap in. Stel in descriptseigenschap de volgende eigenschappen in:- Stel de vereiste
containerUrleigenschap in op de URL van de Azure Blob Storage-container die de scriptbestanden bevat. Shared Access Signatures (SAS) gebruiken voor een container met zowel lees- als lijstmachtigingen. - Stel de vereiste eigenschap in
extensionsop de extensies van de scriptbestanden. - Stel desgewenst de
prefixeigenschap in om een voorvoegsel in te stellen voor de blobnaam.
- Stel de vereiste
Maak een HTTP POST-aanvraag met behulp van de URI, zoals wordt weergegeven in het volgende TrainingSets_UploadData voorbeeld.
- Vervang door
YourResourceKeyuw Spraak-resourcesleutel. - Vervang door
YourResourceRegionuw spraakresourceregio. - Vervang
JessicaTrainingSetIdals u in de vorige stap een andere id voor de trainingsset hebt opgegeven.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"kind": "AudioAndScript",
"audios": {
"containerUrl": "https://contoso.blob.core.windows.net/voicecontainer?mySasToken",
"prefix": "jessica300/",
"extensions": [
".wav"
]
},
"scripts": {
"containerUrl": "https://contoso.blob.core.windows.net/voicecontainer?mySasToken",
"prefix": "jessica300/",
"extensions": [
".txt"
]
}
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/trainingsets/JessicaTrainingSetId:upload?api-version=2024-02-01-preview"
De antwoordheader bevat de Operation-Location eigenschap. Gebruik deze URI voor meer informatie over de TrainingSets_UploadData-bewerking . Hier volgt een voorbeeld van de antwoordheader:
Operation-Location: https://eastus.api.cognitive.microsoft.com/customvoice/operations/284b7e37-f42d-4054-8fa9-08523c3de345?api-version=2024-02-01-preview
Operation-Id: 284b7e37-f42d-4054-8fa9-08523c3de345