De herkenningskwaliteit van een aangepast spraakmodel testen
U kunt de herkenningskwaliteit van een aangepast spraakmodel controleren in Speech Studio. U kunt geüploade audio afspelen en bepalen of het opgegeven herkenningsresultaat juist is. Nadat een test is gemaakt, kunt u zien hoe een model de audiogegevensset heeft getranscribeerd of resultaten van twee modellen naast elkaar vergelijken.
Naast elkaar testen van modellen is handig om te valideren welk spraakherkenningsmodel het beste is voor een toepassing. Zie Testmodel kwantitatief voor een objectieve meting van nauwkeurigheid, waarvoor de invoer van transcriptiegegevenssets is vereist.
Belangrijk
Bij het testen voert het systeem een transcriptie uit. Dit is belangrijk om rekening mee te houden, omdat de prijzen per serviceaanbod en abonnementsniveau variëren. Raadpleeg altijd de officiële prijzen voor Azure AI-services voor de meest recente details.
Een test maken
Volg deze instructies om een test te maken:
Meld u aan bij Speech Studio.
Navigeer naar Aangepaste spraak van Speech Studio>en selecteer uw projectnaam in de lijst.
Selecteer Testmodellen>Nieuwe test maken.
Selecteer Kwaliteit controleren (alleen-audiogegevens)>Volgende.
Kies een audiogegevensset die u wilt gebruiken voor testen en selecteer vervolgens Volgende. Als er geen gegevenssets beschikbaar zijn, annuleert u de installatie en gaat u naar het menu Spraakgegevenssets om gegevenssets te uploaden.
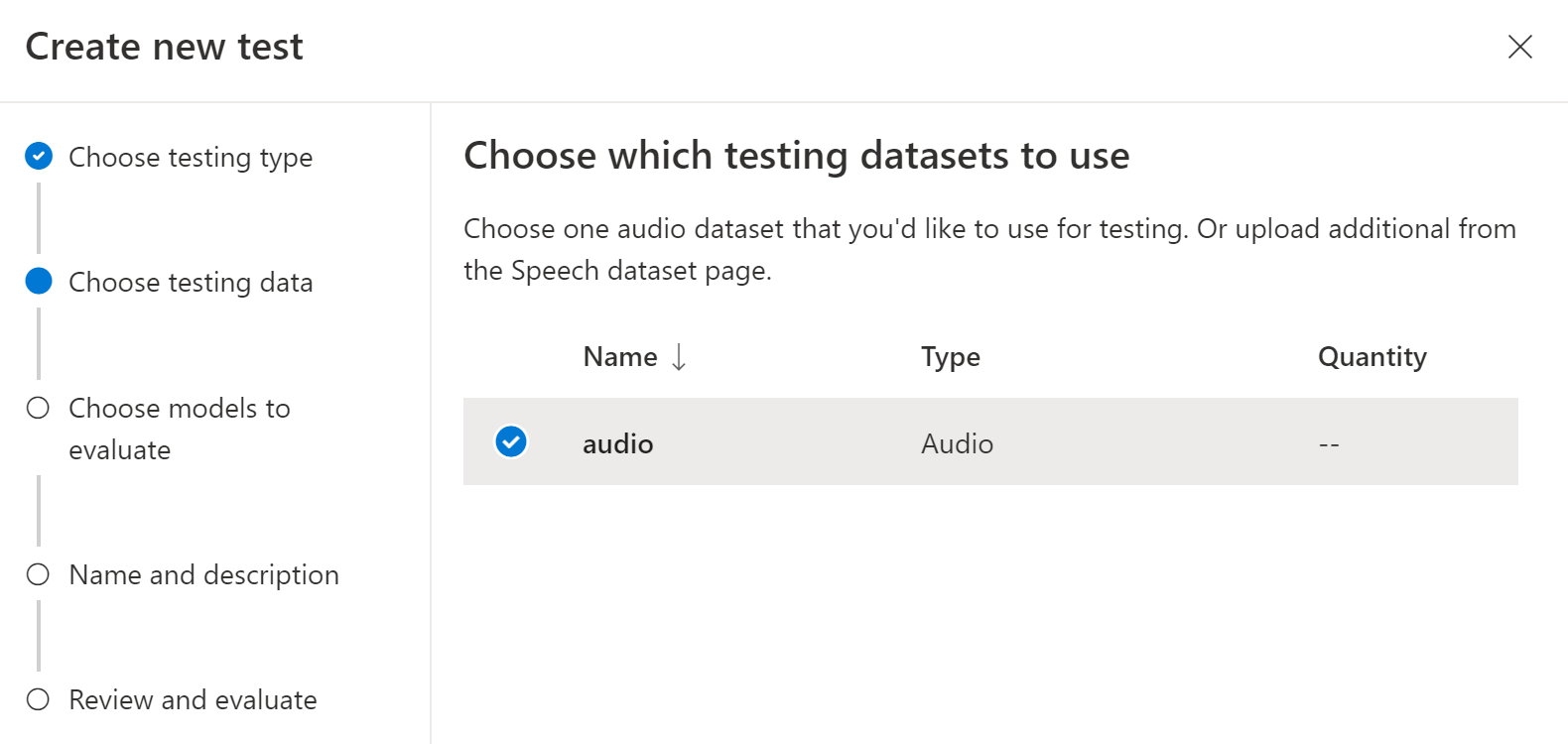
Kies een of twee modellen om de nauwkeurigheid te evalueren en te vergelijken.
Voer de testnaam en beschrijving in en selecteer Vervolgens.
Controleer uw instellingen en selecteer Opslaan en sluiten.
Gebruik de spx csr evaluation create opdracht om een test te maken. Bouw de aanvraagparameters volgens de volgende instructies:
- Stel de
projectparameter in op de id van een bestaand project. Deze parameter wordt aanbevolen, zodat u de test ook kunt bekijken in Speech Studio. U kunt despx csr project listopdracht uitvoeren om beschikbare projecten op te halen. - Stel de vereiste
model1parameter in op de id van een model dat u wilt testen. - Stel de vereiste
model2parameter in op de id van een ander model dat u wilt testen. Als u geen twee modellen wilt vergelijken, gebruikt u hetzelfde model voor beidemodel1enmodel2. - Stel de vereiste
datasetparameter in op de id van een gegevensset die u voor de test wilt gebruiken. - Stel de
languageparameter in, anders stelt de Speech CLI standaard 'en-US' in. Deze parameter moet de landinstelling van de inhoud van de gegevensset zijn. De landinstelling kan later niet meer worden gewijzigd. De speech CLI-parameterlanguagekomt overeen met delocaleeigenschap in de JSON-aanvraag en het antwoord. - Stel de vereiste
nameparameter in. Deze parameter is de naam die wordt weergegeven in Speech Studio. De speech CLI-parameternamekomt overeen met dedisplayNameeigenschap in de JSON-aanvraag en het antwoord.
Hier volgt een voorbeeld van een Speech CLI-opdracht waarmee een test wordt gemaakt:
spx csr evaluation create --api-version v3.2 --project 0198f569-cc11-4099-a0e8-9d55bc3d0c52 --dataset 23b6554d-21f9-4df1-89cb-f84510ac8d23 --model1 13fb305e-09ad-4bce-b3a1-938c9124dda3 --model2 13fb305e-09ad-4bce-b3a1-938c9124dda3 --name "My Inspection" --description "My Inspection Description"
U ontvangt een antwoordtekst in de volgende indeling:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": -1.0,
"sentenceErrorRate1": -1.0,
"sentenceCount1": -1,
"wordCount1": -1,
"correctWordCount1": -1,
"wordSubstitutionCount1": -1,
"wordDeletionCount1": -1,
"wordInsertionCount1": -1,
"wordErrorRate2": -1.0,
"sentenceErrorRate2": -1.0,
"sentenceCount2": -1,
"wordCount2": -1,
"correctWordCount2": -1,
"wordSubstitutionCount2": -1,
"wordDeletionCount2": -1,
"wordInsertionCount2": -1
},
"lastActionDateTime": "2024-07-14T21:21:39Z",
"status": "NotStarted",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
De eigenschap op het hoogste niveau self in de antwoordtekst is de URI van de evaluatie. Gebruik deze URI voor meer informatie over het project en de testresultaten. U gebruikt deze URI ook om de evaluatie bij te werken of te verwijderen.
Voer de volgende opdracht uit voor Speech CLI-hulp bij evaluaties:
spx help csr evaluation
Als u een test wilt maken, gebruikt u de Evaluations_Create bewerking van de REST API voor spraak-naar-tekst. Bouw de aanvraagbody volgens de volgende instructies:
- Stel de
projecteigenschap in op de URI van een bestaand project. Deze eigenschap wordt aanbevolen, zodat u de test ook kunt bekijken in Speech Studio. U kunt een Projects_List aanvraag indienen om beschikbare projecten op te halen. - Stel de vereiste
model1eigenschap in op de URI van een model dat u wilt testen. - Stel de vereiste
model2eigenschap in op de URI van een ander model dat u wilt testen. Als u geen twee modellen wilt vergelijken, gebruikt u hetzelfde model voor beidemodel1enmodel2. - Stel de vereiste
dataseteigenschap in op de URI van een gegevensset die u voor de test wilt gebruiken. - Stel de vereiste
localeeigenschap in. Deze eigenschap moet de landinstelling van de inhoud van de gegevensset zijn. De landinstelling kan later niet meer worden gewijzigd. - Stel de vereiste
displayNameeigenschap in. Deze eigenschap is de naam die wordt weergegeven in Speech Studio.
Maak een HTTP POST-aanvraag met behulp van de URI, zoals wordt weergegeven in het volgende voorbeeld. Vervang door YourSubscriptionKey de spraakresourcesleutel, vervang deze door YourServiceRegion uw spraakresourceregio en stel de eigenschappen van de aanvraagbody in zoals eerder beschreven.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey" -H "Content-Type: application/json" -d '{
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"displayName": "My Inspection",
"description": "My Inspection Description",
"locale": "en-US"
}' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations"
U ontvangt een antwoordtekst in de volgende indeling:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": -1.0,
"sentenceErrorRate1": -1.0,
"sentenceCount1": -1,
"wordCount1": -1,
"correctWordCount1": -1,
"wordSubstitutionCount1": -1,
"wordDeletionCount1": -1,
"wordInsertionCount1": -1,
"wordErrorRate2": -1.0,
"sentenceErrorRate2": -1.0,
"sentenceCount2": -1,
"wordCount2": -1,
"correctWordCount2": -1,
"wordSubstitutionCount2": -1,
"wordDeletionCount2": -1,
"wordInsertionCount2": -1
},
"lastActionDateTime": "2024-07-14T21:21:39Z",
"status": "NotStarted",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
De eigenschap op het hoogste niveau self in de antwoordtekst is de URI van de evaluatie. Gebruik deze URI voor meer informatie over het project en de testresultaten van de evaluatie. U gebruikt deze URI ook om de evaluatie bij te werken of te verwijderen.
Testresultaten ophalen
U moet de testresultaten ophalen en de audiogegevenssets controleren in vergelijking met transcriptieresultaten voor elk model.
Volg deze stappen om testresultaten op te halen:
- Meld u aan bij Speech Studio.
- Selecteer Aangepaste spraak> Uw projectnaam> Testmodellen.
- Selecteer de koppeling op testnaam.
- Nadat de test is voltooid, zoals aangegeven door de status die is ingesteld op Geslaagd, ziet u resultaten met het WER-nummer voor elk getest model.
Op deze pagina worden alle uitingen in uw gegevensset en de herkenningsresultaten weergegeven, samen met de transcriptie van de ingediende gegevensset. U kunt verschillende fouttypen in- of uitschakelen, waaronder invoegen, verwijderen en vervangen. Door naar de audio te luisteren en de herkenningsresultaten in elke kolom te vergelijken, kunt u bepalen welk model aan uw behoeften voldoet en bepalen waar meer training en verbeteringen nodig zijn.
Gebruik de spx csr evaluation status opdracht om testresultaten op te halen. Bouw de aanvraagparameters volgens de volgende instructies:
- Stel de vereiste
evaluationparameter in op de id van de evaluatie die u wilt testen.
Hier volgt een voorbeeld van een Speech CLI-opdracht waarmee testresultaten worden opgehaald:
spx csr evaluation status --api-version v3.2 --evaluation 9c06d5b1-213f-4a16-9069-bc86efacdaac
De modellen, audiogegevensset, transcripties en meer details worden geretourneerd in de hoofdtekst van het antwoord.
U ontvangt een antwoordtekst in de volgende indeling:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": 0.028900000000000002,
"sentenceErrorRate1": 0.667,
"tokenErrorRate1": 0.12119999999999999,
"sentenceCount1": 3,
"wordCount1": 173,
"correctWordCount1": 170,
"wordSubstitutionCount1": 2,
"wordDeletionCount1": 1,
"wordInsertionCount1": 2,
"tokenCount1": 165,
"correctTokenCount1": 145,
"tokenSubstitutionCount1": 10,
"tokenDeletionCount1": 1,
"tokenInsertionCount1": 9,
"tokenErrors1": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
},
"wordErrorRate2": 0.028900000000000002,
"sentenceErrorRate2": 0.667,
"tokenErrorRate2": 0.12119999999999999,
"sentenceCount2": 3,
"wordCount2": 173,
"correctWordCount2": 170,
"wordSubstitutionCount2": 2,
"wordDeletionCount2": 1,
"wordInsertionCount2": 2,
"tokenCount2": 165,
"correctTokenCount2": 145,
"tokenSubstitutionCount2": 10,
"tokenDeletionCount2": 1,
"tokenInsertionCount2": 9,
"tokenErrors2": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
}
},
"lastActionDateTime": "2024-07-14T21:22:45Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
Voer de volgende opdracht uit voor Speech CLI-hulp bij evaluaties:
spx help csr evaluation
Als u testresultaten wilt ophalen, begint u met de Evaluations_Get bewerking van de REST API voor spraak-naar-tekst.
Maak een HTTP GET-aanvraag met behulp van de URI, zoals wordt weergegeven in het volgende voorbeeld. Vervang YourEvaluationId door uw evaluatie-id, vervang deze door YourSubscriptionKey uw Spraak-resourcesleutel en vervang deze door YourServiceRegion uw spraakresourceregio.
curl -v -X GET "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/YourEvaluationId" -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey"
De modellen, audiogegevensset, transcripties en meer details worden geretourneerd in de hoofdtekst van het antwoord.
U ontvangt een antwoordtekst in de volgende indeling:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": 0.028900000000000002,
"sentenceErrorRate1": 0.667,
"tokenErrorRate1": 0.12119999999999999,
"sentenceCount1": 3,
"wordCount1": 173,
"correctWordCount1": 170,
"wordSubstitutionCount1": 2,
"wordDeletionCount1": 1,
"wordInsertionCount1": 2,
"tokenCount1": 165,
"correctTokenCount1": 145,
"tokenSubstitutionCount1": 10,
"tokenDeletionCount1": 1,
"tokenInsertionCount1": 9,
"tokenErrors1": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
},
"wordErrorRate2": 0.028900000000000002,
"sentenceErrorRate2": 0.667,
"tokenErrorRate2": 0.12119999999999999,
"sentenceCount2": 3,
"wordCount2": 173,
"correctWordCount2": 170,
"wordSubstitutionCount2": 2,
"wordDeletionCount2": 1,
"wordInsertionCount2": 2,
"tokenCount2": 165,
"correctTokenCount2": 145,
"tokenSubstitutionCount2": 10,
"tokenDeletionCount2": 1,
"tokenInsertionCount2": 9,
"tokenErrors2": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
}
},
"lastActionDateTime": "2024-07-14T21:22:45Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
Transcriptie vergelijken met audio
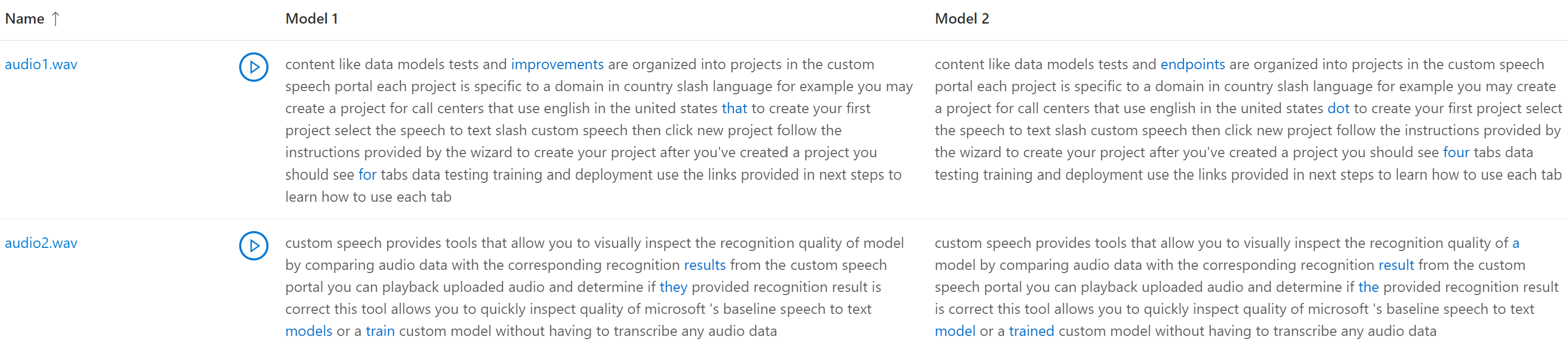
U kunt de transcriptieuitvoer controleren door elk model dat is getest, op basis van de gegevensset voor audio-invoer. Als u twee modellen in de test hebt opgenomen, kunt u de kwaliteit van de transcriptie naast elkaar vergelijken.
De kwaliteit van transcripties controleren:
- Meld u aan bij Speech Studio.
- Selecteer Aangepaste spraak> Uw projectnaam> Testmodellen.
- Selecteer de koppeling op testnaam.
- Een audiobestand afspelen terwijl de bijbehorende transcriptie door een model wordt gelezen.
Als de testgegevensset meerdere audiobestanden bevat, ziet u meerdere rijen in de tabel. Als u twee modellen in de test hebt opgenomen, worden transcripties weergegeven in kolommen naast elkaar. Transcriptieverschillen tussen modellen worden weergegeven in het blauwe lettertype.
De testgegevensset, transcripties en geteste modellen worden geretourneerd in de testresultaten. Als er slechts één model is getest, komt de model1 waarde overeen model2met en komt de transcription1 waarde overeen transcription2.
De kwaliteit van transcripties controleren:
- Download de gegevensset voor de audiotest, tenzij u al een kopie hebt.
- Download de uitvoertranscripties.
- Een audiobestand afspelen terwijl de bijbehorende transcriptie door een model wordt gelezen.
Als u de kwaliteit tussen twee modellen vergelijkt, moet u met name letten op verschillen tussen de transcripties van elk model.
De testgegevensset, transcripties en geteste modellen worden geretourneerd in de testresultaten. Als er slechts één model is getest, komt de model1 waarde overeen model2met en komt de transcription1 waarde overeen transcription2.
De kwaliteit van transcripties controleren:
- Download de gegevensset voor de audiotest, tenzij u al een kopie hebt.
- Download de uitvoertranscripties.
- Een audiobestand afspelen terwijl de bijbehorende transcriptie door een model wordt gelezen.
Als u de kwaliteit tussen twee modellen vergelijkt, moet u met name letten op verschillen tussen de transcripties van elk model.