Uw gegevens labelen in Language Studio
Voordat u uw model traint, moet u uw documenten labelen met de aangepaste entiteiten die u wilt extraheren. Gegevenslabeling is een cruciale stap in de ontwikkelingslevenscyclus. In deze stap kunt u de entiteitstypen maken die u wilt extraheren uit uw gegevens en deze entiteiten labelen in uw documenten. Deze gegevens worden in de volgende stap gebruikt bij het trainen van uw model, zodat uw model kan leren van de gelabelde gegevens. Als u al gelabelde gegevens hebt, kunt u deze rechtstreeks importeren in uw project, maar u moet ervoor zorgen dat uw gegevens de geaccepteerde gegevensindeling volgen. Zie Project maken voor meer informatie over het importeren van gelabelde gegevens in uw project.
Voordat u een aangepast NER-model maakt, moet u eerst gelabelde gegevens hebben. Als uw gegevens nog niet zijn gelabeld, kunt u deze labelen in Language Studio. Gelabelde gegevens informeren het model over het interpreteren van tekst en wordt gebruikt voor training en evaluatie.
Vereisten
Voordat u uw gegevens kunt labelen, hebt u het volgende nodig:
- Een project gemaakt met een geconfigureerd Azure Blob Storage-account
- Tekstgegevens die zijn geüpload naar uw opslagaccount.
Zie de levenscyclus van projectontwikkeling voor meer informatie.
Richtlijnen voor gegevenslabels
Nadat u uw gegevens hebt voorbereid, moet u uw schema ontwerpen en uw project maken door uw gegevens te labelen. Het labelen van uw gegevens is belangrijk, zodat uw model weet welke woorden worden gekoppeld aan de entiteitstypen die u moet extraheren. Wanneer u uw gegevens labelt in Language Studio (of gelabelde gegevens importeert), worden deze labels opgeslagen in het JSON-document in uw opslagcontainer die u met dit project hebt verbonden.
Houd rekening met het label van uw gegevens:
Over het algemeen leiden meer gelabelde gegevens tot betere resultaten, mits de gegevens nauwkeurig worden gelabeld.
De precisie, consistentie en volledigheid van uw gelabelde gegevens zijn belangrijke factoren voor het bepalen van modelprestaties.
- Label precies: Label elke entiteit altijd aan het juiste type. Neem alleen op wat u wilt uitgepakt, vermijd onnodige gegevens in uw labels.
- Label consistent: dezelfde entiteit moet hetzelfde label hebben voor alle documenten.
- Label volledig: Label alle exemplaren van de entiteit in al uw documenten. U kunt de functie voor automatisch labelen gebruiken om volledige labels te garanderen.
Notitie
Er is geen vast aantal labels dat ervoor kan zorgen dat uw model het beste presteert. Modelprestaties zijn afhankelijk van mogelijke dubbelzinnigheid in uw schema en de kwaliteit van uw gelabelde gegevens. We raden echter aan om ongeveer 50 gelabelde exemplaren per entiteitstype te hebben.
Uw gegevens labelen
Gebruik de volgende stappen om uw gegevens te labelen:
Ga naar uw projectpagina in Language Studio.
Selecteer gegevenslabeling in het menu aan de linkerkant. U vindt een lijst met alle documenten in uw opslagcontainer.
Tip
U kunt de filters in het bovenste menu gebruiken om de niet-gelabelde documenten weer te geven, zodat u ze kunt labelen. U kunt de filters ook gebruiken om de documenten weer te geven die zijn gelabeld met een specifiek entiteitstype.
Ga naar één documentweergave aan de linkerkant in het bovenste menu of selecteer een specifiek document om te beginnen met labelen. U vindt een lijst met alle
.txtdocumenten die beschikbaar zijn in uw project aan de linkerkant. U kunt de knop Vorige en Volgende onderaan de pagina gebruiken om door uw documenten te navigeren.Notitie
Als u meerdere talen voor uw project hebt ingeschakeld, vindt u een vervolgkeuzelijst Taal in het bovenste menu, waarin u de taal van elk document kunt selecteren.
Voeg in het rechterdeelvenster het entiteitstype toe aan uw project, zodat u kunt beginnen met het labelen van uw gegevens.
U hebt twee opties om uw document te labelen:
Optie Omschrijving Label met een kwast Selecteer het kwastpictogram naast een entiteitstype in het rechterdeelvenster en markeer vervolgens de tekst in het document waaraan u aantekeningen wilt toevoegen met dit entiteitstype. Labelen met behulp van een menu Markeer het woord dat u als entiteit wilt labelen en er wordt een menu weergegeven. Selecteer het entiteitstype dat u wilt toewijzen voor deze entiteit. In de onderstaande schermopname ziet u het labelen met behulp van een borstel.
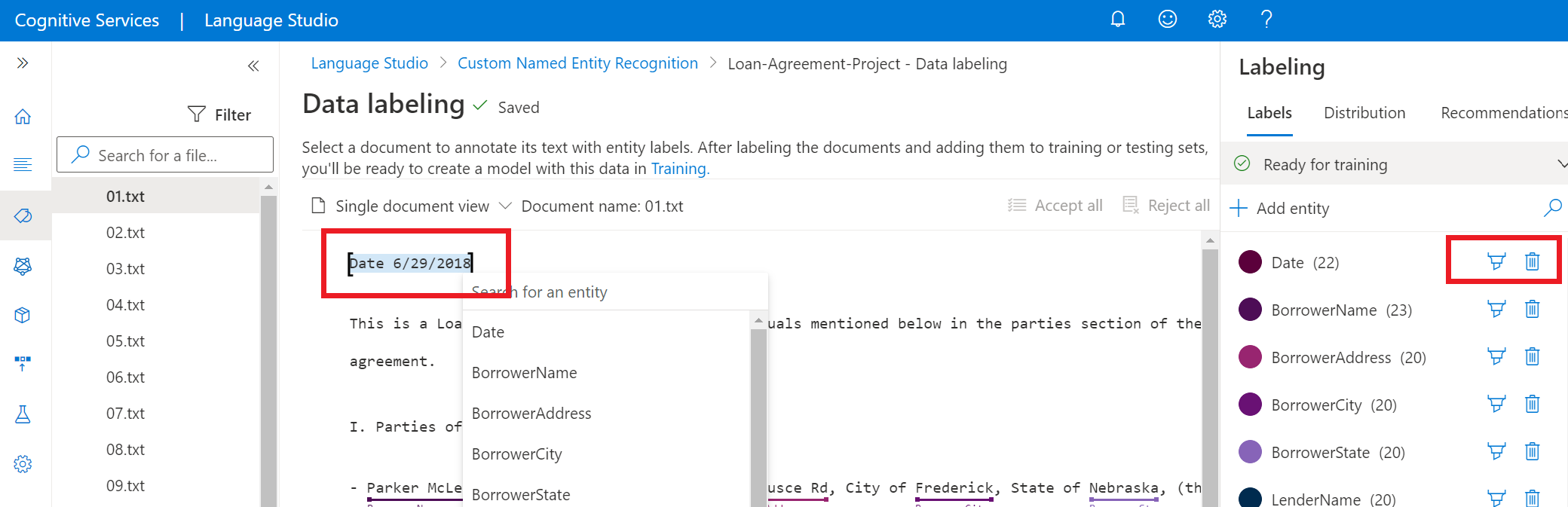
In het rechterdeelvenster onder de draaitabel Labels vindt u alle entiteitstypen in uw project en het aantal gelabelde exemplaren per stuk.
In het onderste gedeelte van het rechterdeelvenster kunt u het huidige document toevoegen dat u bekijkt aan de trainingsset of de testset. Standaard worden alle documenten toegevoegd aan uw trainingsset. Meer informatie over trainings- en testsets en hoe ze worden gebruikt voor modeltraining en -evaluatie.
Tip
Als u van plan bent automatische gegevenssplitsing te gebruiken, gebruikt u de standaardoptie voor het toewijzen van alle documenten aan uw trainingsset.
Onder het distributiedraaipunt kunt u de distributie in trainings- en testsets bekijken. U hebt twee opties voor weergave:
- Totaal aantal exemplaren waar u het aantal gelabelde exemplaren van een specifiek entiteitstype kunt bekijken.
- documenten met ten minste één label waarvan elk document wordt geteld als het ten minste één gelabeld exemplaar van deze entiteit bevat.
Wanneer u labelt, worden uw wijzigingen periodiek gesynchroniseerd, als ze nog niet zijn opgeslagen, ziet u boven aan de pagina een waarschuwing. Als u handmatig wilt opslaan, selecteert u de knop Labels opslaan onder aan de pagina.

Labels verwijderen
Een label verwijderen
- Selecteer de entiteit waaruit u een label wilt verwijderen.
- Blader door het menu dat wordt weergegeven en selecteer Label verwijderen.
Entiteiten verwijderen
Als u een entiteit wilt verwijderen, selecteert u het pictogram Verwijderen naast de entiteit die u wilt verwijderen. Als u een entiteit verwijdert, worden alle gelabelde exemplaren uit uw gegevensset verwijderd.
Volgende stappen
Nadat u uw gegevens hebt gelabeld, kunt u beginnen met het trainen van een model dat op basis van uw gegevens wordt geleerd.