Modelaanpassing (versie 4.0 preview)
Belangrijk
Deze functie is nu afgeschaft. Op 31 maart 2025 wordt azure AI Image Analysis 4.0 Custom Image Classification, Custom Object Detection en Product Recognition preview-API buiten gebruik gesteld. Na deze datum mislukken API-aanroepen naar deze services.
Als u een soepele werking van uw modellen wilt behouden, gaat u over naar Azure AI Custom Vision. Deze is nu algemeen beschikbaar. Custom Vision biedt vergelijkbare functionaliteit als deze buiten gebruik stellende functies.
Met modelaanpassing kunt u een speciaal afbeeldingsanalysemodel trainen voor uw eigen use-case. Aangepaste modellen kunnen afbeeldingsclassificatie uitvoeren (tags zijn van toepassing op de hele afbeelding) of objectdetectie (tags zijn van toepassing op specifieke gebieden van de afbeelding). Zodra uw aangepaste model is gemaakt en getraind, behoort het tot uw Vision-resource en kunt u het aanroepen met behulp van de Analyseafbeeldings-API.
Implementeer snel en eenvoudig modelaanpassing door een quickstart te volgen:
Belangrijk
U kunt een aangepast model trainen met behulp van de Custom Vision-service of de service Image Analysis 4.0 met modelaanpassing. In de volgende tabel worden de twee services vergeleken.
| Gebieden | Custom Vision-service | Afbeeldingsanalyse 4.0-service | ||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Opdrachten | Objectdetectie voor afbeeldingsclassificatie |
Objectdetectie voor afbeeldingsclassificatie |
||||||||||||||||||||||||||||||||||||
| Basismodel | CNN | Transformatormodel | ||||||||||||||||||||||||||||||||||||
| Labels | Customvision.ai | AML Studio | ||||||||||||||||||||||||||||||||||||
| Webportal | Customvision.ai | Vision Studio | ||||||||||||||||||||||||||||||||||||
| Bibliotheken | REST, SDK | REST, Python-voorbeeld | ||||||||||||||||||||||||||||||||||||
| Minimale trainingsgegevens nodig | 15 afbeeldingen per categorie | 2-5 afbeeldingen per categorie | ||||||||||||||||||||||||||||||||||||
| Opslag van trainingsgegevens | Geüpload naar service | Blob Storage-account van de klant | ||||||||||||||||||||||||||||||||||||
| Modelhosting | Cloud en rand | Alleen cloudhosting, edge-containerhosting komt eraan | ||||||||||||||||||||||||||||||||||||
| AI-kwaliteit |
|
|
||||||||||||||||||||||||||||||||||||
| Prijzen | Custom Vision-prijzen | Prijzen voor afbeeldingsanalyse |
Scenarioonderdelen
De belangrijkste onderdelen van een modelaanpassingssysteem zijn de trainingsafbeeldingen, COCO-bestand, gegevenssetobject en modelobject.
Trainingsafbeeldingen
Uw set trainingsafbeeldingen moet verschillende voorbeelden bevatten van elk van de labels die u wilt detecteren. U wilt ook een paar extra afbeeldingen verzamelen om uw model te testen wanneer het is getraind. De installatiekopieën moeten worden opgeslagen in een Azure Storage-container om toegankelijk te zijn voor het model.
Gebruik afbeeldingen met optische variaties om uw model effectief te kunnen trainen. Selecteer afbeeldingen die variëren in:
- camerahoek
- belichting
- achtergrond
- visuele stijl
- afzonderlijke/gegroepeerde onderwerpen
- size
- type
Zorg er bovendien voor dat al uw trainingsafbeeldingen aan de volgende criteria voldoen:
- De afbeelding moet worden weergegeven in JPEG-, PNG-, GIF-, BMP-, WEBP-, ICO-, TIFF- of MPO-indeling.
- De bestandsgrootte van de afbeelding moet kleiner zijn dan 20 MB (megabytes).
- De afmetingen van de afbeelding moeten groter zijn dan 50 x 50 pixels en kleiner dan 16.000 x 16.000 pixels.
COCO-bestand
Het COCO-bestand verwijst naar alle trainingsafbeeldingen en koppelt ze aan hun labelinformatie. In het geval van objectdetectie heeft het de coördinaten van het begrenzingsvak van elke tag op elke afbeelding opgegeven. Dit bestand moet de COCO-indeling hebben. Dit is een specifiek type JSON-bestand. Het COCO-bestand moet worden opgeslagen in dezelfde Azure Storage-container als de trainingsinstallatiekopieën.
Tip
Over COCO-bestanden
COCO-bestanden zijn JSON-bestanden met specifieke vereiste velden: "images", "annotations"en "categories". Een voorbeeld van een COCO-bestand ziet er als volgt uit:
{
"images": [
{
"id": 1,
"width": 500,
"height": 828,
"file_name": "0.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/0.jpg"
},
{
"id": 2,
"width": 754,
"height": 832,
"file_name": "1.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/1.jpg"
},
...
],
"annotations": [
{
"id": 1,
"category_id": 7,
"image_id": 1,
"area": 0.407,
"bbox": [
0.02663142641129032,
0.40691584277841153,
0.9524163571731749,
0.42766634515266866
]
},
{
"id": 2,
"category_id": 9,
"image_id": 2,
"area": 0.27,
"bbox": [
0.11803319477782331,
0.41586723392402375,
0.7765206955096307,
0.3483334397217212
]
},
...
],
"categories": [
{
"id": 1,
"name": "vegall original mixed vegetables"
},
{
"id": 2,
"name": "Amy's organic soups lentil vegetable"
},
{
"id": 3,
"name": "Arrowhead 8oz"
},
...
]
}
Naslaginformatie over COCO-bestandsvelden
Als u uw eigen COCO-bestand helemaal zelf genereert, moet u ervoor zorgen dat alle vereiste velden de juiste gegevens bevatten. In de volgende tabellen wordt elk veld in een COCO-bestand beschreven:
"afbeeldingen"
| Sleutel | Type | Description | Vereist? |
|---|---|---|---|
id |
geheel getal | Unieke afbeeldings-id, beginnend vanaf 1 | Ja |
width |
geheel getal | Breedte van de afbeelding in pixels | Ja |
height |
geheel getal | Hoogte van de afbeelding in pixels | Ja |
file_name |
tekenreeks | Een unieke naam voor de afbeelding | Ja |
absolute_url of coco_url |
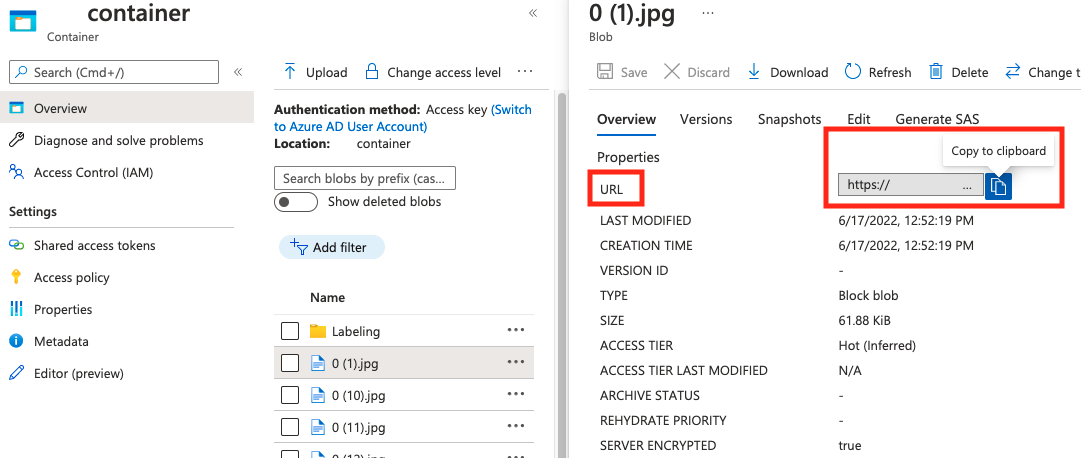
tekenreeks | Afbeeldingspad als een absolute URI naar een blob in een blobcontainer. De Vision-resource moet gemachtigd zijn om de annotatiebestanden en alle afbeeldingsbestanden waarnaar wordt verwezen te lezen. | Ja |
De waarde voor absolute_url vindt u in de eigenschappen van uw blobcontainer:
"aantekeningen"
| Sleutel | Type | Description | Vereist? |
|---|---|---|---|
id |
geheel getal | Id van de aantekening | Ja |
category_id |
geheel getal | Id van de categorie die is gedefinieerd in de categories sectie |
Ja |
image_id |
geheel getal | Id van de afbeelding | Ja |
area |
geheel getal | Waarde van 'Width' x 'Height' (derde en vierde waarde van bbox) |
Nee |
bbox |
list[float] | Relatieve coördinaten van het begrenzingsvak (0 tot 1), in de volgorde van 'Links', 'Boven', 'Breedte', 'Hoogte' | Ja |
"categorieën"
| Sleutel | Type | Description | Vereist? |
|---|---|---|---|
id |
geheel getal | Unieke id voor elke categorie (labelklasse). Deze moeten aanwezig zijn in de annotations sectie. |
Ja |
name |
tekenreeks | Naam van de categorie (labelklasse) | Ja |
COCO-bestandsverificatie
U kunt onze Python-voorbeeldcode gebruiken om de indeling van een COCO-bestand te controleren.
Gegevenssetobject
Het gegevenssetobject is een gegevensstructuur die is opgeslagen door de Image Analysis-service die verwijst naar het koppelingsbestand. U moet een gegevenssetobject maken voordat u een model kunt maken en trainen.
Modelobject
Het modelobject is een gegevensstructuur die is opgeslagen door de Image Analysis-service die een aangepast model vertegenwoordigt. Deze moet zijn gekoppeld aan een gegevensset om de eerste training uit te voeren. Zodra het model is getraind, kunt u een query uitvoeren op uw model door de naam in te voeren in de model-name queryparameter van de aanroep Afbeeldings-API analyseren.
Quotumlimieten
In de volgende tabel worden de limieten beschreven voor de schaal van uw aangepaste modelprojecten.
| Categorie | Algemene afbeeldingsclassificatie | Algemene objectdetector |
|---|---|---|
| Maximum aantal trainingsuren | 288 (12 dagen) | 288 (12 dagen) |
| Maximaal aantal trainingsafbeeldingen | 1.000.000 | 200.000 |
| Maximaal aantal #-evaluatieafbeeldingen | 100.000 | 100.000 |
| Min # trainingsafbeeldingen per categorie | 2 | 2 |
| Maximum aantal tags per afbeelding | 1 | N.v.t. |
| Maximum aantal regio's per afbeelding | N.v.t. | 1.000 |
| Maximum aantal #-categorieën | 2500 | 1.000 |
| Min # categorieën | 2 | 1 |
| Maximale afbeeldingsgrootte (training) | 20 MB | 20 MB |
| Maximale afbeeldingsgrootte (voorspelling) | Synchronisatie: 6 MB, Batch: 20 MB | Synchronisatie: 6 MB, Batch: 20 MB |
| Maximale breedte/hoogte van afbeelding (training) | 10,240 | 10,240 |
| Minimale breedte/hoogte van afbeelding (voorspelling) | 50 | 50 |
| Beschikbare regio's | VS - west 2, VS - oost, Europa - west | VS - west 2, VS - oost, Europa - west |
| Geaccepteerde afbeeldingstypen | jpg, png, bmp, gif, jpeg | jpg, png, bmp, gif, jpeg |
Veelgestelde vragen
Waarom mislukt het importeren van mijn COCO-bestand bij het importeren uit blobopslag?
Momenteel is Microsoft bezig met het oplossen van een probleem waardoor het importeren van COCO-bestanden mislukt met grote gegevenssets wanneer het in Vision Studio wordt gestart. Als u wilt trainen met behulp van een grote gegevensset, is het raadzaam om in plaats daarvan de REST API te gebruiken.
Waarom duurt de training langer/korter dan mijn opgegeven budget?
Het opgegeven trainingsbudget is de gekalibreerde rekentijd, niet de wandkloktijd. Enkele veelvoorkomende redenen voor het verschil worden vermeld:
Langer dan het opgegeven budget:
- Afbeeldingsanalyse ondervindt een hoog trainingsverkeer en GPU-resources zijn mogelijk krap. Uw taak kan in de wachtrij wachten of in de wacht staan tijdens de training.
- Tijdens het back-endtrainingsproces zijn onverwachte fouten opgetreden, wat heeft geresulteerd in het opnieuw proberen van logica. De mislukte uitvoeringen verbruiken uw budget niet, maar dit kan leiden tot langere trainingstijd in het algemeen.
- Uw gegevens worden opgeslagen in een andere regio dan uw Vision-resource, wat leidt tot langere tijd voor gegevensoverdracht.
Korter dan het opgegeven budget: de volgende factoren versnellen de training ten koste van het gebruik van meer budget in bepaalde wandkloktijd.
- Afbeeldingsanalyse traint soms met meerdere GPU's, afhankelijk van uw gegevens.
- Afbeeldingsanalyse traint soms meerdere verkenningsproeven op meerdere GPU's tegelijk.
- Afbeeldingsanalyse maakt soms gebruik van premier (snellere) GPU-SKU's om te trainen.
Waarom mislukt mijn training en wat ik moet doen?
Hier volgen enkele veelvoorkomende redenen voor trainingsfouten:
-
diverged: De training kan geen zinvolle dingen van uw gegevens leren. Enkele veelvoorkomende oorzaken zijn:- Gegevens zijn niet voldoende: het leveren van meer gegevens zou moeten helpen.
- Gegevens zijn van slechte kwaliteit: controleer of uw afbeeldingen een lage resolutie hebben, extreme hoogte-breedteverhoudingen of als aantekeningen onjuist zijn.
-
notEnoughBudget: Uw opgegeven budget is niet voldoende voor de grootte van uw gegevensset en modeltype dat u traint. Geef een groter budget op. -
datasetCorrupt: Dit betekent meestal dat uw opgegeven afbeeldingen niet toegankelijk zijn of dat het aantekeningsbestand de verkeerde indeling heeft. -
datasetNotFound: kan de gegevensset niet vinden -
unknown: Dit kan een back-endprobleem zijn. Neem contact op met ondersteuning voor onderzoek.
Welke metrische gegevens worden gebruikt voor het evalueren van de modellen?
De volgende metrische gegevens worden gebruikt:
- Afbeeldingsclassificatie: Gemiddelde precisie, nauwkeurigheid top 1, nauwkeurigheid top 5
- Objectdetectie: Gemiddelde precisie @ 30, gemiddelde gemiddelde precisie @ 50, gemiddelde precisie @ 75
Waarom mislukt de registratie van mijn gegevensset?
De API-antwoorden moeten informatief genoeg zijn. Dit zijn:
-
DatasetAlreadyExists: Er bestaat een gegevensset met dezelfde naam -
DatasetInvalidAnnotationUri: "Er is een ongeldige URI opgegeven bij de aantekenings-URI's tijdens de registratietijd van de gegevensset.
Hoeveel afbeeldingen zijn vereist voor redelijke/goede/beste modelkwaliteit?
Hoewel Florence-modellen geweldige weinig-shot-mogelijkheden hebben (het bereiken van geweldige modelprestaties onder beperkte beschikbaarheid van gegevens), maken in het algemeen meer gegevens uw getrainde model beter en robuuster. Sommige scenario's vereisen weinig gegevens (zoals het classificeren van een appel tegen een banaan), maar andere vereisen meer (zoals het detecteren van 200 soorten insecten in een regenwoud). Dit maakt het lastig om één aanbeveling te geven.
Als uw budget voor gegevenslabels beperkt is, is de aanbevolen werkstroom de volgende stappen te herhalen:
Verzamel
Nafbeeldingen per klasse, waarNu eenvoudig afbeeldingen kunt verzamelen (bijvoorbeeldN=3)Train een model en test het op uw evaluatieset.
Als de modelprestaties het volgende zijn:
- Goed genoeg (prestaties zijn beter dan uw verwachting of prestaties dicht bij uw vorige experiment met minder verzamelde gegevens): Stop hier en gebruik dit model.
- Niet goed (prestaties zijn nog steeds onder uw verwachting of beter dan uw vorige experiment met minder gegevens die met een redelijke marge worden verzameld):
- Verzamel meer afbeeldingen voor elke klas, een getal dat u gemakkelijk kunt verzamelen en ga terug naar stap 2.
- Als u merkt dat de prestaties na een paar iteraties niet meer worden verbeterd, kan dit het volgende zijn:
- dit probleem is niet goed gedefinieerd of is te moeilijk. Neem contact met ons op voor case-by-case-analyse.
- de trainingsgegevens kunnen van lage kwaliteit zijn: controleer of er verkeerde aantekeningen of zeer lage pixelafbeeldingen zijn.
Hoeveel trainingsbudget moet ik opgeven?
U moet de bovengrens van het budget opgeven dat u wilt gebruiken. Afbeeldingsanalyse maakt gebruik van een AutoML-systeem in de back-end om verschillende modellen en trainingsrecepten uit te proberen om het beste model voor uw use-case te vinden. Hoe meer budget wordt gegeven, hoe hoger de kans op het vinden van een beter model.
Het AutoML-systeem stopt ook automatisch als er wordt geconcludeerd dat het niet meer hoeft te proberen, zelfs als er nog een budget is. Het maakt dus niet altijd gebruik van uw opgegeven budget. U wordt gegarandeerd niet gefactureerd voor uw opgegeven budget.
Kan ik de hyperparameters beheren of mijn eigen modellen gebruiken in de training?
Nee, de aanpassingsservice voor het afbeeldingsanalysemodel maakt gebruik van een autoML-trainingssysteem met weinig code waarmee hyperparameterzoekopdrachten en basismodelselectie in de back-end worden verwerkt.
Kan ik mijn model exporteren na de training?
De voorspellings-API wordt alleen ondersteund via de cloudservice.
Waarom mislukt de evaluatie voor mijn objectdetectiemodel?
Hieronder ziet u de mogelijke redenen:
-
internalServerError: Er is een onbekende fout opgetreden. Probeert u het later nog eens. -
modelNotFound: Het opgegeven model is niet gevonden. -
datasetNotFound: De opgegeven gegevensset is niet gevonden. -
datasetAnnotationsInvalid: Er is een fout opgetreden tijdens het downloaden of parseren van de aan de testgegevensset gekoppelde aan de basiswaarnotaties. -
datasetEmpty: De testgegevensset bevat geen aantekeningen voor 'grondwaar'.
Wat is de verwachte latentie voor voorspellingen met aangepaste modellen?
We raden u niet aan aangepaste modellen te gebruiken voor bedrijfskritieke omgevingen vanwege mogelijke hoge latentie. Wanneer klanten aangepaste modellen trainen in Vision Studio, behoren deze aangepaste modellen tot de Azure AI Vision-resource waaronder ze zijn getraind en kan de klant deze modellen aanroepen met behulp van de Analyze Image-API . Wanneer ze deze aanroepen doen, wordt het aangepaste model in het geheugen geladen en wordt de voorspellingsinfrastructuur geïnitialiseerd. Hoewel dit gebeurt, ervaren klanten mogelijk langer dan de verwachte latentie om voorspellingsresultaten te ontvangen.
Gegevensprivacy en -beveiliging
Net als bij alle Azure AI-services moeten ontwikkelaars die aanpassing van het afbeeldingsanalysemodel gebruiken, rekening houden met het beleid van Microsoft voor klantgegevens. Zie de pagina Azure AI-services in het Vertrouwenscentrum van Microsoft voor meer informatie.