February 2009
Volume 24 Number 02
CLR Inside Out - Handling Corrupted State Exceptions
By Andrew Pardoe | February 2009
This column is based on a prerelease version of Visual Studio 2010. All information is subject to change.
Contents
What Exactly Are Exceptions?
Win32 SEH Exceptions and System.Exception
Managed Code and SEH
Corrupted State Exceptions
It's Still Wrong to Use Catch (Exception e)
Code Wisely
Have you ever written code that isn't quite right but is close enough? Have you had to write code that works fine when everything goes well, but you're not quite sure what will happen when something goes wrong? There's a simple, incorrect statement that's probably sitting in some code that you wrote or have had to maintain: catch (Exception e). It seems innocent and straightforward, but this little statement can cause a lot of problems when it fails to do what you expect.
If you've ever seen code that uses exceptions the way the following code does, then you need to read this column:
public void FileSave(String name)
{
try
{
FileStream fs = new FileStream(name, FileMode.Create);
}
catch (Exception)
{
throw new System.IO.IOException("File Open Error!");
}
}
The error in this code is common: it is simpler to write code to catch all exceptions than it is to catch exactly the exceptions that could be raised by code executing in your try block. But by catching the base of the exception hierarchy, you will end up swallowing an exception of any type and converting it to an IOException.
Exception handling is one of those areas about which most people have a working knowledge rather than an intimate understanding. I'll begin with a bit of background information explaining exception handling from the CLR point of view for those who may be more familiar with exception handling from native programming or an old college textbook. If you're an old pro at managed exception handling, feel free to skip ahead to the section on different kinds of exceptions or the one on managed code and structured exception handling (SEH). Make sure to read the last few sections, though.
What Exactly Are Exceptions?
An exception is the signal raised when a condition is detected that was not expected in the normal execution of a program thread. Many agents can detect incorrect conditions and raise exceptions. Program code (or the library code it uses) can throw types derived from System.Exception, the CLR execution engine can raise exceptions, and unmanaged code can raise exceptions as well. Exceptions raised on a thread of execution follow the thread through native and managed code, across AppDomains, and, if not handled by the program, are treated as unhandled exceptions by the operating system.
An exception indicates that something bad has happened. While every managed exception has a type (such as System.ArgumentException or System.ArithmeticException), the type is only meaningful in the context in which the exception is raised. A program can handle an exception if it understands the conditions that caused the exception to occur. But if the program doesn't handle the exception, it could indicate any number of bad things. And once the exception has left the program, it only has one very general meaning: something bad has happened.
When Windows sees that a program doesn't handle an exception, it tries to protect the program's persisted data (files on disk, registry settings, and so on) by terminating the process. Even if the exception originally indicated some benign, unexpected program state (such as failing to pop from an empty stack) it appears to be a serious problem when Windows sees it because the operating system doesn't have the context to properly interpret the exception. A single thread in one AppDomain can bring down an entire CLR instance by not handling an exception (see Figure 1).
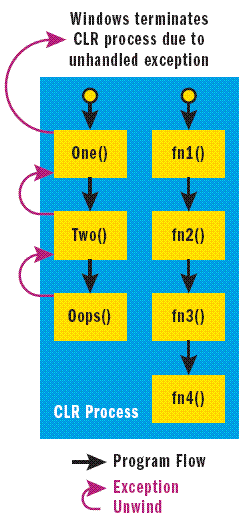
Figure 1 One Thread’s Unhandled Exception Causes the Entire Process to Terminate
If exceptions are so dangerous, why are they so popular? Like motorcycles and chain saws, the raw power of exceptions makes them very useful. Normal dataflow on a program thread goes from function to function through calls and returns. Every call to a function creates a frame of execution on the stack; every return destroys that frame. Aside from altering global state, the only flow of data in a program is achieved by passing data between contiguous frames as function parameters or return values. In the absence of exception handling, every caller needs to check for the success of the function that it called (or just assume everything is always OK).
Most Win32 APIs return a non-zero value to indicate failure because Windows doesn't use exception handling. The programmer has to wrap every function call with code that checks the return value of the called function. For example, this code from MSDN documentation on how to list files in a directory explicitly checks each call for success. The call to FindNextFile(...) is wrapped in a check to see if the return is non-zero. If the call is not successful then a separate function call—GetLastError()—provides details of the exceptional condition. Note that every call must be checked for success on the next frame because return values are necessarily limited to the local function scope:
// FindNextFile requires checking for success of each call
while (FindNextFile(hFind, &ffd) != 0);
dwError = GetLastError();
if (dwError != ERROR_NO_MORE_FILES)
{
ErrorHandler(TEXT("FindFirstFile"));
}
FindClose(hFind);
return dwError;
An error condition can only pass from the function containing the unexpected condition to that function's caller. Exceptions have the power to pass the results of a function's execution out of the current function's scope to every frame up the stack until it reaches the frame that knows how to handle the unexpected condition. The CLR's exception system (called a two-pass exception system) delivers the exception to every predecessor on the thread's call stack, beginning with the caller and proceeding until some function says it will handle the exception (this is known as the first pass).
The exception system will then unwind the state of each frame on the call stack between where the exception is raised and where it will be handled (known as the second pass). As the stack unwinds, the CLR will run both finally clauses and fault clauses in each frame as it is unwound. Then, the catch clause in the handling frame is executed.
Because the CLR checks every predecessor on the call stack there's no need for the caller to have a catch block—the exception can be caught anywhere up the stack. Instead of having code to immediately check the result of every function call, a programmer can handle errors in a place far away from where the exception was raised. Using error codes requires the programmer to inspect and pass on an error code at every stack frame until it reaches the place where the erroneous condition can be handled. Exception handling frees the programmer from inspecting the exception at every frame on the stack.
For more on throwing custom exception types, see "Error Handling: Throwing Custom Exception Types from a Managed COM+ Server Application".
Win32 SEH Exceptions and System.Exception
There's an interesting side effect that comes from the ability to catch exceptions far away from where the exception was raised. A program thread can receive program exceptions from any active frame on its call stack without knowing where the exception was raised. But exceptions don't always represent an error condition that the program detects: a program thread can also cause an exception outside of the program.
If a thread's execution causes a processor to fault, then control is transferred to the operating system kernel, which presents the fault to the thread as an SEH exception. Just as your catch block doesn't know where on the thread's stack an exception was raised, it doesn't need to know exactly at what point the OS kernel raised the SEH exception.
Windows notifies program threads about OS exceptions using SEH. Managed code programmers will rarely see these because the CLR typically prevents the kinds of errors indicated by SEH exceptions. But if Windows raises an SEH exception, the CLR will deliver it to managed code. Although SEH exceptions in managed code are rare, unsafe managed code can generate a STATUS_ACCESS_VIOLATION which indicates that the program has attempted to access invalid memory.
For details on SEH, see Matt Pietrek's article "A Crash Course on the Depths of Win32 Structured Exception Handling" in the January 1997 issue of Microsoft Systems Journal.
SEH exceptions are a different class from those exceptions raised by your program. A program might raise an exception because it tried to pop an item from an empty stack or tried to open a file that didn't exist. All of these exceptions make sense in the context of your program's execution. SEH exceptions refer to a context outside of your program. An access violation (AV), for example, indicates an attempted write to invalid memory. Unlike program errors, an SEH exception indicates that the integrity of the runtime's process may have been compromised. But even though SEH exceptions are different from exceptions that derive from System.Exception, when the CLR delivers the SEH exception to a managed thread it can be caught with a catch (Exception e) statement.
Some systems attempt to separate these two kinds of exceptions. The Microsoft Visual C++ compiler distinguishes between exceptions raised by a C++ throw statement and Win32 SEH exceptions if you compile your program with the /EH switch. This separation is useful because a normal program doesn't know how to handle errors that it did not raise. If a C++ program tries to add an element to a std::vector, it should expect that the operation may fail due to lack of memory, but a correct program using well-written libraries shouldn't be expected to deal with an access violation.
This separation is useful for programmers. An AV is a serious problem: an unexpected write to critical system memory can affect any part of the process unpredictably. But some SEH errors, such as a divide-by-zero error resulting from bad (and unchecked) user input, are less serious. While a program with a divide-by-zero is incorrect, it's unlikely that this will affect any other part of the system. In fact, it's likely that a C++ program could handle a divide-by-zero error without destabilizing the rest of the system. So while this separation is useful, it doesn't quite express the semantics managed programmers need.
Managed Code and SEH
The CLR has always delivered SEH exceptions to managed code using the same mechanisms as exceptions raised by the program itself. This isn't a problem as long as code doesn't attempt to handle exceptional conditions that it cannot reasonably handle. Most programs cannot safely continue execution after an access violation. Unfortunately, the CLR's exception handling model has always encouraged users to catch these serious errors by allowing programs to catch any exception at the top of the System.Exception hierarchy. But this is rarely the right thing to do.
Writing catch (Exception e) is a common programming error because unhandled exceptions have serious consequences. But you might argue that if you don't know what errors will be raised by a function, you should protect against all possible errors when your program calls that function. This seems like a reasonable course of action until you think about what it means to continue execution when your process is possibly in a corrupted state. Sometimes aborting and trying again is the best option: nobody likes to see a Watson dialog, but it's better to restart your program than to have your data corrupted.
Programs catching exceptions arising from contexts they don't understand is a serious problem. But you can't solve the problem by using exceptions specifications or some other contract mechanism. And it's important that managed programs be able to receive notification of SEH exceptions because the CLR is a platform for many kinds of applications and hosts. Some hosts, such as SQL Server, need to have total control of their application's process. Managed code that interoperates with native code sometimes must deal with native C++ exceptions or SEH exceptions.
But most programmers who write catch (Exception e) don't really want to catch access violations. They'd prefer that execution of their program stops when a catastrophic error occurs rather than letting the program limp along in an unknown state. This is especially true for programs that host managed add-ins such as Visual Studio or Microsoft Office. If an add-in causes an access violation and then swallows the exception, the host could be doing damage to its own state (or user files) without ever realizing something went wrong.
In version 4 of the CLR, the product team is making exceptions that indicate a corrupted process state distinct from all other exceptions. We are designating about a dozen SEH exceptions to indicate corrupted process state. The designation is related to the context in which the exception is raised as opposed to the exception type itself. This means that an access violation received from Windows will be marked as a corrupted state exception (CSE), but one raised in user code by writing throw new System.AccessViolationException will not be marked as a CSE. If you attended PDC 2008, you received a Community Technology Preview of Visual Studio 2010 which includes these changes.
It's important to note that the exception doesn't corrupt the process: the exception is raised after corruption is detected in the process state. For example, when a write through a pointer in unsafe code references memory that doesn't belong to the program, an access violation is raised. The illegal write didn't actually occur—the operating system checked the memory's ownership and prevented the action from taking place. The access violation indicates that the pointer itself was corrupted at an earlier time in the thread's execution.
Corrupted State Exceptions
In version 4 and later, the CLR exception system will not deliver CSEs to managed code unless the code has expressly indicated that it can handle process corrupted state exceptions. This means that an instance of catch (Exception e) in managed code won't have the CSE presented to it. By making the change inside of the CLR exception system you don't need to change the exception hierarchy or alter any managed language's exception handling semantics.
For compatibility reasons, the CLR team provided some ways to let you run your old code under the old behavior:
- If you want to recompile your code created in the Microsoft .NET Framework 3.5 and run it in the .NET Framework 4.0 without having to update the source, you can add an entry in your application configuration file: legacyCorruptedStateExceptionsPolicy=true.
- Assemblies compiled against the .NET Framework 3.5 or an earlier version of the runtime will be able to process corrupted state exceptions (in other words, maintain the old behavior) when running on the .NET Framework 4.0.
If you want your code to handle CSEs, you must indicate your intention by marking the function containing the exceptions clause (catch, finally, or fault) with a new attribute:
System.Runtime.ExceptionServices.HandleProcessCorruptedStateExceptions. If a CSE is raised, the CLR will perform its search for a matching catch clause but will only search in functions marked with the HandleProcessCorruptedStateExceptions attribute (see Figure 2).
Figure 2 Using HandleProcessCorruptedStateExceptions
// This program runs as part of an automated test system so you need
// to prevent the normal Unhandled Exception behavior (Watson dialog).
// Instead, print out any exceptions and exit with an error code.
[HandleProcessCorruptedStateExceptions]
[SecurityCritical]
public static int Main()
{
try
{
// Catch any exceptions leaking out of the program CallMainProgramLoop();
}
catch (Exception e)
// We could be catching anything here
{
// The exception we caught could have been a program error
// or something much more serious. Regardless, we know that
// something is not right. We'll just output the exception
// and exit with an error. We won't try to do any work when
// the program or process is in an unknown state!
System.Console.WriteLine(e.Message);
return 1;
}
return 0;
}
If a suitable catch clause is found, the CLR will unwind the stack as normal but will only execute finally and fault blocks (and in C#, the implicit finally block of a using statement) in functions marked with the attribute. The HandleProcessCorruptedStateExceptions attribute is ignored when encountered in partially trusted or transparent code because a trusted host wouldn't want an untrusted add-in to catch and ignore these serious exceptions.
It's Still Wrong to Use Catch (Exception e)
Even though the CLR exception system marks the worst exceptions as CSE, it's still not a good idea to write catch (Exception e) in your code. Exceptions represent a whole spectrum of unexpected situations. The CLR can detect the worst exceptions—SEH exceptions that indicate a possibly corrupt process state. But other unexpected conditions can still be harmful if they are ignored or dealt with generically.
In the absence of process corruption, the CLR offers some pretty strong guarantees about program correctness and memory safety. When executing a program written in safe Microsoft Intermediate Language (MSIL) code you can be certain that all the instructions in your program will execute correctly. But doing what the program instructions say to do is often different from doing what the programmer wants. A program that is completely correct according to the CLR can corrupt persisted state, such as program files written to a disk.
Take as a simple example a program that manages a database of test scores for a high school. The program uses object-oriented design principles to encapsulate data and raises managed exceptions to indicate unexpected events. One day the school secretary hits the Enter key one too many times when generating a grade file. The program tries to pop a value from an empty queue and raises a QueueEmptyException which goes unhandled through frames on the callstack.
Somewhere near the top of the stack is a function, GenerateGrades(), with a try/catch clause that catches Exception. Unfortunately, GenerateGrades() has no idea that students are stored in a queue and doesn't have any idea what to do with a QueueEmptyException. But the programmer who wrote GenerateGrades() doesn't want the program to crash without saving the data that's been computed so far. Everything is written safely to the disk and the program exits.
The problem with this program is that it makes a number of assumptions that could be incorrect. What's to say that the missing entry in the student queue is at the end? Maybe the first student record got skipped, or the tenth. The exception only tells the programmer that the program is incorrect. Taking any action—saving data to disk or "recovering" and continuing execution—is just plain wrong. No correct action is possible without knowledge of the context in which the exception was raised.
If the program had caught a specific exception close to where the exception was raised, it might have been able to take proper action. The program knows what a QueueEmptyException means in the function that attempts to dequeue students. If the function catches that exception by type—rather than catching a whole class of exception types—it would be in a much better position to try to make the program state correct.
In general, catching a specific exception is the correct thing to do because it provides the most context to your exception handler. If your code can potentially catch two exceptions, then it has to be able to deal with both. Writing code that says catch (Exception e) has to be able to deal with literally any exceptional situation. That's a promise that is very hard to keep.
Some languages try to prevent programmers from catching a broad class of exceptions. For example, C++ has exception specifications, a mechanism that allows a programmer to specify what exceptions can be raised in that function. Java takes this a step further with checked exceptions, a compiler-enforced requirement that a certain class of exceptions be specified. In both languages, you list the exceptions that can flow out of this function in the function declaration and callers are required to handle those exceptions. Exception specifications are a good idea, but they have had mixed results in practice.
There's vigorous debate as to whether or not any managed code should be able to handle CSEs. These exceptions normally denote a systems-level error and should only be handled by code that understands the systems-level context. While most people don't need the ability to handle CSEs, there are a couple of scenarios where it's necessary.
One scenario is when you are very close to where the exception happened. For example, consider a program that calls native code that's known to be buggy. Debugging into the code you learn that it sometimes zeros a pointer before accessing it, which causes an access violation. You might want to use the HandleProcessCorruptedStateExceptions attribute on the function which calls native code using P/Invoke because you know the cause of the pointer corruption and are comfortable that the process integrity is maintained.
The other scenario that may call for the use of this attribute is when you're as far as you can be from the error. In fact, you're almost ready to exit your process. Say you've written a host or a framework that wants to perform some custom logging in case of an error. You might wrap your main function with a try/catch/finally block and mark it with HandleProcessCorruptedStateExceptions. If an error unexpectedly makes it all the way up to your program's main function, you write some data to your log, doing as little work as you have to, and exit the process. When the integrity of the process is in question any work you do could be dangerous, but if the custom logging fails sometimes it's acceptable.
Take a look at the diagram shown in Figure 3. Here function 1 (fn1()) is attributed with [HandleProcessCorruptedStateExceptions] so its catch clause catches the access violation. The finally block in function 3 does not execute even though the exception will be caught in function 1. Function 4 at the bottom of the stack raises an access violation.
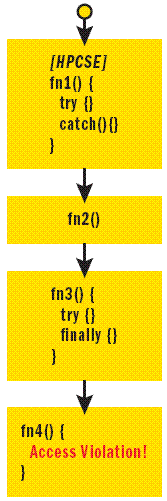
Figure 3 Exception and Access Violation
There is no guarantee in either of these scenarios that what you're doing is completely safe, but there are scenarios where just terminating the process is unacceptable. However, if you decide to handle a CSE there is a huge burden on you as the programmer to do it correctly. Remember that the CLR exception system won't even deliver a CSE to any function that is not marked with the new attribute either during the first pass (when it searches for a matching catch clause) or the second pass (when it unwinds each frame's state and executes finally and fault blocks).
The finally block exists in order to guarantee that code always runs, whether or not there is an exception. (Fault blocks run only when an exception occurs, but they have a similar guarantee of always being executed.) These constructs are used to clean up critical resources such as releasing file handles or reversing impersonation contexts.
Even code that is written to be reliable through the use of constrained execution regions (CER) won't be executed when a CSE has been raised unless it is in a function that has been marked with the HandleProcessCorruptedStateExceptions attribute. It's very difficult to write correct code that handles a CSE and continues running the process safely.
Look closely at the code in Figure 4 to see what could go wrong. If this code is not in a function that can process CSEs, then the finally block will not run when an access violation happens. That's fine if the process terminates—the open file handle will be released. But if some other code catches the access violation and tries to restore state, it needs to know that it has to close this file as well as restore any other external state this program has changed.
Figure 4 The Finally Block May Not Run
void ReadFile(int index)
{
System.IO.StreamReader file = new System.IO.StreamReader(filepath);
try
{
file.ReadBlock(buffer, index, buffer.Length);
}
catch (System.IO.IOException e)
{
Console.WriteLine("File Read Error!");
}
finally
{
if (file != null)
{
file.Close()
}
}
}
If you decide that you're going to handle a CSE, your code needs to expect that there is a ton of critical state that has not been unwound. Finally and fault blocks have not been run. Constrained execution regions have not been executed. The program—and the process—are in an unknown state.
If you know your code will do the right thing, then you know what to do. But if you're not sure of the state your program is executing in, then it's better to just let your process exit. Or, if your application is hosted, invoke the escalation policy your host has specified. See Alessandro Catorcini and Brian Grunkemeyer's CLR Inside Out column from December 2007 for more information on writing reliable code and CERs.
Code Wisely
Even though the CLR prevents you from naively catching CSEs, it's still not a good idea to catch overly broad classes of exceptions. But catch (Exception e) appears in a lot of code, and it's unlikely that this will change. By not delivering exceptions that represent a corrupted process state to code that naively catches all exceptions, you prevent this code from making a serious situation worse.
The next time you write or maintain code that catches an exception, think about what the exception means. Does the type you caught match what your program (and the libraries it uses) is documented to throw? Do you know how to handle the exception such that your program can correctly and safely continue execution?
Exception handling is a powerful tool that should be used carefully and thoughtfully. If you really need to use this feature—if you really need to handle exceptions that may indicate a corrupt process—the CLR will trust you and let you do so. Just be careful and do it correctly.
Send your questions and comments to clrinout@microsoft.com.
Andrew Pardoe is a program manager for CLR at Microsoft. He works on many aspects of the execution engine for both the desktop and Silverlight runtimes. He can be reached at Andrew.Pardoe@microsoft.com.