Query optimaliseren met behulp van taaksimulatie
Een manier om de prestaties van een ASA-taak (Azure Stream Analytics) te verbeteren, is door parallellisme toe te passen in query's. In dit artikel ziet u hoe u de taaksimulatie in de Azure Portal en Visual Studio Code (VS Code) gebruikt om de parallelle uitvoering van query's voor een Stream Analytics-taak te evalueren. U leert hoe u de uitvoering van een query met verschillende streaming-eenheden kunt visualiseren en de parallelle uitvoering van query's kunt verbeteren op basis van de bewerkingssuggesties.
Wat is parallelle query?
Queryparallellisme verdeelt de werkbelasting van een query door meerdere processen (of streamingknooppunten) te maken en parallel uit te voeren. Het vermindert de totale uitvoeringstijd van de query aanzienlijk en er zijn dus minder streaming-uren nodig.
Een taak kan alleen parallel worden uitgevoerd als alle invoer, uitvoer en querystappen zijn uitgelijnd en dezelfde partitiesleutels gebruiken. De partitionering van querylogica wordt bepaald door de sleutels die worden gebruikt voor aggregaties (GROUP BY).
Taaksimulatie gebruiken in VS Code
De functie Taaksimulatie simuleert hoe de taak topologie in Azure zou uitvoeren. In deze zelfstudie leert u hoe u queryprestaties kunt verbeteren op basis van suggesties voor bewerken en hoe u deze parallel kunt uitvoeren. Als voorbeeld gebruiken we een niet-parallel taak waarmee de invoergegevens van een Event Hub worden opgehaald en de resultaten naar een andere Event Hub worden verzonden.
Vereisten:
- ASA Tools-extensie voor VS Code. Als u deze nog niet hebt geïnstalleerd, volgt u deze handleiding om te installeren.
- Live-invoer en live-uitvoer configureren voor uw Stream Analytics-taak.
- U moet live-invoer en uitvoer opnemen in de query.
Notitie
De taaksimulatie kan de topologie voor lokale invoer en uitvoer niet simuleren. Er worden tijdens de simulatie geen gegevens naar de uitvoerbestemming verzonden.
Open het ASA-project in VS Code. Ga naar het querybestand *.asaql en selecteer Taak simuleren om taaksimulatie te starten.
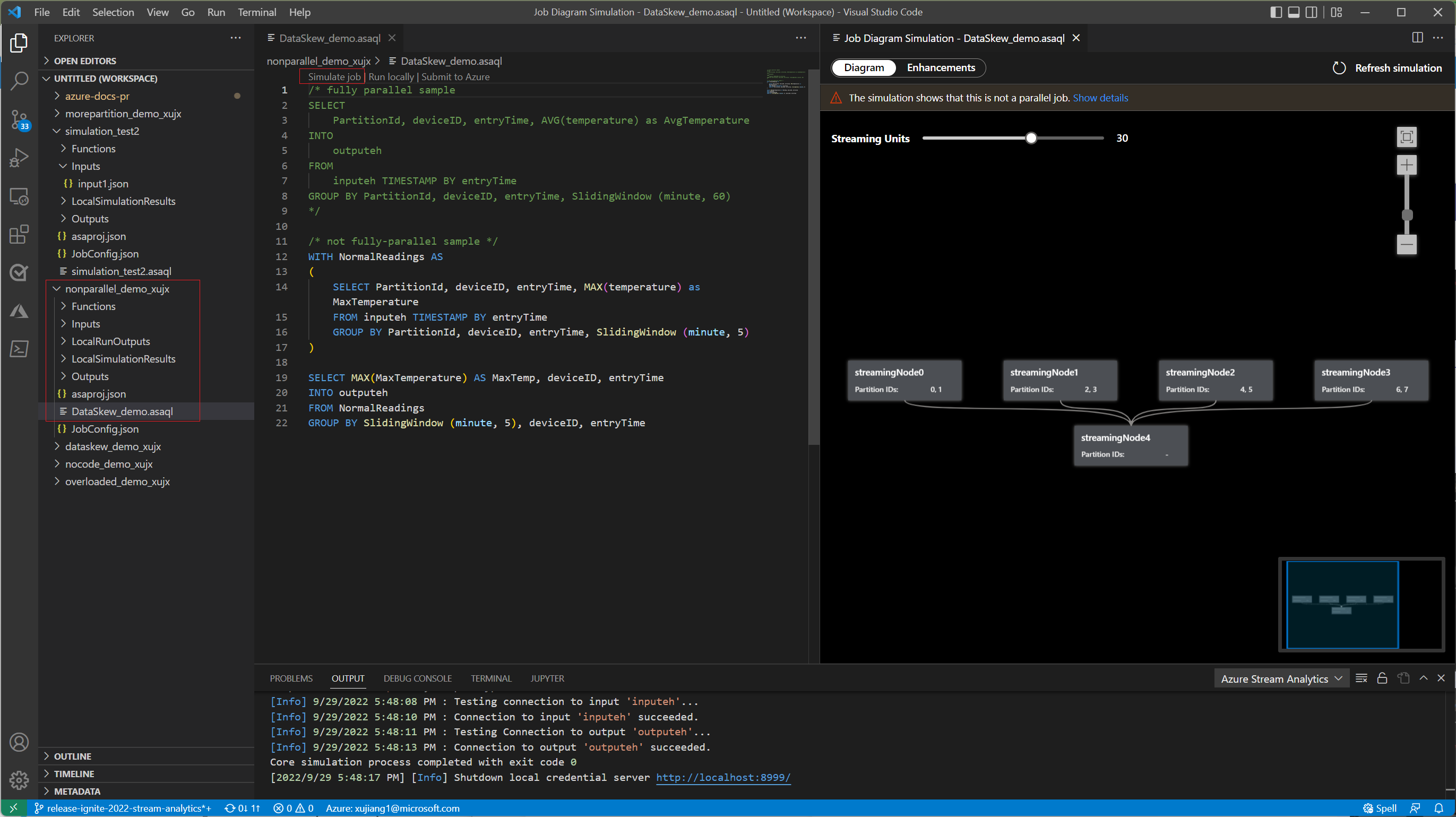
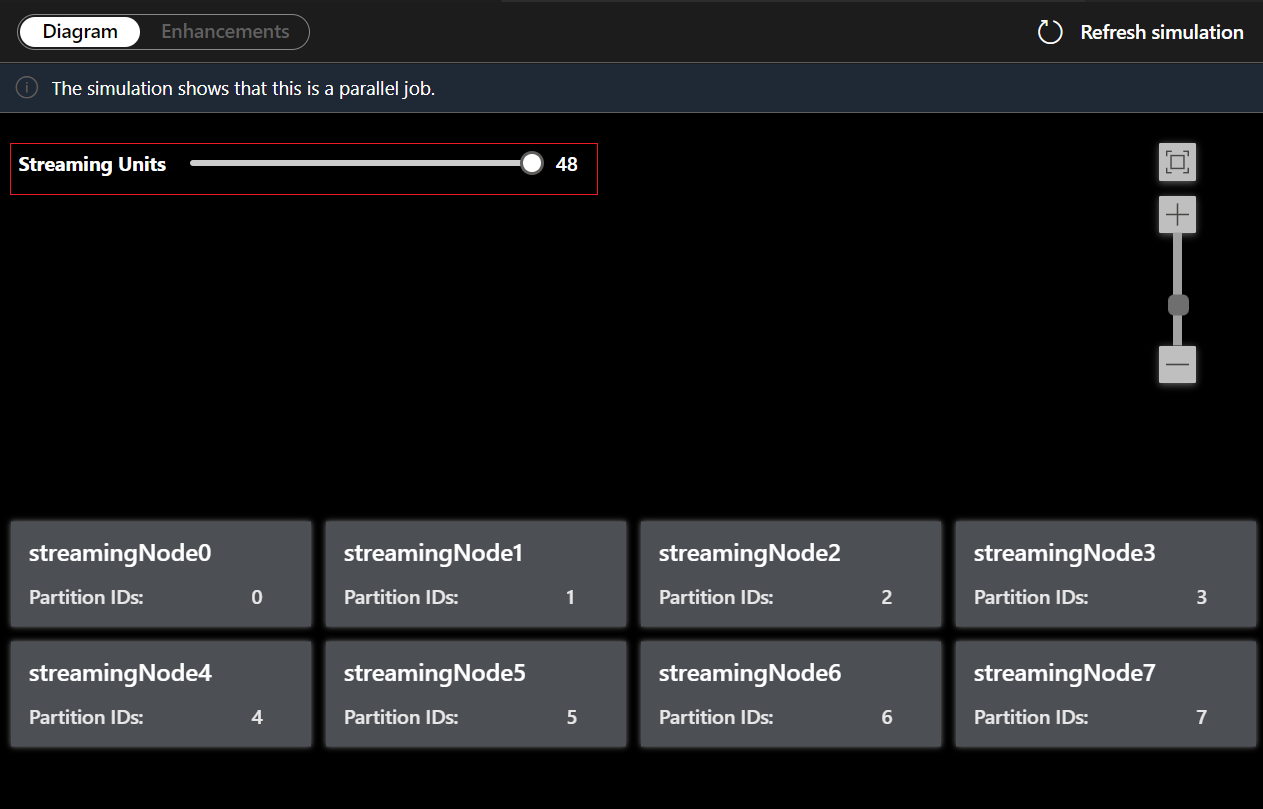
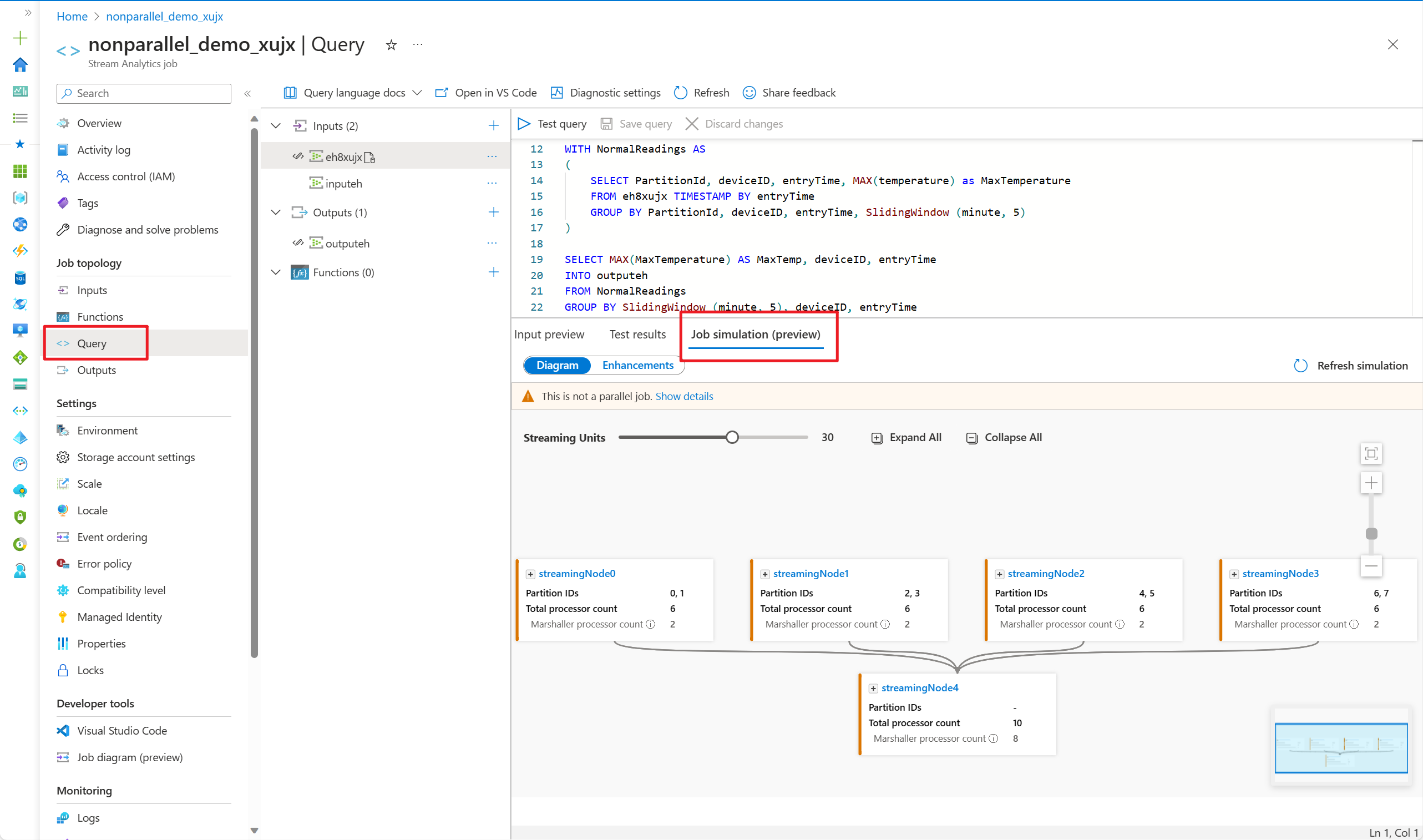
Op het tabblad Diagram ziet u het aantal streamingknooppunten dat is toegewezen aan de taak en het aantal partities in elk streamingknooppunt. De volgende schermopname is een voorbeeld van een niet-allel taak waarbij de gegevens tussen knooppunten stromen.
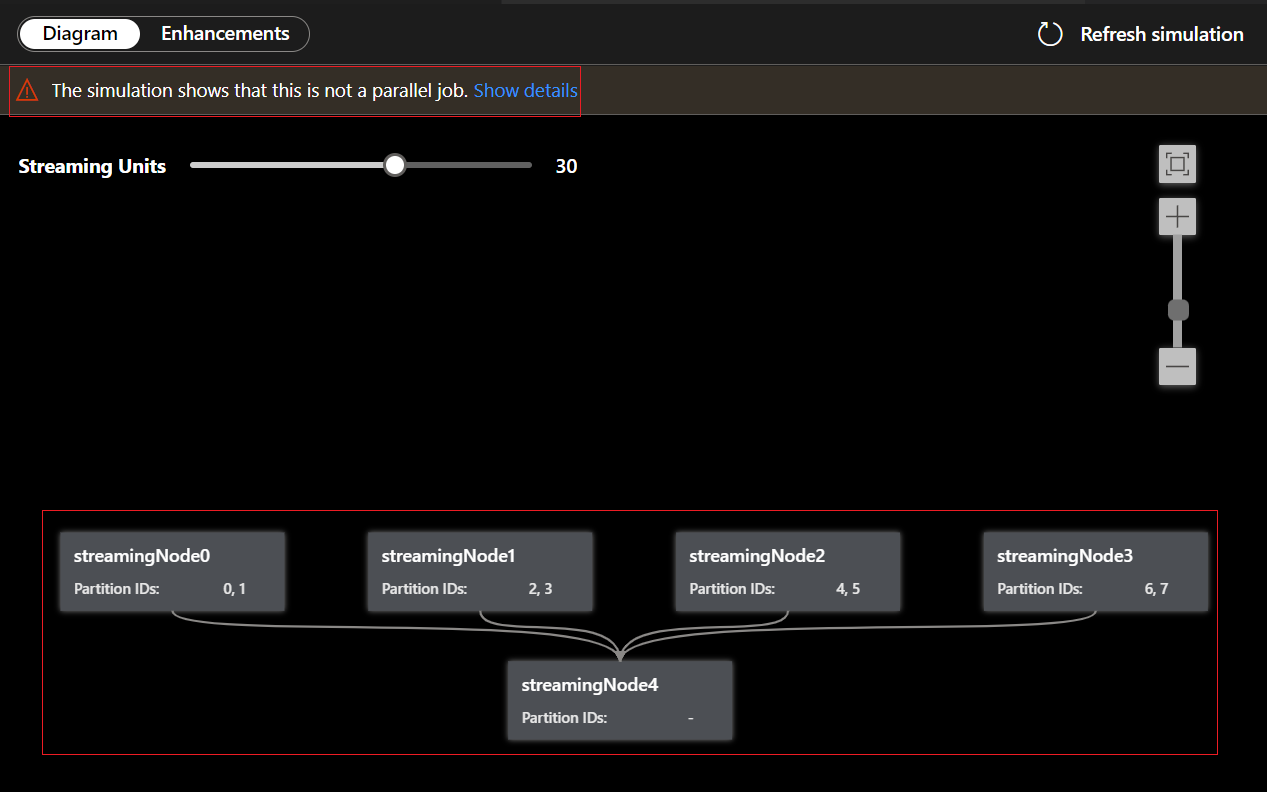
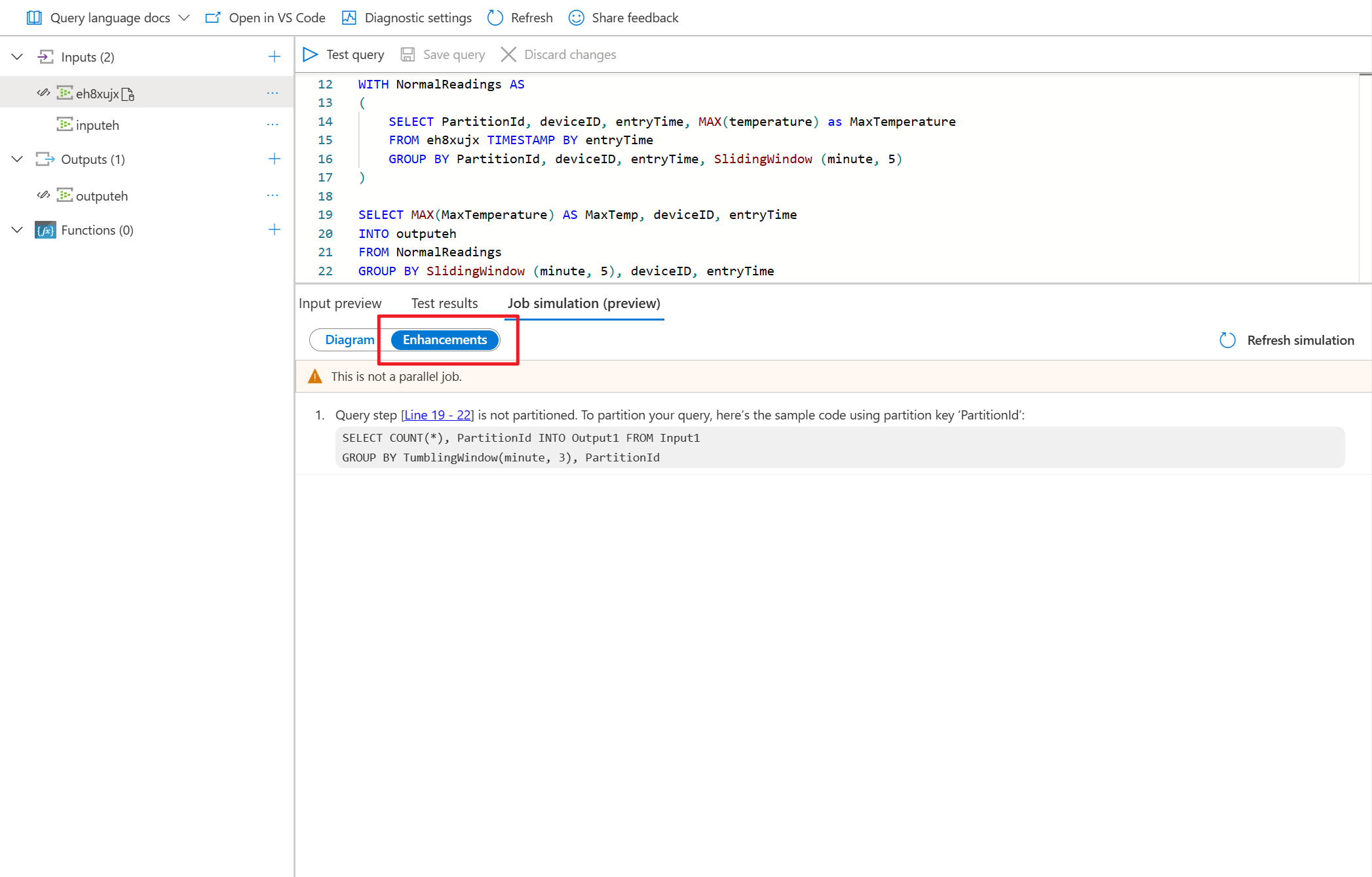
Omdat deze query NIET parallel is, kunt u het tabblad Verbeteringen selecteren om suggesties voor het verbeteren van de query weer te geven.

Selecteer querystap in de lijst met verbeteringen, u ziet dat de bijbehorende regels zijn gemarkeerd en u kunt de query bewerken op basis van de suggesties.
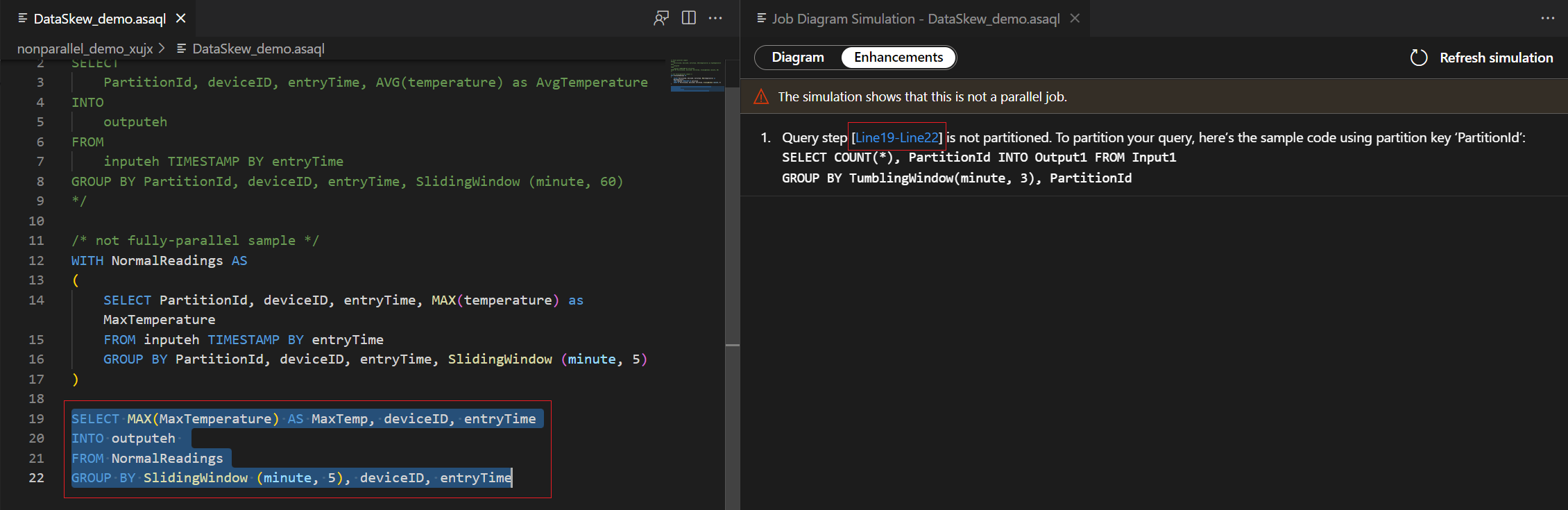
Notitie
Dit zijn bewerkingssuggesties voor het verbeteren van de parallelle uitvoering van query's. Als u echter een statistische functie gebruikt voor alle partities, is het mogelijk dat een parallelle query niet van toepassing is op uw scenario's.
In dit voorbeeld voegt u de PartitionId toe aan regel 22 en slaat u de wijziging op. Vervolgens kunt u de vernieuwingssimulatie gebruiken om het nieuwe diagram op te halen.
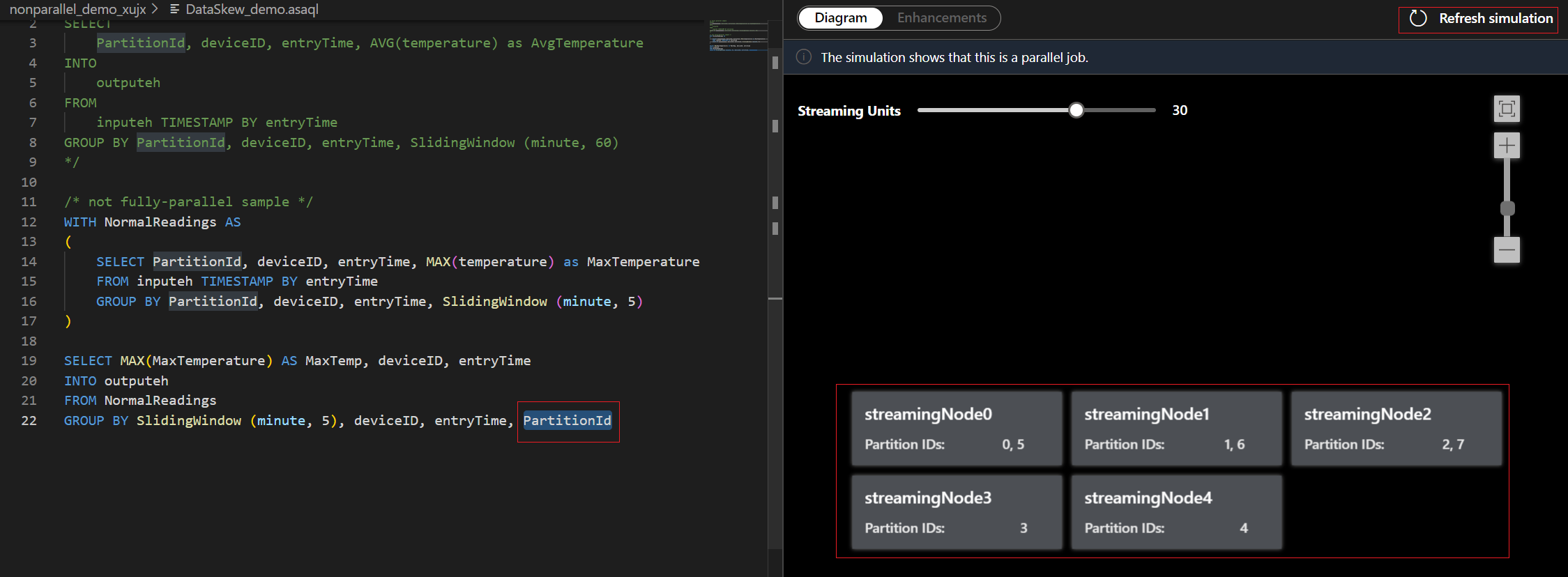
U kunt ook streaming-eenheden aanpassen om te stimuleren hoe streamingknooppunten worden toegewezen aan verschillende SUs. Het geeft u een idee van het aantal RU's dat u nodig hebt om uw workload te verwerken.






Taaksimulatie gebruiken in de Azure Portal
- Ga naar de query-editor in Azure Portal en selecteer Taaksimulatie in het onderste deelvenster. Hiermee wordt de taak uitgevoerde topologie gesimuleerd op basis van uw query en vooraf gedefinieerde streaming-eenheden.
- Selecteer Verbeteringen om de suggesties voor het verbeteren van de parallelle uitvoering van query's weer te geven.
- Pas de streaming-eenheden aan om te zien hoeveel RU's u nodig hebt voor het afhandelen van de workload.
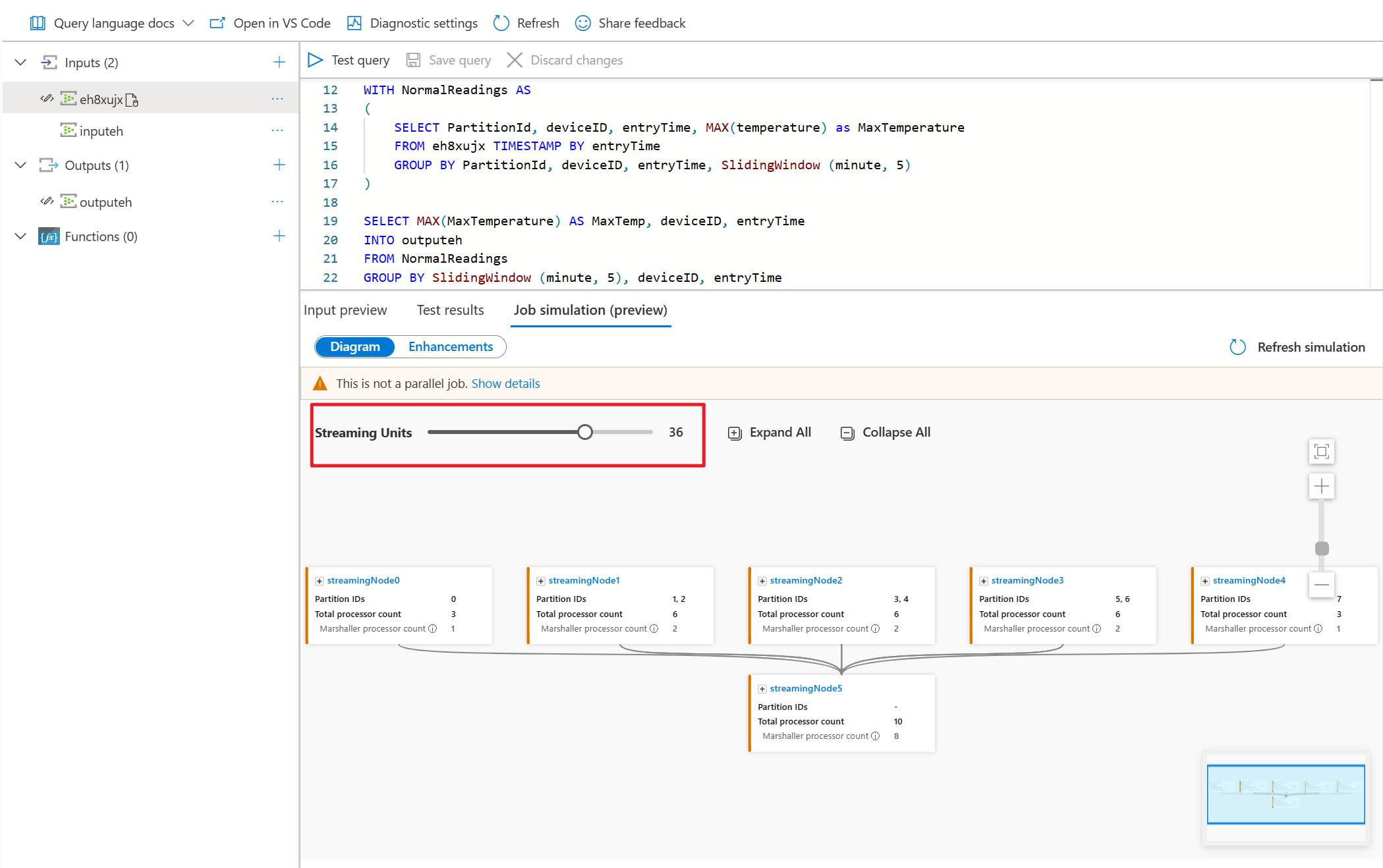



Diagram op processorniveau
Nadat u de streaming-eenheden hebt aangepast om de topologie van uw taak te simuleren, kunt u elk van de streamingknooppunten uitvouwen om te zien hoe uw gegevens op processorniveau worden verwerkt.

Met het diagram op processorniveau kunt u het volgende doen:
- bekijk hoe de invoerpartities worden toegewezen en verwerkt op elk streamingknooppunt.
- ontdek wat de tijdsverschuiving is voor elke computerprocessor.
- geef informatie op over of de invoer- en uitvoerprocessors parallel zijn uitgelijnd.
Als u de processor wilt toewijzen aan de querystap, selecteert u het diagram. Met deze functie kunt u de querystappen voor het samenvoegen vinden.

Suggesties voor verbetering
Hier volgen de verklaringen voor verbeteringen:
| Type | Betekenis |
|---|---|
| Aangepaste partitie wordt niet ondersteund | Wijzig de invoer 'xxx'-partitiesleutel in 'xxx'. |
| Aantal partities dat niet overeenkomt | Invoer en uitvoer moeten hetzelfde aantal partities hebben. |
| Partitiesleutels komen niet overeen | Invoer, uitvoer en elke querystap moeten dezelfde partitiesleutel gebruiken. |
| Aantal invoerpartities dat niet overeenkomt | Alle invoer moet hetzelfde aantal partities hebben. |
| Invoerpartitiesleutels komen niet overeen | Alle invoer moet dezelfde partitiesleutel gebruiken. |
| Laag compatibiliteitsniveau | Upgrade CompatibilityLevel in bestand JobConfig.json . |
| De uitvoerpartitiesleutel is niet gevonden | U moet de opgegeven partitiesleutel gebruiken voor de uitvoer. |
| Aangepaste partitie wordt niet ondersteund | U kunt alleen vooraf gedefinieerde partitiesleutels gebruiken. |
| Querystap maakt geen gebruik van partitie | Uw query maakt geen gebruik van een PARTITION BY-component. |
Volgende stappen
Als u meer wilt weten over parallelle uitvoering van query's en taakdiagrammen, bekijkt u deze zelfstudies: