Brokerinstellingen configureren voor hoge beschikbaarheid, schaalaanpassing en geheugengebruik
De Broker-resource is de belangrijkste resource die de algemene instellingen voor MQTT-broker definieert. Het bepaalt ook het aantal en het type pods waarop de Broker-configuratie wordt uitgevoerd, zoals de front-ends en de back-ends. U kunt de Broker-resource ook gebruiken om het geheugenprofiel te configureren. Zelfherstelmechanismen zijn ingebouwd in de broker en het kan vaak automatisch herstellen van onderdeelfouten. Een knooppunt mislukt bijvoorbeeld in een Kubernetes-cluster dat is geconfigureerd voor hoge beschikbaarheid.
U kunt de MQTT-broker horizontaal schalen door meer front-endreplica's en back-endpartities toe te voegen. De front-endreplica's zijn verantwoordelijk voor het accepteren van MQTT-verbindingen van clients en het doorsturen ervan naar de back-endpartities. De back-endpartities zijn verantwoordelijk voor het opslaan en leveren van berichten aan de clients. De front-endpods verdelen berichtverkeer over de back-endpods en de back-endredundantiefactor bepaalt het aantal gegevenskopieën om tolerantie te bieden tegen knooppuntfouten in het cluster.
Zie de broker-API-verwijzing voor een lijst met de beschikbare instellingen.
Schaalinstellingen configureren
Belangrijk
Deze instelling vereist het wijzigen van de Broker-resource en kan alleen worden geconfigureerd tijdens de eerste implementatie met behulp van de Azure CLI of Azure Portal. Er is een nieuwe implementatie vereist als brokerconfiguratiewijzigingen nodig zijn. Zie Standaardbroker aanpassen voor meer informatie.
Als u de schaalinstellingen van MQTT Broker wilt configureren, geeft u de kardinaliteitsvelden op in de specificatie van de Broker-resource tijdens de implementatie van Azure IoT Operations.
Automatische implementatiekardinaliteit
Als u automatisch de initiële kardinaliteit tijdens de implementatie wilt bepalen, laat u het kardinaliteitsveld in de Broker-resource weg.
Automatische kardinaliteit wordt nog niet ondersteund bij het implementeren van De Azure IoT-bewerkingen via Azure Portal. U kunt de clusterimplementatiemodus echter handmatig opgeven als één knooppunt of meerdere knooppunten. Zie Azure IoT-bewerkingen implementeren voor meer informatie.
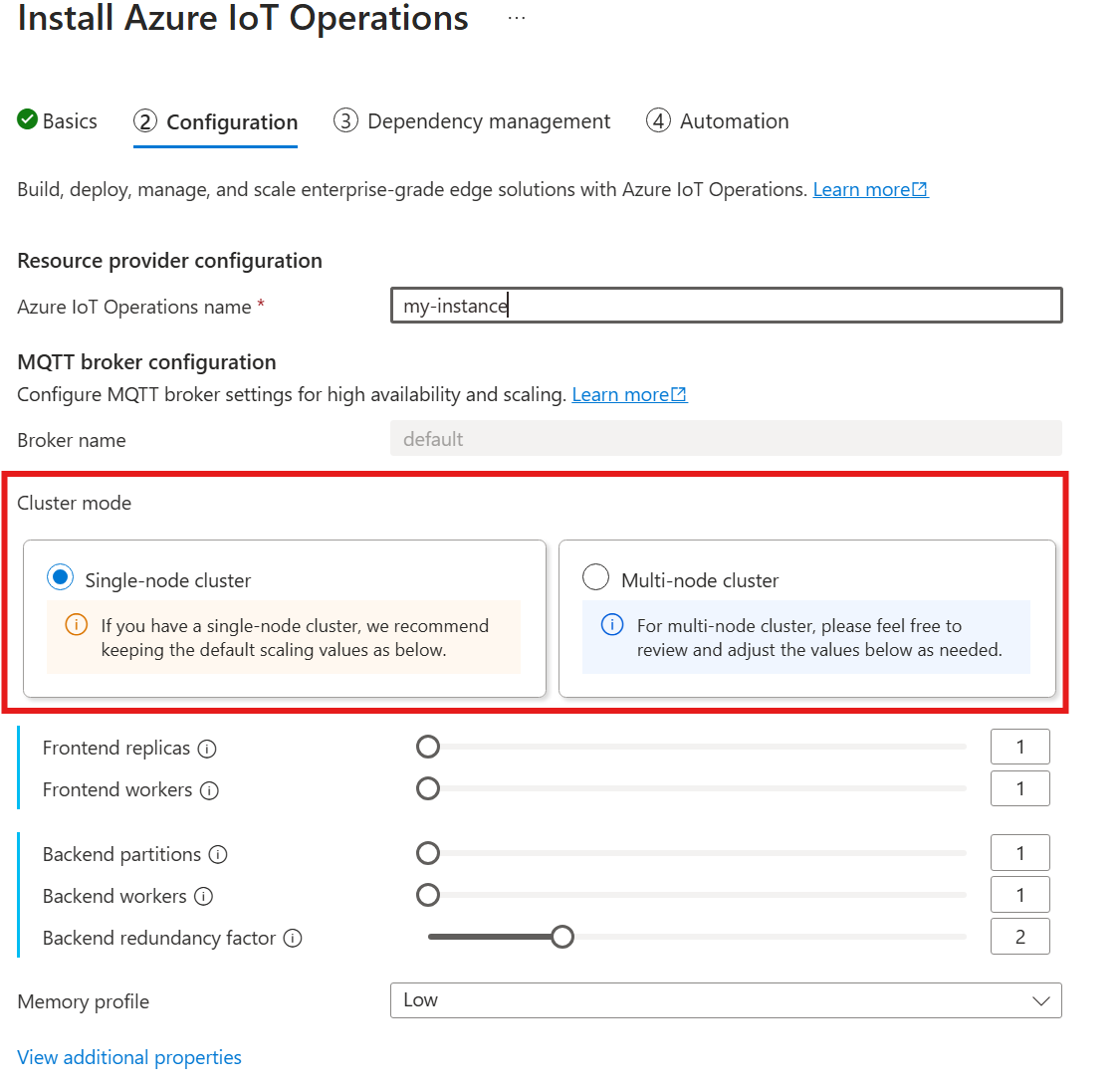
De MQTT-brokeroperator implementeert automatisch het juiste aantal pods op basis van het aantal beschikbare knooppunten op het moment van de implementatie. Dit is handig voor niet-productiescenario's waarbij u geen hoge beschikbaarheid of schaal nodig hebt.
Dit is echter niet automatisch schalen. De operator schaalt niet automatisch het aantal pods op basis van de belasting. De operator bepaalt alleen het eerste aantal pods dat moet worden geïmplementeerd op basis van de clusterhardware. Zoals eerder vermeld, kan de kardinaliteit alleen worden ingesteld tijdens de eerste implementatie en is een nieuwe implementatie vereist als de kardinaliteitsinstellingen moeten worden gewijzigd.
Kardinaliteit rechtstreeks configureren
Als u de kardinaliteitsinstellingen rechtstreeks wilt configureren, geeft u elk van de kardinaliteitsvelden op.
Wanneer u de volgende handleiding volgt voor het implementeren van Azure IoT-bewerkingen, kijkt u in de sectie Configuratie onder de MQTT-brokerconfiguratie. Hier kunt u het aantal front-endreplica's, back-endpartities en back-endmedewerkers opgeven.
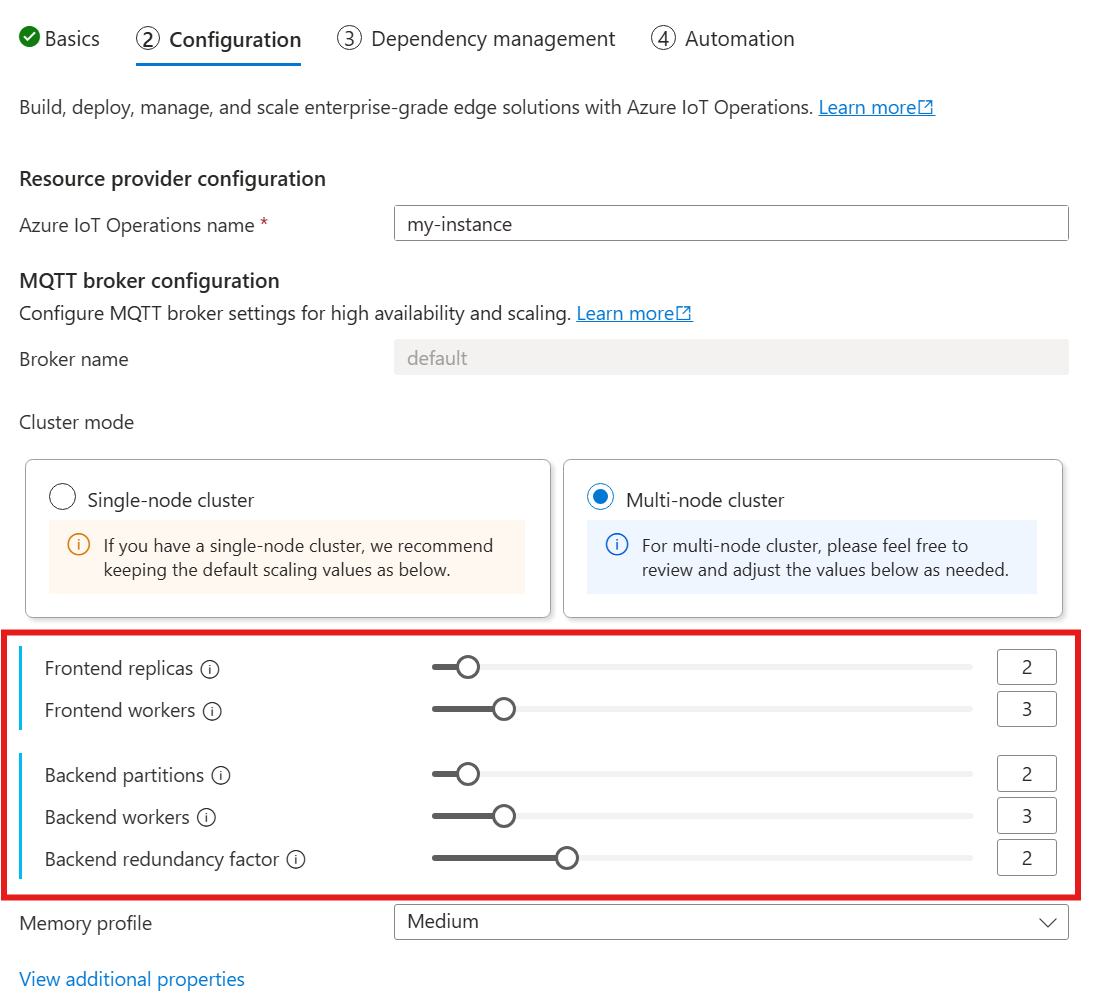
Inzicht in kardinaliteit
Kardinaliteit betekent het aantal exemplaren van een bepaalde entiteit in een set. In de context van de MQTT-broker verwijst kardinaliteit naar het aantal front-endreplica's, back-endpartities en back-endmedewerkers die moeten worden geïmplementeerd. De kardinaliteitsinstellingen worden gebruikt om de broker horizontaal te schalen en hoge beschikbaarheid te verbeteren als er pod- of knooppuntfouten zijn.
Het kardinaliteitsveld is een genest veld, met subvelden voor front-end en back-endchain. Elk van deze subvelden heeft zijn eigen instellingen.
Front-end
Het subveld van de front-end definieert de instellingen voor de front-endpods. De twee belangrijkste instellingen zijn:
Replica's: het aantal front-endreplica's (pods) dat moet worden geïmplementeerd. Het verhogen van het aantal front-endreplica's biedt hoge beschikbaarheid als een van de front-endpods mislukt.
Werkrollen: het aantal logische front-endwerkers per replica. Elke werkrol kan maximaal één CPU-kern verbruiken.
Back-endketen
Het subveld back-endketen definieert de instellingen voor de back-endpartities. De drie belangrijkste instellingen zijn:
Partities: het aantal partities dat moet worden geïmplementeerd. Via een proces met de naam sharding is elke partitie verantwoordelijk voor een deel van de berichten, gedeeld door onderwerp-id en sessie-id. De front-endpods verdelen berichtverkeer over de partities. Door het aantal partities te verhogen, wordt het aantal berichten dat de broker kan verwerken, verhoogd.
Redundantiefactor: het aantal back-endreplica's (pods) dat per partitie moet worden geïmplementeerd. Het verhogen van de redundantiefactor verhoogt het aantal gegevenskopieën om tolerantie te bieden tegen knooppuntfouten in het cluster.
Werkrollen: het aantal werkrollen dat per back-endreplica moet worden geïmplementeerd. Als u het aantal werkrollen per back-endreplica verhoogt, kan het aantal berichten dat door de back-endpod kan worden verwerkt, toenemen. Elke werkrol kan maximaal twee CPU-kernen verbruiken, dus wees voorzichtig bij het verhogen van het aantal werkrollen per replica om het aantal CPU-kernen in het cluster niet te overschrijden.
Overwegingen
Wanneer u de kardinaliteitswaarden verhoogt, wordt de capaciteit van de broker voor het afhandelen van meer verbindingen en berichten over het algemeen verbeterd en wordt de hoge beschikbaarheid verbeterd als er pod- of knooppuntfouten optreden. Dit leidt echter ook tot een hoger resourceverbruik. Houd bij het aanpassen van kardinaliteitswaarden rekening met de instellingen van het geheugenprofiel en de CPU-resourceaanvragen van de broker. Het verhogen van het aantal werkrollen per front-endreplica kan helpen het CPU-kerngebruik te verhogen als u ontdekt dat het CPU-gebruik van front-end een knelpunt is. Het verhogen van het aantal back-endmedewerkers kan helpen bij de doorvoer van berichten als back-end-CPU een knelpunt is.
Als uw cluster bijvoorbeeld drie knooppunten heeft, elk met acht CPU-kernen, stelt u het aantal front-endreplica's in op het aantal knooppunten (3) en stelt u het aantal werkrollen in op 1. Stel het aantal back-endpartities in op het aantal knooppunten (3) en back-endwerkrollen op 1. Stel de redundantiefactor naar wens in (2 of 3). Verhoog het aantal front-endwerkers als u ontdekt dat front-end-CPU een knelpunt is. Houd er rekening mee dat back-end- en front-endmedewerkers met elkaar en andere pods kunnen concurreren voor CPU-resources.
Geheugenprofiel configureren
Belangrijk
Deze instelling vereist het wijzigen van de Broker-resource en kan alleen worden geconfigureerd tijdens de eerste implementatie met behulp van de Azure CLI of Azure Portal. Er is een nieuwe implementatie vereist als brokerconfiguratiewijzigingen nodig zijn. Zie Standaardbroker aanpassen voor meer informatie.
Als u de geheugenprofielinstellingen MQTT Broker wilt configureren, geeft u de geheugenprofielvelden op in de specificatie van de Broker-resource tijdens de implementatie van Azure IoT Operations.
Wanneer u de volgende handleiding volgt voor het implementeren van Azure IoT-bewerkingen, kijkt u in de sectie Configuratie onder de MQTT-brokerconfiguratie en zoekt u de instelling voor het geheugenprofiel . Hier kunt u kiezen uit de beschikbare geheugenprofielen in een vervolgkeuzelijst.
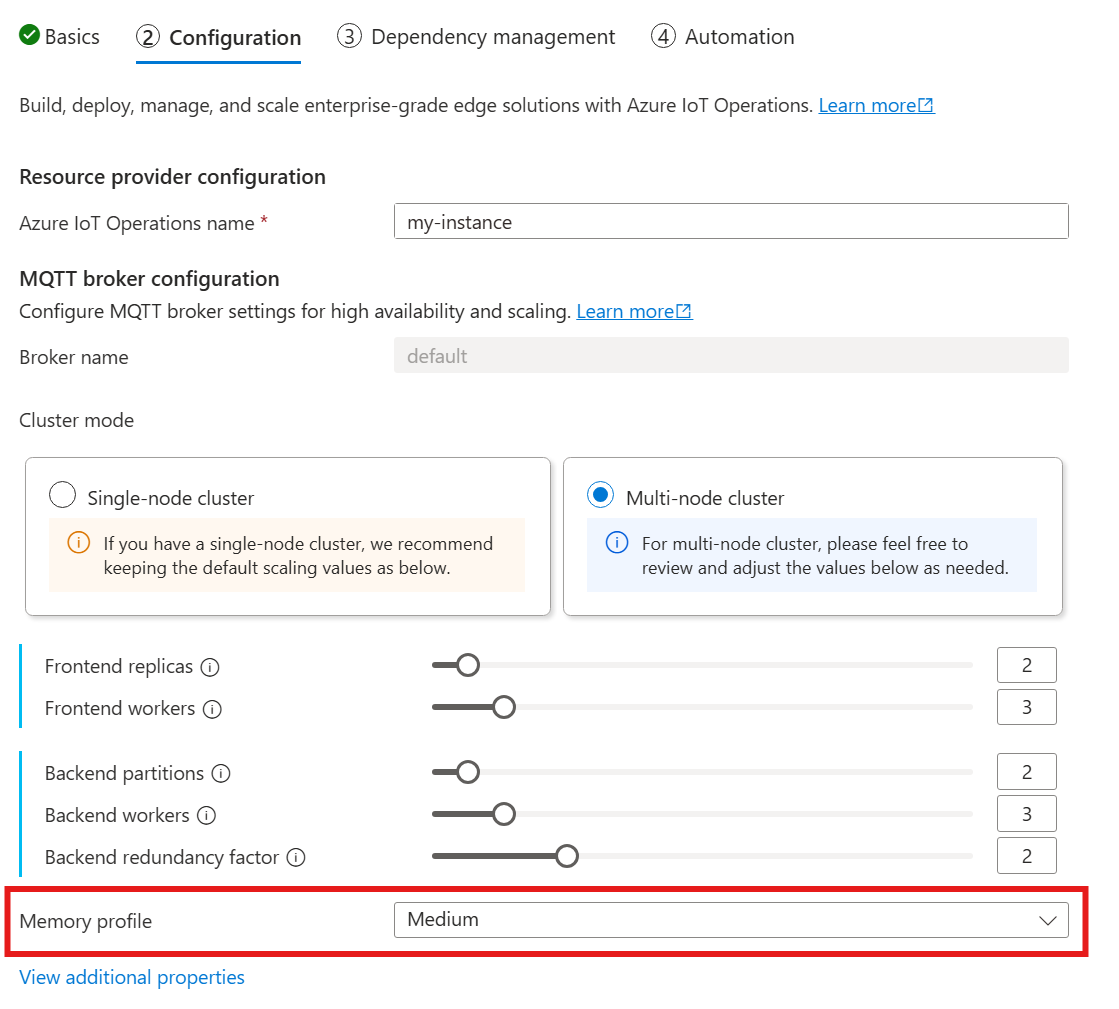
Er zijn enkele geheugenprofielen waaruit u kunt kiezen, elk met verschillende kenmerken van geheugengebruik.
Piepklein
Wanneer u dit profiel gebruikt:
- Het maximale geheugengebruik van elke front-endreplica is ongeveer 99 MiB, maar het werkelijke maximale geheugengebruik kan hoger zijn.
- Het maximale geheugengebruik van elke back-endreplica is ongeveer 102 MiB vermenigvuldigd met het aantal back-endmedewerkers, maar het werkelijke maximale geheugengebruik kan hoger zijn.
Aanbevelingen bij het gebruik van dit profiel:
- Er mag slechts één front-end worden gebruikt.
- Clients mogen geen grote pakketten verzenden. U moet alleen pakketten verzenden die kleiner zijn dan 4 MiB.
Beperkt
Wanneer u dit profiel gebruikt:
- Het maximale geheugengebruik van elke front-endreplica is ongeveer 387 MiB, maar het werkelijke maximale geheugengebruik kan hoger zijn.
- Het maximale geheugengebruik van elke back-endreplica is ongeveer 390 MiB vermenigvuldigd met het aantal back-endmedewerkers, maar het werkelijke maximale geheugengebruik kan hoger zijn.
Aanbevelingen bij het gebruik van dit profiel:
- Er moeten slechts één of twee front-ends worden gebruikt.
- Clients mogen geen grote pakketten verzenden. U moet alleen pakketten verzenden die kleiner zijn dan 10 MiB.
Gemiddeld
Gemiddeld is het standaardprofiel.
- Het maximale geheugengebruik van elke front-endreplica is ongeveer 1,9 GiB, maar het werkelijke maximale geheugengebruik kan hoger zijn.
- Het maximale geheugengebruik van elke back-endreplica is ongeveer 1,5 GiB vermenigvuldigd met het aantal back-endmedewerkers, maar het werkelijke maximale geheugengebruik kan hoger zijn.
Hoog
- Het maximale geheugengebruik van elke front-endreplica is ongeveer 4,9 GiB, maar het werkelijke maximale geheugengebruik kan hoger zijn.
- Het maximale geheugengebruik van elke back-endreplica is ongeveer 5,8 GiB vermenigvuldigd met het aantal back-endmedewerkers, maar het werkelijke maximale geheugengebruik kan hoger zijn.
Kardinaliteit en Kubernetes-resourcelimieten
Als u wilt voorkomen dat resources in het cluster worden verhongerd, wordt de broker standaard geconfigureerd om Kubernetes CPU-resourcelimieten aan te vragen. Door het aantal replica's of werkrollen proportioneel te schalen, worden de vereiste CPU-resources verhoogd. Er wordt een implementatiefout gegenereerd als er onvoldoende CPU-resources beschikbaar zijn in het cluster. Dit helpt situaties te voorkomen waarin de aangevraagde brokerkardinaliteit onvoldoende resources heeft om optimaal te worden uitgevoerd. Het helpt ook om mogelijke CPU-conflicten en podverzettingen te voorkomen.
MQTT Broker vraagt momenteel één (1.0) CPU-eenheid per front-end worker aan en twee (2.0) CPU-eenheden per back-end worker. Zie Kubernetes CPU-resource-eenheden voor meer informatie.
De onderstaande kardinaliteit vraagt bijvoorbeeld de volgende CPU-resources aan:
- Voor front-ends: 2 CPU-eenheden per front-endpod, in totaal 6 CPU-eenheden.
- Voor back-ends: 4 CPU-eenheden per back-endpod (voor twee back-endwerkers), keer 2 (redundantiefactor), keer 3 (aantal partities), in totaal 24 CPU-eenheden.
{
"cardinality": {
"frontend": {
"replicas": 3,
"workers": 2
},
"backendChain": {
"partitions": 3,
"redundancyFactor": 2,
"workers": 2
}
}
}
Als u deze instelling wilt uitschakelen, stelt u het generateResourceLimits.cpu veld Disabled in op de Broker-resource.
Het wijzigen van het generateResourceLimits veld wordt niet ondersteund in Azure Portal. Als u deze instelling wilt uitschakelen, gebruikt u de Azure CLI.
Implementatie met meerdere knooppunten
Om hoge beschikbaarheid en tolerantie met implementaties met meerdere knooppunten te garanderen, stelt de Azure IoT Operations MQTT-broker automatisch antiaffiniteitsregels in voor back-endpods.
Deze regels zijn vooraf gedefinieerd en kunnen niet worden gewijzigd.
Doel van antiaffiniteitsregels
De antiaffiniteitsregels zorgen ervoor dat back-endpods van dezelfde partitie niet op hetzelfde knooppunt worden uitgevoerd. Dit helpt bij het distribueren van de belasting en biedt tolerantie tegen knooppuntfouten. Back-endpods van dezelfde partitie hebben met name antiaffiniteit met elkaar.
Instellingen voor antiaffiniteit controleren
Gebruik de volgende opdracht om de antiaffiniteitsinstellingen voor een back-endpod te controleren:
kubectl get pod aio-broker-backend-1-0 -n azure-iot-operations -o yaml | grep affinity -A 15
In de uitvoer wordt de antiaffiniteitsconfiguratie weergegeven, vergelijkbaar met de volgende:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- podAffinityTerm:
labelSelector:
matchExpressions:
- key: chain-number
operator: In
values:
- "1"
topologyKey: kubernetes.io/hostname
weight: 100
Dit zijn de enige antiaffiniteitsregels die zijn ingesteld voor de broker.