Gegevensstroomeindpunten configureren
Belangrijk
Deze pagina bevat instructies voor het beheren van Azure IoT Operations-onderdelen met behulp van Kubernetes-implementatiemanifesten, die in preview zijn. Deze functie is voorzien van verschillende beperkingen en mag niet worden gebruikt voor productieworkloads.
Raadpleeg de Aanvullende voorwaarden voor Microsoft Azure-previews voor juridische voorwaarden die van toepassing zijn op Azure-functies die in bèta of preview zijn of die anders nog niet algemeen beschikbaar zijn.
Maak eerst eindpunten voor gegevensstromen om aan de slag te gaan met gegevensstromen. Een gegevensstroomeindpunt is het verbindingspunt voor de gegevensstroom. U kunt een eindpunt gebruiken als bron of bestemming voor de gegevensstroom. Sommige eindpunttypen kunnen worden gebruikt als zowel bronnen als bestemmingen, terwijl andere alleen voor bestemmingen zijn. Een gegevensstroom heeft ten minste één broneindpunt en één doeleindpunt nodig.
Gebruik de volgende tabel om het eindpunttype te kiezen dat u wilt configureren:
| Eindpunttype | Beschrijving | Kan worden gebruikt als bron | Kan als bestemming worden gebruikt |
|---|---|---|---|
| MQTT | Voor bidirectionele berichten met MQTT-brokers, inclusief de ingebouwde functie voor Azure IoT Operations en Event Grid. | Ja | Ja |
| Kafka | Voor bidirectionele berichten met Kafka-brokers, waaronder Azure Event Hubs. | Ja | Ja |
| Data Lake | Voor het uploaden van gegevens naar Azure Data Lake Gen2-opslagaccounts. | Nr. | Ja |
| Microsoft Fabric OneLake | Voor het uploaden van gegevens naar Microsoft Fabric OneLake Lakehouses. | Nr. | Ja |
| Azure Data Explorer | Voor het uploaden van gegevens naar Azure Data Explorer-databases. | Nr. | Ja |
| Lokale opslag | Voor het verzenden van gegevens naar een lokaal beschikbaar permanent volume, waarmee u gegevens kunt uploaden via Azure Container Storage die is ingeschakeld door Azure Arc Edge-volumes. | Nr. | Ja |
Belangrijk
Voor opslageindpunten is een schema voor serialisatie vereist. Als u een gegevensstroom wilt gebruiken met Microsoft Fabric OneLake, Azure Data Lake Storage, Azure Data Explorer of Lokale opslag, moet u een schemaverwijzing opgeven.
Als u het schema wilt genereren op basis van een voorbeeldgegevensbestand, gebruikt u de Helper voor Schema Gen.
Gegevensstromen moeten een lokaal MQTT-broker-eindpunt gebruiken
Wanneer u een gegevensstroom maakt, geeft u de bron- en doeleindpunten op. De gegevensstroom verplaatst gegevens van het broneindpunt naar het doeleindpunt. U kunt hetzelfde eindpunt gebruiken voor meerdere gegevensstromen en u kunt hetzelfde eindpunt gebruiken als zowel de bron als het doel in een gegevensstroom.
Het gebruik van aangepaste eindpunten als bron en bestemming in een gegevensstroom wordt echter niet ondersteund. Deze beperking betekent dat de ingebouwde MQTT-broker in Azure IoT Operations ten minste één eindpunt moet zijn. Dit kan de bron, het doel of beide zijn. Gebruik het standaard-MQTT-gegevensstroomeindpunt als de bron of bestemming voor elke gegevensstroom om fouten in de implementatie van gegevensstromen te voorkomen.
De specifieke vereiste is dat elke gegevensstroom de bron of het doel moet hebben geconfigureerd met een MQTT-eindpunt met de host aio-broker. Het is dus niet strikt vereist om het standaardeindpunt te gebruiken en u kunt extra gegevensstroomeindpunten maken die verwijzen naar de lokale MQTT-broker zolang de host is aio-broker. Om verwarring en beheerbaarheidsproblemen te voorkomen, is het standaardeindpunt echter de aanbevolen benadering.
In de volgende tabel ziet u de ondersteunde scenario's:
| Scenario | Ondersteund |
|---|---|
| Standaardeindpunt als bron | Ja |
| Standaardeindpunt als doel | Ja |
| Aangepast eindpunt als bron | Ja, als de bestemming een standaardeindpunt of een MQTT-eindpunt met host is aio-broker |
| Aangepast eindpunt als bestemming | Ja, als de bron standaardeindpunt of een MQTT-eindpunt met host is aio-broker |
| Aangepast eindpunt als bron en doel | Nee, tenzij een van deze eindpunten een MQTT-eindpunt met host is aio-broker |
Eindpunten opnieuw gebruiken
U kunt elk gegevensstroomeindpunt beschouwen als een bundel configuratie-instellingen die de gegevens bevatten waarvandaan de gegevens afkomstig moeten zijn of naar (de host waarde) moeten gaan, hoe u moet verifiëren met het eindpunt en andere instellingen, zoals TLS-configuratie of batchverwerkingsvoorkeur. U hoeft deze dus maar één keer te maken en vervolgens kunt u deze opnieuw gebruiken in meerdere gegevensstromen waar deze instellingen hetzelfde zouden zijn.
Om het gemakkelijker te maken eindpunten opnieuw te gebruiken, maakt het onderwerpfilter MQTT of Kafka geen deel uit van de eindpuntconfiguratie. In plaats daarvan geeft u het onderwerpfilter op in de configuratie van de gegevensstroom. Dit betekent dat u hetzelfde eindpunt kunt gebruiken voor meerdere gegevensstromen die gebruikmaken van verschillende onderwerpfilters.
U kunt bijvoorbeeld het standaardeindpunt van de MQTT-brokergegevensstroom gebruiken. U kunt deze gebruiken voor zowel de bron als de bestemming met verschillende onderwerpfilters:
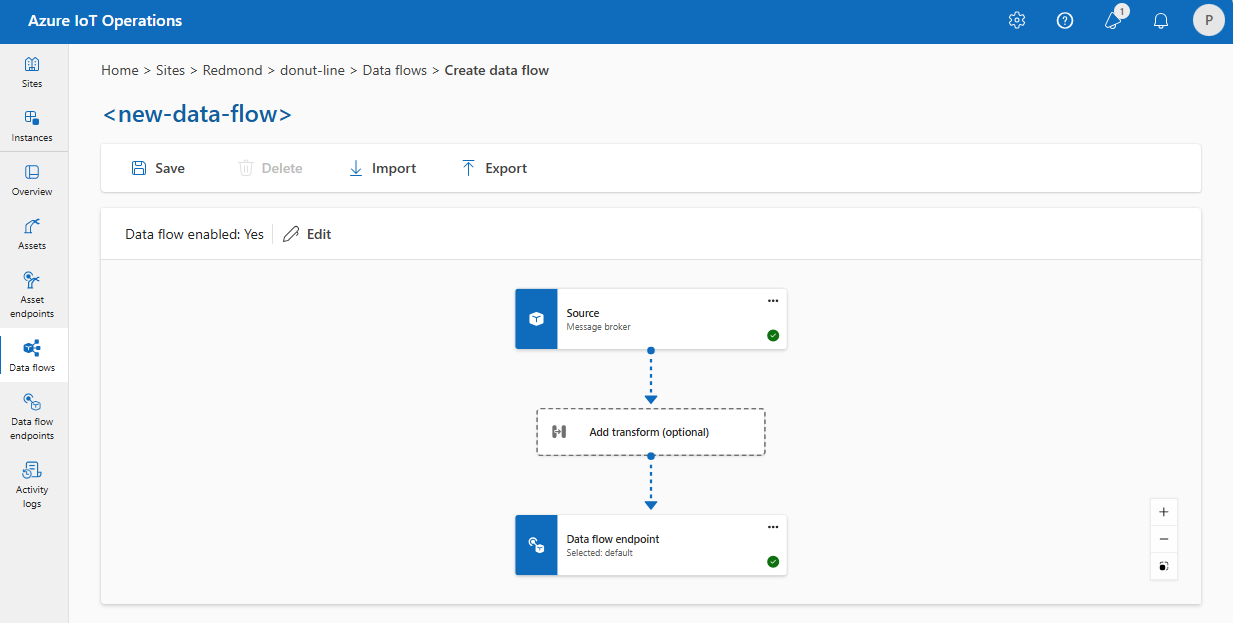
Op dezelfde manier kunt u meerdere gegevensstromen maken die hetzelfde MQTT-eindpunt gebruiken voor andere eindpunten en onderwerpen. U kunt bijvoorbeeld hetzelfde MQTT-eindpunt gebruiken voor een gegevensstroom waarmee gegevens worden verzonden naar een Event Hubs-eindpunt.
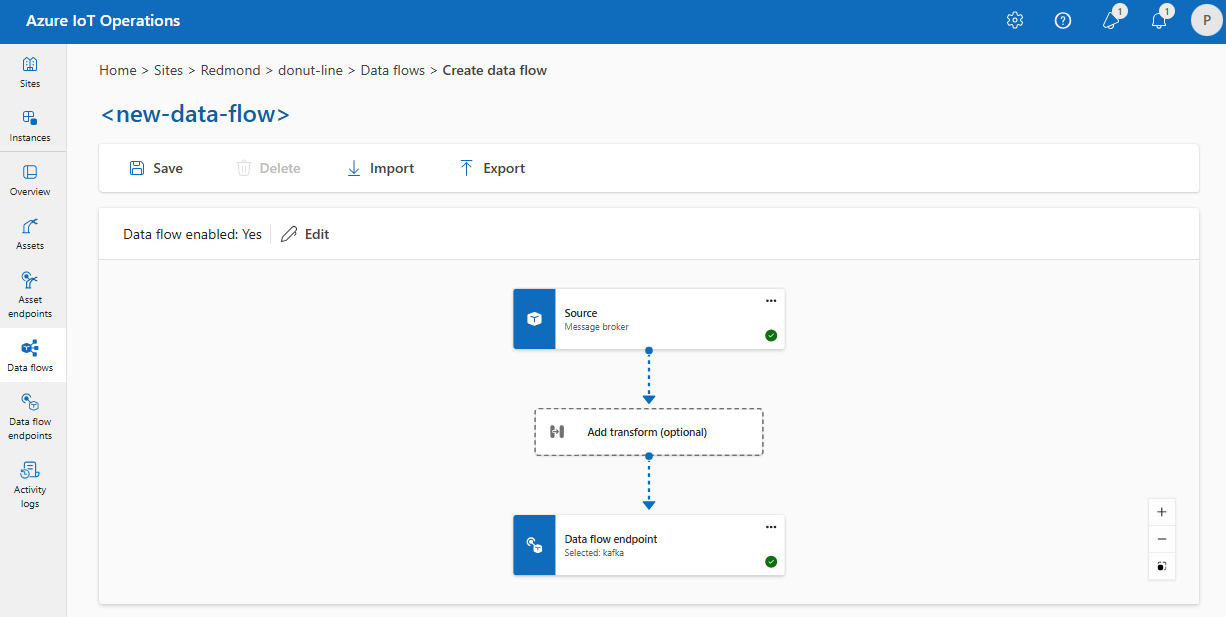
Net als in het MQTT-voorbeeld kunt u meerdere gegevensstromen maken die hetzelfde Kafka-eindpunt gebruiken voor verschillende onderwerpen of hetzelfde Data Lake-eindpunt voor verschillende tabellen.
Volgende stappen
Een gegevensstroomeindpunt maken: