Apache Ranger-beleid configureren voor Spark SQL in HDInsight met Enterprise Security Package
In dit artikel wordt beschreven hoe u Apache Ranger-beleid configureert voor Spark SQL met Enterprise Security Package in HDInsight.
In dit artikel leert u het volgende:
- Apache Ranger-beleid maken.
- Controleer het toegepaste Ranger-beleid.
- Richtlijnen toepassen voor het instellen van Apache Ranger voor Spark SQL.
Vereisten
- Een Apache Spark-cluster in HDInsight versie 5.1 met Enterprise Security Package
Verbinding maken naar de beheerdersinterface van Apache Ranger
Maak vanuit een browser verbinding met de gebruikersinterface van Ranger-beheerders met behulp van de URL
https://ClusterName.azurehdinsight.net/Ranger/.Ga naar
ClusterNamede naam van uw Spark-cluster.Meld u aan met uw Microsoft Entra-beheerdersreferenties. De microsoft Entra-beheerdersreferenties zijn niet hetzelfde als de referenties van het HDInsight-cluster of de SSH-referenties (Secure Shell) van het Linux HDInsight-knooppunt.
Domeingebruikers maken
Zie Een HDInsight-cluster maken met ESP voor meer informatie over het maken sparkuser van domeingebruikers. In een productiescenario komen domeingebruikers uit uw Microsoft Entra-tenant.
Een Ranger-beleid maken
In deze sectie maakt u twee Ranger-beleidsregels:
- Een toegangsbeleid voor toegang vanuit
hivesampletableSpark SQL - Een maskeringsbeleid voor het verbergen van de kolommen in
hivesampletable
Een Ranger-toegangsbeleid maken
Open de gebruikersinterface van de Ranger-beheerder.
Selecteer onder HADOOP SQL hive_and_spark.
Selecteer Nieuw beleid toevoegen op het tabblad Access.
Voer de volgende waarden in:
Eigenschappen Weergegeven als Policy Name read-hivesampletable-all database default table hivesampletable column * Select User sparkuserMachtigingen Selecteer 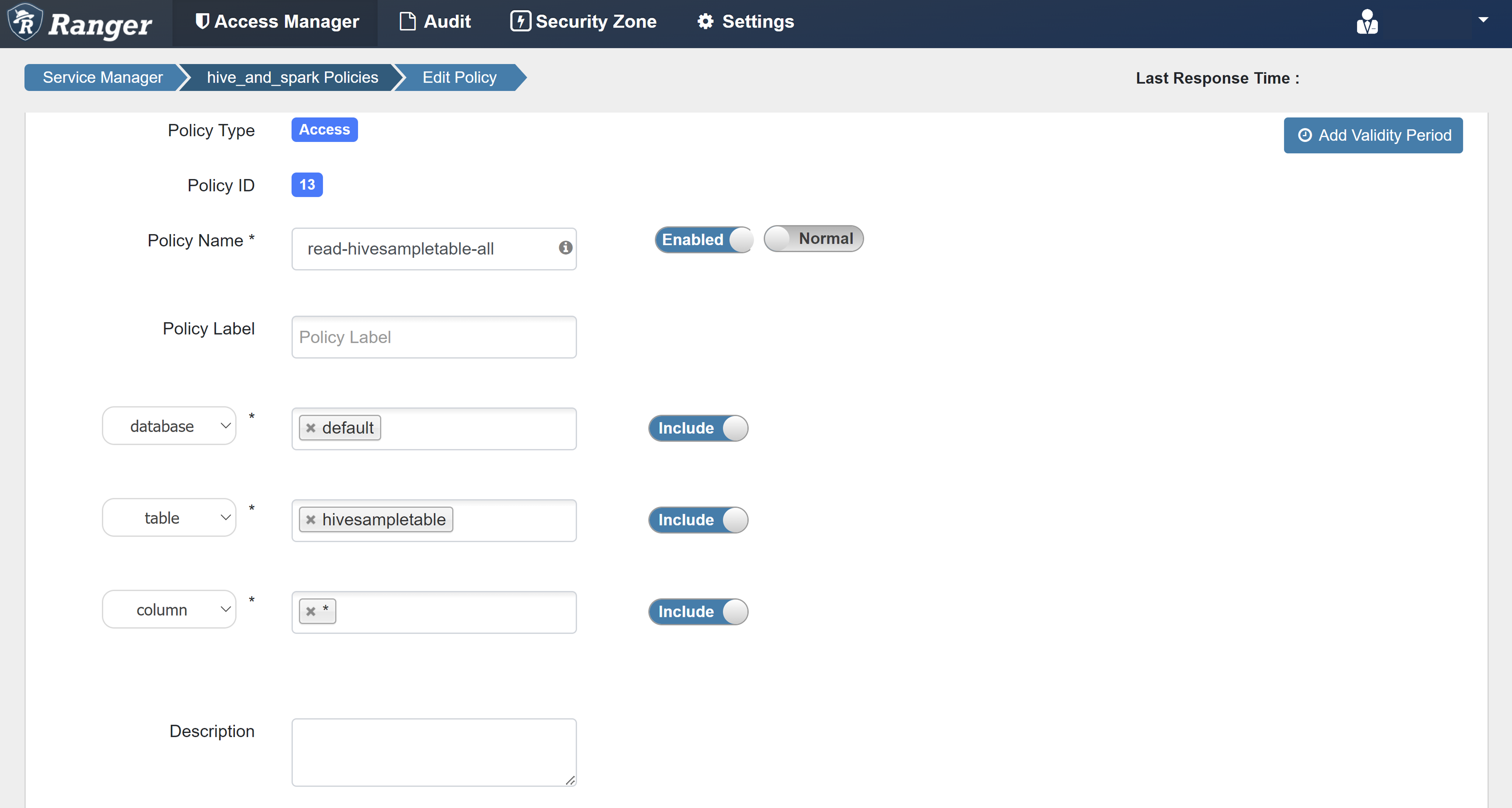
Als een domeingebruiker niet automatisch wordt ingevuld voor Select User, wacht u even tot Ranger is gesynchroniseerd met Microsoft Entra-id.
Selecteer Toevoegen om het beleid op te slaan.
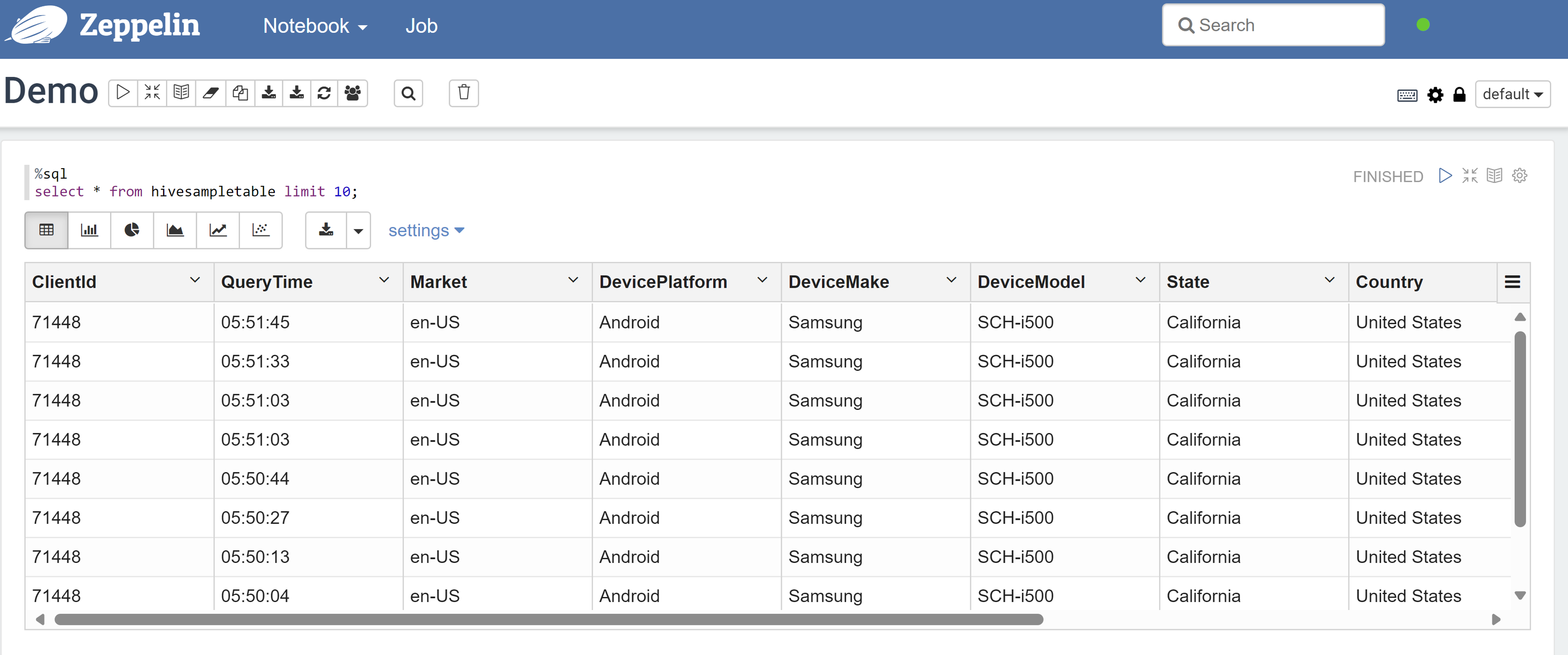
Open een Zeppelin-notebook en voer de volgende opdracht uit om het beleid te controleren:
%sql select * from hivesampletable limit 10;Dit is het resultaat voordat een beleid wordt toegepast:
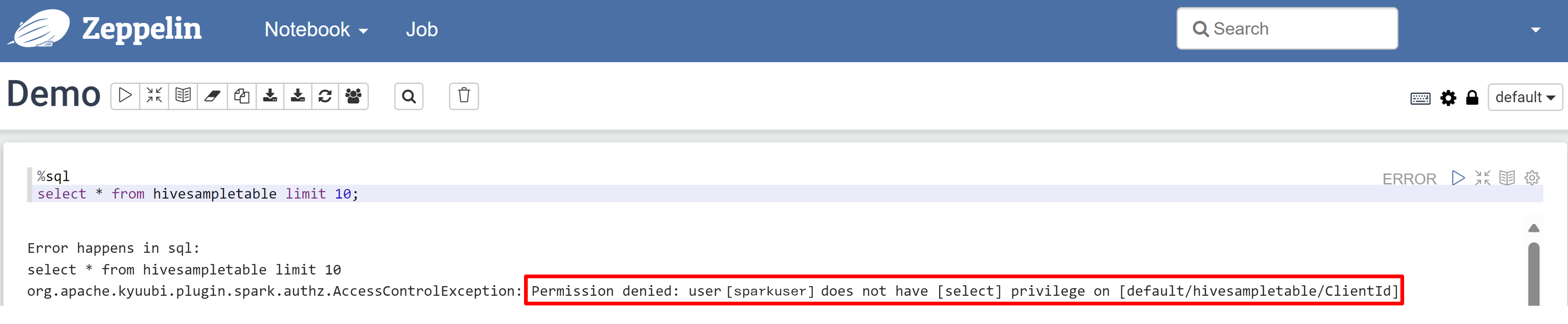
Dit is het resultaat nadat een beleid is toegepast:




Een maskeringsbeleid voor Ranger maken
In het volgende voorbeeld ziet u hoe u een beleid maakt om een kolom te maskeren:
Selecteer Op het tabblad Maskeren de optie Nieuw beleid toevoegen.
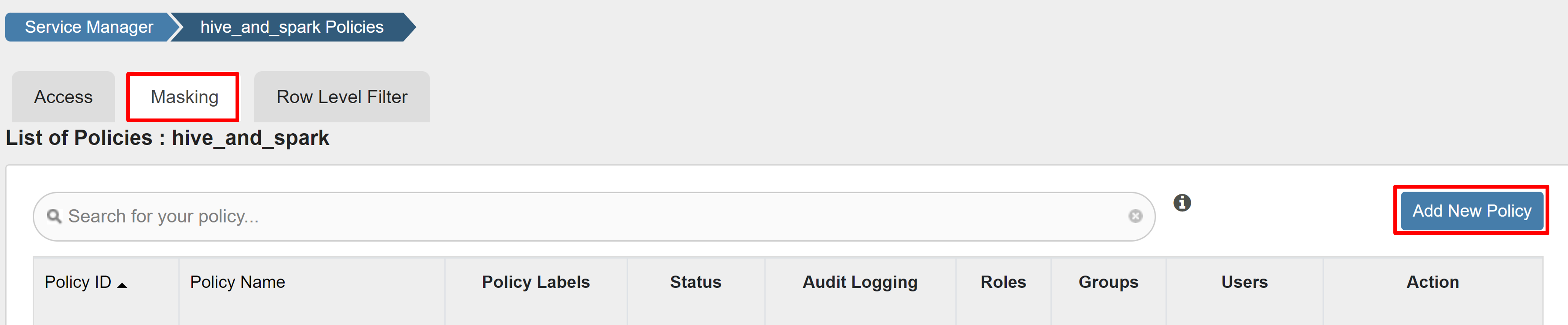
Voer de volgende waarden in:
Eigenschappen Weergegeven als Policy Name masker-hivesampletable Hive-database default Hive-tabel hivesampletable Hive-kolom devicemake Select User sparkuserToegangstypen Selecteer Optie Maskering selecteren Hash 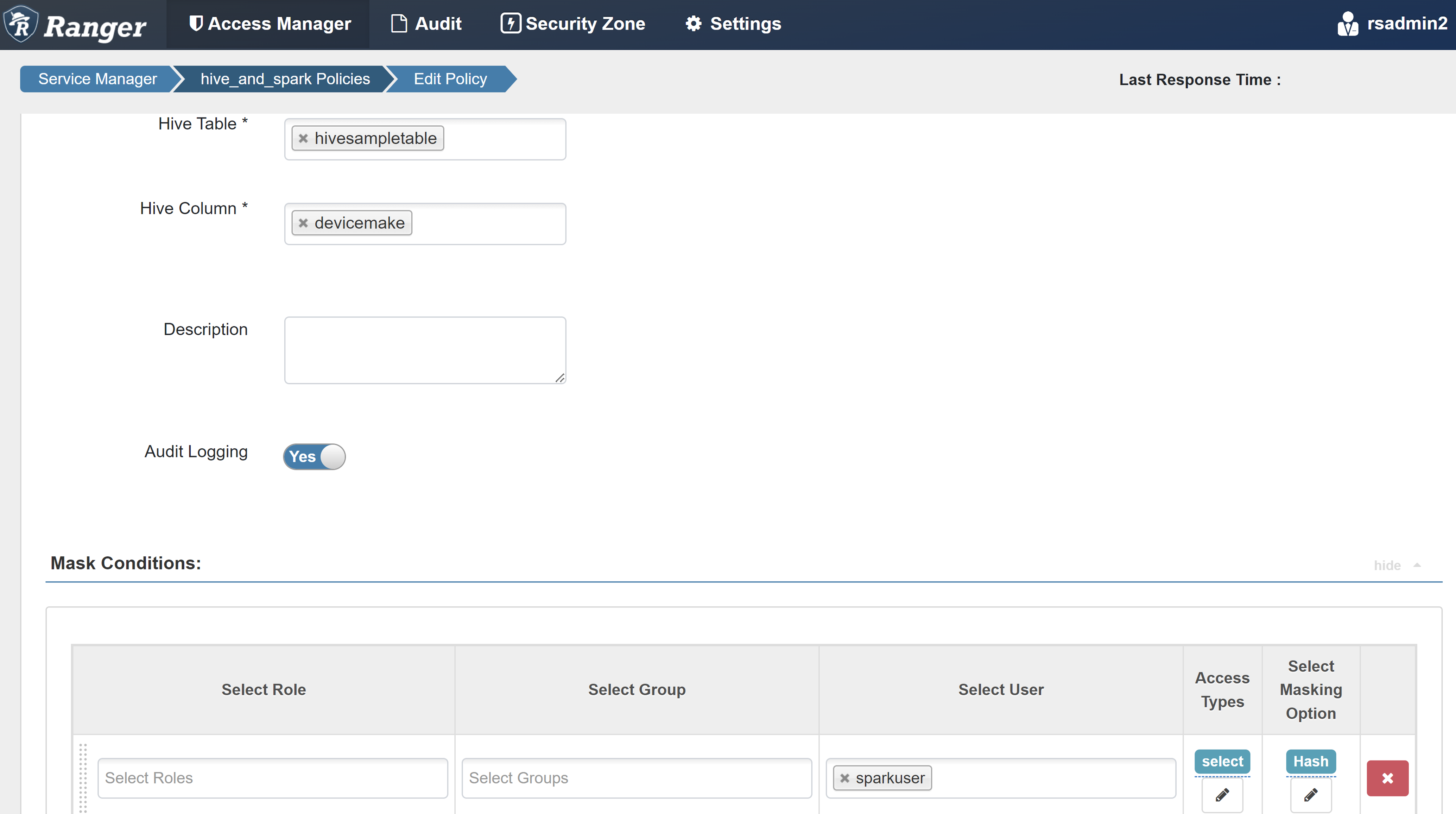
Selecteer Opslaan om het beleid op te slaan.
Open een Zeppelin-notebook en voer de volgende opdracht uit om het beleid te controleren:
%sql select clientId, deviceMake from hivesampletable;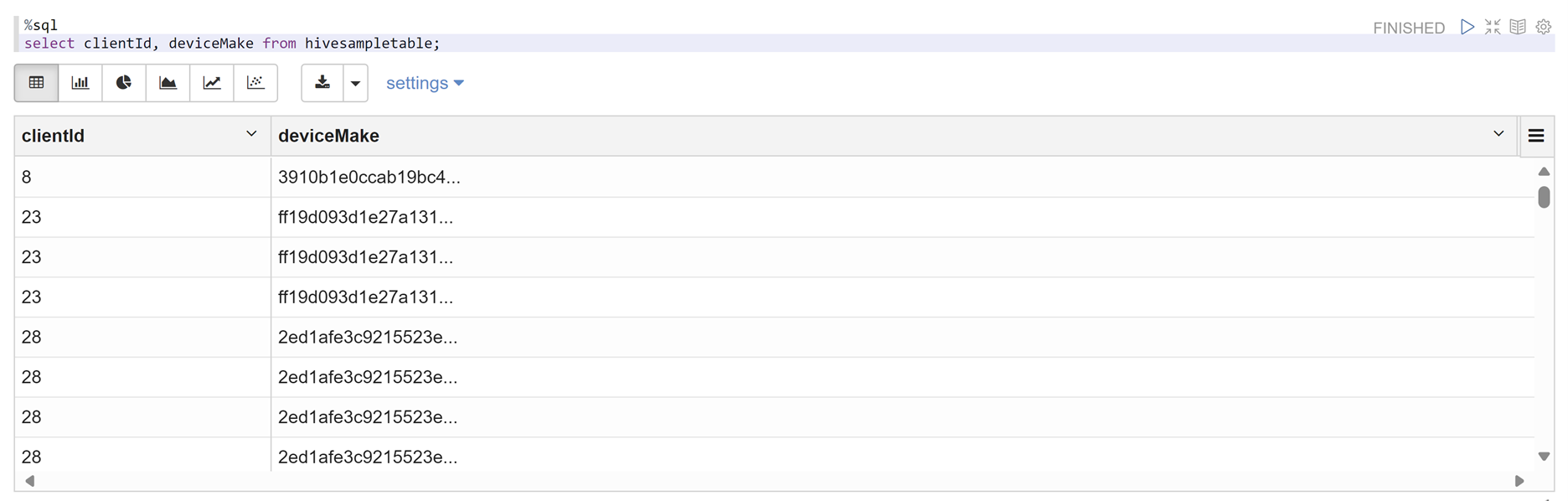



Notitie
Standaard zijn de beleidsregels voor Hive en Spark SQL gebruikelijk in Ranger.
Richtlijnen toepassen voor het instellen van Apache Ranger voor Spark SQL
In de volgende scenario's worden richtlijnen beschreven voor het maken van een HDInsight 5.1 Spark-cluster met behulp van een nieuwe Ranger-database en met behulp van een bestaande Ranger-database.
Scenario 1: Een nieuwe Ranger-database gebruiken tijdens het maken van een HDInsight 5.1 Spark-cluster
Wanneer u een nieuwe Ranger-database gebruikt om een cluster te maken, wordt de relevante Ranger-opslagplaats met het Ranger-beleid voor Hive en Spark gemaakt onder de naam hive_and_spark in de Hadoop SQL-service in de Ranger-database.

Als u het beleid bewerkt, worden deze toegepast op Zowel Hive als Spark.
Houd rekening met deze punten:
Als u twee metastore-databases hebt met dezelfde naam die wordt gebruikt voor zowel Hive-catalogussen (bijvoorbeeld DB1) als Spark (bijvoorbeeld DB1):
- Als Spark gebruikmaakt van de Spark-catalogus (
metastore.catalog.default=spark), worden de beleidsregels toegepast op de DB1-database van de Spark-catalogus. - Als Spark gebruikmaakt van de Hive-catalogus (
metastore.catalog.default=hive), worden de beleidsregels toegepast op de DB1-database van de Hive-catalogus.
Vanuit het perspectief van Ranger is er geen manier om onderscheid te maken tussen DB1 van de Hive- en Spark-catalogi.
In dergelijke gevallen raden we u aan:
- Gebruik de Hive-catalogus voor zowel Hive als Spark.
- Behoud verschillende database-, tabel- en kolomnamen voor zowel Hive- als Spark-catalogi, zodat het beleid niet wordt toegepast op databases in verschillende catalogi.
- Als Spark gebruikmaakt van de Spark-catalogus (
Als u de Hive-catalogus voor Zowel Hive als Spark gebruikt, kunt u het volgende voorbeeld overwegen.
Stel dat u een tabel met de naam table1 maakt via Hive met de huidige xyz-gebruiker . Er wordt een HDFS-bestand (Hadoop Distributed File System) gemaakt met de naam table1.db waarvan de eigenaar de xyz-gebruiker is.
Stel nu dat u de gebruiker abc gebruikt om de Spark SQL-sessie te starten. In deze sessie van user abc, als u iets probeert te schrijven naar table1, is het gebonden om te mislukken omdat de eigenaar van de tabel xyz is.
In dat geval raden we u aan dezelfde gebruiker in Hive en Spark SQL te gebruiken voor het bijwerken van de tabel. Deze gebruiker moet voldoende bevoegdheden hebben om updatebewerkingen uit te voeren.
Scenario 2: Een bestaande Ranger-database (met bestaand beleid) gebruiken tijdens het maken van een HDInsight 5.1 Spark-cluster
Wanneer u een HDInsight 5.1-cluster maakt met behulp van een bestaande Ranger-database, wordt er opnieuw een nieuwe Ranger-opslagplaats gemaakt op deze database met de naam van het nieuwe cluster in deze indeling: hive_and_spark.

Stel dat u het beleid hebt gedefinieerd in de Ranger-opslagplaats, al onder de naam oldclustername_hive op de bestaande Ranger-database in de Hadoop SQL-service. U wilt hetzelfde beleid delen in het nieuwe HDInsight 5.1 Spark-cluster. Gebruik de volgende stappen om dit doel te bereiken.
Notitie
Een gebruiker met Ambari-beheerdersbevoegdheden kan configuratie-updates uitvoeren.
Open de Ambari-gebruikersinterface vanuit uw nieuwe HDInsight 5.1-cluster.
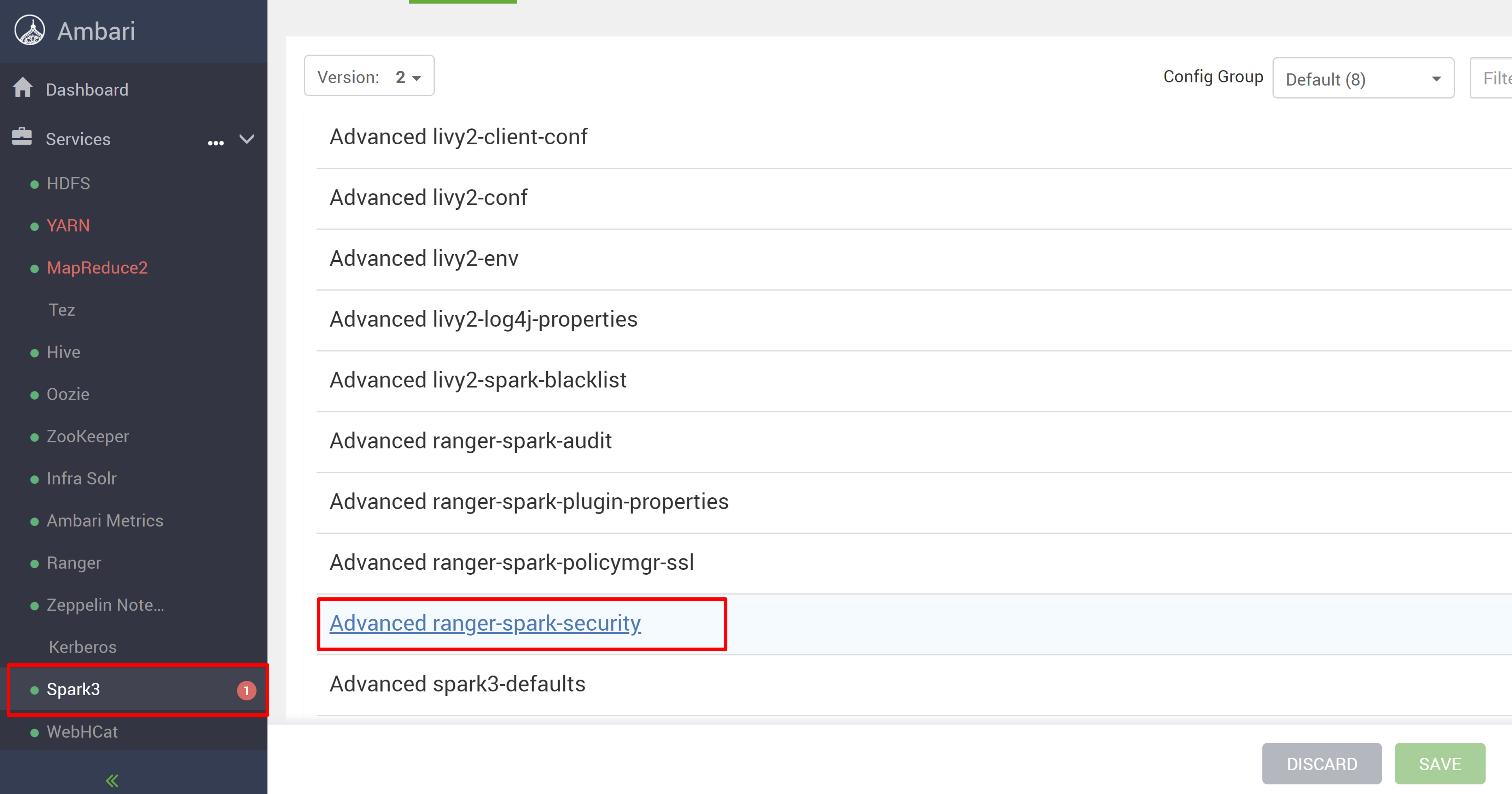
Ga naar de Spark3-service en ga vervolgens naar Configuraties.
Open de advanced ranger-spark-security-configuratie .
of u kunt deze configuratie ook openen in /etc/spark3/conf met behulp van SSH.
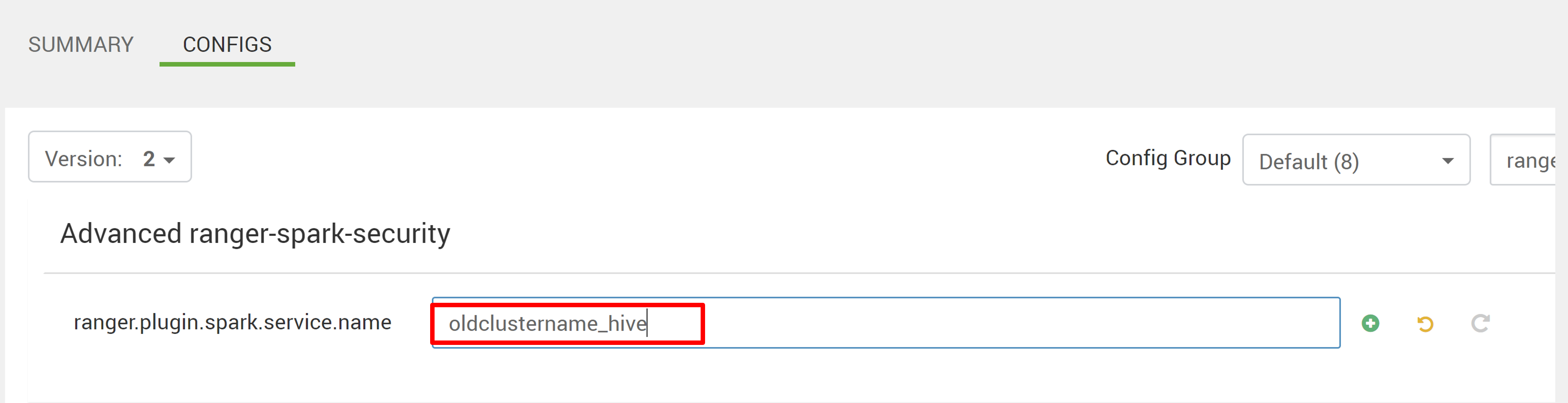
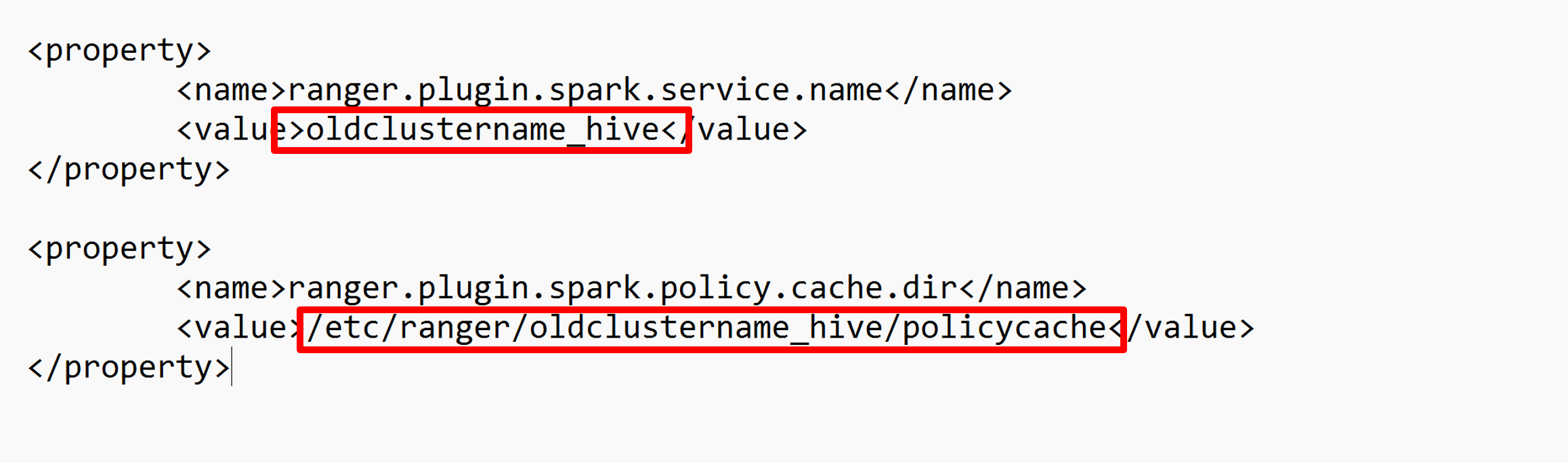
Bewerk twee configuraties (ranger.plugin.spark.service.name en ranger.plugin.spark.policy.cache.dir) om te verwijzen naar de oude beleidsopslagplaats oldclustername_hive en sla de configuraties op.
Ambari:
XML-bestand:
Start de Ranger- en Spark-services opnieuw vanuit Ambari.
Open de gebruikersinterface van ranger-beheerders en klik op de knop Bewerken onder HADOOP SQL-service .
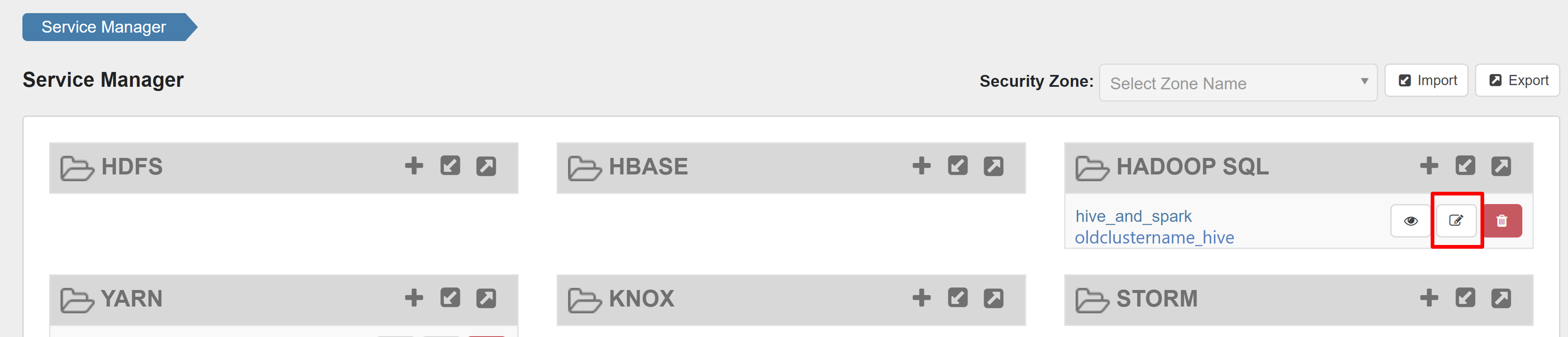
Voeg voor oldclustername_hive service rangersparklookup-gebruiker toe aan de lijst policy.download.auth.users en tag.download.auth.users en klik op Opslaan.






Het beleid wordt toegepast op databases in de Spark-catalogus. Als u toegang wilt tot de databases in de Hive-catalogus:
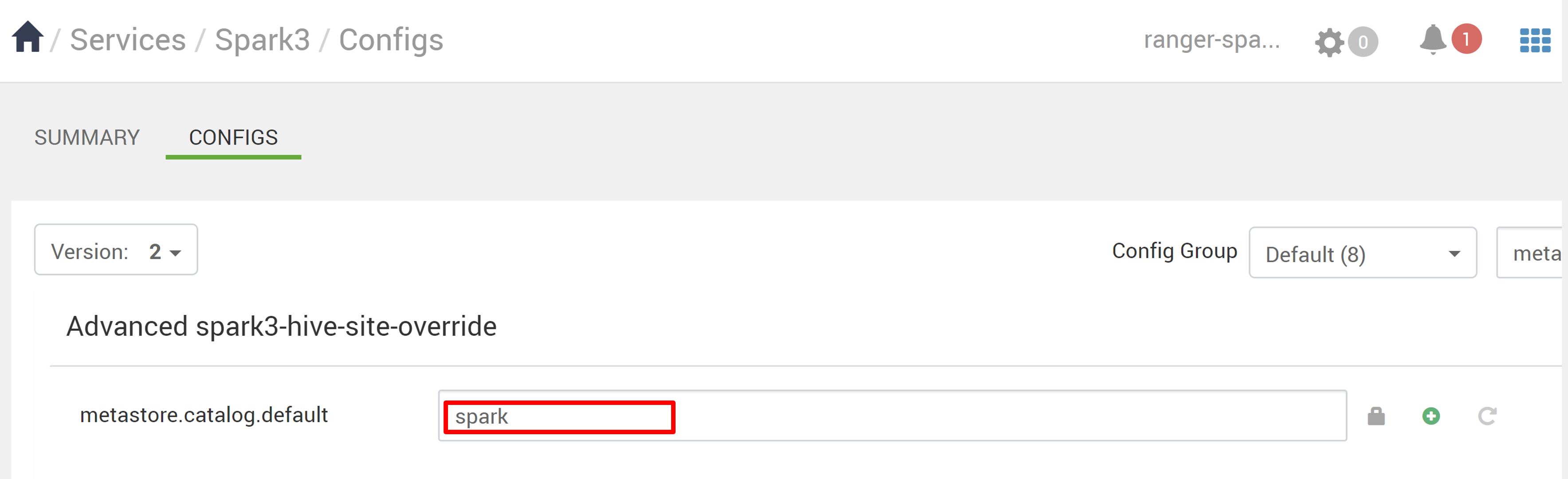
Ga in Ambari naar Spark3-configuraties>.
Wijzig metastore.catalog.default van spark in Hive.

Bekende problemen
- Apache Ranger-integratie met Spark SQL werkt niet als de Ranger-beheerder niet beschikbaar is.
- Wanneer u de muisaanwijzer boven de kolom Resource beweegt, kan de volledige query die u hebt uitgevoerd, niet worden weergegeven in de auditlogboeken van Ranger.