Optimalisatie van geheugengebruik voor Apache Spark
In dit artikel wordt beschreven hoe u geheugenbeheer van uw Apache Spark-cluster optimaliseert voor de beste prestaties in Azure HDInsight.
Overzicht
Spark werkt door gegevens in het geheugen te plaatsen. Het beheren van geheugenresources is dus een belangrijk aspect van het optimaliseren van de uitvoering van Spark-taken. Er zijn verschillende technieken die u kunt toepassen om het geheugen van uw cluster efficiënt te gebruiken.
- Gebruik eerder kleinere gegevenspartities en houd in uw partitiestrategie rekening met gegevensgrootten, -typen, en -distributie.
- Overweeg de nieuwere, efficiëntere
Kryo data serialization, in plaats van de standaard-Java-serialisatie. - Gebruik yarn liever, omdat deze wordt gescheiden
spark-submitdoor batch. - Bewaak Spark-configuratie-instellingen en verfijn ze.
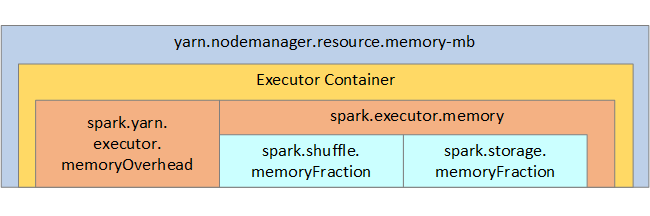
Ter referentie worden de Spark-geheugenstructuur en enkele belangrijke geheugenparameters voor de uitvoerder weergegeven in de volgende afbeelding.
Overwegingen voor Spark-geheugen
Als u Apache Hadoop YARN gebruikt, beheert YARN het geheugen dat door alle containers op elk Spark-knooppunt wordt gebruikt. In het volgende diagram ziet u de belangrijkste objecten en hun relaties.
Probeer het volgende om berichten over onvoldoende geheugen af te handelen:
- Bekijk beheer-shuffles in DAG. Verminder door brongegevens aan de toewijzingszijde te verminderen, brongegevens vooraf te partitioneren (of bucketize) te maximaliseren, enkelvoudige willekeurige volgordes te maximaliseren en de hoeveelheid verzonden gegevens te verminderen.
- Gebruik eerder
ReduceByKey- met de bijbehorende vaste geheugenlimiet - in plaats vanGroupByKey, wat aggregaties, vensterbewerking en andere functies biedt, maar waarvoor een niet-gebonden geheugenlimiet geldt. - Gebruik eerder
TreeReduce, wat meer werk uitvoert met de uitvoerders of partities, in plaats vanReduce, wat al het werk uitvoert in het stuurprogramma. - Gebruik DataFrames in plaats van de RDD-objecten op lager niveau.
- Maak ComplexTypes dat acties inkapselt, zoals ‘Top N’, verschillende aggregaties of vensterbewerking.
Zie OutOfMemoryError-uitzonderingen voor Apache Spark in Azure HDInsight voor aanvullende stappen voor probleemoplossing.