Toegang tot Apache Hadoop YARN-toepassingslogboeken in een HDInsight-cluster op basis van Linux
Meer informatie over het openen van de logboeken voor Apache Hadoop YARN-toepassingen (nog een andere resourceonderhandelaar) in een Apache Hadoop-cluster in Azure HDInsight.
Wat is Apache YARN?
YARN ondersteunt meerdere programmeermodellen (Apache Hadoop MapReduce is een van deze modellen) door resourcebeheer los te koppelen van toepassingsplanning/-bewaking. YARN maakt gebruik van een globaal ResourceManager (RM), nodemanagers per werkrol (NM's) en application ApplicationMasters (VM's). De AM per toepassing onderhandelt over resources (CPU, geheugen, schijf, netwerk) voor het uitvoeren van uw toepassing met de RM. De RM werkt met VM's om deze resources te verlenen, die worden verleend als containers. De AM is verantwoordelijk voor het bijhouden van de voortgang van de containers die eraan zijn toegewezen door de RM. Voor een toepassing zijn mogelijk veel containers vereist, afhankelijk van de aard van de toepassing.
Elke toepassing kan bestaan uit meerdere toepassingspogingen. Als een toepassing mislukt, kan het opnieuw worden geprobeerd als een nieuwe poging. Elke poging wordt uitgevoerd in een container. In zekere zin biedt een container de context voor basiseenheden van werk die door een YARN-toepassing worden uitgevoerd. Al het werk dat binnen de context van een container wordt uitgevoerd, wordt uitgevoerd op het knooppunt met één werkrol waarop de container is opgegeven. Zie Hadoop: YARN-toepassingen schrijven of Apache Hadoop YARN voor meer informatie.
Als u het cluster wilt schalen ter ondersteuning van een grotere verwerkingsdoorvoer, kunt u uw clusters handmatig schalen of schalen met behulp van een aantal verschillende talen.
YARN Timeline Server
De Apache Hadoop YARN Timeline Server biedt algemene informatie over voltooide toepassingen
YARN Timeline Server bevat het volgende type gegevens:
- De toepassings-id, een unieke id van een toepassing
- De gebruiker die de toepassing heeft gestart
- Informatie over pogingen om de toepassing te voltooien
- De containers die worden gebruikt door een bepaalde toepassingspoging
YARN-toepassingen en -logboeken
Toepassingslogboeken (en de bijbehorende containerlogboeken) zijn essentieel bij het opsporen van fouten in problematische Hadoop-toepassingen. YARN biedt een mooi framework voor het verzamelen, aggregeren en opslaan van toepassingslogboeken met Logboekaggregatie.
De functie Logboekaggregatie maakt het openen van toepassingslogboeken meer deterministisch. Hiermee worden logboeken samengevoegd in alle containers op een werkknooppunt en opgeslagen als één samengevoegd logboekbestand per werkknooppunt. Het logboek wordt opgeslagen in het standaardbestandssysteem nadat een toepassing is beëindigd. Uw toepassing kan honderden of duizenden containers gebruiken, maar logboeken voor alle containers die op één werkknooppunt worden uitgevoerd, worden altijd samengevoegd tot één bestand. Er is dus slechts één logboek per werkknooppunt dat door uw toepassing wordt gebruikt. Logboekaggregatie wordt standaard ingeschakeld op HDInsight-clusters versie 3.0 en hoger. Geaggregeerde logboeken bevinden zich in de standaardopslag voor het cluster. Het volgende pad is het HDFS-pad naar de logboeken:
/app-logs/<user>/logs/<applicationId>
In het pad user is de naam van de gebruiker die de toepassing heeft gestart. Dit applicationId is de unieke id die is toegewezen aan een toepassing door de YARN RM.
De samengevoegde logboeken kunnen niet rechtstreeks worden gelezen, omdat ze zijn geschreven in een TFilebinaire indeling die door de container wordt geïndexeerd. Gebruik de YARN-logboeken ResourceManager of CLI-hulpprogramma's om deze logboeken weer te geven als tekst zonder opmaak voor toepassingen of containers die van belang zijn.
Yarn-logboeken in een ESP-cluster
Er moeten twee configuraties worden toegevoegd aan de aangepaste mapred-site configuratie in Ambari.
Navigeer in een webbrowser naar
https://CLUSTERNAME.azurehdinsight.net, waarbijCLUSTERNAMEde naam van uw cluster is.Navigeer vanuit de Ambari-gebruikersinterface naar MapReduce2>Configs>Advanced>Custom mapred-site.
Voeg een van de volgende sets eigenschappen toe:
Stel 1 in
mapred.acls.enabled=true mapreduce.job.acl-view-job=*Stel 2 in
mapreduce.job.acl-view-job=<user1>,<user2>,<user3>Sla wijzigingen op en start alle betrokken services opnieuw op.
YARN CLI-hulpprogramma's
Gebruik de ssh-opdracht om verbinding te maken met uw cluster. Bewerk de volgende opdracht door CLUSTERNAME te vervangen door de naam van uw cluster en voer vervolgens de opdracht in:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netVermeld alle toepassings-id's van de momenteel uitgevoerde Yarn-toepassingen met de volgende opdracht:
yarn topNoteer de toepassings-id uit de
APPLICATIONIDkolom waarvan de logboeken moeten worden gedownload.YARN top - 18:00:07, up 19d, 0:14, 0 active users, queue(s): root NodeManager(s): 4 total, 4 active, 0 unhealthy, 0 decommissioned, 0 lost, 0 rebooted Queue(s) Applications: 2 running, 10 submitted, 0 pending, 8 completed, 0 killed, 0 failed Queue(s) Mem(GB): 97 available, 3 allocated, 0 pending, 0 reserved Queue(s) VCores: 58 available, 2 allocated, 0 pending, 0 reserved Queue(s) Containers: 2 allocated, 0 pending, 0 reserved APPLICATIONID USER TYPE QUEUE #CONT #RCONT VCORES RVCORES MEM RMEM VCORESECS MEMSECS %PROGR TIME NAME application_1490377567345_0007 hive spark thriftsvr 1 0 1 0 1G 0G 1628407 2442611 10.00 18:20:20 Thrift JDBC/ODBC Server application_1490377567345_0006 hive spark thriftsvr 1 0 1 0 1G 0G 1628430 2442645 10.00 18:20:20 Thrift JDBC/ODBC ServerU kunt deze logboeken weergeven als tekst zonder opmaak door een van de volgende opdrachten uit te voeren:
yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application> yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application> -containerId <containerId> -nodeAddress <worker-node-address>Geef bij het uitvoeren van deze opdrachten de <applicationId>, <user-who-started-the-application>, <containerId> en <worker-node-address> information op.
Andere voorbeeldopdrachten
Download Yarn-containerslogboeken voor alle toepassingsmodellen met de volgende opdracht. Met deze stap maakt u het logboekbestand met de naam
amlogs.txtin tekstindeling.yarn logs -applicationId <application_id> -am ALL > amlogs.txtDownload Yarn-containerlogboeken voor alleen de nieuwste toepassingsmaster met de volgende opdracht:
yarn logs -applicationId <application_id> -am -1 > latestamlogs.txtDownload YARN-containerlogboeken voor de eerste twee toepassingsmodellen met de volgende opdracht:
yarn logs -applicationId <application_id> -am 1,2 > first2amlogs.txtDownload alle Yarn-containerlogboeken met de volgende opdracht:
yarn logs -applicationId <application_id> > logs.txtDownload het yarn-containerlogboek voor een bepaalde container met de volgende opdracht:
yarn logs -applicationId <application_id> -containerId <container_id> > containerlogs.txt
YARN-gebruikersinterface ResourceManager
De YARN-gebruikersinterface ResourceManager wordt uitgevoerd op het hoofdknooppunt van het cluster. Het wordt geopend via de Ambari-webgebruikersinterface. Gebruik de volgende stappen om de YARN-logboeken weer te geven:
Navigeer in uw webbrowser naar
https://CLUSTERNAME.azurehdinsight.net. Vervang CLUSTERNAME door de naam van uw HDInsight-cluster.Selecteer YARN in de lijst met services aan de linkerkant.
Selecteer in de vervolgkeuzelijst Snelle koppelingen een van de hoofdknooppunten van het cluster en selecteer
ResourceManager Logvervolgens .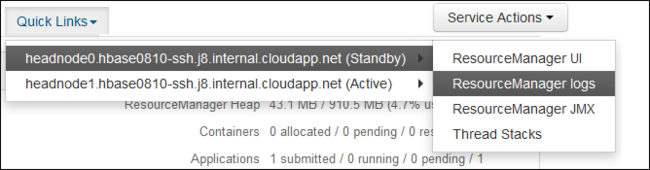
U ziet een lijst met koppelingen naar YARN-logboeken.