Apache Kafka® gebruiken in HDInsight met Apache Flink® in HDInsight op AKS
Notitie
Op 31 januari 2025 wordt Azure HDInsight buiten gebruik gesteld op AKS. Vóór 31 januari 2025 moet u uw workloads migreren naar Microsoft Fabric of een gelijkwaardig Azure-product om te voorkomen dat uw workloads plotseling worden beëindigd. De resterende clusters in uw abonnement worden gestopt en verwijderd van de host.
Alleen basisondersteuning is beschikbaar tot de buitengebruikstellingsdatum.
Belangrijk
Deze functie is momenteel beschikbaar in preview. De aanvullende gebruiksvoorwaarden voor Microsoft Azure Previews bevatten meer juridische voorwaarden die van toepassing zijn op Azure-functies die bèta, in preview of anderszins nog niet beschikbaar zijn in algemene beschikbaarheid. Zie Azure HDInsight op AKS Preview-informatie voor meer informatie over deze specifieke preview. Voor vragen of suggesties voor functies dient u een aanvraag in op AskHDInsight met de details en volgt u ons voor meer updates in de Azure HDInsight-community.
Een bekende use case voor Apache Flink is stream analytics. De populaire keuze van veel gebruikers om de gegevensstromen te gebruiken, die worden opgenomen met Behulp van Apache Kafka. Typische installaties van Flink en Kafka beginnen met gebeurtenisstromen die naar Kafka worden gepusht, die kunnen worden verbruikt door Flink-taken.
In dit voorbeeld wordt HDInsight gebruikt op AKS-clusters met Flink 1.17.0 voor het verwerken van streaminggegevens die kafka-onderwerp verbruiken en produceren.
Notitie
FlinkKafkaConsumer is afgeschaft en wordt verwijderd met Flink 1.17, gebruik in plaats daarvan KafkaSource. FlinkKafkaProducer is afgeschaft en wordt verwijderd met Flink 1.15, gebruik in plaats daarvan KafkaSink.
Vereisten
Zowel Kafka als Flink moeten zich in hetzelfde VNet bevinden of er moet vnet-peering tussen de twee clusters zijn.
Maak een Kafka-cluster in hetzelfde VNet. U kunt Kafka 3.2 of 2.4 in HDInsight kiezen op basis van uw huidige gebruik.
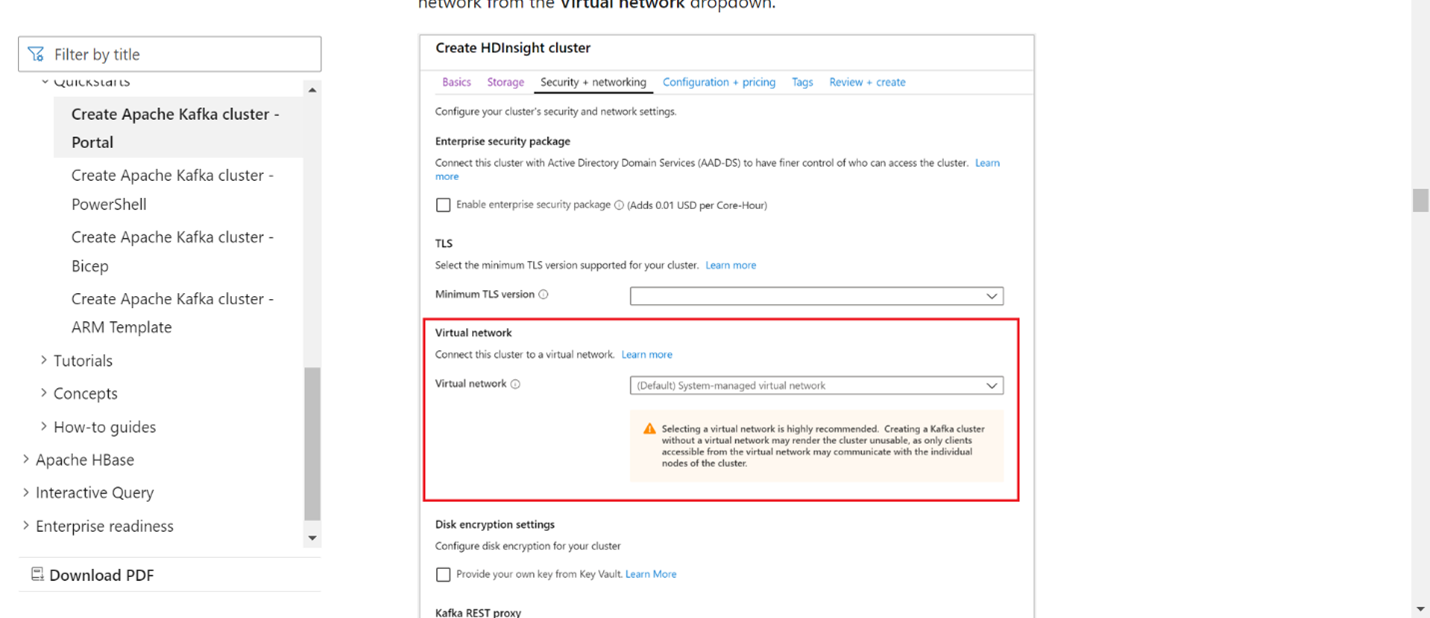
Voeg de VNet-details toe in de sectie virtueel netwerk.
Maak een HDInsight in een AKS-clustergroep met hetzelfde VNet.
Maak een Flink-cluster voor de gemaakte clustergroep.

Apache Kafka-connector
Flink biedt een Apache Kafka-connector voor het lezen van gegevens van en het schrijven van gegevens naar Kafka-onderwerpen met precies eenmaal gegarandeerde garanties.
Maven-afhankelijkheid
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>1.17.0</version>
</dependency>
Kafka-sink bouwen
Kafka-sink biedt een opbouwklasse voor het maken van een exemplaar van een KafkaSink. We gebruiken hetzelfde om onze Sink samen te stellen en te gebruiken samen met het Flink-cluster dat wordt uitgevoerd in HDInsight op AKS
SinKafkaToKafka.java
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class SinKafkaToKafka {
public static void main(String[] args) throws Exception {
// 1. get stream execution environment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. read kafka message as stream input, update your broker IPs below
String brokers = "X.X.X.X:9092,X.X.X.X:9092,X.X.X.X:9092";
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(brokers)
.setTopics("clicks")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStream<String> stream = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
// 3. transformation:
// https://www.taobao.com,1000 --->
// Event{user: "Tim",url: "https://www.taobao.com",timestamp: 1970-01-01 00:00:01.0}
SingleOutputStreamOperator<String> result = stream.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
String[] fields = value.split(",");
return new Event(fields[0].trim(), fields[1].trim(), Long.valueOf(fields[2].trim())).toString();
}
});
// 4. sink click into another kafka events topic
KafkaSink<String> sink = KafkaSink.<String>builder()
.setBootstrapServers(brokers)
.setProperty("transaction.timeout.ms","900000")
.setRecordSerializer(KafkaRecordSerializationSchema.builder()
.setTopic("events")
.setValueSerializationSchema(new SimpleStringSchema())
.build())
.setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE)
.build();
result.sinkTo(sink);
// 5. execute the stream
env.execute("kafka Sink to other topic");
}
}
Een Java-programma schrijven Event.java
import java.sql.Timestamp;
public class Event {
public String user;
public String url;
public Long timestamp;
public Event() {
}
public Event(String user,String url,Long timestamp) {
this.user = user;
this.url = url;
this.timestamp = timestamp;
}
@Override
public String toString(){
return "Event{" +
"user: \"" + user + "\"" +
",url: \"" + url + "\"" +
",timestamp: " + new Timestamp(timestamp) +
"}";
}
}
Pak het jar-bestand in en dien de taak in bij Flink
Upload op Webssh het jar-bestand en verzend het jar-bestand

Op Flink Dashboard UI

Het onderwerp produceren - klikken op Kafka

Het onderwerp gebruiken - gebeurtenissen in Kafka

Verwijzing
- Apache Kafka-connector
- Apache, Apache Kafka, Kafka, Apache Flink, Flink en bijbehorende opensource-projectnamen zijn handelsmerken van de Apache Software Foundation (ASF).