Hoge beschikbaarheid en herstel na noodgevallen met Azure Managed Redis (preview)
Net als bij alle cloudsystemen kunnen niet-geplande storingen optreden, waardoor een VM-instantie (virtuele machine), een beschikbaarheidszone of een volledige Azure-regio uitvalt. We raden klanten aan een plan te hebben voor het afhandelen van zone- of regionale storingen.
Dit artikel bevat de informatie voor klanten om een plan voor bedrijfscontinuïteit en herstel na noodgevallen te maken voor de implementatie van Azure Managed Redis (preview).
Opties voor hoge beschikbaarheid:
| Optie | Omschrijving | Beschikbaarheid |
|---|---|---|
| Standaardreplicatie | Gerepliceerde configuratie met twee knooppunten in één datacenter met automatische failover | 99,9% (zie details) |
| Zoneredundantie | Gerepliceerde configuratie met meerdere knooppunten in Beschikbaarheidszones, met automatische failover | 99,99% (zie details) |
| Geo-replicatie | Gekoppelde cache-exemplaren in twee regio's, met door de gebruiker beheerde failover | Actief (zie details) |
| Import/export | Momentopname van gegevens in cache naar een bepaald tijdstip. | 99,9% (zie details) |
| Volharding | Periodiek opslaan van gegevens in opslagaccount. | 99,9% (zie details) |
Standaardreplicatie voor hoge beschikbaarheid
Aanbevolen voor: Hoge beschikbaarheid
Azure Managed Redis heeft een architectuur met hoge beschikbaarheid die ervoor zorgt dat uw beheerde exemplaar functioneert, zelfs wanneer storingen van invloed zijn op de onderliggende virtuele machines (VM's). Of de storing nu geplande of niet-geplande storingen is, Azure Managed Redis biedt hogere beschikbaarheidspercentages dan wat kan worden bereikt door Redis op één VIRTUELE machine te hosten. Een door Azure beheerde Redis-installatie wordt standaard uitgevoerd op een paar Redis-servers. De twee servers worden gehost op toegewezen VM's.
Met Azure Managed Redis is de ene server het primaire knooppunt, terwijl de andere de replica is. Nadat de serverknooppunten zijn ingericht, wijst Azure Managed Redis primaire en replicarollen eraan toe. Het primaire knooppunt is meestal verantwoordelijk voor het onderhoud van schrijf- en leesaanvragen van clients. Bij een schrijfbewerking voert deze een nieuwe sleutel en een sleutelupdate door naar het interne geheugen en reageert deze onmiddellijk op de client. De bewerking wordt asynchroon doorgestuurd naar de replica .
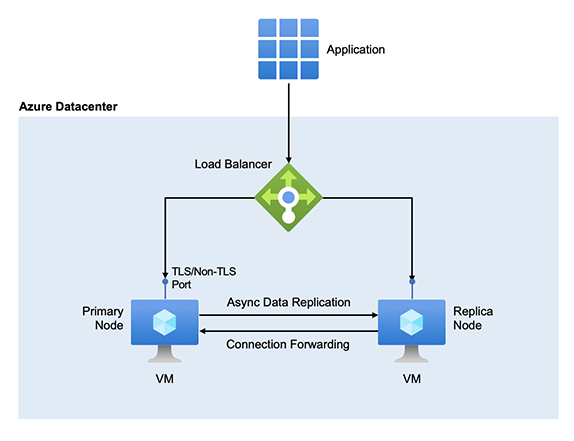
Als het primaire knooppunt in een cache niet beschikbaar is, bevordert de replica zichzelf automatisch om de nieuwe primaire te worden. Dit proces wordt een failover genoemd. Een failover is slechts twee knooppunten, primaire/replica, handelsrollen, replica/primair, waarbij een van de knooppunten mogelijk enkele minuten offline gaat. In de meeste failovers coördineren de primaire en replicaknooppunten de overdracht, zodat u bijna nul tijd hebt zonder een primaire.
De voormalige primaire versie gaat kort offline om updates van de nieuwe primaire te ontvangen. Vervolgens komt de replica nu weer online en wordt de cache volledig gesynchroniseerd. De sleutel is dat wanneer een knooppunt niet beschikbaar is, het een tijdelijke voorwaarde is en het weer online komt.
Een typische failoverreeks ziet er als volgt uit wanneer een primaire service moet worden uitgeschakeld voor onderhoud:
- Primaire en replicaknooppunten onderhandelen over een gecoördineerde failover en handelsrollen.
- Replica (voorheen primair) gaat offline voor opnieuw opstarten.
- Een paar seconden of minuten later komt de replica weer online.
- Replica synchroniseert de gegevens van de primaire.
Een primair knooppunt kan uit de service gaan als onderdeel van een geplande onderhoudsactiviteit, zoals een update naar Redis-software of het besturingssysteem. Het kan ook stoppen met werken vanwege niet-geplande gebeurtenissen, zoals storingen in onderliggende hardware, software of netwerk. Failover en patching voor Azure Managed Redis biedt een gedetailleerde uitleg over typen failovers. Een door Azure beheerde Redis doorloopt veel failovers tijdens de levensduur. Het ontwerp van de architectuur voor hoge beschikbaarheid maakt deze wijzigingen in een cache zo transparant mogelijk voor de clients.
Zoneredundantie
Aanbevolen voor: hoge beschikbaarheid, herstel na noodgevallen - intraregio
Azure Managed Redis ondersteunt standaard configuratie van zoneredundantie. In een zoneredundante cache worden de knooppunten automatisch in verschillende Azure-Beschikbaarheidszones in dezelfde regio geplaatst. Wanneer een zone uitvalt, zijn cacheknooppunten in andere zones beschikbaar om de cache te laten functioneren zoals gebruikelijk. Het voorkomt dat storingen in datacenters of beschikbaarheidszones enkele faalpunten zijn en verhoogt de algehele beschikbaarheid van uw cache.
Zoneuitvalervaring
Wanneer een gegevensknooppunt niet meer beschikbaar is of een netwerksplitsing plaatsvindt, vindt er een failover plaats die vergelijkbaar is met de failover die wordt beschreven in de standaardreplicatie . Het cluster maakt gebruik van een quorummodel om te bepalen welke overlevende knooppunten deelnemen aan een nieuw quorum. Indien nodig bevordert het ook replicapartities binnen deze knooppunten tot primair.
Regionale beschikbaarheid
Zone-redundante caches zijn beschikbaar in de volgende regio's:
| Noord- en Zuid-Amerika | Europa | Midden-Oosten | Afrika | Azië en Stille Oceaan |
|---|---|---|---|---|
| Canada - centraal* | Europa - noord | Australië - oost | ||
| VS - centraal* | Verenigd Koninkrijk Zuid | India - centraal | ||
| VS - oost | Europa -west | Azië - zuidoost | ||
| VS - oost 2 | Japan - oost* | |||
| VS - zuid-centraal | Azië - oost* | |||
| VS - west 2 | ||||
| US - west 3 | ||||
| Brazilië - zuid |
Persistentie
Aanbevolen voor: Duurzaamheid van gegevens
Omdat uw cachegegevens worden opgeslagen in het geheugen, kan een zeldzame en ongeplande fout van meerdere knooppunten ertoe leiden dat alle gegevens worden verwijderd. Om te voorkomen dat gegevens volledig verloren gaan, kunt u met Redis persistentie periodieke momentopnamen van in-memory gegevens maken en opslaan op een beheerde schijf die rechtstreeks aan het cache-exemplaar is gekoppeld. In het geval van gegevensverlies worden de cachegegevens automatisch hersteld met behulp van de momentopname op de beheerde schijf. Zie Gegevenspersistentie configureren voor een Azure Managed Redis-exemplaar voor meer informatie.
Import/Export
Aanbevolen voor: herstel na noodgevallen
Azure Managed Redis biedt ondersteuning voor de optie voor het importeren en exporteren van RDB-bestanden (Redis Database) om gegevensportabiliteit te bieden. Hiermee kunt u gegevens importeren in Azure Managed Redis of gegevens exporteren uit Azure Managed Redis met behulp van een RDB-momentopname. De RDB-momentopname uit een cache wordt geëxporteerd naar een blob in een Azure Storage-account. U kunt een script maken om periodiek exporteren naar uw opslagaccount te activeren. Zie Gegevens importeren en exporteren in Azure Managed Redis voor meer informatie.
Opslagaccount voor export
Overweeg om een geografisch redundant opslagaccount te kiezen om hoge beschikbaarheid van uw geëxporteerde gegevens te garanderen. Zie Redundantie in Azure Storage voor meer informatie.
Actieve geo-replicatie
Aanbevolen voor: hoge beschikbaarheid, herstel na noodgevallen - meerdere regio's
Geo-replicatie is een mechanisme voor het koppelen van Azure Managed Redis-exemplaren in meerdere Azure-regio's. Azure Managed Redis ondersteunt een geavanceerde vorm van geo-replicatie met de naam actieve geo-replicatie die zowel hogere beschikbaarheid als herstel na noodgevallen tussen regio's in meerdere regio's biedt. De Azure Managed Redis-software maakt gebruik van conflictvrije gerepliceerde gegevenstypen ter ondersteuning van schrijfbewerkingen naar meerdere cache-exemplaren, voegt wijzigingen samen en lost conflicten op. U kunt maximaal vijf cache-exemplaren in verschillende Azure-regio's samenvoegen om een geo-replicatiegroep te vormen.
Een toepassing die een dergelijke cache gebruikt, kan via de bijbehorende eindpunten lezen en schrijven naar een van de geografisch gedistribueerde cache-exemplaren. De toepassing moet gebruiken wat het dichtst bij elk toepassingsexemplaren ligt, waardoor u de laagste latentie krijgt. Zie Actieve geo-replicatie configureren voor Azure Managed Redis-exemplaren voor meer informatie.
Als een regio van een van de caches in uw replicatiegroep uitvalt, moet uw toepassing overschakelen naar een andere regio die beschikbaar is.
Wanneer een cache in uw replicatiegroep niet beschikbaar is, raden we u aan het geheugengebruik voor andere caches in dezelfde replicatiegroep te bewaken. Terwijl een van de caches niet beschikbaar is, beginnen alle andere caches in de replicatiegroep met het opslaan van metagegevens die ze niet konden delen met de cache die niet beschikbaar is. Als het geheugengebruik voor de beschikbare caches met een hoge snelheid groeit nadat een van de caches uitvalt, kunt u overwegen de cache die niet beschikbaar is van de replicatiegroep te ontkoppelen.
Zie Force-Unlink voor meer informatie over force-unlinking als er sprake is van een storing in de regio.
Cache verwijderen en opnieuw maken
Als u een regionale storing ondervindt, kunt u overwegen om uw cache in een andere regio opnieuw te maken en uw toepassing bij te werken om in plaats daarvan verbinding te maken met de nieuwe cache. Het is belangrijk om te begrijpen dat gegevens verloren gaan tijdens een regionale storing, tenzij u actieve geo-replicatie gebruikt. Uw toepassingscode moet bestand zijn tegen gegevensverlies.
Zodra de getroffen regio is hersteld, wordt uw niet-beschikbare Beheerde Redis automatisch hersteld en weer beschikbaar voor gebruik. Zie Azure Managed Redis-exemplaren verplaatsen naar verschillende regio's voor meer strategieën voor het verplaatsen van uw cache naar een andere regio.