TripPin del 10 – grunnleggende spørringsdelegering
Merk
Dette innholdet refererer for øyeblikket til innhold fra en eldre implementering for logger i Visual Studio. Innholdet oppdateres i nær fremtid for å dekke den nye SDK-en for Power Query i Visual Studio Code.
Denne flerdelte opplæringen dekker opprettelsen av en ny datakildeutvidelse for Power Query. Opplæringen er ment å gjøres sekvensielt – hver leksjon bygger på koblingen som er opprettet i tidligere leksjoner, og legger trinnvis til nye funksjoner i koblingen.
I denne leksjonen vil du:
- Lær det grunnleggende om spørringsdelegering
- Finn ut mer om table.view-funksjonen
- Repliker OData-spørringsdelegeringsbehandlinger for:
$top$skip$count$select$orderby
En av de kraftige funksjonene i M-språket er muligheten til å sende transformasjonsarbeid til én eller flere underliggende datakilder. Denne funksjonen kalles spørringsdelegering (andre verktøy/teknologier refererer også til lignende funksjon som Predikat pushdown eller spørringsdelegering ).
Når du oppretter en egendefinert kobling som bruker en M-funksjon med innebygde funksjoner for spørringsdelegering, for eksempel OData.Feed eller Odbc.DataSource, arver koblingen automatisk denne funksjonen gratis.
Denne opplæringen replikerer den innebygde virkemåten for spørringsdelegering for OData ved å implementere funksjonsbehandlinger for Table.View-funksjonen . Denne delen av opplæringen implementerer noen av de enklere behandlerne å implementere (det vil si de som ikke krever uttrykksanalyse og tilstandssporing).
Hvis du vil forstå mer om spørringsfunksjonene som en OData-tjeneste kan tilby, kan du gå til OData v4 URL-adressekonvensjoner.
Merk
Som nevnt tidligere har OData.Feed-funksjonen automatisk funksjoner for spørringsdelegering. Siden TripPin-serien behandler OData-tjenesten som en vanlig REST-API, ved hjelp av Web.Contents i stedet for OData.Feed, må du implementere spørringsdelegeringsbehandlingene selv. For bruk i den virkelige verden anbefaler vi at du bruker OData.Feed når det er mulig.
Gå til Oversikt over spørringsevaluering og spørringsdelegering i Power Query for mer informasjon om spørringsdelegering.
Bruke Table.View
Table.View-funksjonen gjør det mulig for en egendefinert kobling å overstyre standard transformasjonsbehandlinger for datakilden. En implementering av Table.View gir en funksjon for én eller flere av de støttede behandlerne. Hvis en behandler ikke er knyttet til, eller returnerer en error under evaluering, faller M-motoren tilbake til standardbehandlingen.
Når en egendefinert kobling bruker en funksjon som ikke støtter implisitt spørringsdelegering, for eksempel Web.Contents, utføres alltid standard transformasjonsbehandling lokalt. Hvis REST-API-en du kobler til, støtter spørringsparametere som en del av spørringen, lar Table.View deg legge til optimaliseringer som gjør at transformasjonsarbeid kan sendes til tjenesten.
Table.View-funksjonen har følgende signatur:
Table.View(table as nullable table, handlers as record) as table
Implementeringen bryter hovedfunksjonen for datakilden. Det finnes to nødvendige behandlere for Table.View:
GetType– returnerer forventet spørringsresultattable typeGetRows– returnerer det faktisketableresultatet av datakildefunksjonen
Den enkleste implementeringen vil være lik følgende eksempel:
TripPin.SuperSimpleView = (url as text, entity as text) as table =>
Table.View(null, [
GetType = () => Value.Type(GetRows()),
GetRows = () => GetEntity(url, entity)
]);
TripPinNavTable Oppdater funksjonen til kall TripPin.SuperSimpleView i stedet GetEntityfor :
withData = Table.AddColumn(rename, "Data", each TripPin.SuperSimpleView(url, [Name]), type table),
Hvis du kjører enhetstestene på nytt, ser du at virkemåten til funksjonen ikke endres. I dette tilfellet går implementeringen av Table.View ganske enkelt gjennom kallet til GetEntity. Siden du ikke har implementert noen transformasjonsbehandlinger (ennå), forblir den opprinnelige url parameteren uberørt.
Første implementering av Table.View
Implementeringen ovenfor av Table.View er enkel, men ikke veldig nyttig. Følgende implementering brukes som grunnlinje – den implementerer ingen foldefunksjonalitet, men har stillaset du trenger for å gjøre det.
TripPin.View = (baseUrl as text, entity as text) as table =>
let
// Implementation of Table.View handlers.
//
// We wrap the record with Diagnostics.WrapHandlers() to get some automatic
// tracing if a handler returns an error.
//
View = (state as record) => Table.View(null, Diagnostics.WrapHandlers([
// Returns the table type returned by GetRows()
GetType = () => CalculateSchema(state),
// Called last - retrieves the data from the calculated URL
GetRows = () =>
let
finalSchema = CalculateSchema(state),
finalUrl = CalculateUrl(state),
result = TripPin.Feed(finalUrl, finalSchema),
appliedType = Table.ChangeType(result, finalSchema)
in
appliedType,
//
// Helper functions
//
// Retrieves the cached schema. If this is the first call
// to CalculateSchema, the table type is calculated based on
// the entity name that was passed into the function.
CalculateSchema = (state) as type =>
if (state[Schema]? = null) then
GetSchemaForEntity(entity)
else
state[Schema],
// Calculates the final URL based on the current state.
CalculateUrl = (state) as text =>
let
urlWithEntity = Uri.Combine(state[Url], state[Entity])
in
urlWithEntity
]))
in
View([Url = baseUrl, Entity = entity]);
Hvis du ser på kallet til Table.View, ser du en ekstra wrapper-funksjon rundt handlers postenDiagnostics.WrapHandlers. Denne hjelpefunksjonen finnes i diagnosemodulen (som ble introdusert i tilleggsdiagnoseleksjonen), og gir deg en nyttig måte å automatisk spore eventuelle feil som oppstår av individuelle behandlere.
Funksjonene GetType og GetRows oppdateres for å gjøre bruk av to nye hjelpefunksjoner –CalculateSchema og CalculateUrl. Akkurat nå er implementeringene av disse funksjonene ganske enkle – legg merke til at de inneholder deler av det som tidligere ble gjort av GetEntity funksjonen.
Legg til slutt merke til at du definerer en intern funksjon (View) som godtar en state parameter.
Etter hvert som du implementerer flere behandlere, vil de rekursivt kalle den interne View funksjonen, oppdatere og sende videre state etter hvert som de går.
TripPinNavTable Oppdater funksjonen igjen, bytt kallet til TripPin.SuperSimpleView med et kall til den nye TripPin.View funksjonen, og kjør enhetstestene på nytt. Du vil ikke se noen ny funksjonalitet ennå, men du har nå en solid grunnlinje for testing.
Implementere spørringsdelegering
Siden M-motoren automatisk faller tilbake til lokal behandling når en spørring ikke kan brettes, må du utføre noen ekstra trinn for å bekrefte at Table.View-behandlerne fungerer som de skal.
Den manuelle måten å validere folding virkemåte på, er å se nettadressen ber om at enhetstestene gjør det ved hjelp av et verktøy som Fiddler. Alternativt vil diagnoseloggingen du har lagt til TripPin.Feed , avgi den fullstendige nettadressen som kjøres, som skal inneholde OData-spørringsstrengparameterne som behandlerne legger til.
En automatisert måte å validere spørringsdelegering på, er å tvinge kjøringen av enhetstesten til å mislykkes hvis en spørring ikke brettes fullstendig. Du kan gjøre dette ved å åpne prosjektegenskapene og angi Feil ved delegeringsfeil til Sann. Når denne innstillingen er aktivert, vil alle spørringer som krever lokal behandling, resultere i følgende feil:
Vi kan ikke brette uttrykket til kilden. Prøv et enklere uttrykk.
Du kan teste dette ved å legge til en ny Fact enhetstestfil som inneholder én eller flere tabelltransformasjoner.
// Query folding tests
Fact("Fold $top 1 on Airlines",
#table( type table [AirlineCode = text, Name = text] , {{"AA", "American Airlines"}} ),
Table.FirstN(Airlines, 1)
)
Merk
Feil ved delegeringsfeil er en «alt eller ingenting»-tilnærming. Hvis du vil teste spørringer som ikke er utformet for å brettes som en del av enhetstestene, må du legge til en betinget logikk for å aktivere/deaktivere tester tilsvarende.
De gjenværende delene av denne opplæringen legger hver til en ny Table.View-behandling . Du tar en TDD-tilnærming (Test Driven Development), der du først legger til mislykkede enhetstester, og deretter implementerer du M-koden for å løse dem.
De følgende behandlingsdelene beskriver funksjonaliteten som leveres av behandleren, OData-tilsvarende spørringssyntaks, enhetstestene og implementeringen. Ved hjelp av stillaskoden som er beskrevet tidligere, krever hver implementering av behandler to endringer:
- Legge til behandleren i Table.View som oppdaterer
stateposten. - Endre for
CalculateUrlå hente verdiene frastateog legge til i parameterne for nettadressen og/eller spørringsstrengen.
Behandle Table.FirstN med OnTake
Behandleren OnTake mottar en count parameter, som er maksimalt antall rader å ta fra GetRows.
I OData-termer kan du oversette dette til $top spørringsparameteren.
Du bruker følgende enhetstester:
// Query folding tests
Fact("Fold $top 1 on Airlines",
#table( type table [AirlineCode = text, Name = text] , {{"AA", "American Airlines"}} ),
Table.FirstN(Airlines, 1)
),
Fact("Fold $top 0 on Airports",
#table( type table [Name = text, IataCode = text, Location = record] , {} ),
Table.FirstN(Airports, 0)
),
Disse testene bruker begge Table.FirstN til å filtrere til resultatet satt til det første X-antallet rader. Hvis du kjører disse testene med Feil ved delegeringsfeil satt til False (standard), skal testene lykkes, men hvis du kjører Fiddler (eller kontrollerer sporingsloggene), kan du legge merke til at forespørselen du sender, ikke inneholder noen OData-spørringsparametere.
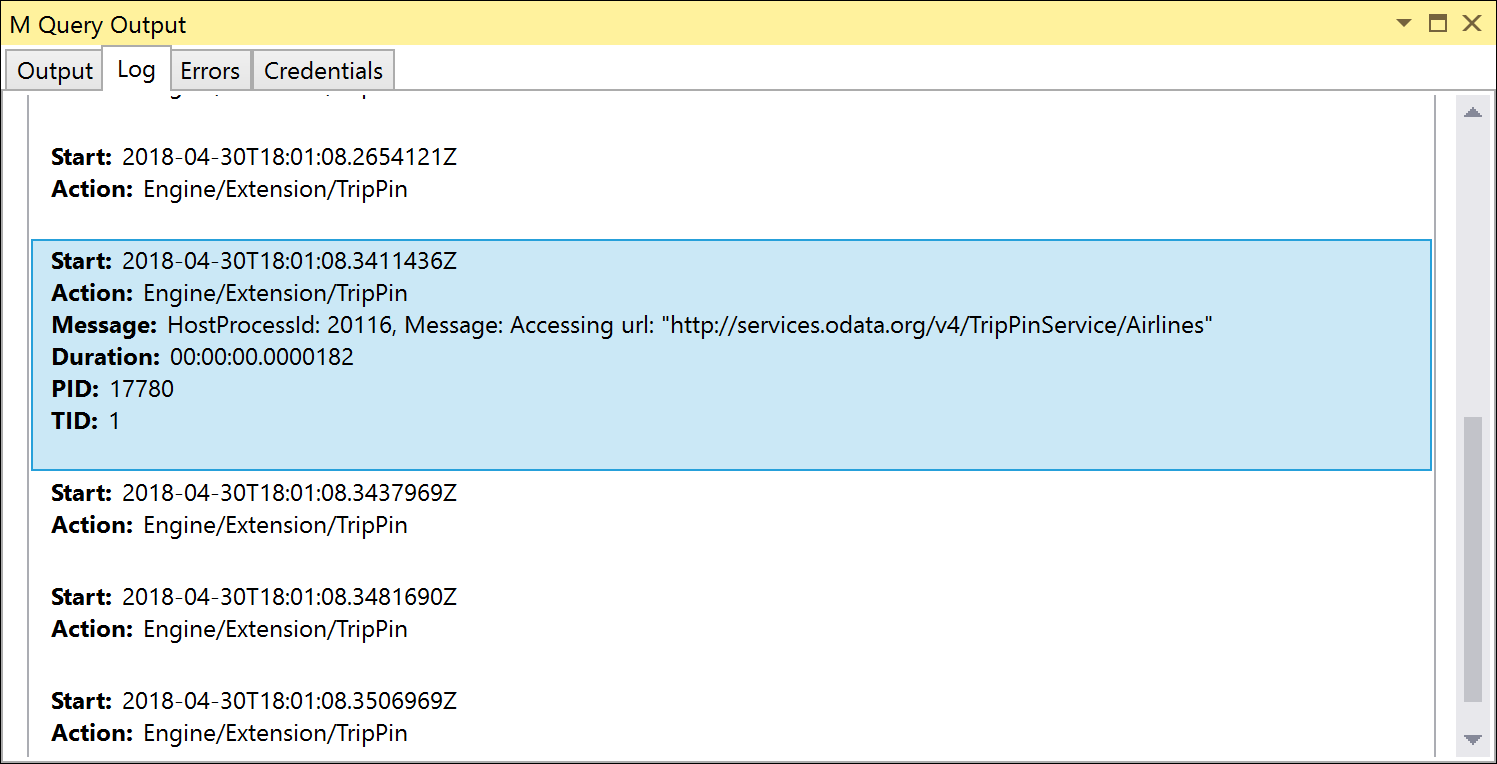
Hvis du angir Feil ved delegeringsfeil Truetil, mislykkes testene med Please try a simpler expression. feilen. Hvis du vil løse denne feilen, må du definere din første Table.View-behandling for OnTake.
Behandleren OnTake ser ut som følgende kode:
OnTake = (count as number) =>
let
// Add a record with Top defined to our state
newState = state & [ Top = count ]
in
@View(newState),
Funksjonen CalculateUrl oppdateres for å trekke ut Top verdien fra state posten, og angi riktig parameter i spørringsstrengen.
// Calculates the final URL based on the current state.
CalculateUrl = (state) as text =>
let
urlWithEntity = Uri.Combine(state[Url], state[Entity]),
// Uri.BuildQueryString requires that all field values
// are text literals.
defaultQueryString = [],
// Check for Top defined in our state
qsWithTop =
if (state[Top]? <> null) then
// add a $top field to the query string record
defaultQueryString & [ #"$top" = Number.ToText(state[Top]) ]
else
defaultQueryString,
encodedQueryString = Uri.BuildQueryString(qsWithTop),
finalUrl = urlWithEntity & "?" & encodedQueryString
in
finalUrl
Kjør enhetstestene på nytt, og legg merke til at nettadressen du har tilgang til, nå inneholder parameteren $top . På grunn av url-koding vises $top som %24top, men OData-tjenesten er smart nok til å konvertere den automatisk.
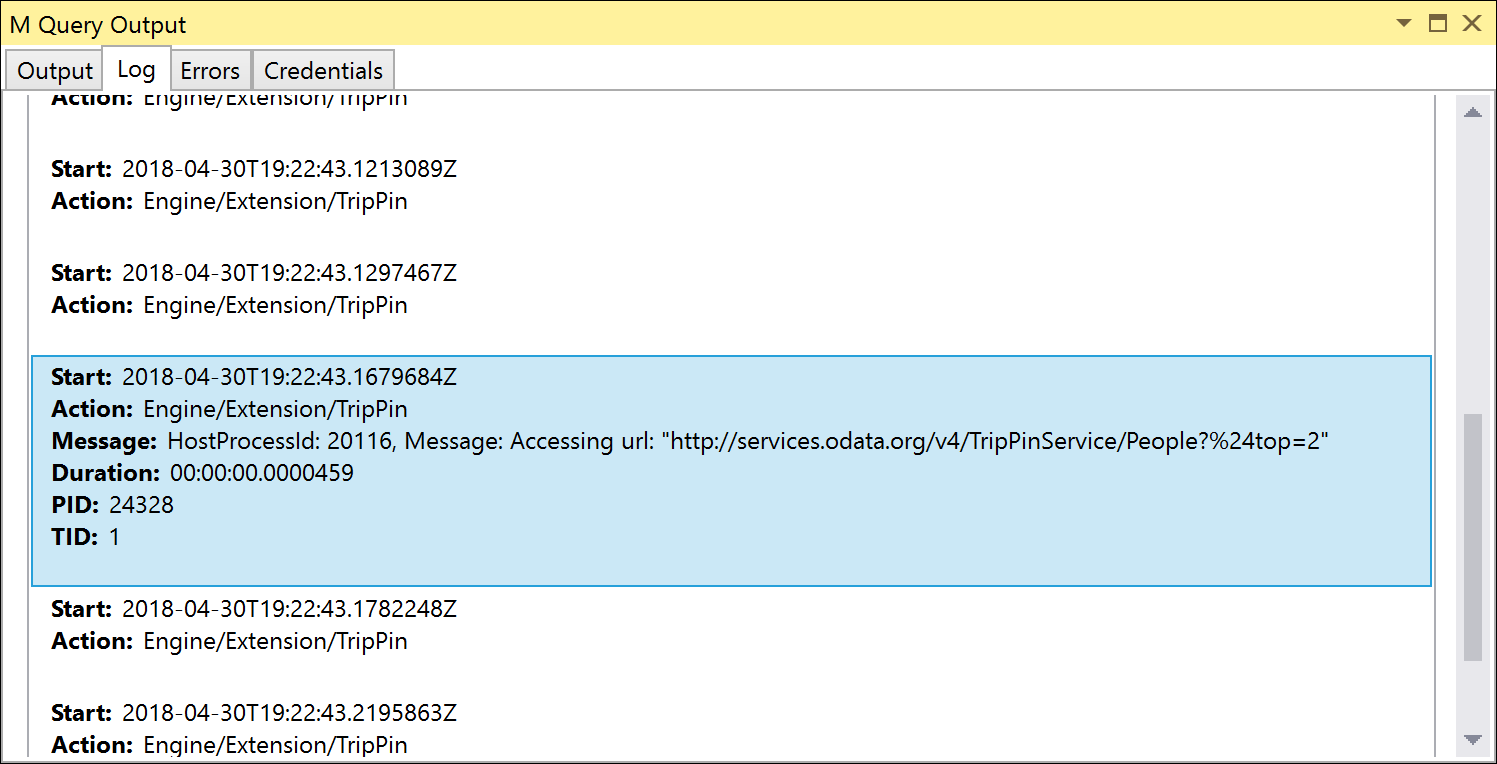
Behandle Table.Skip med OnSkip
Behandleren OnSkip er mye lik OnTake. Den mottar en count parameter, som er antall rader som skal hoppes over fra resultatsettet. Denne behandleren oversettes pent til OData $skip-spørringsparameteren .
Enhetstester:
// OnSkip
Fact("Fold $skip 14 on Airlines",
#table( type table [AirlineCode = text, Name = text] , {{"EK", "Emirates"}} ),
Table.Skip(Airlines, 14)
),
Fact("Fold $skip 0 and $top 1",
#table( type table [AirlineCode = text, Name = text] , {{"AA", "American Airlines"}} ),
Table.FirstN(Table.Skip(Airlines, 0), 1)
),
Implementering:
// OnSkip - handles the Table.Skip transform.
// The count value should be >= 0.
OnSkip = (count as number) =>
let
newState = state & [ Skip = count ]
in
@View(newState),
Samsvarende oppdateringer til CalculateUrl:
qsWithSkip =
if (state[Skip]? <> null) then
qsWithTop & [ #"$skip" = Number.ToText(state[Skip]) ]
else
qsWithTop,
Mer informasjon: Table.Skip
Behandle Table.SelectColumns med OnSelectColumns
Behandleren OnSelectColumns kalles når brukeren velger eller fjerner kolonner fra resultatsettet. Behandleren mottar en list verdi text , som representerer én eller flere kolonner som skal velges.
I OData-termer tilordnes denne operasjonen til $select spørringsalternativet .
Fordelen med å brette kolonnevalg blir tydelig når du arbeider med tabeller med mange kolonner. Operatoren $select fjerner umerkede kolonner fra resultatsettet, noe som resulterer i mer effektive spørringer.
Enhetstester:
// OnSelectColumns
Fact("Fold $select single column",
#table( type table [AirlineCode = text] , {{"AA"}} ),
Table.FirstN(Table.SelectColumns(Airlines, {"AirlineCode"}), 1)
),
Fact("Fold $select multiple column",
#table( type table [UserName = text, FirstName = text, LastName = text],{{"russellwhyte", "Russell", "Whyte"}}),
Table.FirstN(Table.SelectColumns(People, {"UserName", "FirstName", "LastName"}), 1)
),
Fact("Fold $select with ignore column",
#table( type table [AirlineCode = text] , {{"AA"}} ),
Table.FirstN(Table.SelectColumns(Airlines, {"AirlineCode", "DoesNotExist"}, MissingField.Ignore), 1)
),
De to første testene velger forskjellige antall kolonner med Table.SelectColumns, og inkluderer et Table.FirstN-kall for å forenkle testtilfellet.
Merk
Hvis testen bare skulle returnere kolonnenavnene (ved hjelp av Table.ColumnNames og ikke noen data, sendes aldri forespørselen til OData-tjenesten. Dette er fordi kallet skal GetType returnere skjemaet, som inneholder all informasjonen M-motoren trenger for å beregne resultatet.
Den tredje testen bruker alternativet MissingField.Ignore , som ber M-motoren om å ignorere eventuelle valgte kolonner som ikke finnes i resultatsettet. Behandleren OnSelectColumns trenger ikke å bekymre seg for dette alternativet – M-motoren håndterer det automatisk (det vil si at manglende kolonner ikke er inkludert i columns listen).
Merk
Det andre alternativet for Table.SelectColumns, MissingField.UseNull, krever en kobling for å implementere behandleren OnAddColumn . Dette gjøres i en senere leksjon.
Implementeringen for OnSelectColumns gjør to ting:
- Legger til listen over valgte kolonner i
state. - Beregner verdien på nytt
Schema, slik at du kan angi riktig tabelltype.
OnSelectColumns = (columns as list) =>
let
// get the current schema
currentSchema = CalculateSchema(state),
// get the columns from the current schema (which is an M Type value)
rowRecordType = Type.RecordFields(Type.TableRow(currentSchema)),
existingColumns = Record.FieldNames(rowRecordType),
// calculate the new schema
columnsToRemove = List.Difference(existingColumns, columns),
updatedColumns = Record.RemoveFields(rowRecordType, columnsToRemove),
newSchema = type table (Type.ForRecord(updatedColumns, false))
in
@View(state &
[
SelectColumns = columns,
Schema = newSchema
]
),
CalculateUrl oppdateres for å hente listen over kolonner fra tilstanden, og kombinerer dem (med et skilletegn) for parameteren $select .
// Check for explicitly selected columns
qsWithSelect =
if (state[SelectColumns]? <> null) then
qsWithSkip & [ #"$select" = Text.Combine(state[SelectColumns], ",") ]
else
qsWithSkip,
Behandle Table.Sorter med OnSort
Behandleren OnSort mottar en liste over oppføringer av typen:
type [ Name = text, Order = Int16.Type ]
Hver post inneholder et Name felt som angir navnet på kolonnen, og et Order felt som er lik Order.Ascending eller Order.Descending.
I OData-termer tilordnes denne operasjonen til $orderby spørringsalternativet .
Syntaksen $orderby har kolonnenavnet etterfulgt av asc eller desc for å angi stigende eller synkende rekkefølge. Når du sorterer etter flere kolonner, skilles verdiene med et komma. Hvis parameteren columns inneholder mer enn ett element, er det viktig å opprettholde rekkefølgen de vises i.
Enhetstester:
// OnSort
Fact("Fold $orderby single column",
#table( type table [AirlineCode = text, Name = text], {{"TK", "Turkish Airlines"}}),
Table.FirstN(Table.Sort(Airlines, {{"AirlineCode", Order.Descending}}), 1)
),
Fact("Fold $orderby multiple column",
#table( type table [UserName = text], {{"javieralfred"}}),
Table.SelectColumns(Table.FirstN(Table.Sort(People, {{"LastName", Order.Ascending}, {"UserName", Order.Descending}}), 1), {"UserName"})
)
Implementering:
// OnSort - receives a list of records containing two fields:
// [Name] - the name of the column to sort on
// [Order] - equal to Order.Ascending or Order.Descending
// If there are multiple records, the sort order must be maintained.
//
// OData allows you to sort on columns that do not appear in the result
// set, so we do not have to validate that the sorted columns are in our
// existing schema.
OnSort = (order as list) =>
let
// This will convert the list of records to a list of text,
// where each entry is "<columnName> <asc|desc>"
sorting = List.Transform(order, (o) =>
let
column = o[Name],
order = o[Order],
orderText = if (order = Order.Ascending) then "asc" else "desc"
in
column & " " & orderText
),
orderBy = Text.Combine(sorting, ", ")
in
@View(state & [ OrderBy = orderBy ]),
Oppdateringer tilCalculateUrl:
qsWithOrderBy =
if (state[OrderBy]? <> null) then
qsWithSelect & [ #"$orderby" = state[OrderBy] ]
else
qsWithSelect,
Behandle Table.RowCount med GetRowCount
I motsetning til de andre spørringsbehandlingene du implementerer, returnerer behandleren GetRowCount én enkelt verdi – antall rader som forventes i resultatsettet. I en M-spørring vil denne verdien vanligvis være resultatet av transformasjonen Table.RowCount .
Du har noen ulike alternativer for hvordan du håndterer denne verdien som en del av en OData-spørring:
- Den $count spørringsparameteren, som returnerer antallet som et eget felt i resultatsettet.
- Banesegmentet /$count, som bare returnerer totalt antall, som en skalarverdi.
Ulempen med spørringsparametertilnærmingen er at du fortsatt må sende hele spørringen til OData-tjenesten. Siden antallet er innebygd igjen som en del av resultatsettet, må du behandle den første siden med data fra resultatsettet. Selv om denne prosessen fremdeles er mer effektiv enn å lese hele resultatsettet og telle radene, er den sannsynligvis fortsatt mer arbeid enn du vil gjøre.
Fordelen med fremgangsmåten for banesegmentet er at du bare får én skalarverdi i resultatet. Denne tilnærmingen gjør hele operasjonen mye mer effektiv. Men, som beskrevet i OData-spesifikasjonen, returnerer /$count banesegmentet en feil hvis du inkluderer andre spørringsparametere, for eksempel $top eller $skip, som begrenser nytten.
I denne opplæringen GetRowCount implementerte du behandlingsprogrammet ved hjelp av fremgangsmåten for banesegmentet. Hvis du vil unngå feilene du får hvis andre spørringsparametere er inkludert, så du etter andre tilstandsverdier og returnerte en «uimplementert feil» (...) hvis du fant noen. Hvis du returnerer en feil fra en Table.View-behandling , forteller M-motoren at operasjonen ikke kan brettes, og den bør falle tilbake til standardbehandlingen i stedet (som i dette tilfellet teller det totale antallet rader).
Først legger du til en enhetstest:
// GetRowCount
Fact("Fold $count", 15, Table.RowCount(Airlines)),
Siden banesegmentet /$count returnerer én enkelt verdi (i rent/tekstformat) i stedet for et JSON-resultatsett, må du også legge til en ny intern funksjon (TripPin.Scalar) for å gjøre forespørselen og håndtere resultatet.
// Similar to TripPin.Feed, but is expecting back a scalar value.
// This function returns the value from the service as plain text.
TripPin.Scalar = (url as text) as text =>
let
_url = Diagnostics.LogValue("TripPin.Scalar url", url),
headers = DefaultRequestHeaders & [
#"Accept" = "text/plain"
],
response = Web.Contents(_url, [ Headers = headers ]),
toText = Text.FromBinary(response)
in
toText;
Implementeringen bruker deretter denne funksjonen (hvis ingen andre spørringsparametere finnes i state):
GetRowCount = () as number =>
if (Record.FieldCount(Record.RemoveFields(state, {"Url", "Entity", "Schema"}, MissingField.Ignore)) > 0) then
...
else
let
newState = state & [ RowCountOnly = true ],
finalUrl = CalculateUrl(newState),
value = TripPin.Scalar(finalUrl),
converted = Number.FromText(value)
in
converted,
Funksjonen CalculateUrl oppdateres for å føye /$count til url-adressen hvis RowCountOnly feltet er angitt i state.
// Check for $count. If all we want is a row count,
// then we add /$count to the path value (following the entity name).
urlWithRowCount =
if (state[RowCountOnly]? = true) then
urlWithEntity & "/$count"
else
urlWithEntity,
Den nye Table.RowCount enhetstesten skal nå bestå.
Hvis du vil teste reservetilfellet, legger du til en ny test som tvinger feilen.
Først legger du til en hjelpemetode som kontrollerer resultatet av en try operasjon for en foldingsfeil.
// Returns true if there is a folding error, or the original record (for logging purposes) if not.
Test.IsFoldingError = (tryResult as record) =>
if ( tryResult[HasError]? = true and tryResult[Error][Message] = "We couldn't fold the expression to the data source. Please try a simpler expression.") then
true
else
tryResult;
Legg deretter til en test som bruker både Table.RowCount og Table.FirstN til å fremtvinge feilen.
// test will fail if "Fail on Folding Error" is set to false
Fact("Fold $count + $top *error*", true, Test.IsFoldingError(try Table.RowCount(Table.FirstN(Airlines, 3)))),
Et viktig notat her er at denne testen nå returnerer en feil hvis feil ved delegeringsfeil er satt til false, fordi Table.RowCount operasjonen faller tilbake til den lokale (standard) behandleren. Hvis du kjører testene med feil ved delegeringsfeil satt til true årsaker til å mislykkes Table.RowCount , og testen kan lykkes.
Konklusjon
Implementering av Table.View for koblingen legger til en betydelig mengde kompleksitet i koden. Siden M-motoren kan behandle alle transformasjoner lokalt, aktiverer ikke det å legge til Table.View-behandlere nye scenarier for brukerne, men resulterer i mer effektiv behandling (og potensielt lykkeligere brukere). En av de viktigste fordelene med at Table.View-behandlere er valgfrie, er at den lar deg trinnvis legge til ny funksjonalitet uten å påvirke bakoverkompatibiliteten for koblingen.
For de fleste koblinger er OnTake en viktig (og grunnleggende) behandling å implementere (som oversettes til $top i OData), da det begrenser antall rader som returneres. Power Query-opplevelsen utfører alltid en OnTake rekke 1000 rader når du viser forhåndsvisninger i navigatøren og redigeringsprogrammet for spørring, slik at brukerne kan se betydelige ytelsesforbedringer når de arbeider med større datasett.