Sampling med høy tetthet i Power BI-punktdiagrammer
Samplingsalgoritmen for Power BI forbedrer hvordan punktdiagrammer representerer data med høy tetthet.
Du kan for eksempel opprette et punktdiagram fra organisasjonens salgsaktivitet, der hver butikk har titusenvis av datapunkter hvert år. Et punktdiagram med slik informasjon vil eksempeldata fra en meningsfull representasjon av disse dataene for å illustrere hvordan salget skjedde over tid. Detaljene for datautvalg med høy tetthet er beskrevet i denne artikkelen.

Merk
Samplingsalgoritmen med høy tetthet som er beskrevet i denne artikkelen, er tilgjengelig i punktdiagrammene for både Power BI Desktop og Power Bi-tjeneste.
Slik fungerer punktdiagrammer med høy tetthet
Tidligere valgte Power BI en samling eksempeldatapunkter i hele utvalget av underliggende data på en deterministisk måte for å opprette et punktdiagram. Spesielt ville Power BI velge de første og siste radene med data i punktdiagramserien, og deretter dele de gjenværende radene jevnt slik at totalt 3500 datapunkter ble tegnet inn i punktdiagrammet. Hvis eksempelet hadde 35 000 rader, ble de første og siste radene valgt for plotting, og hver tiende rad ble også tegnet inn (35 000 / 10 = hver tiende rad = 3500 datapunkter). Tidligere ble ikke nullverdier eller punkter som ikke kunne tegnes inn, for eksempel tekstverdier, i dataserier, vist, og dermed ikke vurdert når visualobjektet ble generert. Med en slik sampling var den oppfattede tettheten til punktdiagrammet også basert på de representative datapunktene, så den underforståtte visuelle tettheten var en omstendighet for de samplede punktene, ikke den fullstendige samlingen av de underliggende dataene.
Når du aktiverer sampling med høy tetthet, implementerer Power BI en algoritme som eliminerer overlappende punkter og sikrer at punktene på visualobjektet kan nås når du samhandler med visualobjektet. Algoritmen sikrer også at alle punkter i datasettet er representert i visualobjektet, noe som gir kontekst til betydningen av valgte punkter, i stedet for bare å plotte et representativt utvalg.
Per definisjon er data med høy tetthet samplet for å opprette visualiseringer som reagerer på interaktivitet. For mange datapunkter på et visualobjekt kan redusere det og forringe synligheten av trender. Måten data er samplet på driver opprettelsen av samplingsalgoritmen for å gi den beste visualiseringsopplevelsen og sikre at alle dataene er representert. I Power BI forbedres algoritmen for å gi den beste kombinasjonen av respons, representasjon og klar bevaring av viktige punkter i det generelle datasettet.
Merk
Punktdiagrammer som bruker samplingsalgoritmen med høy tetthet, tegnes best inn på firkantede visualobjekter, som med alle punktdiagrammer.
Slik fungerer samplingsalgoritmen for punktdiagram
Algoritmen for sampling med høy tetthet for punktdiagrammer bruker metoder som registrerer og representerer de underliggende dataene mer effektivt og eliminerer overlappende punkter. Algoritmen starter med en liten radius for hvert datapunkt, som er den visuelle sirkelstørrelsen for et gitt punkt på visualiseringen. Den øker deretter radiusen for alle datapunkter. Når to eller flere datapunkter overlapper hverandre, representerer en enkelt sirkel av den økte radiusstørrelsen de overlappende datapunktene. Algoritmen fortsetter å øke radiusen for datapunkter til radiusverdien resulterer i at et rimelig antall datapunkter (3500) vises i punktdiagrammet.
Metodene i denne algoritmen sikrer at ytterpunkter er representert i det resulterende visualobjektet. Algoritmen respekterer skala når du bestemmer overlapping også, slik at eksponentielle skalaer visualiseres med gjengivelse til de underliggende visualiserte punktene.
Algoritmen bevarer også den generelle formen på punktdiagrammet.
Merk
Når du bruker samplingsalgoritmen med høy tetthet for punktdiagrammer, er nøyaktig fordeling av dataene målet, ikke underforstått visuell tetthet. Du kan for eksempel se et punktdiagram med mange sirkler som overlapper (tetthet) i et bestemt område, og tenk deg at mange datapunkter må grupperes der. Siden samplingsalgoritmen med høy tetthet kan bruke én sirkel til å representere mange datapunkter, vises ikke slik underforstått visuell tetthet eller "klynger". Hvis du vil ha flere detaljer i et gitt område, kan du bruke slicere til å zoome inn.
I tillegg ignoreres datapunkter som ikke kan tegnes inn, for eksempel nullverdier eller tekstverdier, slik at en annen verdi som kan tegnes inn, velges. Dette sikrer videre at den sanne formen på punktdiagrammet opprettholdes.
Når standardalgoritmen for punktdiagrammer brukes
Det er tilfeller der sampling med høy tetthet ikke kan brukes på et punktdiagram, og den opprinnelige algoritmen brukes. Disse omstendighetene er:
Hvis du høyreklikker en verdi under Verdier og setter den til Vis elementer uten data fra menyen, går punktdiagrammet tilbake til den opprinnelige algoritmen.
Alle verdier i Avspillingsakse-feltet fører til at punktdiagrammet går tilbake til den opprinnelige algoritmen.
Hvis både X- og Y-akser mangler i et punktdiagram, tilbakestilles diagrammet til den opprinnelige algoritmen.
Hvis du bruker en forholdslinje i analyseruten , vil diagrammet gå tilbake til den opprinnelige algoritmen.
Slik aktiverer du sampling med høy tetthet for et punktdiagram
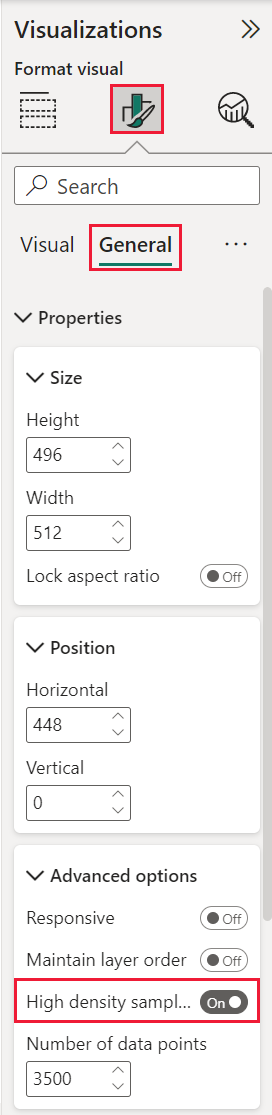
Hvis du vil bytte sampling med høy tetthet til På, velger du et punktdiagram, går til Formater visualobjekt-ruten , utvider Generelt-kortet og skyver glidebryteren med høy tetthet til På nær bunnen av kortet.
Merk
Når bryteren er slått på, prøver Power BI å bruke samplingsalgoritmen med høy tetthet når det er mulig. Når algoritmen ikke kan brukes, for eksempel når du plasserer en verdi i Avspilling-aksen , forblir bryteren på selv om diagrammet har gått tilbake til standardalgoritmen. Hvis du deretter fjerner en verdi fra Spill av-aksen, eller hvis betingelsene endres for å aktivere bruk av samplingsalgoritmen med høy tetthet, vil diagrammet automatisk bruke sampling med høy tetthet for diagrammet fordi funksjonen er aktiv.
Merk
Datapunkter grupperes eller velges av indeksen. Å ha en forklaring påvirker ikke sampling for algoritmen. Det påvirker bare rekkefølgen på visualobjektet.
Hensyn og begrensninger
Samplingsalgoritmen med høy tetthet er en viktig forbedring av Power BI. Samplingsalgoritmen med høy tetthet fungerer imidlertid bare med live-tilkoblinger til Power Bi-tjeneste-baserte modeller, importerte modeller eller DirectQuery.