Oversikt over årsaksanalyse
Årsaksanalyse gjør at du kan finne skjulte tilkoblinger i dataene. Det blir for eksempel enklere å forstå hvorfor noen saker tar lengre tid å fullføre enn andre, eller hvorfor noen saker låser seg fast i etterbehandlinger mens andre kjører uten problemer. Årsaksanalyse viser de viktige forskjellene mellom slike saker.
Obligatoriske data
Årsaksanalyse kan bruke alle attributter, måleverdier og egne måleverdier på saksnivå til å finne tilkoblinger blant dem, og en måleverdi du velger.
Det beste eksemplet er hvis du tar med alle dataene du kan, som et attributt på saksnivå, og lar årsaksanalyse velge hvilket attributt som faktisk virker inn på måleverdien, og hvilket som ikke gjør det.
Slik fungerer årsaksanalyse
Algoritmen for årsaksanalyse beregner en trestruktur der hver node deler datasettet i to mindre deler. Dette er basert på én variabel der den finner den beste korrelasjonen mellom variabeldelingen og målmåleverdien. Fra dette kan du se de skjulte tilkoblingene i dataene. Her får du vite hvilken kombinasjon av attributter som virker inn på saken, og hvordan.
Slik finner årsaksanalyse den beste delingen
Vi genererer først flere hundre eller flere tusen kombinasjoner av mulige delinger. Så prøver vi hver deling for å finne ut hvor godt datasettet deles i to deler. Vi beregner variasjonen i hovedmåleverdien i hver del av delingen og beregner poengsummen for hver deling med følgende beregning:
poengsumsplit_x = avvikleft * antall sakerleft + avvikright * antall sakerright
Vi sorterer deretter alle delinger etter denne poengsummen, og de beste delingene tas fra begynnelsen, med lavest poengsum. Når det gjelder den kategoriske hovedmåleverdien (streng), beregner vi Gini-urenhet i stedet for avvik.
Eksempel på årsaksanalyse
I dette eksemplet ønsker vi å se årsaken til saksvarigheten. I dataene har vi attributtene leverandørland, leverandørpoststed, materiale, totalbeløp og kostnadssenter på saksnivå. Den gjennomsnittlige saksvarigheten er 46 timer.
Når vi ser på hver verdi til hvert attributt separat, ser vi at den største innvirkningen på saksvarighet forekommer når leverandørpoststed er Graz, som i gjennomsnitt øker varigheten til saken med ytterligere 15 timer. Vi kan se fra denne innledende analysen at de andre attributtverdiene har mye mindre innvirkning på målmåleverdien. Når vi beregner tremodellen, kan vi imidlertid se at beregningen ovenfor er misvisende (som på skjermbildet nedenfor).
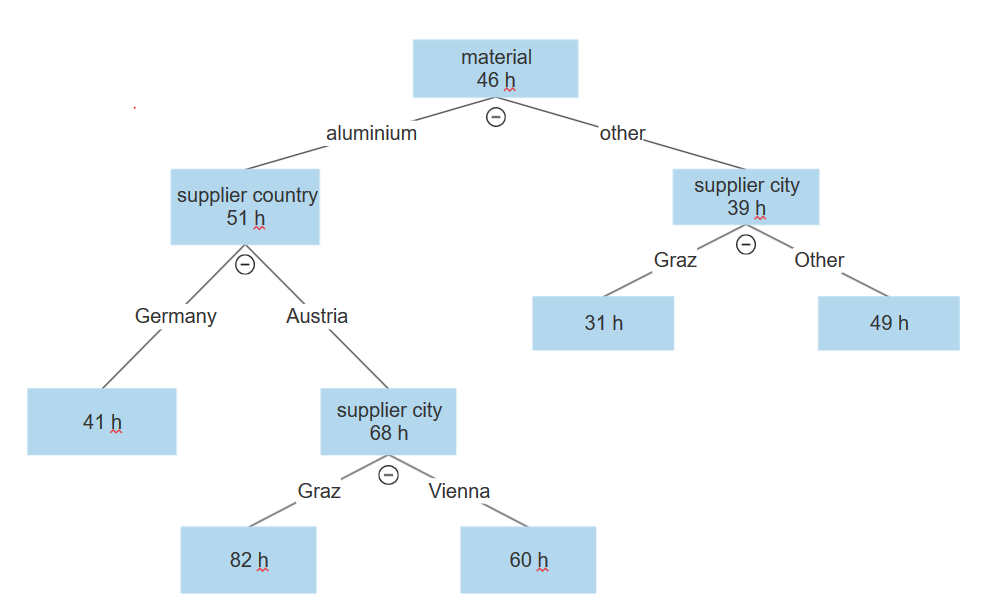
Trestrukturen ser slik ut:
Den første delingen er dataene langs variabelen materiale. Dataene med aluminium er på den ene siden og alle andre materialer er på den andre siden.
Grenen aluminium deles ytterligere etter leverandørland i Tyskland og Østerrike.
Grenen Østerrike fortsetter med en deling et leverandørpoststed, der Graz er på den ene siden og Wien er på den andre.
I noden Graz var den gjennomsnittlige saken 36 timer langsommere enn den totale gjennomsnittlige varigheten på 46 timer.
I det samme treet kan vi se at hvis vi har et annet materiale enn aluminium, deles det også etter variabelen leverandørpoststed, der Graz er på den ene siden og Wien, München eller Frankfurt er på den andre. Men her er verdiene motsatt. Graz har mye bedre statistikk enn Wien eller andre tyske steder, der en gjennomsnittlig sak i Graz er 15 timer raskere enn det totale gjennomsnittet for alle saker.
Fra dette kan vi se at den innledende statistikken er villedende, fordi Graz har dårlig ytelse når materialet er aluminium. Ytelsen er imidlertid over gjennomsnittet når materialet er et annet enn aluminium, og er helt motsatt for andre steder.
Saksvarighetsinnvirkning tar bare hensyn til én verdi, og noen ganger kan det bli villedende. Årsaksanalyse tar hensyn til kombinasjoner av dem for å gi deg mer innsikt i prosessen.