Utføre OCR på flerspråklige dokumenter
Ocr gjør det mulig å finne og trekke ut tekst fra bilder eller skjermen.
Selv om de fleste scenarier krever at du håndterer tekst på et bestemt språk, kan det være tilfeller der kildene er flerspråklige.
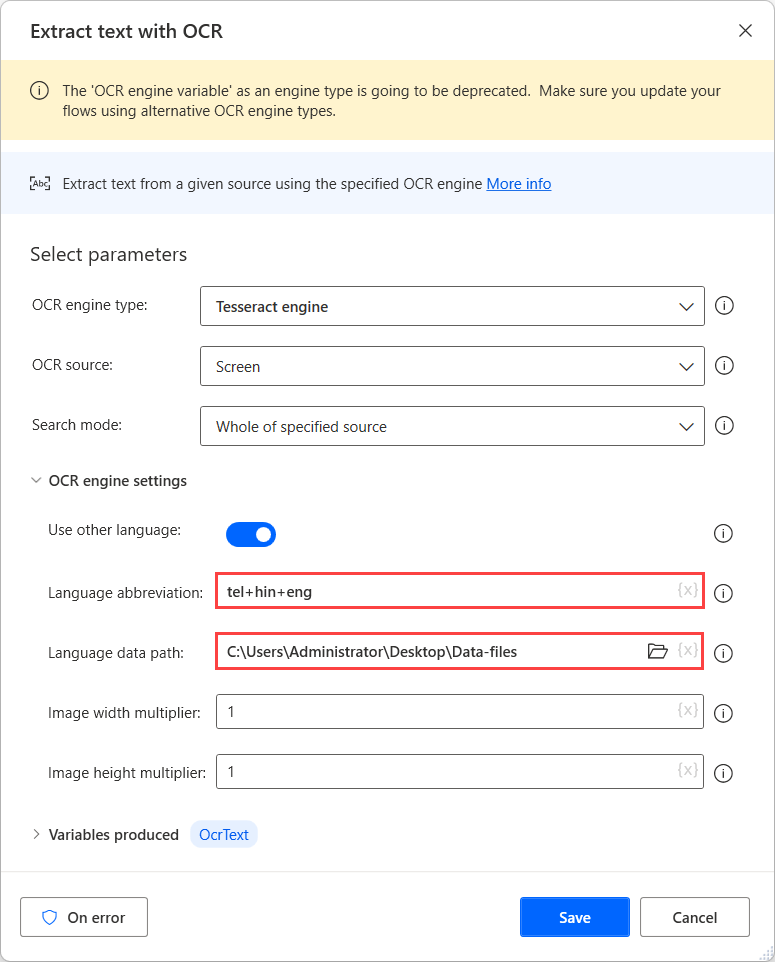
Hvis du vil utføre OCR på disse kildene, bruker du en Tesseract-motor i den respektive OCR-handlingen og aktiverer alternativet Bruk andre språk i motorinnstillingene.
Når alternativet Bruk andre språk er aktivert, viser handlingen to tilleggsinnstillinger: feltene Språkforkortelse og Bane til språkdata.
Feltet Språkforkortelse angir for motoren hvilket språk det skal søkes etter under OCR. Feltet Bane til språkdata inneholder språkdatafilene (.traineddata) som brukes til å lære opp OCR-motoren.
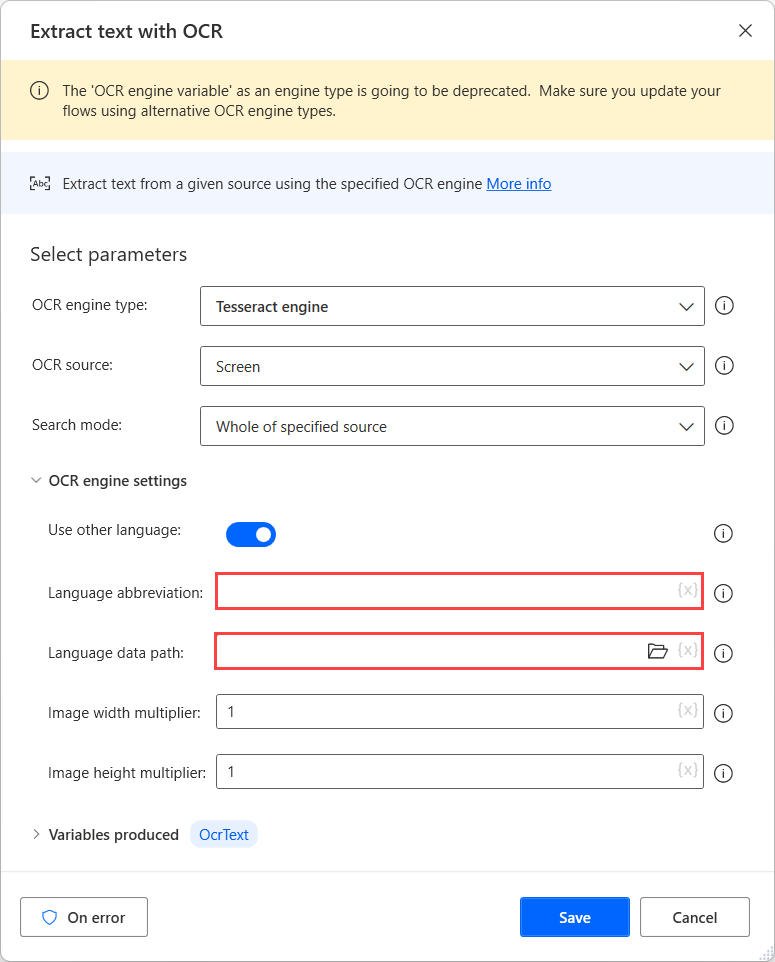
Når du har lastet ned datafilene for de nødvendige språkene, flytter du dem til en fellesmappe for å gjøre dem tilgjengelige under samme bane.
Deretter velger du den opprettede mappen i feltet Språkdatabaner og fyller ut de tilsvarende språkkodene i feltet Språkforkortelse. Hvis du vil skille språkkodene, bruker du plusstegnet (+).
Merk
Du finner alle tilgjengelige språkkoder i kilden for språkdatafilene. I følgende eksempel representerer de brukte kodene telugu, hindi og engelsk.