Flervariat avviksregistrering
Hvis du vil ha generell informasjon om multivariate avviksregistrering i sanntidsintelligens, kan du se Multivariate anomaly detection in Microsoft Fabric – oversikt. I denne opplæringen skal du bruke eksempeldata til å lære opp en flervariat avviksregistreringsmodell ved hjelp av Spark-motoren i en Python-notatblokk. Deretter forutser du avvik ved å bruke den opplærte modellen på nye data ved hjelp av Eventhouse-motoren. De første trinnene konfigurerer miljøene dine, og trinnene nedenfor lærer opp modellen og forutse avvik.
Forutsetning
- Et arbeidsområde med en Microsoft Fabric-aktivert kapasitet
- Rollen som administrator, bidragsyter eller medlem i arbeidsområdet. Dette tillatelsesnivået er nødvendig for å opprette elementer, for eksempel et miljø.
- Et hendelseshus i arbeidsområdet med en database.
- Last ned eksempeldataene fra GitHub-repositoriet
- Last ned notatblokken fra GitHub-repositoriet
Del 1 – Aktiver OneLake-tilgjengelighet
OneLake-tilgjengelighet må aktiveres før du henter data i Eventhouse. Dette trinnet er viktig, fordi det gjør at dataene du inntar, blir tilgjengelige i OneLake. I et senere trinn får du tilgang til de samme dataene fra Spark Notebook for å lære opp modellen.
Bla til hjemmesiden for arbeidsområdet i sanntidsintelligens.
Velg Eventhouse du opprettet i forutsetningene. Velg databasen der du vil lagre dataene.
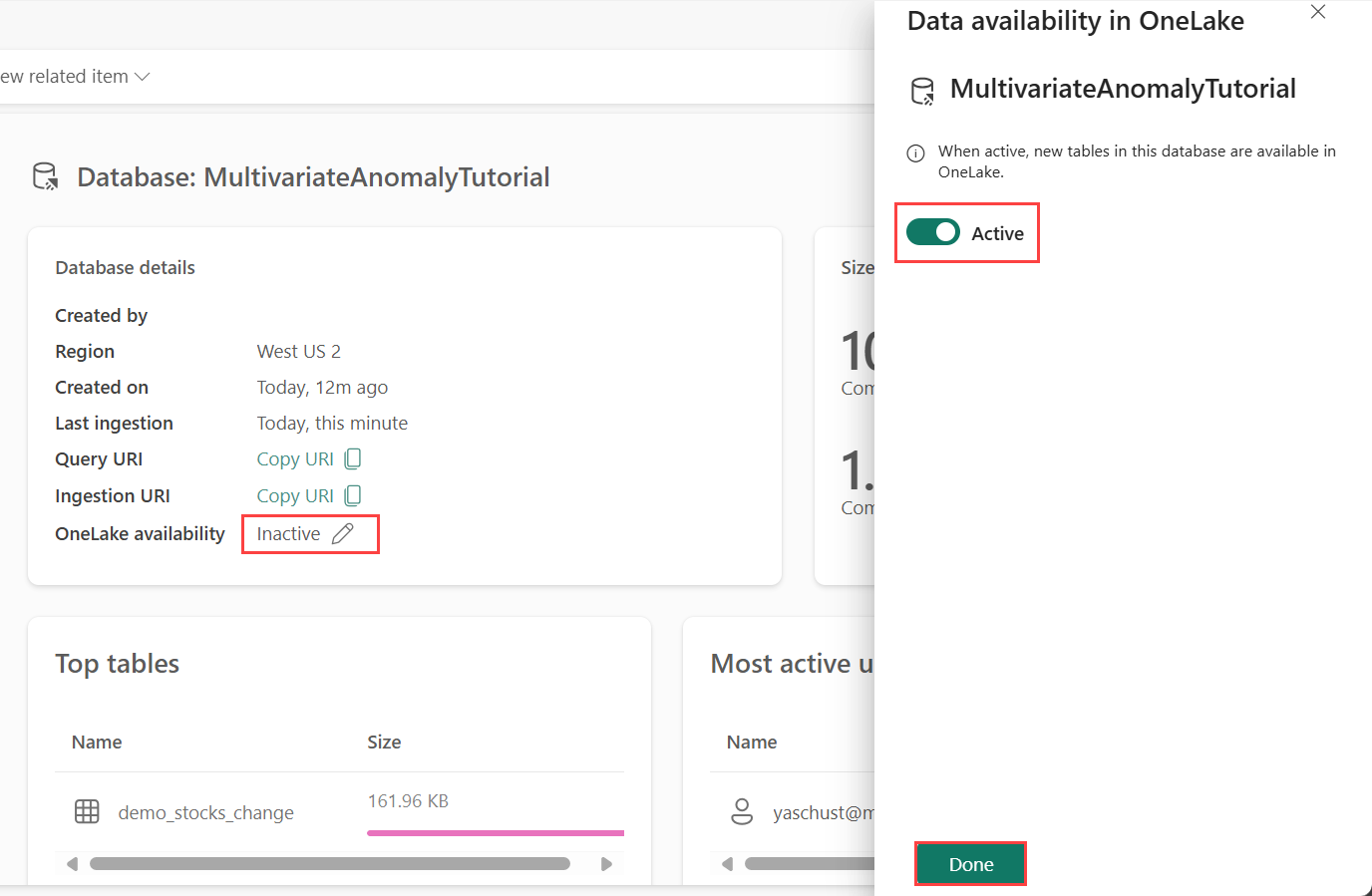
Velg blyantikonet ved siden av OneLake-tilgjengelighet i flisen Databasedetaljer
I ruten til høyre kan du veksle knappen til Aktiv.
Velg Ferdig.
Del 2 - Aktiver KQL Python-plugin-modul
I dette trinnet aktiverer du python-plugin-modulen i Eventhouse. Dette trinnet kreves for å kjøre Python-koden for forutsigelsesavvik i KQL-spørringssettet. Det er viktig å velge riktig pakke som inneholder time-series-anomaly-detector-pakken .
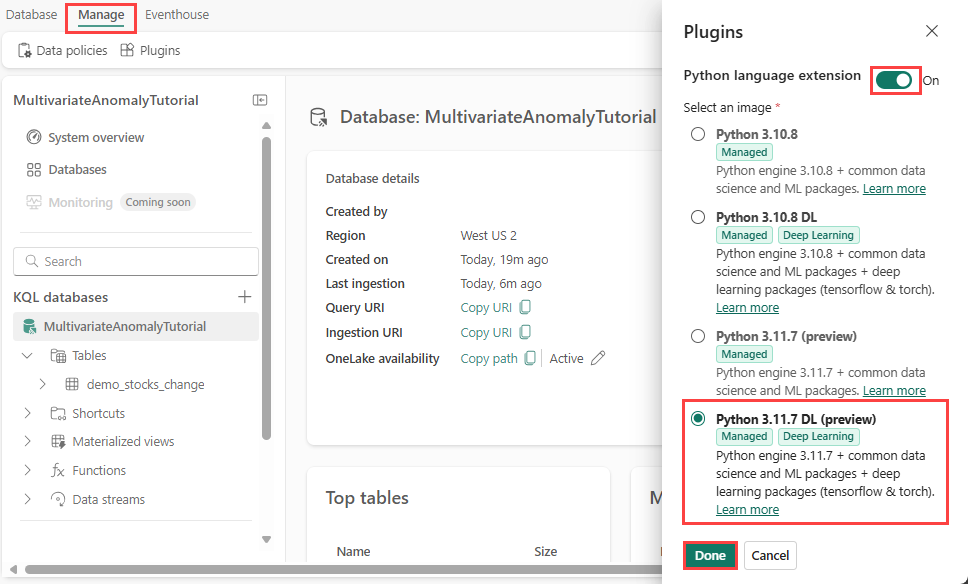
Velg databasen i Eventhouse-skjermen, og velg deretter Behandle plugin-moduler> fra båndet..
I Plugins-ruten kan du slå python-språkutvidelsen til På.
Velg Python 3.11.7 DL (forhåndsvisning).
Velg Ferdig.
Del 3 – Opprett et Spark-miljø
I dette trinnet oppretter du et Spark-miljø for å kjøre Python-notatblokken som trener den flervariate avviksregistreringsmodellen ved hjelp av Spark-motoren. Hvis du vil ha mer informasjon om hvordan du oppretter miljøer, kan du se Opprette og administrere miljøer.
Velg Dataingeniør i opplevelsesbryteren. Hvis du allerede er i Dataingeniør opplevelsen, kan du gå til Hjem.
Velg miljøer fra anbefalte elementer for å opprette, og skriv inn navnet MVAD_ENV for miljøet.
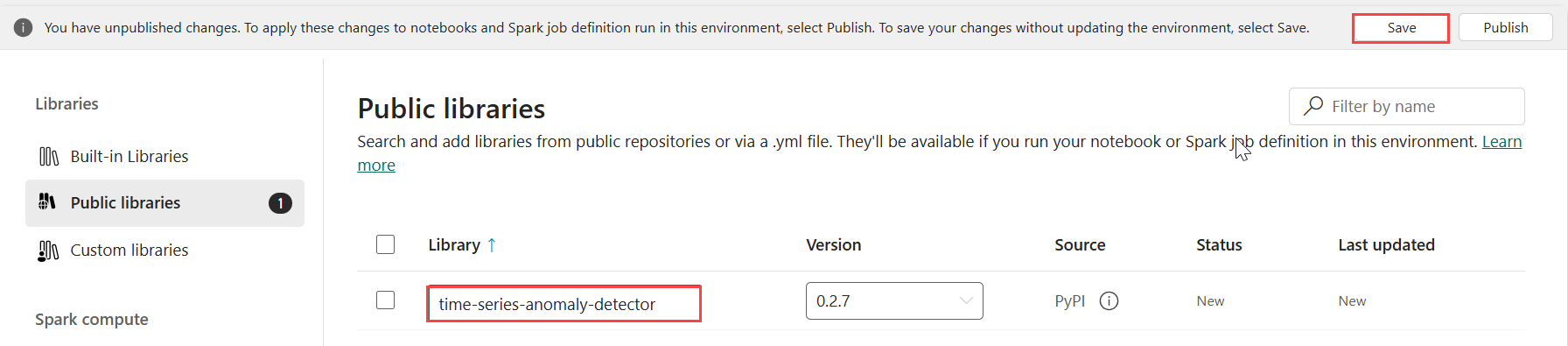
Velg Folkebiblioteker under Biblioteker.
Velg Legg til fra PyPI.
Skriv inn tidsserie-anomali-detektoren i søkeboksen. Versjonen fylles automatisk ut med den nyeste versjonen. Denne opplæringen ble opprettet ved hjelp av versjon 0.2.7, som er versjonen som er inkludert i Kusto Python 3.11.7 DL.
Velg Lagre.
Velg Hjem-fanen i miljøet.
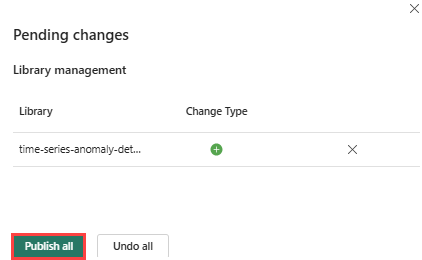
Velg Publiser-ikonet på båndet.

Velg Publiser alle. Dette trinnet kan ta flere minutter å fullføre.
Del 4– Hent data inn i Eventhouse
Hold pekeren over KQL-databasen der du vil lagre dataene. Velg Mer-menyen [...]>Hent lokal datafil>.
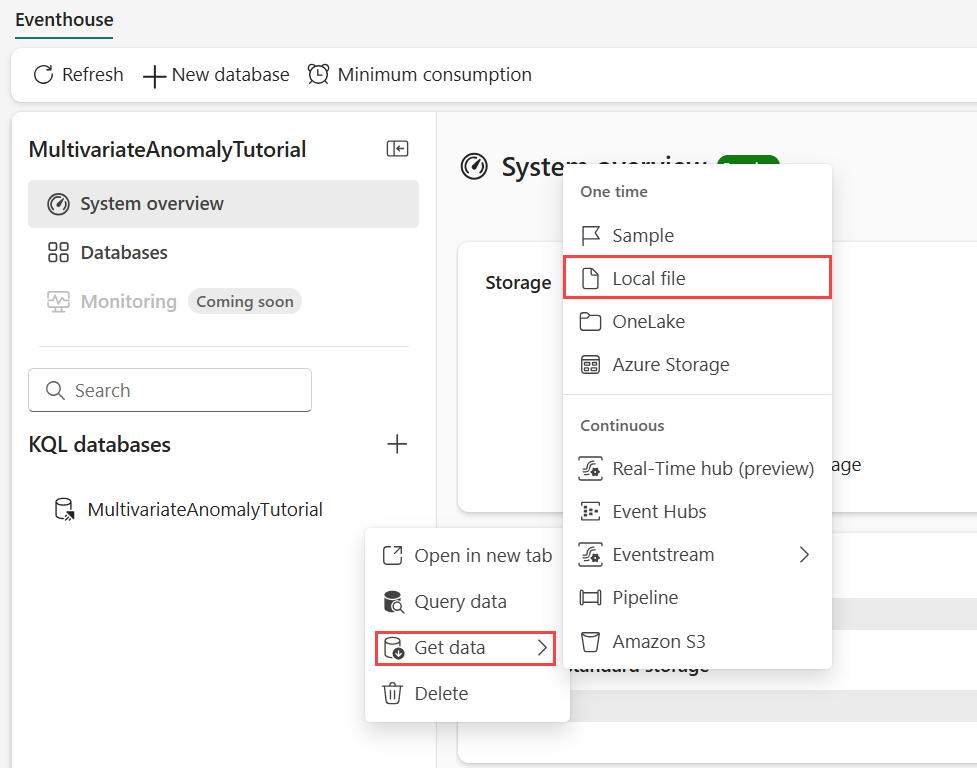
Velg + Ny tabell , og skriv inn demo_stocks_change som tabellnavn.
Velg Bla gjennom etter filer i dialogboksen opplastingsdata, og last opp eksempeldatafilen som ble lastet ned i forutsetningene
Velg Neste.
I Undersøk data-delen er aktiver/deaktiver første rad kolonneoverskriften til På.
Velg Fullfør.
Når dataene lastes opp, velger du Lukk.
Del 5 – Kopier OneLake-banen til tabellen
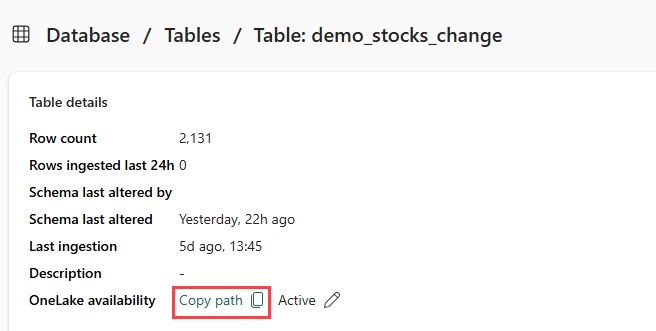
Kontroller at du velger demo_stocks_change tabellen. Velg Kopier bane i Tabelldetaljer-flisen for å kopiere OneLake-banen til utklippstavlen. Lagre denne kopierte teksten i et tekstredigeringsprogram et sted som skal brukes i et senere trinn.
Del 6– Klargjør notatblokken
Velg Utvikle og velg arbeidsområdet i opplevelsesbryteren.
Velg Importer, Notatblokk og deretter Fra denne datamaskinen.
Velg Last opp, og velg notatblokken du lastet ned i forutsetningene.
Når notatblokken er lastet opp, kan du finne og åpne notatblokken fra arbeidsområdet.
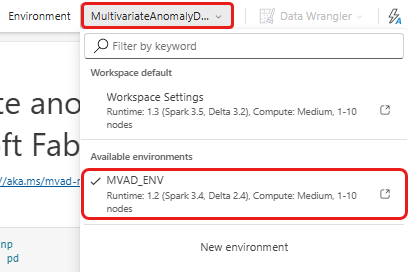
Velg rullegardinlisten arbeidsområde på det øverste båndet, og velg miljøet du opprettet i forrige trinn.
Del 7 – Kjør notatblokken
Importer standardpakker.
import numpy as np import pandas as pdSpark trenger en ABFSS URI for å koble til OneLake-lagring på en sikker måte, så neste trinn definerer denne funksjonen for å konvertere OneLake URI til ABFSS URI.
def convert_onelake_to_abfss(onelake_uri): if not onelake_uri.startswith('https://'): raise ValueError("Invalid OneLake URI. It should start with 'https://'.") uri_without_scheme = onelake_uri[8:] parts = uri_without_scheme.split('/') if len(parts) < 3: raise ValueError("Invalid OneLake URI format.") account_name = parts[0].split('.')[0] container_name = parts[1] path = '/'.join(parts[2:]) abfss_uri = f"abfss://{container_name}@{parts[0]}/{path}" return abfss_uriSkriv inn OneLake-URI-en kopiert fra del 5– Kopier OneLake-banen til tabellen for å laste inn demo_stocks_change tabell i en pandas-dataramme.
onelake_uri = "OneLakeTableURI" # Replace with your OneLake table URI abfss_uri = convert_onelake_to_abfss(onelake_uri) print(abfss_uri)df = spark.read.format('delta').load(abfss_uri) df = df.toPandas().set_index('Date') print(df.shape) df[:3]Kjør følgende celler for å klargjøre datarammene for opplæring og prognoser.
Merk
De faktiske prognosene kjøres på data av Eventhouse i del 9- Predict-anomalies-in-the-kql-queryset. I et produksjonsscenario, hvis du strømmet data inn i hendelseshuset, ville prognosene bli gjort på de nye strømmedataene. I forbindelse med opplæringen er datasettet delt inn etter dato i to deler for opplæring og prognoser. Dette er for å simulere historiske data og nye data for strømming.
features_cols = ['AAPL', 'AMZN', 'GOOG', 'MSFT', 'SPY'] cutoff_date = pd.to_datetime('2023-01-01')train_df = df[df.Date < cutoff_date] print(train_df.shape) train_df[:3]train_len = len(train_df) predict_len = len(df) - train_len print(f'Total samples: {len(df)}. Split to {train_len} for training, {predict_len} for testing')Kjør cellene for å lære opp modellen og lagre den i Fabric MLflow-modellregisteret.
import mlflow from anomaly_detector import MultivariateAnomalyDetector model = MultivariateAnomalyDetector()sliding_window = 200 param s = {"sliding_window": sliding_window}model.fit(train_df, params=params)with mlflow.start_run(): mlflow.log_params(params) mlflow.set_tag("Training Info", "MVAD on 5 Stocks Dataset") model_info = mlflow.pyfunc.log_model( python_model=model, artifact_path="mvad_artifacts", registered_model_name="mvad_5_stocks_model", )# Extract the registered model path to be used for prediction using Kusto Python sandbox mi = mlflow.search_registered_models(filter_string="name='mvad_5_stocks_model'")[0] model_abfss = mi.latest_versions[0].source print(model_abfss)Kopier modell-URI-en fra den siste celleutdataene. Du bruker dette i et senere neste trinn.
Del 8 – Konfigurer KQL-spørringssettet
Hvis du vil ha generell informasjon, kan du se Opprette et KQL-spørringssett.
- Velg Sanntidsintelligens i opplevelsesbryteren.
- Velg arbeidsområdet.
- Velg +Nytt element>KQL Queryset. Skriv inn navnet MultivariateAnomalyDetectionTutorial.
- Velg Opprett.
- Velg KQL-databasen der du lagret dataene, i OneLake-datahubvinduet.
- Velg Koble til.
Del 9 – Forutsi avvik i KQL-spørringssettet
Kopier/lim inn, og kjør følgende spørring for create-or-alter-funksjonen for å definere den
predict_fabric_mvad_fl()lagrede funksjonen:.create-or-alter function with (folder = "Packages\\ML", docstring = "Predict MVAD model in Microsoft Fabric") predict_fabric_mvad_fl(samples:(*), features_cols:dynamic, artifacts_uri:string, trim_result:bool=false) { let s = artifacts_uri; let artifacts = bag_pack('MLmodel', strcat(s, '/MLmodel;impersonate'), 'conda.yaml', strcat(s, '/conda.yaml;impersonate'), 'requirements.txt', strcat(s, '/requirements.txt;impersonate'), 'python_env.yaml', strcat(s, '/python_env.yaml;impersonate'), 'python_model.pkl', strcat(s, '/python_model.pkl;impersonate')); let kwargs = bag_pack('features_cols', features_cols, 'trim_result', trim_result); let code = ```if 1: import os import shutil import mlflow model_dir = 'C:/Temp/mvad_model' model_data_dir = model_dir + '/data' os.mkdir(model_dir) shutil.move('C:/Temp/MLmodel', model_dir) shutil.move('C:/Temp/conda.yaml', model_dir) shutil.move('C:/Temp/requirements.txt', model_dir) shutil.move('C:/Temp/python_env.yaml', model_dir) shutil.move('C:/Temp/python_model.pkl', model_dir) features_cols = kargs["features_cols"] trim_result = kargs["trim_result"] test_data = df[features_cols] model = mlflow.pyfunc.load_model(model_dir) predictions = model.predict(test_data) predict_result = pd.DataFrame(predictions) samples_offset = len(df) - len(predict_result) # this model doesn't output predictions for the first sliding_window-1 samples if trim_result: # trim the prefix samples result = df[samples_offset:] result.iloc[:,-4:] = predict_result.iloc[:, 1:] # no need to copy 1st column which is the timestamp index else: result = df # output all samples result.iloc[samples_offset:,-4:] = predict_result.iloc[:, 1:] ```; samples | evaluate python(typeof(*), code, kwargs, external_artifacts=artifacts) }Kopier/lim inn følgende prognosespørring.
- Erstatt URI-en for utdatamodellen som ble kopiert i slutten av trinn 7.
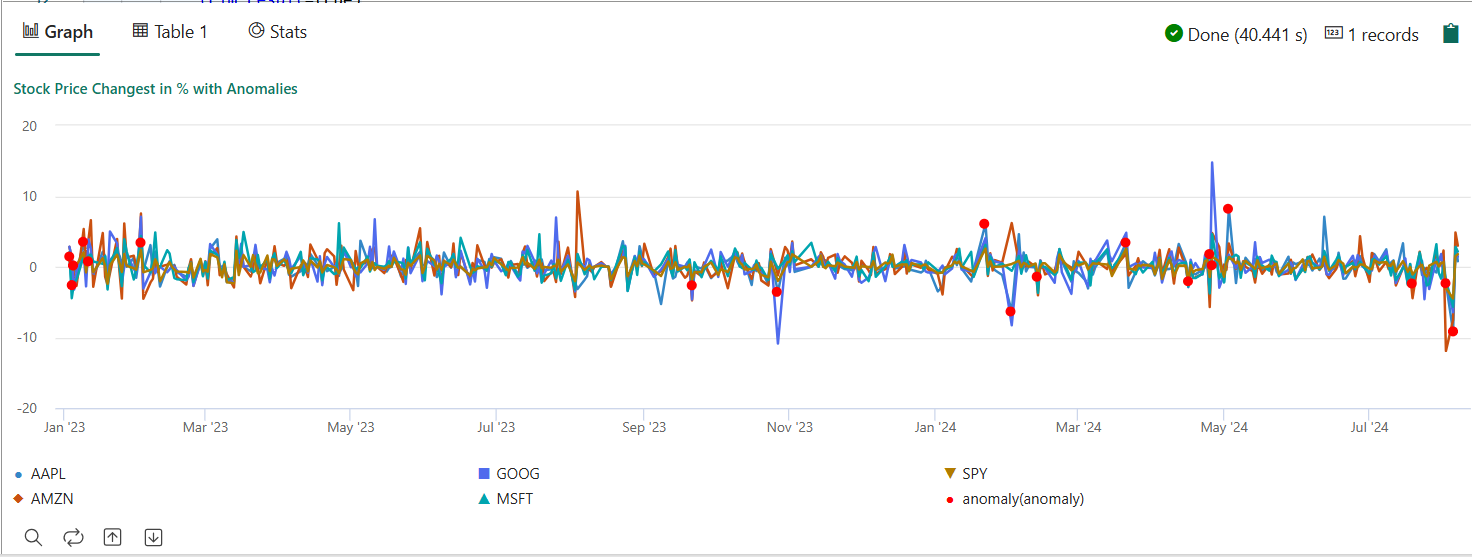
- Kjør spørringen. Den oppdager multivariate avvik på de fem bestandene, basert på den opplærte modellen, og gjengir resultatene som
anomalychart. De uregelmessige punktene gjengis på den første aksjen (AAPL), selv om de representerer multivariate anomalier (med andre ord avvik av de felles endringene i de fem bestandene i den spesifikke datoen).
let cutoff_date=datetime(2023-01-01); let num_predictions=toscalar(demo_stocks_change | where Date >= cutoff_date | count); // number of latest points to predict let sliding_window=200; // should match the window that was set for model training let prefix_score_len = sliding_window/2+min_of(sliding_window/2, 200)-1; let num_samples = prefix_score_len + num_predictions; demo_stocks_change | top num_samples by Date desc | order by Date asc | extend is_anomaly=bool(false), score=real(null), severity=real(null), interpretation=dynamic(null) | invoke predict_fabric_mvad_fl(pack_array('AAPL', 'AMZN', 'GOOG', 'MSFT', 'SPY'), // NOTE: Update artifacts_uri to model path artifacts_uri='enter your model URI here', trim_result=true) | summarize Date=make_list(Date), AAPL=make_list(AAPL), AMZN=make_list(AMZN), GOOG=make_list(GOOG), MSFT=make_list(MSFT), SPY=make_list(SPY), anomaly=make_list(toint(is_anomaly)) | render anomalychart with(anomalycolumns=anomaly, title='Stock Price Changest in % with Anomalies')
Det resulterende avviksdiagrammet skal se ut som følgende bilde:
Fjerning av ressurser
Når du er ferdig med opplæringen, kan du slette ressursene, du opprettet for å unngå å pådra deg andre kostnader. Følg disse trinnene for å slette ressursene:
- Bla til hjemmesiden for arbeidsområdet.
- Slett miljøet som er opprettet i denne opplæringen.
- Slett notatblokken som er opprettet i denne opplæringen.
- Slett Eventhouse eller databasen som brukes i denne opplæringen.
- Slett KQL-spørringssettet som er opprettet i denne opplæringen.