Hent data fra Kafka
Apache Kafka er en distribuert strømmeplattform for bygging av datasamlebånd i sanntid som på en pålitelig måte flytter data mellom systemer eller programmer. Kafka Connect er et verktøy for skalerbar og pålitelig strømming av data mellom Apache Kafka og andre datasystemer. Kusto Kafka Sink fungerer som koblingen fra Kafka og krever ikke bruk av kode. Last ned vaskkoblingskannen fra Git-repositoriet eller Confluent Connector Hub.
Denne artikkelen viser hvordan du inntar data med Kafka ved hjelp av et selvstendig Docker-oppsett for å forenkle konfigurasjonen av Kafka-klyngen og Kafka-koblingsklyngen.
Hvis du vil ha mer informasjon, kan du se koblingen Git-repositorium og versjonsspesifikke.
Forutsetning
- Et Azure-abonnement. Opprett en kostnadsfri Azure-konto.
- En KQL-database i Microsoft Fabric.
- URI-en for databaseinntak og URI for spørring som skal brukes i konfigurasjonsfilen for JSON. Hvis du vil ha mer informasjon, kan du se Kopier URI.
- Azure CLI.
- Docker og Docker Compose.
Opprette en Microsoft Entra-tjenestekontohaver
Microsoft Entra-tjenestekontohaveren kan opprettes gjennom Azure-portalen eller programatisk, som i eksemplet nedenfor.
Denne tjenestekontohaveren er identiteten som brukes av koblingen til å skrive data i tabellen i Kusto. Du gir denne tjenestekontohaveren tillatelse til å få tilgang til Kusto-ressurser.
Logg på Azure-abonnementet via Azure CLI. Deretter godkjenner du i nettleseren.
az loginVelg abonnementet som vert for hovedstolen. Dette trinnet er nødvendig når du har flere abonnementer.
az account set --subscription YOUR_SUBSCRIPTION_GUIDOpprett tjenestekontohaveren. I dette eksemplet kalles
my-service-principaltjenestekontohaveren .az ad sp create-for-rbac -n "my-service-principal" --role Contributor --scopes /subscriptions/{SubID}Kopier ,
passwordogtenantfor fremtidig bruk,appIdfra de returnerte JSON-dataene.{ "appId": "00001111-aaaa-2222-bbbb-3333cccc4444", "displayName": "my-service-principal", "name": "my-service-principal", "password": "00001111-aaaa-2222-bbbb-3333cccc4444", "tenant": "00001111-aaaa-2222-bbbb-3333cccc4444" }
Du har opprettet Microsoft Entra-programmet og tjenestekontohaveren.
Opprette en måltabell
Opprett en tabell med
Stormsfølgende kommando fra spørringsmiljøet:.create table Storms (StartTime: datetime, EndTime: datetime, EventId: int, State: string, EventType: string, Source: string)Opprett tilsvarende tabelltilordning
Storms_CSV_Mappingfor inntatte data ved hjelp av følgende kommando:.create table Storms ingestion csv mapping 'Storms_CSV_Mapping' '[{"Name":"StartTime","datatype":"datetime","Ordinal":0}, {"Name":"EndTime","datatype":"datetime","Ordinal":1},{"Name":"EventId","datatype":"int","Ordinal":2},{"Name":"State","datatype":"string","Ordinal":3},{"Name":"EventType","datatype":"string","Ordinal":4},{"Name":"Source","datatype":"string","Ordinal":5}]'Opprett en inntaksgruppepolicy i tabellen for konfigurerbar ventetid i kø.
Tips
Policyen for inntaksgruppering er en ytelsesoptimalisering og inkluderer tre parametere. Den første betingelsen som er oppfylt utløser inntak i tabellen.
.alter table Storms policy ingestionbatching @'{"MaximumBatchingTimeSpan":"00:00:15", "MaximumNumberOfItems": 100, "MaximumRawDataSizeMB": 300}'Bruk tjenestekontohaveren fra Opprett en Microsoft Entra-tjenestekontohaver til å gi tillatelse til å arbeide med databasen.
.add database YOUR_DATABASE_NAME admins ('aadapp=YOUR_APP_ID;YOUR_TENANT_ID') 'AAD App'
Kjør laboratoriet
Følgende laboratorium er utformet for å gi deg opplevelsen av å begynne å opprette data, konfigurere Kafka-koblingen og strømme disse dataene. Deretter kan du se på de inntatte dataene.
Klon git-repositoriet
Klone laboratoriets git repo.
Opprett en lokal katalog på maskinen.
mkdir ~/kafka-kusto-hol cd ~/kafka-kusto-holKlone repo.
cd ~/kafka-kusto-hol git clone https://github.com/Azure/azure-kusto-labs cd azure-kusto-labs/kafka-integration/dockerized-quickstart
Innholdet i klonet repo
Kjør følgende kommando for å vise innholdet i det klonede repoet:
cd ~/kafka-kusto-hol/azure-kusto-labs/kafka-integration/dockerized-quickstart
tree
Dette resultatet av dette søket er:
├── README.md
├── adx-query.png
├── adx-sink-config.json
├── connector
│ └── Dockerfile
├── docker-compose.yaml
└── storm-events-producer
├── Dockerfile
├── StormEvents.csv
├── go.mod
├── go.sum
├── kafka
│ └── kafka.go
└── main.go
Se gjennom filene i klonet repo
Avsnittene nedenfor forklarer de viktige delene av filene i filtreet ovenfor.
adx-sink-config.json
Denne filen inneholder kustovaskegenskapsfilen der du oppdaterer spesifikke konfigurasjonsdetaljer:
{
"name": "storm",
"config": {
"connector.class": "com.microsoft.azure.kusto.kafka.connect.sink.KustoSinkConnector",
"flush.size.bytes": 10000,
"flush.interval.ms": 10000,
"tasks.max": 1,
"topics": "storm-events",
"kusto.tables.topics.mapping": "[{'topic': 'storm-events','db': '<enter database name>', 'table': 'Storms','format': 'csv', 'mapping':'Storms_CSV_Mapping'}]",
"aad.auth.authority": "<enter tenant ID>",
"aad.auth.appid": "<enter application ID>",
"aad.auth.appkey": "<enter client secret>",
"kusto.ingestion.url": "<ingestion URI per prerequisites>",
"kusto.query.url": "<query URI per prerequisites>",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.storage.StringConverter"
}
}
Erstatt verdiene for følgende attributter i henhold til oppsettet: , , , kusto.tables.topics.mapping (databasenavnet), kusto.ingestion.urlog kusto.query.url. aad.auth.appkeyaad.auth.appidaad.auth.authority
Kobling - Dockerfile
Denne filen har kommandoene for å generere docker-bildet for tilkoblingsforekomsten. Den inneholder nedlastingen av koblingen fra utgivelseskatalogen for git-repositoriet.
Storm-events-produsent katalog
Denne katalogen har et Go-program som leser en lokal StormEvents.csv-fil og publiserer dataene til et Kafka-emne.
docker-compose.yaml
version: "2"
services:
zookeeper:
image: debezium/zookeeper:1.2
ports:
- 2181:2181
kafka:
image: debezium/kafka:1.2
ports:
- 9092:9092
links:
- zookeeper
depends_on:
- zookeeper
environment:
- ZOOKEEPER_CONNECT=zookeeper:2181
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092
kusto-connect:
build:
context: ./connector
args:
KUSTO_KAFKA_SINK_VERSION: 1.0.1
ports:
- 8083:8083
links:
- kafka
depends_on:
- kafka
environment:
- BOOTSTRAP_SERVERS=kafka:9092
- GROUP_ID=adx
- CONFIG_STORAGE_TOPIC=my_connect_configs
- OFFSET_STORAGE_TOPIC=my_connect_offsets
- STATUS_STORAGE_TOPIC=my_connect_statuses
events-producer:
build:
context: ./storm-events-producer
links:
- kafka
depends_on:
- kafka
environment:
- KAFKA_BOOTSTRAP_SERVER=kafka:9092
- KAFKA_TOPIC=storm-events
- SOURCE_FILE=StormEvents.csv
Start beholderne
Start beholderne i en terminal:
docker-compose upProdusentprogrammet begynner å sende hendelser til
storm-eventsemnet. Du bør se logger som ligner på følgende logger:.... events-producer_1 | sent message to partition 0 offset 0 events-producer_1 | event 2007-01-01 00:00:00.0000000,2007-01-01 00:00:00.0000000,13208,NORTH CAROLINA,Thunderstorm Wind,Public events-producer_1 | events-producer_1 | sent message to partition 0 offset 1 events-producer_1 | event 2007-01-01 00:00:00.0000000,2007-01-01 05:00:00.0000000,23358,WISCONSIN,Winter Storm,COOP Observer ....Hvis du vil kontrollere loggene, kjører du følgende kommando i en separat terminal:
docker-compose logs -f | grep kusto-connect
Start koblingen
Bruk en Kafka Connect REST-samtale for å starte koblingen.
Start vaskoppgaven med følgende kommando i en separat terminal:
curl -X POST -H "Content-Type: application/json" --data @adx-sink-config.json http://localhost:8083/connectorsHvis du vil kontrollere statusen, kjører du følgende kommando i en separat terminal:
curl http://localhost:8083/connectors/storm/status
Koblingen starter inntaksprosesser i kø.
Merk
Hvis du har problemer med loggkoblingen, kan du opprette et problem.
Spørrings- og gjennomgangsdata
Bekreft datainntak
Når dataene er ankommet i
Stormstabellen, bekrefter du overføringen av data ved å kontrollere radantallet:Storms | countBekreft at det ikke er noen feil i inntaksprosessen:
.show ingestion failuresNår du ser data, kan du prøve ut noen spørringer.
Spør etter dataene
Hvis du vil se alle postene, kjører du følgende spørring:
Storms | take 10Bruk
whereogprojectfiltrer bestemte data:Storms | where EventType == 'Drought' and State == 'TEXAS' | project StartTime, EndTime, Source, EventIdBruk operatoren
summarize:Storms | summarize event_count=count() by State | where event_count > 10 | project State, event_count | render columnchart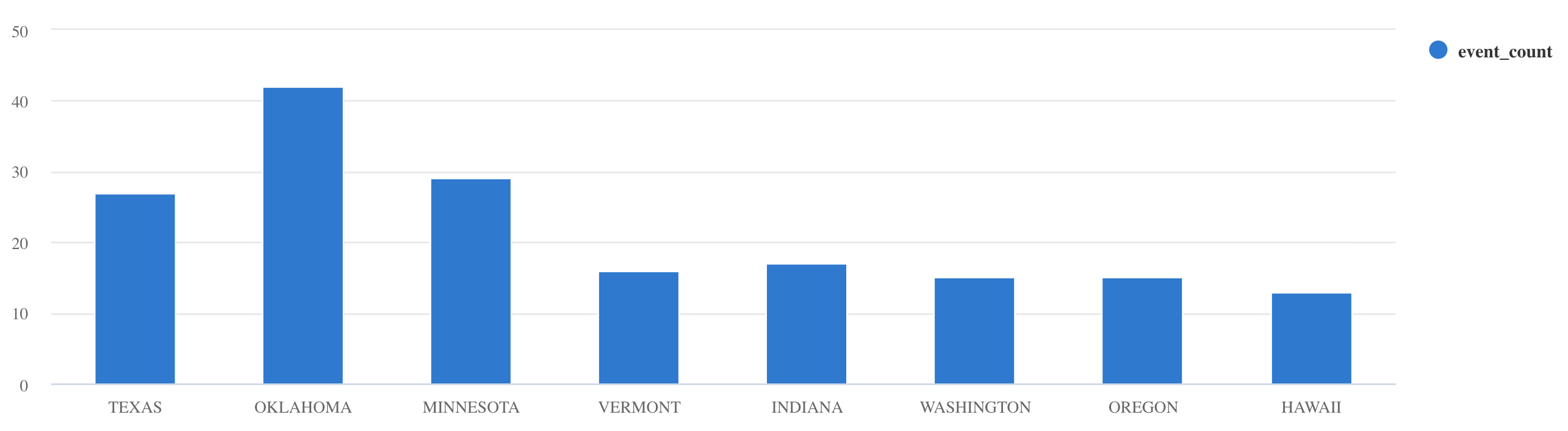
Hvis du vil ha flere spørringseksempler og veiledning, kan du se Skrive spørringer i dokumentasjonen for KQL og Kusto-spørringsspråk.
Reset
Gjør følgende for å tilbakestille:
- Stopp beholderne (
docker-compose down -v) - Slett (
drop table Storms) - Opprett tabellen på nytt
Storms - Opprett tabelltilordning på nytt
- Start beholdere på nytt (
docker-compose up)
Fjerning av ressurser
Rydd opp i elementene som ble opprettet ved å navigere til arbeidsområdet der de ble opprettet.
Hold pekeren over databasen i arbeidsområdet, og velg Mer-menyen [...] > Slett.
Velg Slett. Du kan ikke gjenopprette slettede elementer.
Justere Kafka Sink-koblingen
Still inn Kafka Sink-koblingen for å arbeide med policyen for inninntaksgruppering:
- Juster størrelsesgrensen på Kafka-vasken
flush.size.bytesfra 1 MB, noe som øker med intervaller på 10 MB eller 100 MB. - Når du bruker Kafka Sink, aggregeres data to ganger. Dataene på koblingssiden aggregeres i henhold til innstillinger for tømming, og på tjenestesiden i henhold til gruppepolicyen. Hvis satsvis tid er for kort, slik at data ikke kan inntas av både kobling og tjeneste, må satsvis tid økes. Angi satsvis størrelse på 1 GB og øk eller reduser med 100 MB intervaller etter behov. Hvis for eksempel tømmingsstørrelsen er 1 MB og den satsvise policystørrelsen er 100 MB, aggregerer Kafka Sink-koblingen data til en 100 MB batch. Denne bunken blir deretter inntatt av tjenesten. Hvis den satsvise policytiden er 20 sekunder og Kafka Sink-koblingen tømmer 50 MB i løpet av en periode på 20 sekunder, vil tjenesten innta en 50 MB batch.
- Du kan skalere ved å legge til forekomster og Kafka-partisjoner. Øke
tasks.maxtil antall partisjoner. Opprett en partisjon hvis du har nok data til å produsere en blob påflush.size.bytesstørrelse med innstillingen. Hvis bloben er mindre, behandles bunken når den når tidsgrensen, slik at partisjonen ikke får nok gjennomstrømming. Et stort antall partisjoner betyr mer behandling av indirekte kostnader.