Hent data fra Eventstream
I denne artikkelen lærer du hvordan du henter data fra en eksisterende hendelsesstrøm inn i en ny eller eksisterende tabell.
Hvis du vil hente data fra en ny hendelsesstrøm, kan du se Hent data fra en ny hendelsesstrøm.
Forutsetninger
- Et arbeidsområde med en Microsoft Fabric-aktivert kapasitet
- En KQL-database med redigeringstillatelser
- En eventstream- med en datakilde
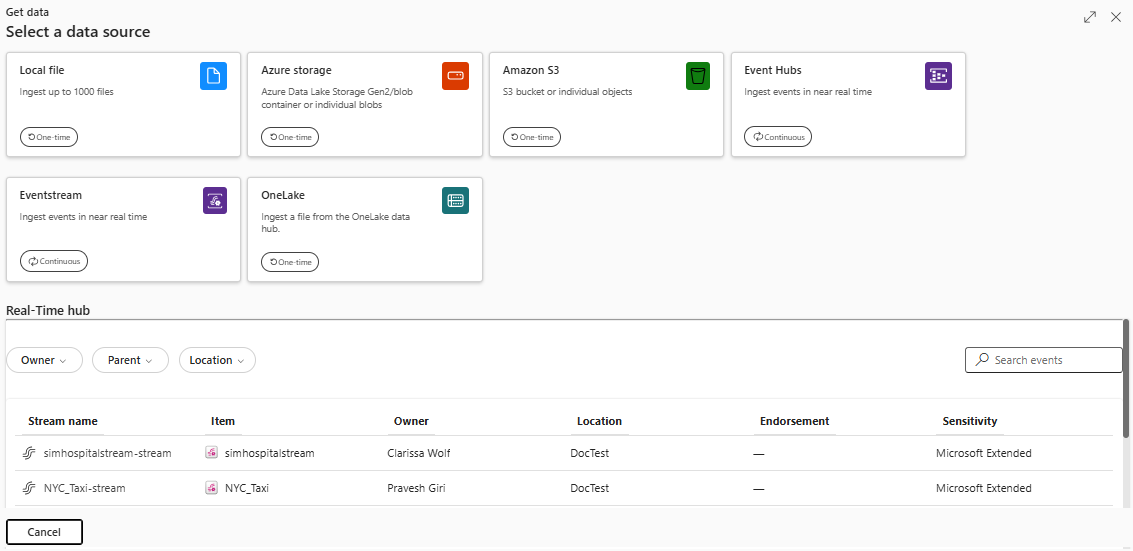
Kilde
Hvis du vil hente data fra en hendelsesstrøm, må du velge hendelsesstrømmen som datakilde. Du kan velge en eksisterende hendelsesstrøm på følgende måter:
Enten på det nedre båndet i KQL-databasen:
Gå til rullegardinmenyen Hent data, og velg deretter Eventstream>Existing Eventstreamunder Continuous.
Velg Hent data, og velg deretter Eventstreami vinduet Hent data .
Velg Real-Time datahub>Eksisterende hendelsesstrømunder Kontinuerligi rullegardinmenyen Hent data.

Konfigurere
Velg en måltabell. Hvis du vil innta data i en ny tabell, velger du + Ny tabell og skriver inn et tabellnavn.
Notat
Tabellnavn kan være opptil 1024 tegn, inkludert mellomrom, alfanumeriske tegn, bindestreker og understrekingstegn. Spesialtegn støttes ikke.
Under Konfigurere datakildenfyller du ut innstillingene ved hjelp av informasjonen i tabellen nedenfor:
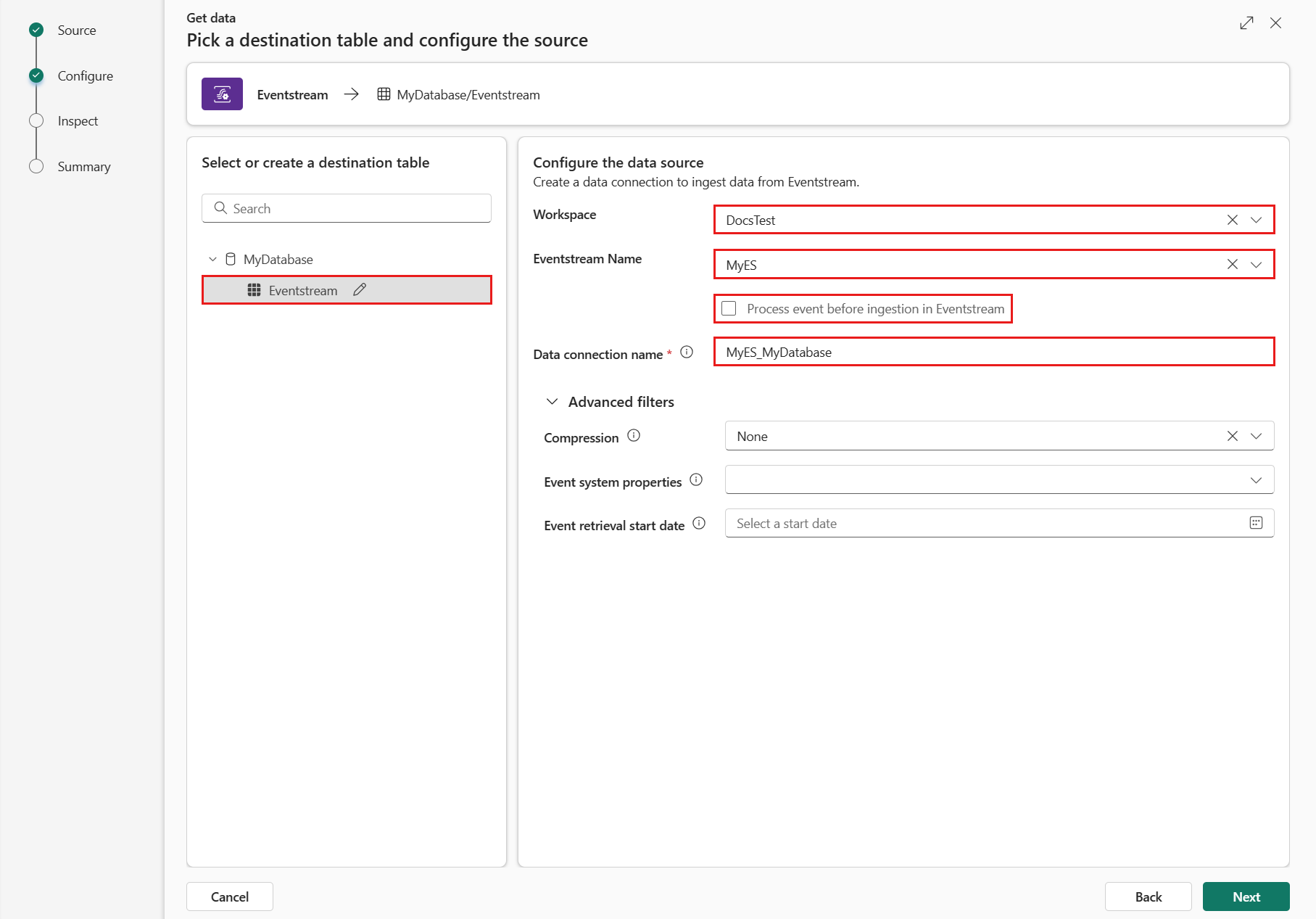
innstilling beskrivelse Arbeidsområde Plasseringen for eventstream-arbeidsområdet. Velg et arbeidsområde fra rullegardinlisten. Eventstream-navn Navnet på eventstreamen. Velg en hendelsesstrøm fra rullegardinlisten. Datatilkoblingsnavn Navnet som brukes til å referere til og administrere datatilkoblingen i arbeidsområdet. Navnet på datatilkoblingen fylles automatisk ut. Du kan også skrive inn et nytt navn. Navnet kan bare inneholde alfanumeriske tegn, tankestreker og prikktegn, og være opptil 40 tegn. Prosesshendelse før inntak i Eventstream Med dette alternativet kan du konfigurere databehandling før data inntas i måltabellen. Hvis valgt, fortsetter du datainntaksprosessen i Eventstream. Hvis du vil ha mer informasjon, kan du se Prosesshendelse før inntak i Eventstream. Avanserte filtre Kompresjon Datakomprimering av hendelsene, som kommer fra hendelseshuben. Alternativene er Ingen (standard) eller Gzip-komprimering. Egenskaper for hendelsessystem Hvis det finnes flere poster per hendelsesmelding, legges systemegenskapene til i den første. Hvis du vil ha mer informasjon, kan du se Systemegenskaper for hendelse. Startdato for hendelseshenting Datatilkoblingen henter eksisterende hendelser som er opprettet siden startdatoen for hendelseshenting. Den kan bare hente hendelser som beholdes av hendelseshuben, basert på oppbevaringsperioden. Tidssonen er UTC. Hvis ingen tid er angitt, er standardtidspunktet tidspunktet da datatilkoblingen ble opprettet. Velg Neste

Prosesshendelse før inntak i Eventstream
Alternativet Prosess før inntak i Eventstream gjør det mulig å behandle dataene før de tas inn i måltabellen. Med dette alternativet fortsetter hent dataprosessen sømløst i Eventstream, der måltabellen og datakildedetaljene fylles ut automatisk.
Slik behandler du hendelse før inntak i Eventstream:
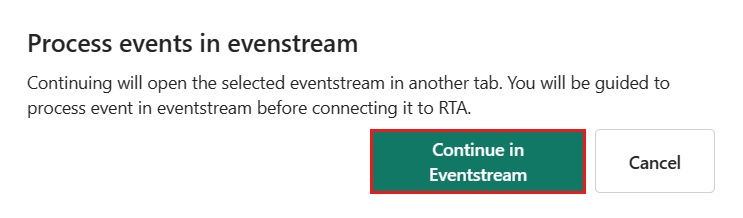
Velg Prosesshendelse før inntak i Eventstreampå fanen Konfigurer .
Velg Fortsett i Eventstreami dialogboksen Prosesshendelser i Eventstream .
Viktig
Hvis du velger Fortsett i Eventstream avsluttes hent dataprosessen i Real-Time Intelligence, og fortsetter i Eventstream med måltabellen og datakildedetaljene automatisk utfylt.
I Eventstream velger du KQL-database målnode, og i ruten KQL-database kontrollerer du at hendelsesbehandling før inntak er valgt, og at måldetaljene er riktige.
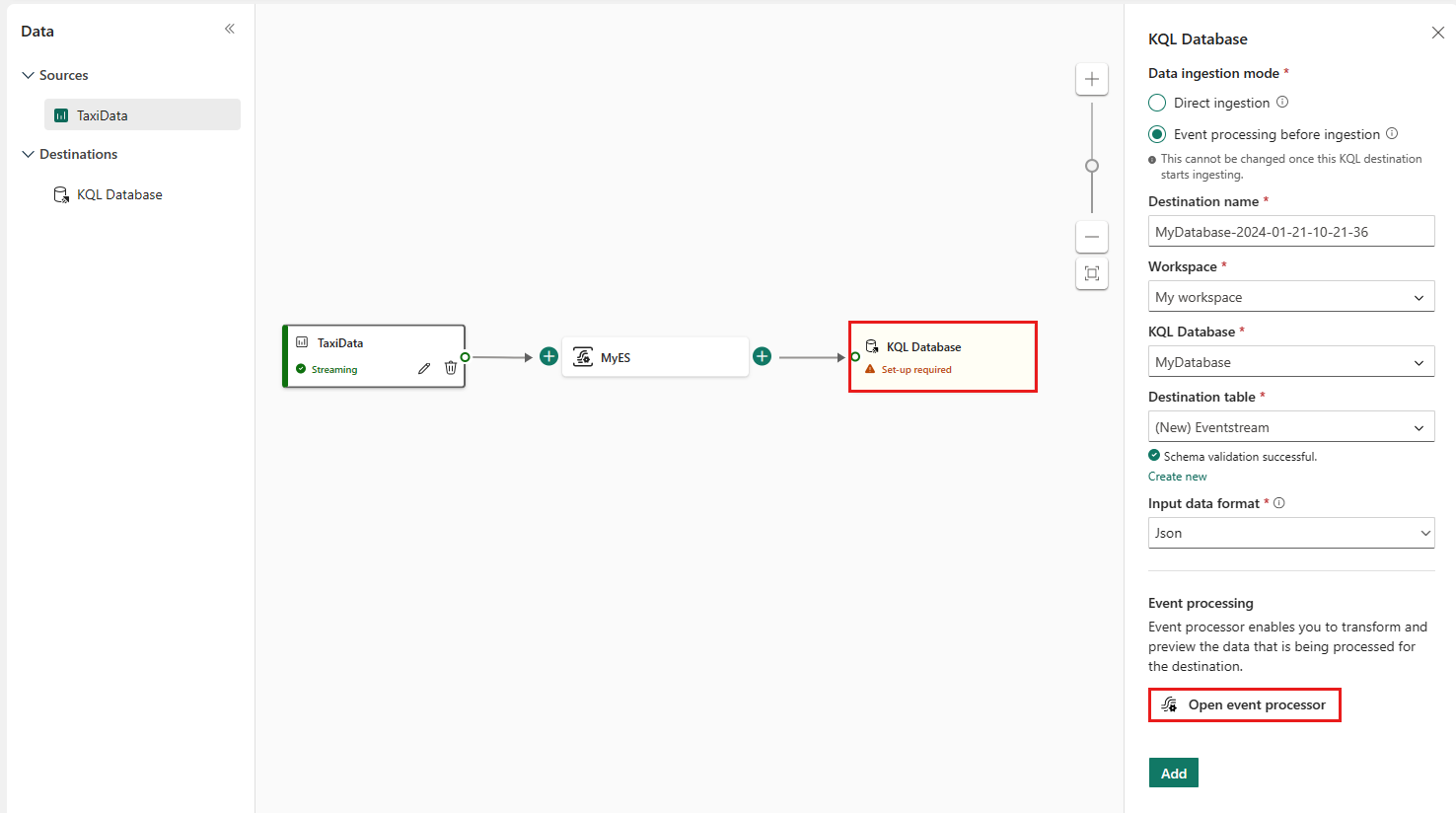
Velg Åpne hendelsesprosessor for å konfigurere databehandlingen, og velg deretter Lagre. Hvis du vil ha mer informasjon, kan du se Behandle hendelsesdata med redigeringsprogrammet for hendelsesprosessor.
Velg Legg til for å fullføre KQL-database målnodeoppsettet, tilbake i KQL-database-ruten.
Kontroller at dataene er inntatt i måltabellen.


Notat
Prosesshendelsen før inntak i Eventstream-prosessen er fullført, og de gjenværende trinnene i denne artikkelen er ikke nødvendige.
Inspisere
Fanen Undersøk åpnes med en forhåndsvisning av dataene.
Hvis du vil fullføre inntaksprosessen, velger du Fullfør.

Eventuelt:
- Velg kommandovisningsprogram for å vise og kopiere de automatiske kommandoene som genereres fra inndataene.
- Endre det automatisk utsatte dataformatet ved å velge ønsket format fra rullegardinlisten. Data leses fra hendelseshuben i form av EventData- objekter. Støttede formater er CSV, JSON, PSV, SCsv, SOHsv TSV, TXT og TSVE.
- Rediger kolonner.
- Utforsk Avanserte alternativer basert på datatype.
Rediger kolonner
Notat
- For tabellformater (CSV, TSV, PSV) kan du ikke tilordne en kolonne to ganger. Hvis du vil tilordne til en eksisterende kolonne, må du først slette den nye kolonnen.
- Du kan ikke endre en eksisterende kolonnetype. Hvis du prøver å tilordne til en kolonne med et annet format, kan du ende opp med tomme kolonner.
Endringene du kan gjøre i en tabell, avhenger av følgende parametere:
- tabelltype er ny eller eksisterende
- Tilordning type er ny eller eksisterende
| Tabelltype | Tilordningstype | Tilgjengelige justeringer |
|---|---|---|
| Ny tabell | Ny tilordning | Gi nytt navn til kolonne, endre datatype, endre datakilde, tilordningstransformasjon, legge til kolonne, slette kolonne |
| Eksisterende tabell | Ny tilordning | Legg til kolonne (der du deretter kan endre datatype, gi nytt navn til og oppdatere) |
| Eksisterende tabell | Eksisterende tilordning | ingen |

Tilordningstransformasjoner
Noen dataformattilordninger (Parquet, JSON og Avro) støtter enkle inntakstidstransformasjoner. Hvis du vil bruke tilordningstransformasjoner, oppretter eller oppdaterer du en kolonne i vinduet Rediger kolonner.
Tilordningstransformasjoner kan utføres på en kolonne av typen streng eller datetime, der kilden har datatypeint eller lang. Støttede tilordningstransformasjoner er:
- DateTimeFromUnixSeconds
- DateTimeFromUnixMilliseconds
- DateTimeFromUnixMicroseconds
- DateTimeFromUnixNanoseconds
Avanserte alternativer basert på datatype
tabell (CSV, TSV, PSV):
Tabelldata inneholder ikke nødvendigvis kolonnenavnene som brukes til å tilordne kildedata til de eksisterende kolonnene. Hvis du vil bruke den første raden som kolonnenavn, aktiverer du Første rad er kolonneoverskrift.

JSON:
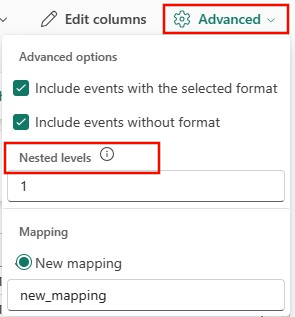
Hvis du vil bestemme kolonnedeling av JSON-data, velger du Avansert>Nestede nivåer, fra 1 til 100.
Sammendrag
I vinduet dataforberedelse merkes alle tre trinnene med grønne hakemerker når datainntaket fullføres. Du kan velge et kort som skal spørres, slippe de inntatte dataene eller se et instrumentbord i inntakssammendraget. Velg Lukk for å lukke vinduet.

Relatert innhold
- Hvis du vil administrere databasen, kan du se Behandle data
- Hvis du vil opprette, lagre og eksportere spørringer, kan du se Spørringsdata i et KQL-spørringssett