Hent data fra Azure Storage
I denne artikkelen lærer du hvordan du henter data fra Azure Storage (ADLS Gen2-beholder, blobbeholder eller individuelle blober) til enten en ny eller eksisterende tabell.
Forutsetninger
- Et arbeidsområde med en Microsoft Fabric-aktivert kapasitet
- En KQL-database med redigeringstillatelser
- En lagringskonto
Kilde
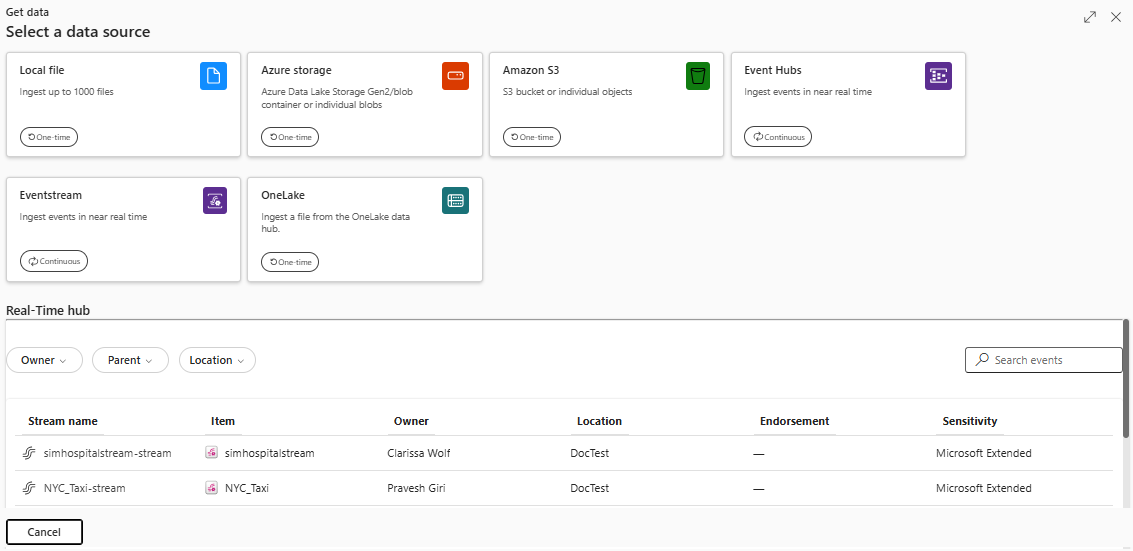
Velg Hent datapå det nedre båndet i KQL-databasen.
I vinduet Hent data er fanen Kilde valgt.
Velg datakilden fra den tilgjengelige listen. I dette eksemplet inntar du data fra Azure Storage.

Konfigurere
Velg en måltabell. Hvis du vil innta data i en ny tabell, velger du + Ny tabell og skriver inn et tabellnavn.
Notat
Tabellnavn kan være opptil 1024 tegn, inkludert mellomrom, alfanumeriske tegn, bindestreker og understrekingstegn. Spesialtegn støttes ikke.
Hvis du vil legge til datakilden, limer du inn lagringstilkoblingsstrengen i URI--feltet, og deretter velger du +. Tabellen nedenfor viser de støttede godkjenningsmetodene og tillatelsene som kreves for inntak av data fra Azure Storage.
Godkjenningsmetode Individuell blob Blob-beholder Azure Data Lake Storage Gen2 sas-tokenet (Shared Access) Lese og skrive Lese og liste Lese og liste tilgangsnøkkel for lagringskonto Notat
- Du kan enten legge til opptil 10 individuelle blober eller innta opptil 5000 blober fra én enkelt beholder. Du kan ikke innta begge samtidig.
- Hver blob kan være maksimalt 1 GB ukomprimert.
Hvis du limte inn en tilkoblingsstreng for en BLOB-beholder eller en Azure Data Lake Storage Gen2, kan du deretter legge til følgende valgfrie filtre:

innstilling Feltbeskrivelse Filfiltre (valgfritt) Mappebane Filtrerer data til å innta filer med en bestemt mappebane. Filtype Filtrerer data til å innta filer bare med en bestemt filtype.
Velg Neste

Inspisere
Fanen Undersøk åpnes med en forhåndsvisning av dataene.
Hvis du vil fullføre inntaksprosessen, velger du Fullfør.

Eventuelt:
- Velg kommandovisningsprogram for å vise og kopiere de automatiske kommandoene som genereres fra inndataene.
- Bruk skjemadefinisjonsfilen rullegardinlisten for å endre filen som skjemaet er utledet fra.
- Endre det automatisk utsatte dataformatet ved å velge ønsket format fra rullegardinlisten. Hvis du vil ha mer informasjon, kan du se Dataformater som støttes av Real-Time Intelligence.
- Rediger kolonner.
- Utforsk Avanserte alternativer basert på datatype.
Rediger kolonner
Notat
- For tabellformater (CSV, TSV, PSV) kan du ikke tilordne en kolonne to ganger. Hvis du vil tilordne til en eksisterende kolonne, må du først slette den nye kolonnen.
- Du kan ikke endre en eksisterende kolonnetype. Hvis du prøver å tilordne til en kolonne med et annet format, kan du ende opp med tomme kolonner.
Endringene du kan gjøre i en tabell, avhenger av følgende parametere:
- tabelltype er ny eller eksisterende
- Tilordning type er ny eller eksisterende
| Tabelltype | Tilordningstype | Tilgjengelige justeringer |
|---|---|---|
| Ny tabell | Ny tilordning | Gi nytt navn til kolonne, endre datatype, endre datakilde, tilordningstransformasjon, legge til kolonne, slette kolonne |
| Eksisterende tabell | Ny tilordning | Legg til kolonne (der du deretter kan endre datatype, gi nytt navn til og oppdatere) |
| Eksisterende tabell | Eksisterende tilordning | ingen |

Tilordningstransformasjoner
Noen dataformattilordninger (Parquet, JSON og Avro) støtter enkle inntakstidstransformasjoner. Hvis du vil bruke tilordningstransformasjoner, oppretter eller oppdaterer du en kolonne i vinduet Rediger kolonner.
Tilordningstransformasjoner kan utføres på en kolonne av typen streng eller datetime, der kilden har datatypeint eller lang. Støttede tilordningstransformasjoner er:
- DateTimeFromUnixSeconds
- DateTimeFromUnixMilliseconds
- DateTimeFromUnixMicroseconds
- DateTimeFromUnixNanoseconds
Avanserte alternativer basert på datatype
tabell (CSV, TSV, PSV):
Hvis du inntar tabellformater i en eksisterende tabell, kan du velge Avansert>Behold tabellskjema. Tabelldata inneholder ikke nødvendigvis kolonnenavnene som brukes til å tilordne kildedata til de eksisterende kolonnene. Når dette alternativet er merket av, utføres tilordningen etter rekkefølge, og tabellskjemaet forblir det samme. Hvis dette alternativet ikke er avmerket, opprettes nye kolonner for innkommende data, uavhengig av datastruktur.
Hvis du vil bruke den første raden som kolonnenavn, velger du Avansert>Første rad er kolonneoverskrift.

JSON:
Hvis du vil bestemme kolonnedeling av JSON-data, velger du Avansert>Nestede nivåer, fra 1 til 100.
Hvis du velger Avansert>Hopp over JSON-linjer med feil, blir dataene inntatt i JSON-format. Hvis du lar denne avmerkingsboksen være umerket, blir dataene inntatt i flerjsonformat.

Sammendrag
I vinduet dataforberedelse merkes alle tre trinnene med grønne hakemerker når datainntaket fullføres. Du kan velge et kort som skal spørres, slippe de inntatte dataene eller se et instrumentbord i inntakssammendraget.

Relatert innhold
- Hvis du vil administrere databasen, kan du se Behandle data
- Hvis du vil opprette, lagre og eksportere spørringer, kan du se Spørringsdata i et KQL-spørringssett