Implementere arkitektur for medaljong lakehouse i Microsoft Fabric
Denne artikkelen introduserer arkitektur for medaljongsjøen og beskriver hvordan du kan implementere et lakehouse i Microsoft Fabric. Den er rettet mot flere målgrupper:
- Dataingeniører: Teknisk personale som utformer, bygger og vedlikeholder infrastrukturer og systemer som gjør det mulig for organisasjonen å samle inn, lagre, behandle og analysere store mengder data.
- Center of Excellence-, IT- og BI-teamet: Teamene som er ansvarlige for å overvåke analyser i hele organisasjonen.
- Fabric-administratorer: Administratorene som er ansvarlige for å overvåke Fabric i organisasjonen.
Medaljong lakehouse arkitektur, kjent som medaljong arkitektur, er et designmønster som brukes av organisasjoner til logisk å organisere data i et innsjøhus. Det er den anbefalte designtilnærmingen for Fabric.
Medaljongarkitektur består av tre forskjellige lag – eller soner. Hvert lag indikerer kvaliteten på dataene som er lagret i lakehouse, med høyere nivåer som representerer høyere kvalitet. Denne flerlags tilnærmingen hjelper deg med å bygge en enkelt kilde til sannhet for bedriftsdataprodukter.
Viktigere, medaljong arkitektur garanterer Atomicity, Konsekvens, Isolasjon, og Holdbarhet (ACID) sett med egenskaper som data utvikler seg gjennom lagene. Fra og med rådata klargjør en rekke valideringer og transformasjoner data som er optimalisert for effektiv analyse. Det er tre medaljong stadier: bronse (rå), sølv (validert) og gull (beriket).
Hvis du vil ha mer informasjon, kan du se Hva er medaljongen lakehouse arkitektur?.
OneLake og lakehouse i Fabric
Grunnlaget for et moderne datalager er en datainnsjø. Microsoft OneLake, som er en enkel, enhetlig, logisk datainnsjø for hele organisasjonen. Den leveres automatisk med hver Fabric-leier, og den er utformet for å være den eneste plasseringen for alle analysedataene dine.
Du kan bruke OneLake til å:
- Fjern siloer og reduser administrasjonsarbeidet. Alle organisasjonsdata lagres, administreres og sikres i én datainnsjøressurs. Fordi OneLake er klargjort med Fabric-leieren, er det ikke flere ressurser å klargjøre eller administrere.
- Reduser dataflytting og duplisering. Målet med OneLake er å lagre bare én kopi av data. Færre kopier av data resulterer i færre databevegelsesprosesser, og det fører til effektivitetsgevinster og reduksjon i kompleksiteten. Hvis det er nødvendig, kan du opprette en snarvei for å referere til data som er lagret andre steder, i stedet for å kopiere den til OneLake.
- Bruk med flere analytiske motorer. Dataene i OneLake lagres i et åpent format. På denne måten kan dataene spørres av ulike analytiske motorer, inkludert Analysis Services (brukes av Power BI), T-SQL og Apache Spark. Andre programmer som ikke er stoff, kan også bruke API-er og SDK-er for å få tilgang til OneLake .
Hvis du vil ha mer informasjon, kan du se OneLake, OneDrive for data.
Hvis du vil lagre data i OneLake, oppretter du et lakehouse i Fabric. Et lakehouse er en dataarkitekturplattform for lagring, administrasjon og analyse av strukturerte og ustrukturerte data på ett sted. Det kan enkelt skaleres til store datavolumer av alle filtyper og størrelser, og fordi det er lagret på én enkelt plassering, er det enkelt å dele og brukes på nytt på tvers av organisasjonen.
Hvert lakehouse har et innebygd SQL Analytics-endepunkt som låser opp datalagerfunksjoner uten å måtte flytte data. Det betyr at du kan spørre dataene i lakehouse ved hjelp av SQL-spørringer og uten noen spesiell konfigurasjon.
Hvis du vil ha mer informasjon, kan du se Hva er et lakehouse i Microsoft Fabric?.
Tabeller og filer
Når du oppretter et lakehouse i Fabric, klargjøres to fysiske lagringssteder automatisk for tabeller og filer.
- Tabeller er et administrert område for å være vert for tabeller i alle formater i Apache Spark (CSV, Parquet eller Delta). Alle tabeller, enten de opprettes automatisk eller eksplisitt, gjenkjennes som tabeller i lakehouse. Alle Delta-tabeller, som er Parquet-datafiler med en filbasert transaksjonslogg, gjenkjennes også som tabeller.
- Filer er et uadministrert område for lagring av data i alle filformater. Delta-filer som er lagret i dette området, gjenkjennes ikke automatisk som tabeller. Hvis du vil opprette en tabell over en Delta Lake-mappe i det uadministrerte området, må du eksplisitt opprette en snarvei eller en ekstern tabell med en plassering som peker til den uadministrerte mappen som inneholder Delta Lake-filene i Apache Spark.
Hovedforskjellen mellom det administrerte området (tabeller) og det uadministrerte området (filer) er den automatiske tabelloppdagelses- og registreringsprosessen. Denne prosessen kjører bare over alle mapper som er opprettet i det administrerte området, men ikke i det uadministrerte området.
I Microsoft Fabric gir Lakehouse Explorer en enhetlig grafisk representasjon av hele Lakehouse for brukere å navigere, få tilgang til og oppdatere dataene sine.
Hvis du vil ha mer informasjon om automatisk tabelloppdagelse, kan du se Automatisk tabelloppdagelse og -registrering.
Delta Lake-lagring
Delta Lake er et optimalisert lagringslag som gir grunnlaget for lagring av data og tabeller. Den støtter ACID-transaksjoner for store dataarbeidsbelastninger, og derfor er det standard lagringsformat i et Fabric Lakehouse.
Det viktigste er at Delta Lake leverer pålitelighet, sikkerhet og ytelse i lakehouse for både strømming og batchoperasjoner. Internt lagrer den data i Parquet-filformat, men det opprettholder også transaksjonslogger og statistikk som gir funksjoner og ytelsesforbedringer i forhold til standard parkettformat.
Delta Lake-format over generiske filformater gir følgende hovedfordeler.
- Støtte for ACID-egenskaper, og spesielt holdbarhet for å forhindre datakorrupsjon.
- Raskere lesespørringer.
- Økt datafriskhet.
- Støtte for både gruppe- og strømming av arbeidsbelastninger.
- Støtte for tilbakerulling av data ved hjelp av Tidsreiser i Delta Lake.
- Forbedret forskriftssamsvar og revisjon ved hjelp av Tabellhistorikk for Delta Lake.
Fabric standardiserer lagringsfilformatet med Delta Lake, og som standard oppretter hver arbeidsbelastningsmotor i Fabric Delta-tabeller når du skriver data til en ny tabell. Hvis du vil ha mer informasjon, kan du se Lakehouse- og Delta Lake-bord.
Medaljongarkitektur i Stoff
Målet med medaljongarkitekturen er å trinnvis og gradvis forbedre strukturen og kvaliteten på dataene etter hvert som den utvikler seg gjennom hvert trinn.
Medaljongarkitektur består av tre forskjellige lag (eller soner).
- Bronse: Dette første laget er også kjent som råsonen, og lagrer kildedata i det opprinnelige formatet. Dataene i dette laget er vanligvis tilføybare og uforanderlige.
- Sølv: Også kjent som den berikede sonen lagrer dette laget data hentet fra bronselaget. Rådataene er renset og standardisert, og de er nå strukturert som tabeller (rader og kolonner). Det kan også være integrert med andre data for å gi en virksomhetsvisning av alle forretningsenheter, for eksempel kunde, produkt og andre.
- Gull: Også kjent som den kuraterte sonen lagrer dette siste laget data hentet fra sølvlaget. Dataene er presisert for å oppfylle spesifikke nedstrøms forretnings- og analysekrav. Tabeller samsvarer vanligvis med utforming av stjerneskjema, som støtter utvikling av datamodeller som er optimalisert for ytelse og brukervennlighet.
Viktig
Fordi et Fabric lakehouse representerer en enkelt sone, oppretter du ett innsjøhus for hver av de tre sonene.
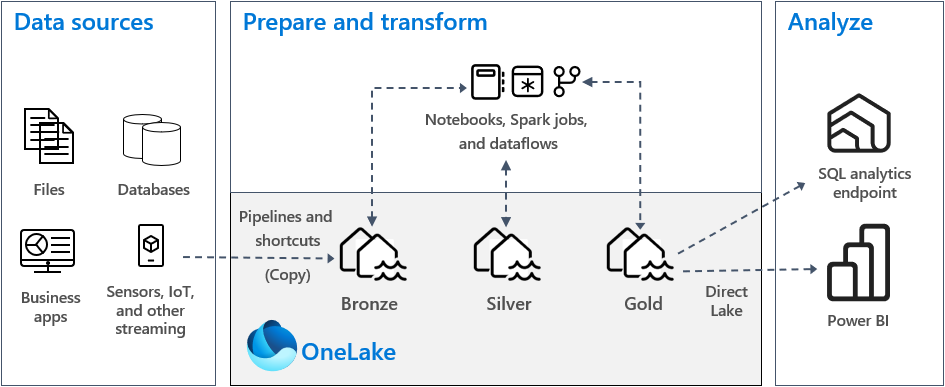
I en typisk implementering av medaljongarkitektur i Fabric lagrer bronsesonen dataene i samme format som datakilden. Når datakilden er en relasjonsdatabase, er Delta-tabeller et godt valg. Sølv- og gullsonene inneholder Delta-tabeller.
Tips
Hvis du vil lære hvordan du oppretter et lakehouse, kan du arbeide gjennom opplæringen i ende-til-ende-scenarioet i Lakehouse.
Veiledning for Fabric Lakehouse
Denne delen gir deg veiledning knyttet til implementering av Fabric Lakehouse ved hjelp av medaljongarkitektur.
Distribusjonsmodell
Hvis du vil implementere medaljongarkitektur i Fabric, kan du enten bruke lakehouses (én for hver sone), et datalager eller en kombinasjon av begge. Din beslutning bør være basert på dine preferanser og ekspertisen til teamet ditt. Husk at Fabric gir deg fleksibilitet: Du kan bruke forskjellige analytiske motorer som fungerer på den ene kopien av dataene dine i OneLake.
Her er to mønstre å vurdere.
- Mønster 1: Opprett hver sone som et innsjøhus. I dette tilfellet får forretningsbrukere tilgang til data ved hjelp av SQL Analytics-endepunktet.
- Mønster 2: Opprett bronse- og sølvsonene som innsjøer, og gullsonen som datalager. I dette tilfellet får forretningsbrukere tilgang til data ved hjelp av datalagerendepunktet.
Selv om du kan opprette alle lakehouses i et enkelt Fabric arbeidsområde, anbefaler vi at du oppretter hvert lakehouse i sitt eget, separate Fabric arbeidsområde. Denne tilnærmingen gir deg mer kontroll og bedre styring på sonenivå.
For bronsesonen anbefaler vi at du lagrer dataene i det opprinnelige formatet, eller bruker Parquet eller Delta Lake. Når det er mulig, beholder du dataene i det opprinnelige formatet. Hvis kildedataene er fra OneLake, oppretter Azure Data Lake Store Gen2 (ADLS Gen2), Amazon S3 eller Google en snarvei i bronsesonen i stedet for å kopiere dataene på tvers.
For sølv- og gullsonene anbefaler vi at du bruker Delta-tabeller på grunn av de ekstra funksjonene og ytelsesforbedringene de tilbyr. Stoff standardiseres på Delta Lake-format, og som standard skriver hver motor i Fabric data i dette formatet. Videre bruker disse motorene V-Order-skrivetidsoptimalisering til Parquet-filformatet. Denne optimaliseringen muliggjør ekstremt raske lesinger av stoffdatabehandlingsmotorer, for eksempel Power BI, SQL, Apache Spark og andre. Hvis du vil ha mer informasjon, kan du se Tabelloptimalisering for Delta Lake og V-order.
Til slutt står mange organisasjoner i dag overfor massiv vekst i datavolumer, sammen med et økende behov for å organisere og administrere disse dataene på en logisk måte, samtidig som de legger til rette for mer målrettet og effektiv bruk og styring. Dette kan føre til at du etablerer og administrerer en desentralisert eller forbundsbasert dataorganisasjon med styring.
For å nå dette målet bør du vurdere å implementere en datanettarkitektur. Datanett er et arkitektonisk mønster som fokuserer på å opprette datadomener som tilbyr data som et produkt.
Du kan opprette en datanettarkitektur for dataområdet i Fabric ved å opprette datadomener. Du kan opprette domener som tilordnes forretningsdomenene, for eksempel markedsføring, salg, beholdning, personaladministrasjon og andre. Deretter kan du implementere medaljongarkitektur ved å konfigurere datasoner innenfor hvert av domenene dine.
Hvis du vil ha mer informasjon om domener, kan du se Domener.
Forstå datalagring for Delta-tabell
Denne delen beskriver andre veiledningsemner knyttet til implementering av en medaljong lakehouse arkitektur i Fabric.
Filstørrelse
Vanligvis fungerer en stor dataplattform bedre når den har et lite antall store filer i stedet for et stort antall små filer. Det er fordi ytelsesreduksjon oppstår når databehandlingsmotoren må administrere mange metadata- og filoperasjoner. For bedre spørringsytelse anbefaler vi at du sikter mot datafiler som er omtrent 1 GB i størrelse.
Delta Lake har en funksjon som kalles prediktiv optimalisering. Prediktiv optimalisering fjerner behovet for manuelt å administrere vedlikeholdsoperasjoner for Delta-tabeller. Når denne funksjonen er aktivert, identifiserer Delta Lake automatisk tabeller som vil dra nytte av vedlikeholdsoperasjoner, og deretter optimaliserer lagringsplassen. Det kan gjennomsiktig samle mange mindre filer i store filer, og uten noen innvirkning på andre lesere og forfattere av dataene. Selv om denne funksjonen skal være en del av den operative fortreffeligheten og dataforberedelsesarbeidet, har Fabric muligheten til å optimalisere disse datafilene under dataskriving også. Hvis du vil ha mer informasjon, kan du se Prediktiv optimalisering for Delta Lake.
Historisk oppbevaring
Som standard opprettholder Delta Lake en historie over alle endringer som er gjort Det betyr at størrelsen på historiske metadata vokser over tid. Basert på dine forretningskrav bør du ha som mål å beholde historiske data bare i en viss tidsperiode for å redusere lagringskostnadene. Vurder å beholde historiske data for bare den siste måneden eller en annen passende tidsperiode.
Du kan fjerne eldre historiske data fra en Delta-tabell ved hjelp av VACUUM-kommandoen. Vær imidlertid oppmerksom på at du som standard ikke kan slette historiske data i løpet av de siste sju dagene – det vil si å opprettholde konsekvensen i dataene. Standard antall dager kontrolleres av tabellegenskapen delta.deletedFileRetentionDuration = "interval <interval>". Den bestemmer tidsperioden en fil må slettes før den kan betraktes som en kandidat for en vakuumoperasjon.
Tabell partisjoner
Når du lagrer data i hver sone, anbefaler vi at du bruker en partisjonert mappestruktur der det er aktuelt. Denne teknikken bidrar til å forbedre databehandling og spørringsytelse. Partisjonerte data i en mappestruktur resulterer vanligvis i raskere søk etter bestemte dataoppføringer takket være partisjonsbeskjæring/eliminering.
Vanligvis tilføyer du data til måltabellen etter hvert som nye data kommer. I noen tilfeller kan du imidlertid flette data fordi du må oppdatere eksisterende data samtidig. I så fall kan du utføre en upsert-operasjon ved hjelp av KOMMANDOEN SLÅ SAMMEN. Når måltabellen er partisjonert, må du bruke et partisjonsfilter for å øke hastigheten på operasjonen. På den måten kan motoren eliminere partisjoner som ikke krever oppdatering.
Datatilgang
Til slutt bør du planlegge og kontrollere hvem som trenger tilgang til bestemte data i lakehouse. Du bør også forstå de ulike transaksjonsmønstrene de kommer til å bruke mens du får tilgang til disse dataene. Deretter kan du definere riktig tabellpartisjoneringsskjema og datakollegasjon med Delta Lake Z-ordreindekser.
Relatert innhold
Hvis du vil ha mer informasjon om hvordan du implementerer et Fabric Lakehouse, kan du se følgende ressurser.
- Opplæring: Lakehouse ende-til-ende scenario
- Lakehouse og Delta Lake tabeller
- Beslutningsveiledning for Microsoft Fabric: Velg et datalager
- Tabelloptimalisering for Delta Lake og V-order
- Behovet for å optimalisere skriving på Apache Spark
- Spørsmål? Prøv å spørre Fabric-fellesskapet.
- Forslag? Bidra med ideer for å forbedre Fabric.