Utforske data i den speilvendte databasen med notatblokker
Du kan utforske dataene replikert fra den speilvendte databasen med Spark-spørringer i notatblokker.
Notatblokker er et kraftig kodeelement som du kan bruke til å utvikle Apache Spark-jobber og maskinlæringseksperimenter på dataene dine. Du kan bruke notatblokker i Fabric Lakehouse til å utforske speilvendte tabeller.
Forutsetning
- Fullfør opplæringen for å opprette en speilvendt database fra kildedatabasen.
- Opplæring: Konfigurere Microsoft Fabric-speilet database for Azure Cosmos DB (forhåndsversjon)
- Opplæring: Konfigurere Microsoft Fabric-speilbaserte databaser fra Azure Databricks (forhåndsversjon)
- Opplæring: Konfigurere microsoft Fabric-speilvendte databaser fra Azure SQL Database
- Opplæring: Konfigurere Speilvendte Microsoft Fabric-databaser fra Azure SQL administrert forekomst (forhåndsversjon)
- Opplæring: Konfigurere speilvendte databaser i Microsoft Fabric fra Snowflake
Opprette en snarvei
Du må først opprette en snarvei fra speilvendte tabeller til Lakehouse, og deretter bygge notatblokker med Spark-spørringer i Lakehouse.
Åpne Dataingeniør i Stoffportalen.
Hvis du ikke allerede har opprettet et Lakehouse, velger du Lakehouse og oppretter et nytt Lakehouse ved å gi det et navn.
Velg Hent data –> ny snarvei.
Velg Microsoft OneLake.
Du kan se alle speilvendte databaser i Fabric-arbeidsområdet.
Velg den speilvendte databasen du vil legge til i Lakehouse, som en snarvei.
Velg ønskede tabeller fra den speilvendte databasen.
Velg Neste, og deretter Opprett.
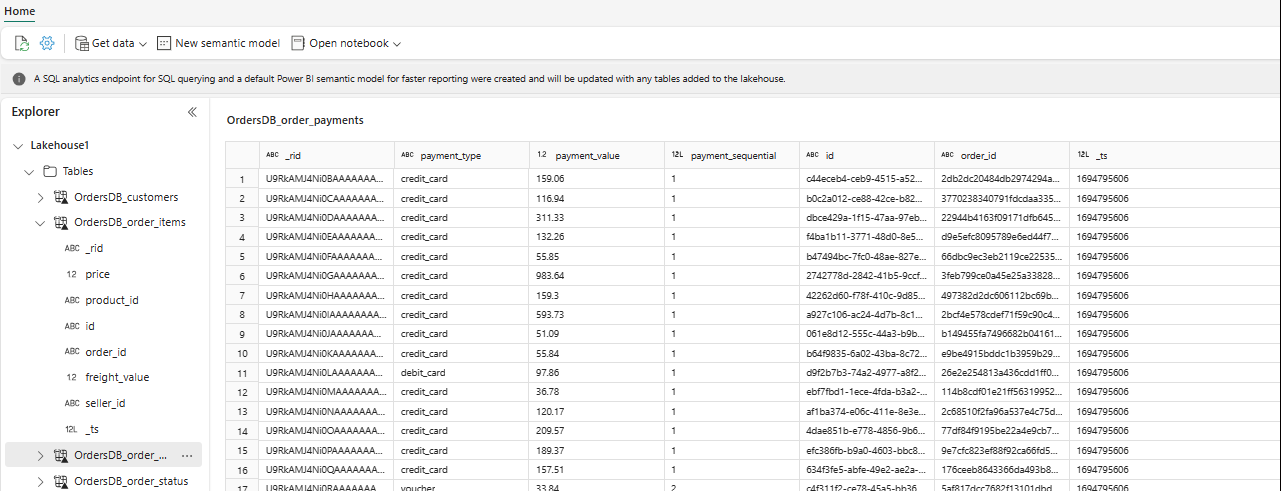
I Explorer kan du nå se valgte tabelldata i Lakehouse.
Tips
Du kan legge til andre data i Lakehouse direkte eller ta med snarveier som S3, ADLS Gen2. Du kan navigere til SQL Analytics-endepunktet i Lakehouse og bli med i dataene på tvers av alle disse kildene med speilvendte data sømløst.
Hvis du vil utforske disse dataene i Spark, velger du prikkene ved siden av
...en tabell. Velg Ny notatblokk eller eksisterende notatblokk for å starte analysen.
Notatblokken åpnes automatisk, og datarammen lastes inn med en
SELECT ... LIMIT 1000Spark SQL-spørring.- Nye notatblokker kan ta opptil to minutter å laste inn fullstendig. Du kan unngå denne forsinkelsen ved å bruke en eksisterende notatblokk med en aktiv økt.
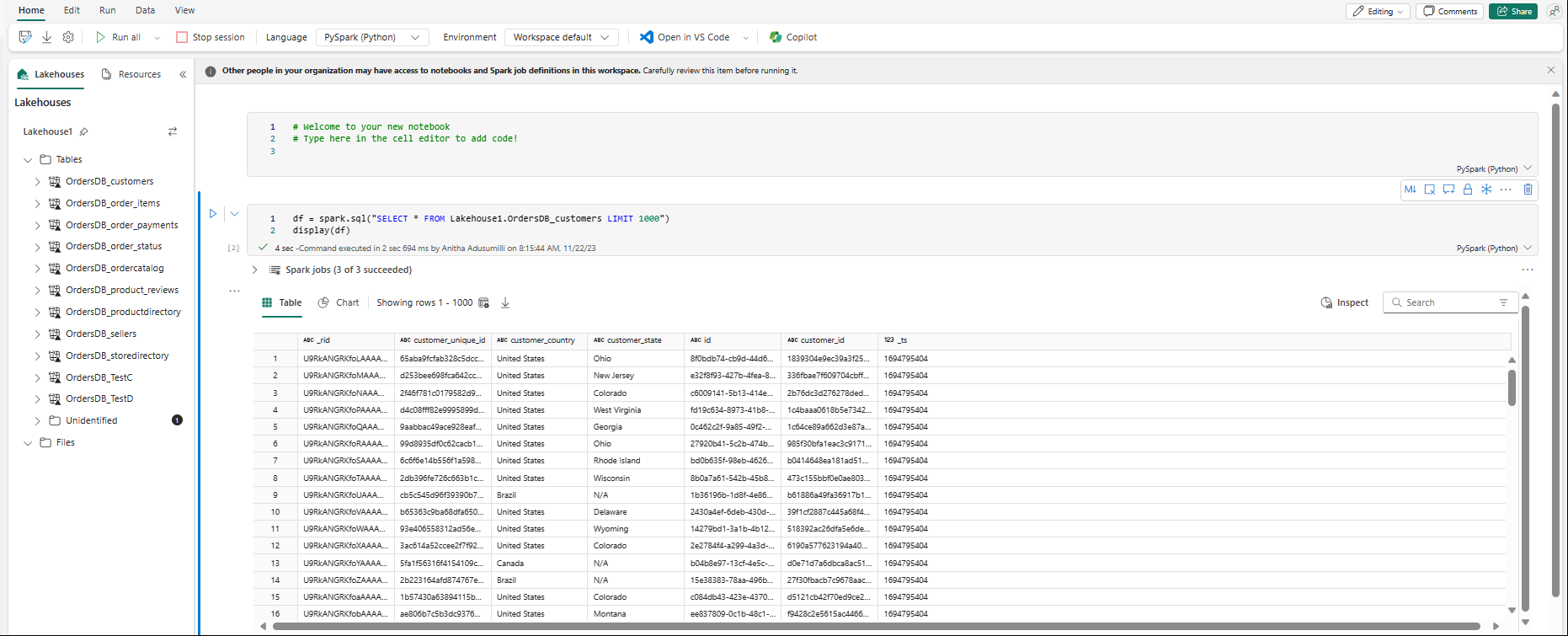
- Nye notatblokker kan ta opptil to minutter å laste inn fullstendig. Du kan unngå denne forsinkelsen ved å bruke en eksisterende notatblokk med en aktiv økt.


