Dataflyt gen2-datamål og administrerte innstillinger
Når du har renset og klargjort dataene med Dataflyt gen2, vil du lande dataene i et mål. Du kan gjøre dette ved hjelp av datamålfunksjonene i Dataflyt gen2. Med denne funksjonen kan du velge mellom forskjellige destinasjoner, for eksempel Azure SQL, Fabric Lakehouse og mange flere. Dataflyt gen2 skriver deretter dataene til målet, og derfra kan du bruke dataene til videre analyse og rapportering.
Listen nedenfor inneholder datamålene som støttes.
- Azure SQL-databaser
- Azure Data Explorer (Kusto)
- Fabric Lakehouse
- Fabric Warehouse
- KQL-database for stoff
- Fabric SQL-database
Inngangspunkter
Hver dataspørring i Dataflyt gen2 kan ha et datamål. Funksjoner og lister støttes ikke. Du kan bare bruke den på tabellspørringer. Du kan angi datamålet for hver spørring individuelt, og du kan bruke flere forskjellige mål i dataflyten.
Det finnes tre hovedinngangspunkter for å angi datamålet:
Gjennom det øverste båndet.
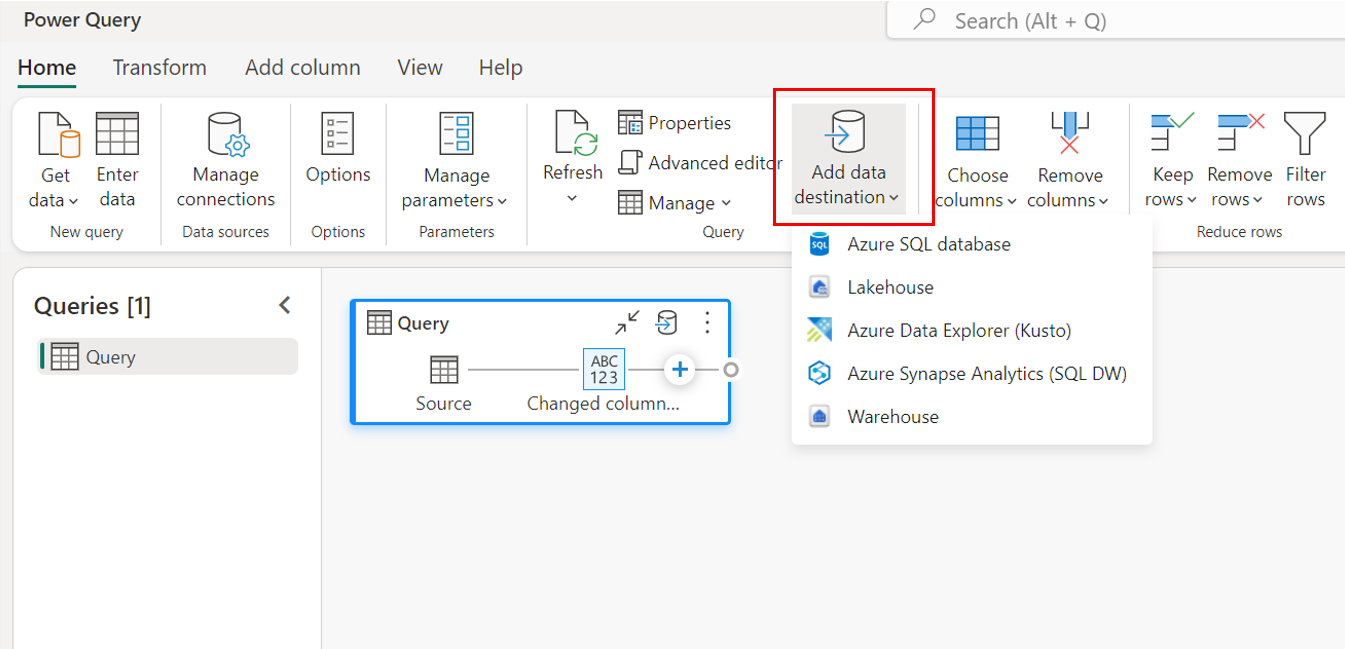
Gjennom spørringsinnstillinger.
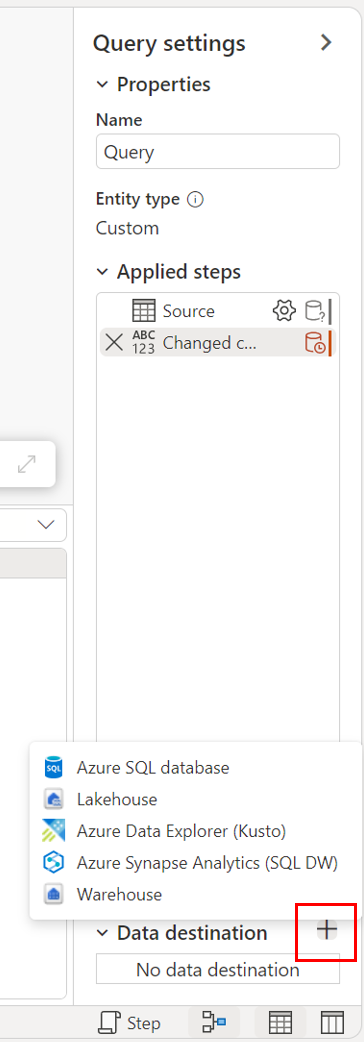
Gjennom diagramvisningen.

Koble til datamålet
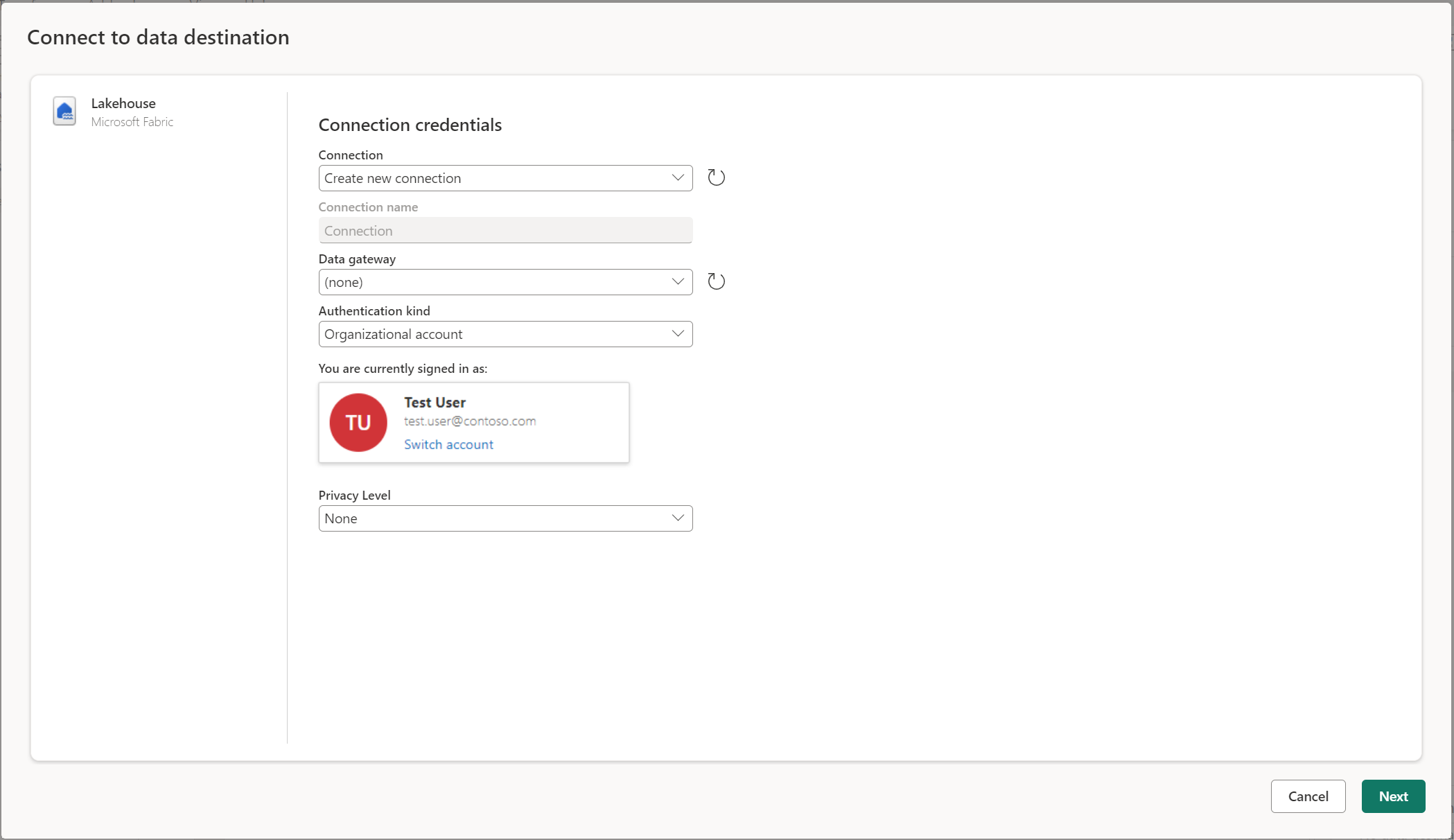
Tilkobling til datamålet ligner på tilkobling til en datakilde. Tilkoblinger kan brukes til både å lese og skrive dataene, gitt at du har de riktige tillatelsene på datakilden. Du må opprette en ny tilkobling eller velge en eksisterende tilkobling, og deretter velge Neste.
Opprette en ny tabell eller velge en eksisterende tabell
Når du laster inn i datamålet, kan du enten opprette en ny tabell eller velge en eksisterende tabell.
Opprett en ny tabell
Når du velger å opprette en ny tabell, opprettes en ny tabell i datamålet under Dataflyt gen2-oppdateringen. Hvis tabellen slettes i fremtiden ved å gå manuelt inn i målet, gjenoppretter dataflyten tabellen under den neste dataflytoppdateringen.
Tabellnavnet har som standard samme navn som spørringsnavnet. Hvis du har ugyldige tegn i tabellnavnet som målet ikke støtter, justeres tabellnavnet automatisk. Mange mål støtter for eksempel ikke mellomrom eller spesialtegn.
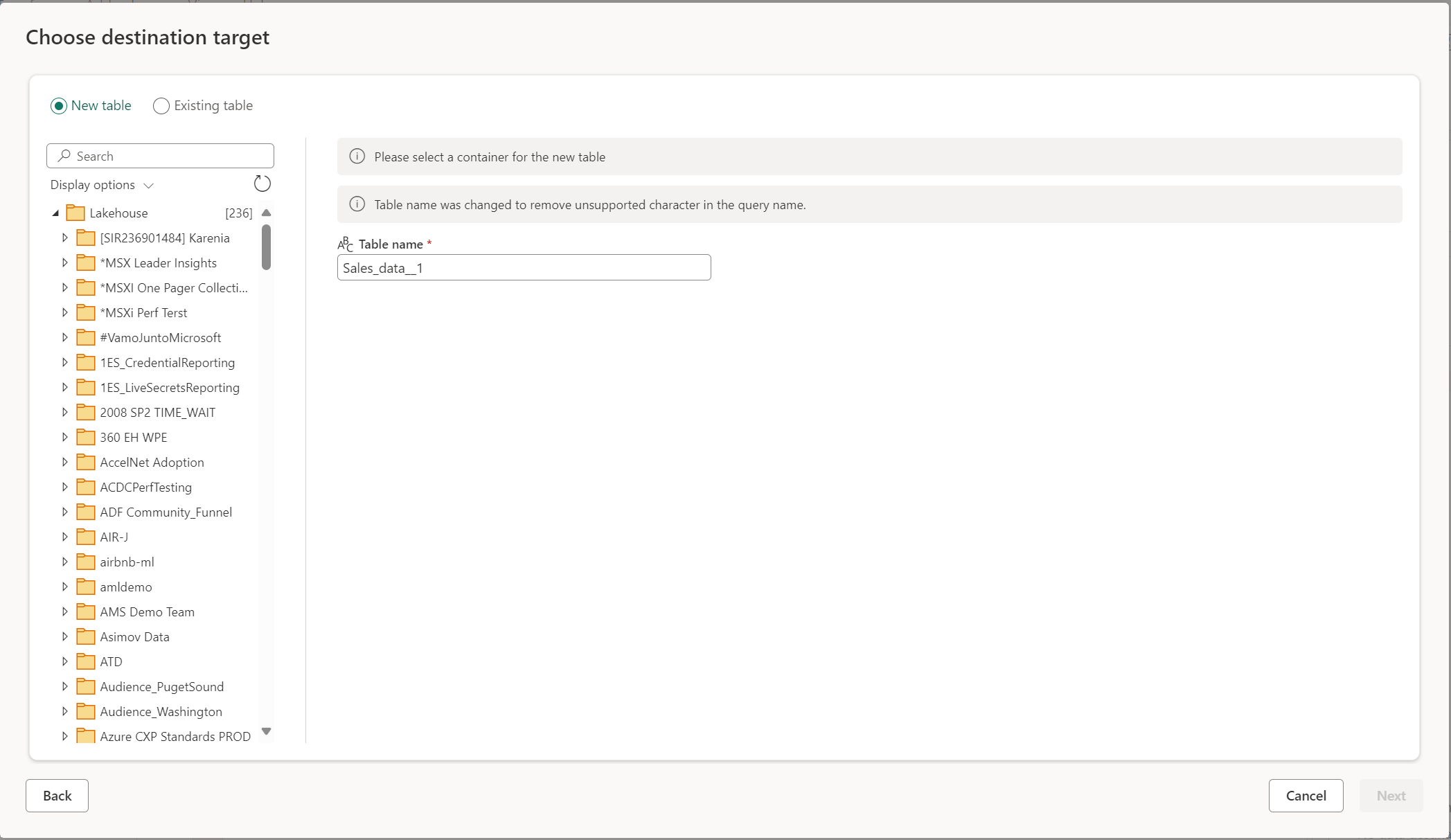
Deretter må du velge målbeholderen. Hvis du velger noen av stoffdatamålene, kan du bruke navigatøren til å velge fabric-artefakten du vil laste inn dataene i. For Azure-mål kan du enten angi databasen under oppretting av tilkobling, eller velge databasen fra navigatoropplevelsen.
Bruke en eksisterende tabell
Hvis du vil velge en eksisterende tabell, bruker du veksleknappen øverst på navigatøren. Når du velger en eksisterende tabell, må du velge både Fabric-artefakten/databasen og tabellen ved hjelp av navigatøren.
Når du bruker en eksisterende tabell, kan ikke tabellen opprettes på nytt i et scenario. Hvis du sletter tabellen manuelt fra datamålet, gjenoppretter ikke Dataflyt Gen2 tabellen på nytt ved neste oppdatering.
Administrerte innstillinger for nye tabeller
Når du laster inn i en ny tabell, er de automatiske innstillingene aktivert som standard. Hvis du bruker de automatiske innstillingene, administrerer Dataflyt Gen2 tilordningen for deg. De automatiske innstillingene gir følgende virkemåte:
Erstatning av oppdateringsmetode: Data erstattes ved hver dataflytoppdatering. Alle data i målet fjernes. Dataene i målet erstattes med utdata for dataflyten.
Administrert tilordning: Tilordning administreres for deg. Når du må gjøre endringer i dataene/spørringen for å legge til en annen kolonne eller endre en datatype, justeres tilordningen automatisk for denne endringen når du publiserer dataflyten på nytt. Du trenger ikke å gå inn i datamålopplevelsen hver gang du gjør endringer i dataflyten, noe som gir enkel skjemaendringer når du publiserer dataflyten på nytt.
Slipp og gjenopprett tabell: Hvis du vil tillate disse skjemaendringene, slettes og gjenopprettes tabellen ved hver dataflytoppdatering. Oppdatering av dataflyten kan føre til fjerning av relasjoner eller mål som ble lagt til tidligere i tabellen.
Merk
Automatisk innstilling støttes for øyeblikket bare for Lakehouse og Azure SQL-database som datamål.
Manuelle innstillinger
Ved å løsne Bruk automatiske innstillinger får du full kontroll over hvordan du laster inn dataene i datamålet. Du kan gjøre eventuelle endringer i kolonnetilordningen ved å endre kildetypen eller utelate en kolonne som du ikke trenger i datamålet.
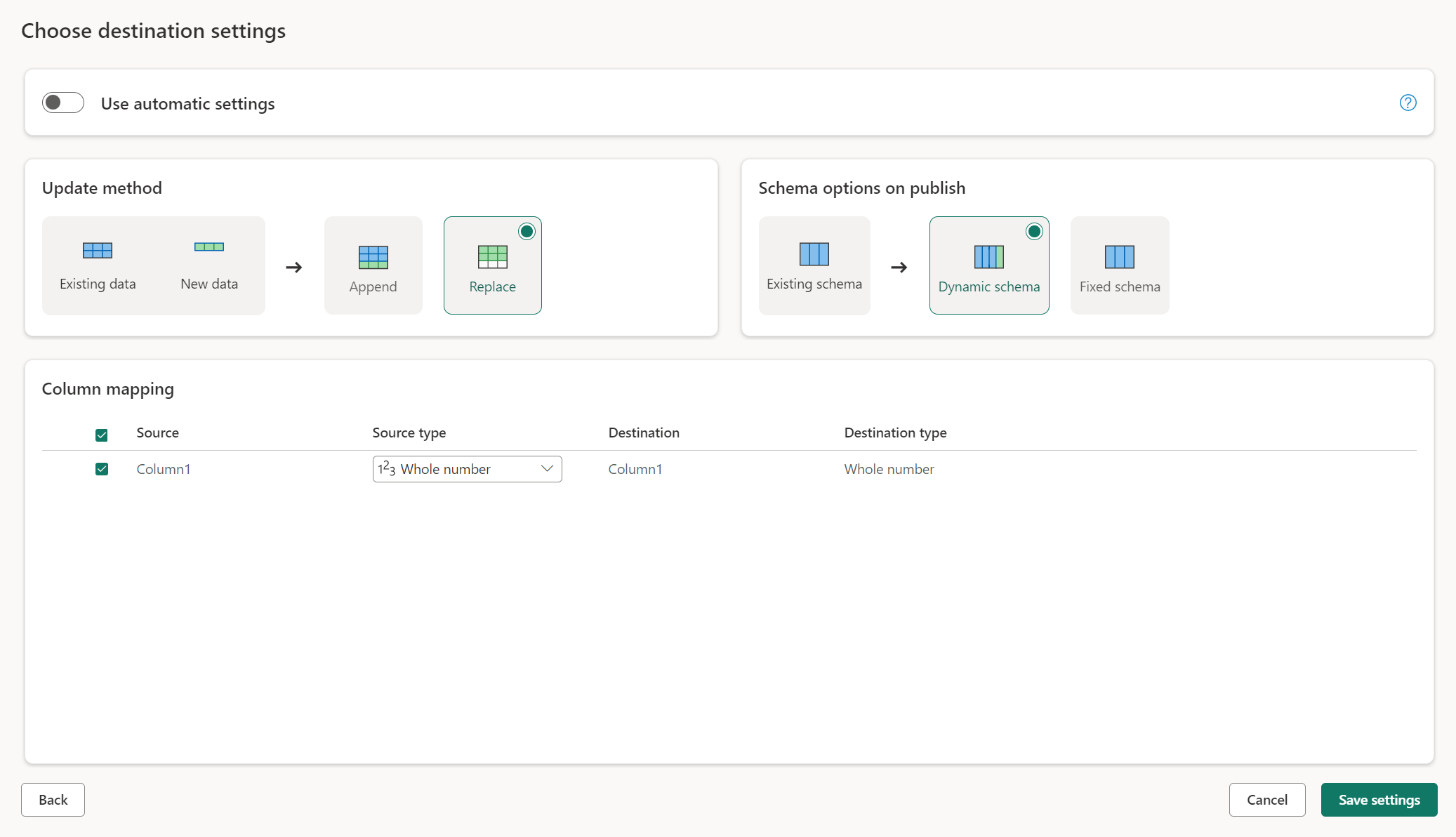
Oppdater metoder
De fleste destinasjoner støtter både tilføying og erstatning som oppdateringsmetoder. Fabric KQL-databaser og Azure Data Explorer støtter imidlertid ikke erstatning som en oppdateringsmetode.
Erstatt: I hver dataflytoppdatering slippes dataene fra målet og erstattes av utdata for dataflyten.
Tilføy: I hver dataflytoppdatering legges utdata fra dataflyten til de eksisterende dataene i datamåltabellen.
Skjemaalternativer ved publisering
Skjemaalternativer for publisering gjelder bare når oppdateringsmetoden er erstattet. Når du tilføyer data, er ikke endringer i skjemaet mulig.
Dynamisk skjema: Når du velger dynamisk skjema, tillater du skjemaendringer i datamålet når du publiserer dataflyten på nytt. Fordi du ikke bruker administrert tilordning, må du fortsatt oppdatere kolonnetilordningen i målflytflyten for dataflyten når du gjør endringer i spørringen. Når dataflyten oppdateres, slippes tabellen og gjenopprettes. Oppdatering av dataflyten kan føre til fjerning av relasjoner eller mål som ble lagt til tidligere i tabellen.
Fast skjema: Når du velger fast skjema, er ikke skjemaendringer mulig. Når dataflyten oppdateres, slippes bare radene i tabellen og erstattes med utdata fra dataflyten. Eventuelle relasjoner eller mål i tabellen forblir intakte. Hvis du gjør endringer i spørringen i dataflyten, mislykkes publiseringen av dataflyten hvis den oppdager at spørringsskjemaet ikke samsvarer med datamålskjemaet. Bruk denne innstillingen når du ikke har tenkt å endre skjemaet og har relasjoner eller mål lagt til i måltabellen.
Merk
Når du laster inn data i lageret, støttes bare fast skjema.
Støttede datakildetyper per mål
| Støttede datatyper per lagringsplassering | DataflowStagingLakehouse | Azure DB-utdata (SQL) | Azure Data Explorer Output | Fabric Lakehouse (LH) Utgang | Fabric Warehouse (WH) Utgang | Sql-utdata (Fabric SQL Database) |
|---|---|---|---|---|---|---|
| Handling | Nei | No | No | No | No | No |
| Any | Nei | No | No | No | No | No |
| Binær | Nei | No | No | No | No | Nei |
| Valuta | Ja | Ja | Ja | Ja | No | Ja |
| DateTimeZone | Ja | Ja | Ja | No | No | Ja |
| Duration | Nei | No | Ja | No | No | No |
| Function | Nei | No | No | No | No | Nei |
| Ingen | Nei | No | No | No | No | No |
| Null | Nei | No | No | No | No | No |
| Tid | Ja | Ja | No | No | No | Ja |
| Type | Nei | No | No | No | No | No |
| Strukturert (liste, post, tabell) | Nei | No | No | No | No | No |
Avanserte emner
Bruke oppsamling før innlasting til et mål
Hvis du vil forbedre ytelsen til spørringsbehandling, kan oppsamling brukes i Dataflyter Gen2 til å bruke Stoff-databehandling til å utføre spørringene.
Når oppsamling er aktivert på spørringene dine (standard virkemåte), lastes dataene inn i oppsamlingsplasseringen, som er et internt Lakehouse som bare er tilgjengelig av selve dataflyten.
Bruk av plasseringer for oppsamling kan forbedre ytelsen i noen tilfeller der det er raskere å brette spørringen til SQL Analytics-endepunktet enn i minnebehandlingen.
Når du laster inn data i Lakehouse eller andre ikke-lagermål, deaktiverer vi som standard oppsamlingsfunksjonen for å forbedre ytelsen. Når du laster inn data i datamålet, skrives dataene direkte til datamålet uten å bruke oppsamling. Hvis du vil bruke oppsamling for spørringen, kan du aktivere den på nytt.
Hvis du vil aktivere oppsamling, høyreklikker du på spørringen og aktiverer oppsamling ved å velge Aktiver oppsamling-knappen . Spørringen blir deretter blå.
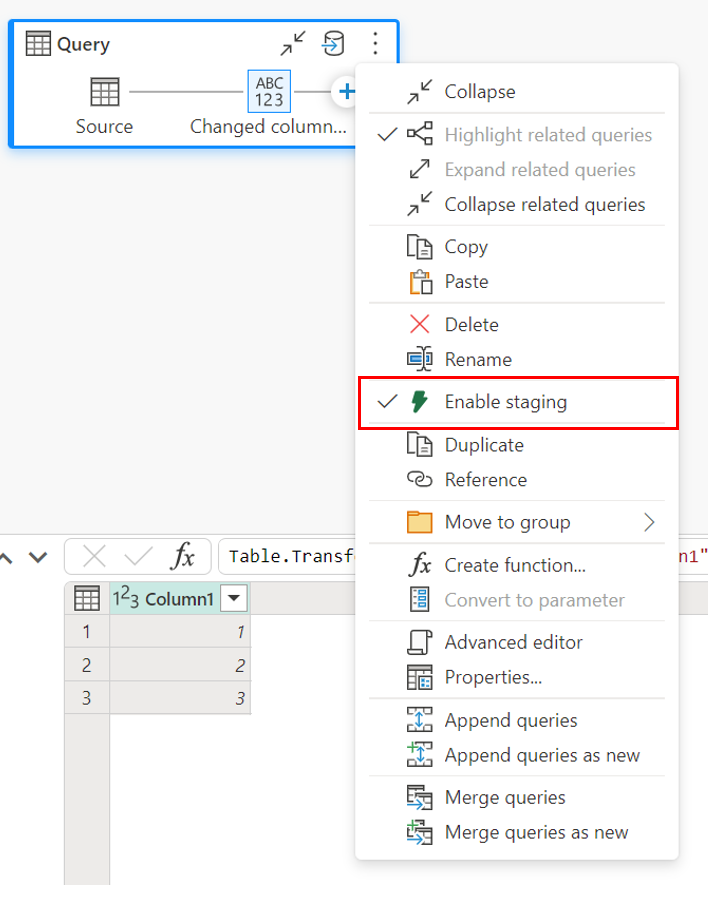
Laster inn data i lageret
Når du laster inn data i lageret, kreves oppsamling før skriveoperasjonen til datamålet. Dette kravet forbedrer ytelsen. For øyeblikket støttes bare innlasting i samme arbeidsområde som dataflyten. Kontroller at oppsamling er aktivert for alle spørringer som lastes inn i lageret.
Når oppsamling er deaktivert, og du velger Lager som utdatamål, får du en advarsel om å aktivere oppsamling først før du kan konfigurere datamålet.
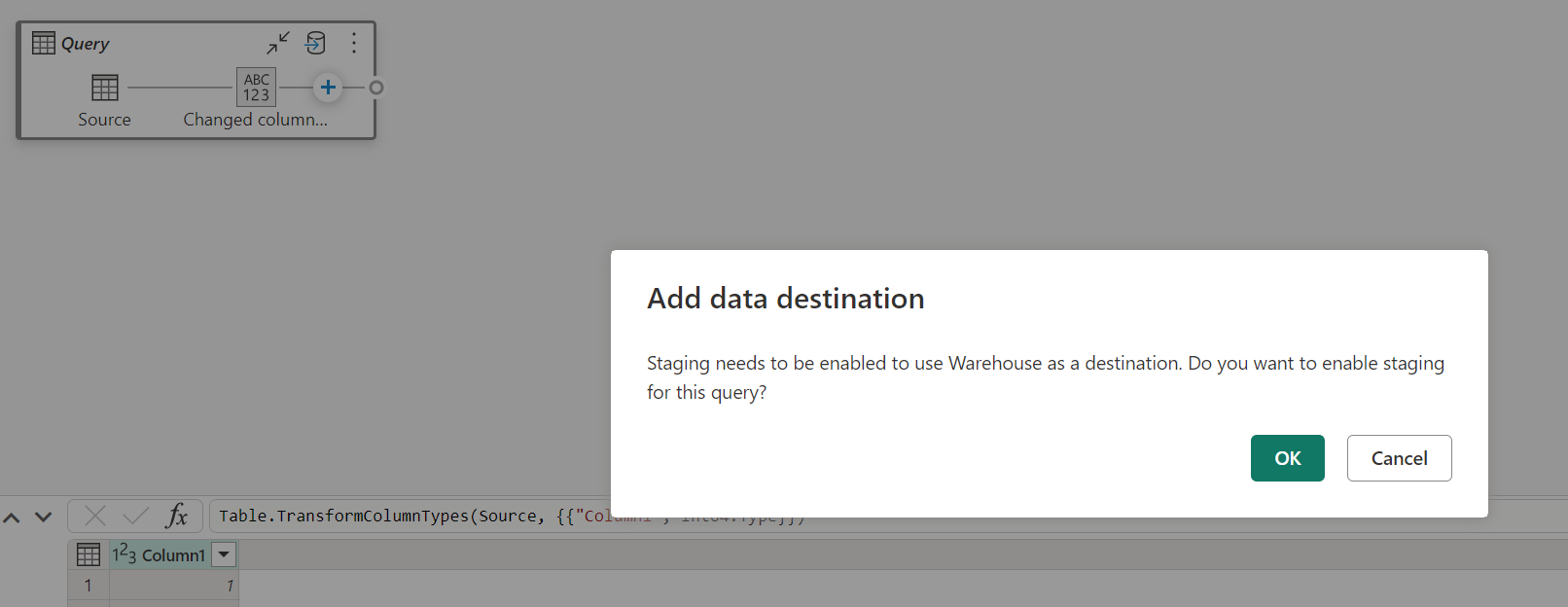
Hvis du allerede har et lager som mål og prøver å deaktivere oppsamling, vises en advarsel. Du kan enten fjerne lageret som mål eller avvise oppsamlingshandlingen.
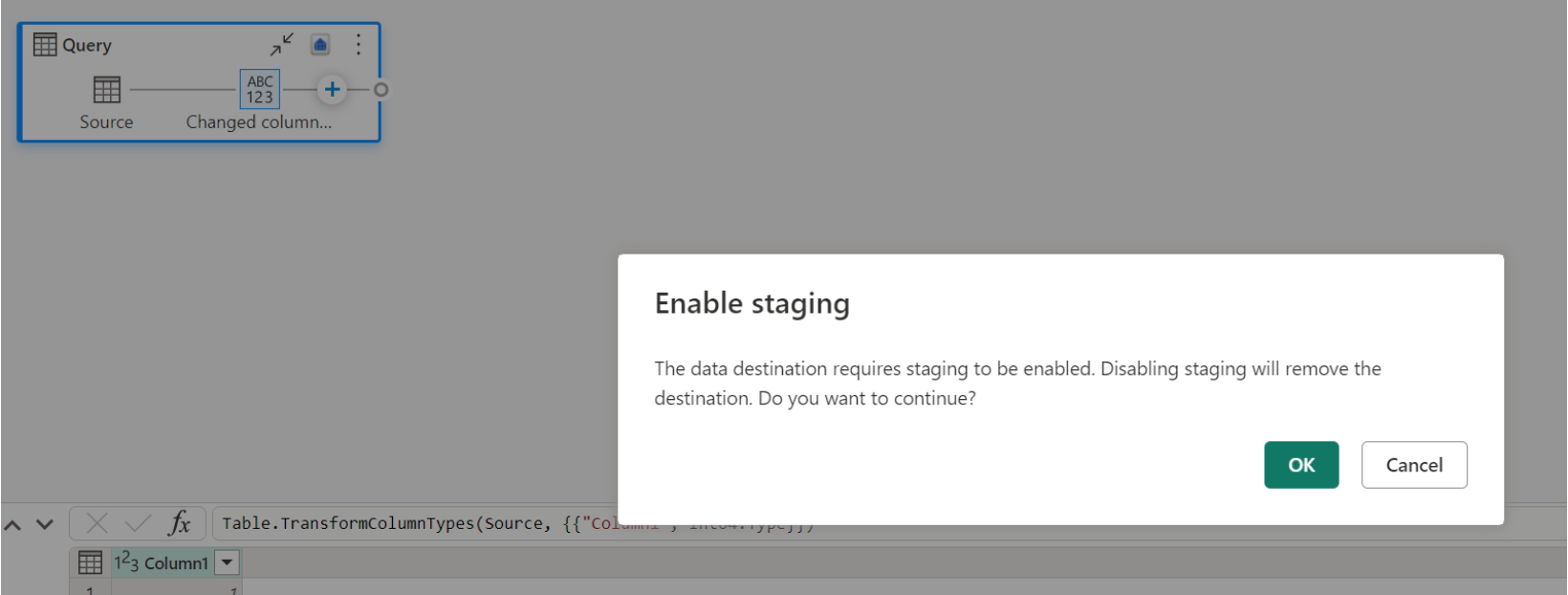
Støvsuge lakehouse-datamålet
Når du bruker Lakehouse som destinasjon for Dataflow Gen2 i Microsoft Fabric, er det avgjørende å utføre regelmessig vedlikehold for å sikre optimal ytelse og effektiv lagringsadministrasjon. En viktig vedlikeholdsoppgave er å støvsuge datamålet. Denne prosessen bidrar til å fjerne gamle filer som ikke lenger refereres til av Delta-tabellloggen, og dermed optimalisere lagringskostnader og opprettholde integriteten til dataene.
Hvorfor støvsuging er viktig
- Lagringsoptimalisering: Over tid akkumulerer Delta-tabeller gamle filer som ikke lenger er nødvendige. Støvsuging bidrar til å rydde opp i disse filene, frigjøre lagringsplass og redusere kostnadene.
- Ytelsesforbedring: Fjerning av unødvendige filer kan forbedre spørringsytelsen ved å redusere antall filer som må skannes under leseoperasjoner.
- Dataintegritet: Å sikre at bare relevante filer beholdes bidrar til å opprettholde integriteten til dataene dine, og forhindrer potensielle problemer med uforpliktende filer som kan føre til leserfeil eller tabellfeil.
Slik støvsuger du datamålet
Følg disse trinnene for å støvsuge Delta-tabellene i Lakehouse:
- Gå til Lakehouse: Gå til ønsket Lakehouse fra Microsoft Fabric-kontoen.
- Vedlikehold av Access-tabell: Høyreklikk på tabellen du vil vedlikeholde, i Lakehouse Explorer, eller bruk ellipsen til å få tilgang til hurtigmenyen.
- Velg vedlikeholdsalternativer: Velg oppføringen på vedlikeholdsmenyen , og velg alternativet Vakuum .
- Kjør vakuumkommandoen: Angi oppbevaringsterskelen (standard er sju dager) og utfør vakuumkommandoen ved å velge Kjør nå.
Beste fremgangsmåter
- Oppbevaringsperiode: Angi et oppbevaringsintervall på minst sju dager for å sikre at gamle øyeblikksbilder og uforpliktende filer ikke fjernes for tidlig, noe som kan forstyrre samtidige tabelllesere og forfattere.
- Regelmessig vedlikehold: Planlegg regelmessig støvsuging som en del av datavedlikeholdsrutinen for å holde Delta-tabellene optimalisert og klar for analyse.
Ved å innlemme støvsuging i strategien for datavedlikehold, kan du sikre at Lakehouse-destinasjonen forblir effektiv, kostnadseffektiv og pålitelig for dataflytoperasjonene dine.
Hvis du vil ha mer detaljert informasjon om vedlikehold av tabeller i Lakehouse, kan du se vedlikeholdsdokumentasjonen for Delta-tabellen.
Kan nullstilles
I noen tilfeller når du har en kolonne som kan nullstilles, blir den oppdaget av Power Query som ikke-nullbar, og når du skriver til datamålet, kan ikke kolonnetypen nullstilles. Under oppdateringen oppstår følgende feil:
E104100 Couldn't refresh entity because of an issue with the mashup document MashupException.Error: DataFormat.Error: Error in replacing table's content with new data in a version: #{0}., InnerException: We can't insert null data into a non-nullable column., Underlying error: We can't insert null data into a non-nullable column. Details: Reason = DataFormat.Error;Message = We can't insert null data into a non-nullable column.; Message.Format = we can't insert null data into a non-nullable column.
Hvis du vil tvinge kolonner som kan nullstilles, kan du prøve følgende fremgangsmåte:
Slett tabellen fra datamålet.
Fjern datamålet fra dataflyten.
Gå til dataflyten og oppdater datatypene ved hjelp av følgende Power Query-kode:
Table.TransformColumnTypes( #"PREVIOUS STEP", { {"COLLUMNNAME1", type nullable text}, {"COLLUMNNAME2", type nullable Int64.Type} } )Legg til datamålet.
Konvertering og oppskalering av datatyper
I noen tilfeller er datatypen i dataflyten forskjellig fra det som støttes i datamålet nedenfor, noen standardkonverteringer vi har satt på plass for å sikre at du fremdeles kan hente dataene i datamålet:
| Mål | Datatype for dataflyt | Måldatatype |
|---|---|---|
| Fabric Warehouse | Int8.Type | Int16.Type |