Konfigurer Azure Synapse Analytics i en kopiaktivitet
Denne artikkelen beskriver hvordan du bruker kopieringsaktiviteten i datasamlebåndet til å kopiere data fra og til Azure Synapse Analytics.
Støttet konfigurasjon
Hvis du vil ha konfigurasjonen av hver fane under kopieringsaktivitet, kan du gå til følgende inndelinger.
Generelt
Se veiledningen for generelle innstillinger for å konfigurere fanen Generelle innstillinger.
Kilde
Følgende egenskaper støttes for Azure Synapse Analytics under Kilde-fanen for en kopiaktivitet.

Følgende egenskaper er nødvendige:
Datalagertype: Velg ekstern.
Koble til ion: Velg en Azure Synapse Analytics-tilkobling fra tilkoblingslisten. Hvis tilkoblingen ikke finnes, oppretter du en ny Azure Synapse Analytics-tilkobling ved å velge Ny.
Koble til iontype: Velg Azure Synapse Analytics.
Bruk spørring: Du kan velge tabell, spørring eller lagret prosedyre for å lese kildedataene. Listen nedenfor beskriver konfigurasjonen av hver innstilling:
Tabell: Les data fra tabellen du angav i Tabellen hvis du velger denne knappen. Velg tabellen fra rullegardinlisten, eller velg Rediger for å angi skjema- og tabellnavnet manuelt.

Spørring: Angi den egendefinerte SQL-spørringen som skal leses data. Et eksempel er
select * from MyTable. Eller velg blyantikonet du vil redigere i koderedigeringsprogrammet.
Lagret prosedyre: Bruk den lagrede prosedyren som leser data fra kildetabellen. Den siste SQL-setningen må være en SELECT-setning i den lagrede prosedyren.

- Navn på lagret prosedyre: Velg den lagrede prosedyren, eller angi navnet på den lagrede prosedyren manuelt når du velger Rediger.
- Lagrede prosedyreparametere: Velg importparametere for å importere parameteren i den angitte lagrede prosedyren, eller legg til parametere for den lagrede prosedyren ved å velge + Ny. Tillatte verdier er navn eller verdipar. Navn og foringsrør for parametere må samsvare med navnene og foringsrøret til de lagrede prosedyreparameterne.

Under Avansert kan du angi følgende felt:
Tidsavbrudd for spørring (minutter): Angi tidsavbrudd for kjøring av spørringskommando, standard er 120 minutter. Hvis en parameter er angitt for denne egenskapen, er tillatte verdier tidsrom, for eksempel 02:00:00( 120 minutter).
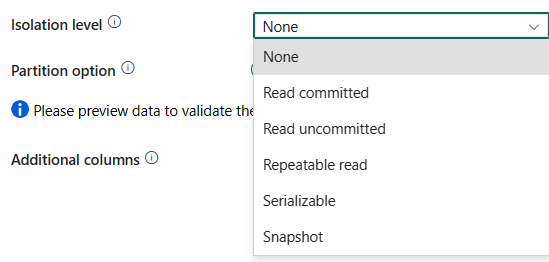
Isolasjonsnivå: Angir virkemåten for transaksjonslåsing for SQL-kilden. De tillatte verdiene er: Ingen, Lese forpliktet, Lese uforpliktende, Gjentabar lesing, Serialiserbar eller Øyeblikksbilde. Hvis ikke angitt, brukes ingen isoleringsnivå . Se IsolationLevel-opplisting for mer informasjon.
Partisjonsalternativ: Angi alternativene for datapartisjonering som brukes til å laste inn data fra Azure Synapse Analytics. Tillatte verdier er: Ingen (standard), fysiske partisjoner i tabellen og dynamisk område. Når et partisjonsalternativ er aktivert (det vil være ingen), styres graden av parallellitet for samtidig innlasting av data fra en Azure Synapse Analytics av den parallelle kopiinnstillingen på kopiaktiviteten.
Ingen: Velg denne innstillingen for ikke å bruke en partisjon.
Fysiske partisjoner i tabellen: Velg denne innstillingen hvis du vil bruke en fysisk partisjon. Partisjonskolonnen og -mekanismen bestemmes automatisk basert på den fysiske tabelldefinisjonen.
Dynamisk område: Velg denne innstillingen hvis du vil bruke dynamisk områdepartisjon. Når du bruker spørring med parallell aktivert, er parameteren(
?DfDynamicRangePartitionCondition) for områdepartisjon nødvendig. Eksempelspørring:SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition.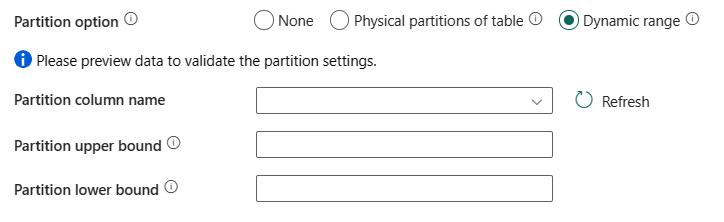
- Partisjonskolonnenavn: Angi navnet på kildekolonnen i heltall eller dato/klokkesletttype (
int, ,smallint,bigint,date,smalldatetime,datetime,datetime2ellerdatetimeoffset) som brukes av områdepartisjonering for parallell kopi. Hvis det ikke er angitt, oppdages indeksen eller primærnøkkelen for tabellen automatisk og brukes som partisjonskolonne. - Partisjonsgrense: Angi maksimumsverdien for partisjonskolonnen for deling av partisjonsområde. Denne verdien brukes til å bestemme partisjonssteget, ikke for filtrering av radene i tabellen. Alle rader i tabellen eller spørringsresultatet partisjoneres og kopieres.
- Partisjonsgrense: Angi minimumsverdien for partisjonskolonnen for deling av partisjonsområde. Denne verdien brukes til å bestemme partisjonssteget, ikke for filtrering av radene i tabellen. Alle rader i tabellen eller spørringsresultatet partisjoneres og kopieres.
- Partisjonskolonnenavn: Angi navnet på kildekolonnen i heltall eller dato/klokkesletttype (
Flere kolonner: Legg til flere datakolonner for å lagre kildefilens relative bane eller statiske verdi. Uttrykket støttes for sistnevnte. Hvis du vil ha mer informasjon, kan du gå til Legg til flere kolonner under kopieringen.
Mål
Følgende egenskaper støttes for Azure Synapse Analytics under Mål-fanen for en kopiaktivitet.
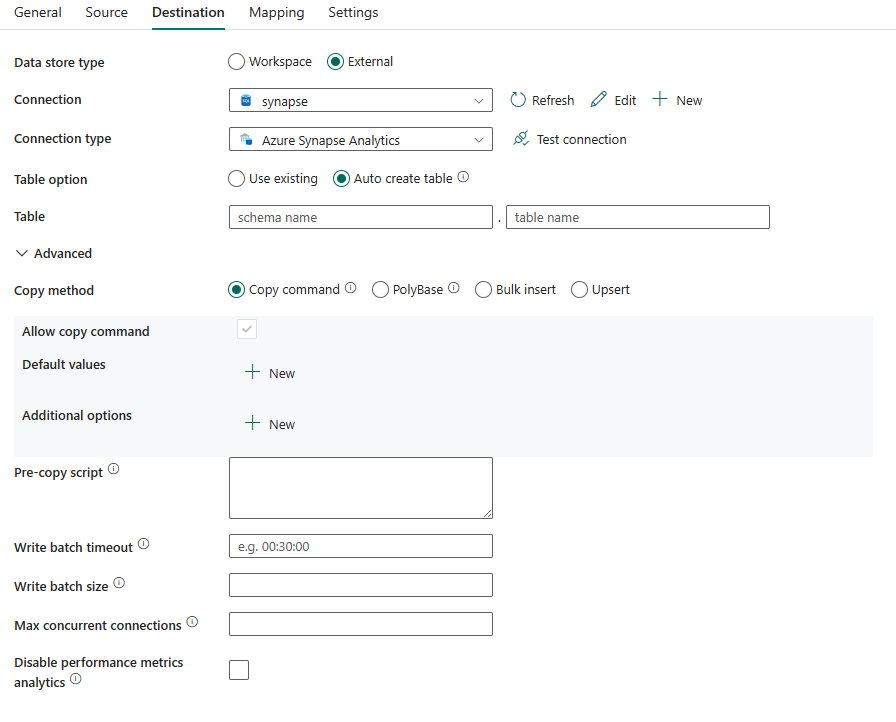
Følgende egenskaper er nødvendige:
- Datalagertype: Velg ekstern.
- Koble til ion: Velg en Azure Synapse Analytics-tilkobling fra tilkoblingslisten. Hvis tilkoblingen ikke finnes, oppretter du en ny Azure Synapse Analytics-tilkobling ved å velge Ny.
- Koble til iontype: Velg Azure Synapse Analytics.
- Tabellalternativ: Du kan velge Bruk eksisterende, Opprett tabell automatisk. Listen nedenfor beskriver konfigurasjonen av hver innstilling:
- Bruk eksisterende: Velg tabellen i databasen fra rullegardinlisten. Du kan også kontrollere Rediger for å angi skjema- og tabellnavnet manuelt.
- Automatisk oppretting av tabell: Tabellen opprettes automatisk (hvis ikke-eksisterende) i kildeskjemaet.
Under Avansert kan du angi følgende felt:
Kopier metode Velg metoden du vil bruke til å kopiere data. Du kan velge Kopier-kommandoen, PolyBase, Masseinnsetting eller Upsert. Listen nedenfor beskriver konfigurasjonen av hver innstilling:
Kopier kommando: Bruk COPY-setningen til å laste inn data fra Azure Storage i Azure Synapse Analytics eller SQL Pool.
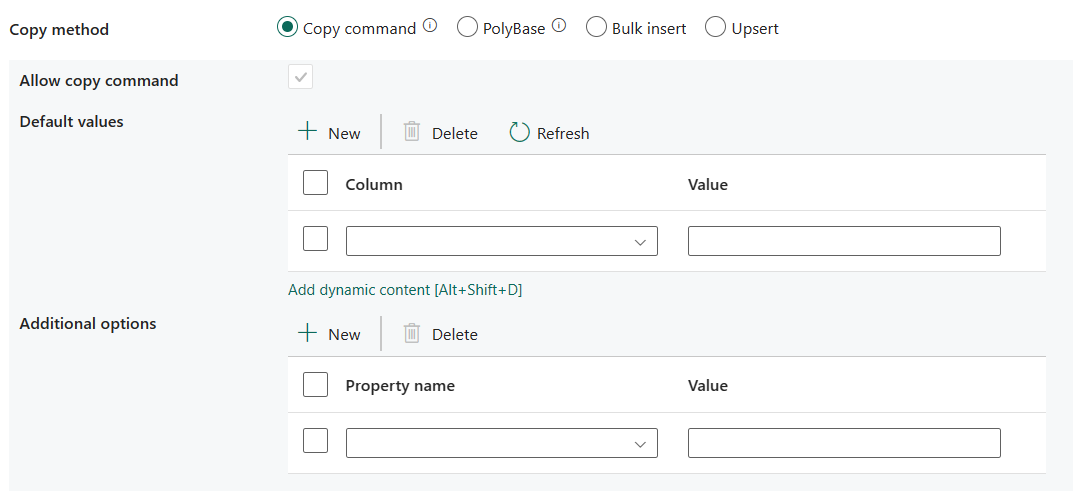
- Tillat kopiering-kommandoen: Det er obligatorisk å velge når du velger Kopier-kommandoen.
- Standardverdier: Angi standardverdiene for hver målkolonne i Azure Synapse Analytics. Standardverdiene i egenskapen overskriver STANDARDbetingelsessettet i datalageret, og identitetskolonnen kan ikke ha en standardverdi.
- Flere alternativer: Flere alternativer som sendes til en Azure Synapse Analytics COPY-setning direkte i «Med»-setningsdelen i COPY-setningen. Anfør verdien etter behov for å justere med kravene for COPY-setningen.
PolyBase: PolyBase er en mekanisme for høy gjennomstrømming. Bruk den til å laste inn store mengder data i Azure Synapse Analytics eller SQL Pool.
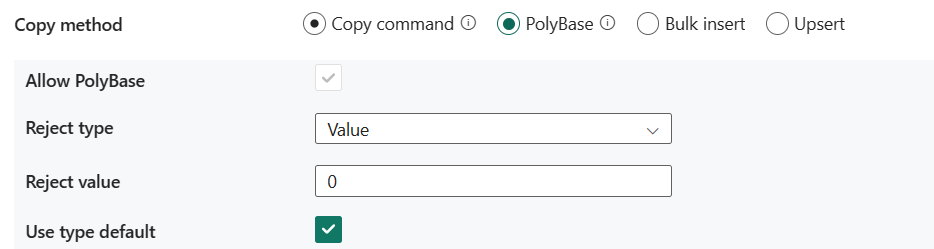
- Tillat polybase: Det er obligatorisk å velge når du velger PolyBase.
- Avvis type: Angi om rejectValue-alternativet er en litteralverdi eller en prosentdel. Tillatte verdier er verdi (standard) og prosent.
- Avvis verdi: Angi antall eller prosentvise rader som kan avvises før spørringen mislykkes. Mer informasjon om polybasens avvisingsalternativer i Argumenter-delen av OPPRETT EKSTERN TABELL (Transact-SQL). Tillatte verdier er 0 (standard), 1, 2 osv.
- Avvis utvalgsverdi: Bestemmer antall rader som skal hentes før PolyBase beregner prosentandelen av avviste rader på nytt. Tillatte verdier er 1, 2 osv. Hvis du velger Prosent som forkastingstype, kreves denne egenskapen.
- Bruk standardtype: Angi hvordan du skal håndtere manglende verdier i tekstfiler med skilletegn når PolyBase henter data fra tekstfilen. Mer informasjon om denne egenskapen fra Argumenter-inndelingen i OPPRETT EKSTERNT FILFORMAT (Transact-SQL). Tillatte verdier er valgt (standard) eller ikke valgt.
Masseinnsettelse: Bruk masseinnsettelse til å sette inn data til mål i bulk.

- Lås for masseinnsettelse av tabell: Bruk denne til å forbedre kopieringsytelsen under masseinnsettelse i tabeller uten indeks fra flere klienter. Mer informasjon fra MASSEINNDELING (Transact-SQL).
Upsert: Angi gruppen av innstillingene for skriveatferd når du vil oppsendt data til målet.
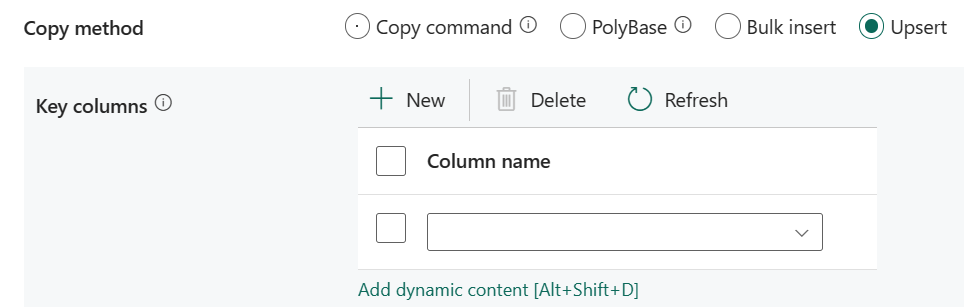
Nøkkelkolonner: Velg hvilken kolonne som skal brukes til å avgjøre om en rad fra kilden samsvarer med en rad fra målet.
Lås for masseinnsettelse av tabell: Bruk denne til å forbedre kopieringsytelsen under masseinnsettelse i tabeller uten indeks fra flere klienter. Mer informasjon fra MASSEINNDELING (Transact-SQL).
Forhåndskopier skript: Angi et skript for kopieringsaktivitet som skal utføres før du skriver data til en måltabell i hver kjøring. Du kan bruke denne egenskapen til å rydde opp i de forhåndsinnlastede dataene.
Skriv tidsavbrudd for satsvis tidsavbrudd: Angi ventetiden for at den satsvise innsettingsoperasjonen skal fullføres før den blir tidsavbrutt. Den tillatte verdien er timespan. Standardverdien er 00:30:00 (30 minutter).
Skrive bunkestørrelse: Angi antall rader som skal settes inn i SQL-tabellen per bunke. Den tillatte verdien er heltall (antall rader). Som standard bestemmer tjenesten dynamisk riktig satsvis størrelse basert på radstørrelsen.
Maksimalt antall samtidige tilkoblinger: Angi den øvre grensen for samtidige tilkoblinger som ble opprettet i datalageret under aktivitetskjøringen. Angi en verdi bare når du vil begrense samtidige tilkoblinger.
Deaktiver analyse av ytelsesmåledata: Denne innstillingen brukes til å samle inn måledata, for eksempel DTU, DWU, RU og så videre, for kopiering av ytelsesoptimalisering og anbefalinger. Hvis du er opptatt av denne virkemåten, merker du av for dette alternativet. Det er ikke valgt som standard.
Direktekopi ved hjelp av KOMMANDOEN KOPIER
Azure Synapse Analytics COPY-kommandoen støtter direkte Azure Blob Storage og Azure Data Lake Storage Gen2 som kildedatalagre. Hvis kildedataene oppfyller vilkårene som er beskrevet i denne delen, kan du bruke KOPIER-kommandoen til å kopiere direkte fra kildedatalageret til Azure Synapse Analytics.
Kildedataene og formatet inneholder følgende typer og godkjenningsmetoder:
Støttet kildedatalagertype Støttet format Støttet kildegodkjenningstype Azure Blob-lagring Tekst med skilletegn
ParquetAnonym godkjenning
Godkjenning av kontonøkkel
Godkjenning av delt tilgangssignaturAzure Data Lake Storage Gen2 Tekst med skilletegn
ParquetGodkjenning av kontonøkkel
Godkjenning av delt tilgangssignaturFølgende formatinnstillinger kan angis:
- For parquet: Komprimeringstype kan være Ingen, kjapp eller gzip.
- For Skilletegntekst:
- Radskilletegn: Når du kopierer tekst med skilletegn til Azure Synapse Analytics via kommandoen direkte KOPIER, angir du radskilletegnet eksplisitt (\r; \n; eller \r\n). Bare når radskilletegnet for kildefilen er \r\n, fungerer standardverdien (\r, \n eller \r\n). Ellers kan du aktivere oppsamling for scenarioet ditt.
- Nullverdi er igjen som standard eller satt til tom streng ("").
- Koding er igjen som standard eller satt til UTF-8 eller UTF-16.
- Hopp over linjeantallet er igjen som standard eller satt til 0.
- Komprimeringstype kan være Ingen eller gzip.
Hvis kilden er en mappe, må du merke av for Rekursivt .
Starttidspunkt (UTC) og Sluttidspunkt (UTC) i Filter etter sist endret, Prefiks, Aktiver partisjonsoppdagelse og flere kolonner er ikke angitt.
Hvis du vil lære hvordan du inntar data i Azure Synapse Analytics ved hjelp av KOMMANDOEN KOPIER, kan du se denne artikkelen.
Hvis kildedatalageret og -formatet ikke opprinnelig støttes av en COPY-kommando, bruker du trinnvis kopi ved hjelp av kommandoen KOPIER i stedet. Dataene konverteres automatisk til et KOPIER-kommandokompatibelt format, og kaller deretter en COPY-kommando for å laste inn data i Azure Synapse Analytics.
Tilordning
Hvis du ikke bruker Azure Synapse Analytics med automatisk oppretting av tabell som mål, kan du gå til Tilordning for fanen Tilordning.
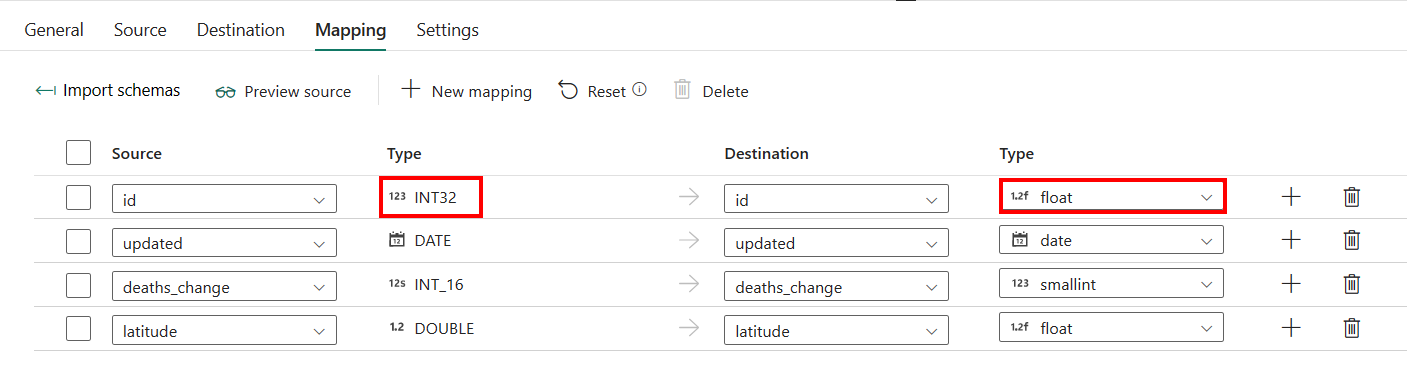
Hvis du bruker Azure Synapse Analytics med automatisk oppretting av tabell som mål, bortsett fra konfigurasjonen i Tilordning, kan du redigere typen for målkolonnene. Når du har valgt Importer skjemaer, kan du angi kolonnetypen i målet.
Typen for ID-kolonne i kilde er for eksempel heltall, og du kan endre den til flyttype når du tilordner til målkolonnen.
Innstillinger
Hvis du vil ha Innstillinger fanekonfigurasjon, kan du gå til Konfigurer de andre innstillingene under innstillinger-fanen.
Parallell kopi fra Azure Synapse Analytics
Azure Synapse Analytics-koblingen i kopieringsaktivitet gir innebygd datapartisjonering for å kopiere data parallelt. Du finner alternativer for datapartisjonering på Kilde-fanen for kopiaktiviteten.
Når du aktiverer partisjonert kopi, kjører kopieringsaktivitet parallelle spørringer mot Azure Synapse Analytics-kilden for å laste inn data etter partisjoner. Den parallelle graden styres av graden av kopi-parallellisme i fanen innstillinger for kopieringsaktivitet. Hvis du for eksempel angir grad av kopi-parallellisme til fire, genererer og kjører tjenesten samtidig fire spørringer basert på det angitte partisjonsalternativet og innstillingene, og hver spørring henter en del av dataene fra Azure Synapse Analytics.
Du foreslås å aktivere parallell kopi med datapartisjonering, spesielt når du laster inn store mengder data fra Azure Synapse Analytics. Følgende er foreslåtte konfigurasjoner for ulike scenarioer. Når du kopierer data til filbasert datalager, anbefales det å skrive til en mappe som flere filer (bare angi mappenavn), i så fall er ytelsen bedre enn å skrive til én enkelt fil.
| Scenario | Foreslåtte innstillinger |
|---|---|
| Full belastning fra store tabeller, med fysiske partisjoner. | Partisjonsalternativ: Fysiske partisjoner av tabellen. Under kjøringen oppdager tjenesten automatisk de fysiske partisjonene, og kopierer data etter partisjoner. Hvis du vil kontrollere om tabellen har fysisk partisjon eller ikke, kan du referere til denne spørringen. |
| Full belastning fra store tabeller, uten fysiske partisjoner, mens med et heltall eller datetime-kolonne for datapartisjonering. | Partisjonsalternativer: Dynamisk områdepartisjon. Partisjonskolonne (valgfritt): Angi kolonnen som brukes til å partisjonere data. Hvis ikke angitt, brukes indeksen eller primærnøkkelkolonnen. Partisjon øvre grense og partisjon nedre grense (valgfritt): Angi om du vil bestemme partisjonssteget. Dette er ikke for filtrering av radene i tabellen, alle radene i tabellen blir partisjonert og kopiert. Hvis det ikke er angitt, oppdager kopieringsaktiviteten automatisk verdiene. Hvis for eksempel partisjonskolonnen «ID» har verdier fra 1 til 100, og du angir den nedre grensen som 20 og øvre grense som 80, med parallell kopi som 4, henter tjenesten data etter 4 partisjoner – ID-er i området <=20, [21, 50], [51, 80] og >=81, henholdsvis. |
| Last inn en stor mengde data ved hjelp av en egendefinert spørring, uten fysiske partisjoner, mens med et heltall eller en date/datetime-kolonne for datapartisjonering. | Partisjonsalternativer: Dynamisk områdepartisjon. Spørring: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.Partisjonskolonne: Angi kolonnen som brukes til å partisjonere data. Partisjon øvre grense og partisjon nedre grense (valgfritt): Angi om du vil bestemme partisjonssteget. Dette er ikke for filtrering av radene i tabellen, alle radene i spørringsresultatet blir partisjonert og kopiert. Hvis det ikke er angitt, oppdager kopieringsaktivitet automatisk verdien. Hvis for eksempel partisjonskolonnen «ID» har verdier fra 1 til 100, og du angir den nedre grensen som 20 og øvre grense som 80, med parallell kopi som 4, henter tjenesten data etter henholdsvis 4 partisjoner- ID-er i området <=20, [21, 50], [51, 80] og >=81. Her er flere eksempelspørringer for ulike scenarioer: • Spør hele tabellen: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition• Spørring fra en tabell med kolonnevalg og flere der-setningsfiltre: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Spørring med delspørringer: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Spørring med partisjon i delspørring: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Anbefalte fremgangsmåter for innlasting av data med partisjonsalternativ:
- Velg distinkt kolonne som partisjonskolonne (for eksempel primærnøkkel eller unik nøkkel) for å unngå dataskyvhet.
- Hvis tabellen har innebygd partisjon, kan du bruke partisjonsalternativet Fysiske partisjoner i tabellen for å få bedre ytelse.
- Azure Synapse Analytics kan utføre maksimalt 32 spørringer om øyeblikket, ved å angi graden av kopi-parallellisme for stor, kan det føre til et synapsebegrensningsproblem.
Eksempelspørring for å kontrollere fysisk partisjon
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, c.name AS ColumnName, CASE WHEN c.name IS NULL THEN 'no' ELSE 'yes' END AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.types AS y ON c.system_type_id = y.system_type_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Hvis tabellen har fysisk partisjon, vil du se «HasPartition» som «ja».
Tabellsammendrag
Tabellene nedenfor inneholder mer informasjon om kopieringsaktiviteten i Azure Synapse Analytics.
Kilde
| Name | Beskrivelse | Verdi | Kreves | JSON-skriptegenskap |
|---|---|---|---|---|
| Datalagertype | Datalagertypen. | Ekstern | Ja | / |
| Koble til ion | Tilkoblingen til kildedatalageret. | < tilkoblingen > | Ja | Tilkobling |
| Koble til iontype | Kildetilkoblingstypen. | Azure Synapse Analytics | Ja | / |
| Bruk spørring | Måten å lese data på. | •Tabellen •Spørring • Lagret prosedyre |
Ja | • typeProperties (under typeProperties ->source)-Skjemaet -Tabellen • sqlReaderQuery • sqlReaderStoredProcedureName storedProcedureParameters -navn -Verdi |
| Tidsavbrudd for spørring | Tidsavbruddet for kjøring av spørringskommando, standard er 120 minutter. | Tidsrom | No | queryTimeout |
| Isolasjonsnivå | Virkemåten for transaksjonslåsing for SQL-kilden. | •Ingen • Lese forpliktet • Les uforpliktende • Les gjentatt •Serialiseres •Øyeblikksbilde |
No | isolationLevel: • ReadCommitted • ReadUncommitted • RepeatableRead •Serialiseres •Øyeblikksbilde |
| Partisjonsalternativ | Alternativene for datapartisjonering som brukes til å laste inn data fra Azure SQL Database. | •Ingen • Fysiske partisjoner av tabellen • Dynamisk område - Partisjonskolonnenavn - Partisjon øvre grense - Partisjon nedre grense |
No | partitionOption: • PhysicalPartitionsOfTable • DynamicRange partisjon Innstillinger: - partitionColumnName - partitionUpperBound - partitionLowerBound |
| Flere kolonner | Legg til flere datakolonner for å lagre kildefilens relative bane eller statiske verdi. Uttrykket støttes for sistnevnte. | • Navn •Verdi |
No | additionalColumns: •navn •Verdi |
Mål
| Name | Beskrivelse | Verdi | Kreves | JSON-skriptegenskap |
|---|---|---|---|---|
| Datalagertype | Datalagertypen. | Ekstern | Ja | / |
| Koble til ion | Tilkoblingen til måldatalageret. | < tilkoblingen > | Ja | Tilkobling |
| Koble til iontype | Måltilkoblingstypen. | Azure Synapse Analytics | Ja | / |
| Tabellalternativ | Alternativet måldatatabell. | • Bruk eksisterende • Opprett tabell automatisk |
Ja | • typeProperties (under typeProperties ->sink)-Skjemaet -Tabellen • tableOption: - autooppretting typeProperties (under typeProperties ->sink)-Skjemaet -Tabellen |
| Kopier metode | Metoden som brukes til å kopiere data. | • Kopier kommando • PolyBase • Masseinnst. • Oppsett |
No | / |
| Når du velger Kopier-kommandoen | Bruk COPY-setningen til å laste inn data fra Azure Storage til Azure Synapse Analytics eller SQL Pool. | / | Nei. Bruk når du bruker COPY. |
allowCopyCommand: sann copyCommand Innstillinger |
| Standardverdier | Angi standardverdiene for hver målkolonne i Azure Synapse Analytics. Standardverdiene i egenskapen overskriver STANDARDbetingelsessettet i datalageret, og identitetskolonnen kan ikke ha en standardverdi. | < Standardverdier > | No | defaultValues: - columnName -Defaultvalue |
| Flere alternativer | Flere alternativer som sendes til en Azure Synapse Analytics COPY-setning direkte i «Med»-setningsdelen i COPY-setningen. Anfør verdien etter behov for å justere med kravene for COPY-setningen. | < flere alternativer > | No | additionalOptions: - <egenskapsnavn> : <verdi> |
| Når du velger PolyBase | PolyBase er en mekanisme for høy gjennomstrømming. Bruk den til å laste inn store mengder data i Azure Synapse Analytics eller SQL Pool. | / | Nei. Bruk når du bruker PolyBase. |
allowPolyBase: sann polyBase Innstillinger |
| Avvis type | Typen forkastingsverdi. | •Verdi •Prosent |
No | rejectType: -Verdi -Prosent |
| Avvis verdi | Antall rader eller prosent som kan forkastes før spørringen mislykkes. | 0 (standard), 1, 2 osv. | No | rejectValue |
| Avvis eksempelverdi | Bestemmer antall rader som skal hentes før PolyBase beregner prosentandelen av avviste rader på nytt. | 1, 2 osv. | Ja når du angir Prosent som forkastingstype | rejectSampleValue |
| Bruk standardtype | Angi hvordan du skal håndtere manglende verdier i tekstfiler med skilletegn når PolyBase henter data fra tekstfilen. Mer informasjon om denne egenskapen fra Argumenter-inndelingen i OPPRETT EKSTERNT FILFORMAT (Transact-SQL) | valgt (standard) eller umerket. | No | useTypeDefault: sann (standard) eller usann |
| Når du velger Masseinnsendelse | Sett inn data til mål i bulk. | / | No | writeBehavior: Sett inn |
| Lås for masseinnset tabell | Bruk denne til å forbedre kopieringsytelsen under masseinnsettelse i tabeller uten indeks fra flere klienter. Mer informasjon fra MASSEINNDELING (Transact-SQL). | merket eller umerket (standard) | No | sqlWriterUseTableLock: sann eller usann (standard) |
| Når du velger Upsert | Angi gruppen av innstillingene for skrivevirkemåte når du vil oppsert data til målet. | / | No | writeBehavior: Upsert |
| Nøkkelkolonner | Angir hvilken kolonne som brukes til å avgjøre om en rad fra kilden samsvarer med en rad fra målet. | < kolonnenavn> | No | upsert Innstillinger: - nøkler: < kolonnenavn > - interimSchemaName |
| Lås for masseinnset tabell | Bruk denne til å forbedre kopieringsytelsen under masseinnsettelse i tabeller uten indeks fra flere klienter. Mer informasjon fra MASSEINNDELING (Transact-SQL). | merket eller umerket (standard) | No | sqlWriterUseTableLock: sann eller usann (standard) |
| Forhåndskopier skript | Et skript for kopier aktivitet som skal utføres før du skriver data til en måltabell i hver kjøring. Du kan bruke denne egenskapen til å rydde opp i de forhåndsinnlastede dataene. | < forhåndskopieringsskript > (streng) |
No | preCopyScript |
| Tidsavbrudd for skrivegruppe | Ventetiden for at den satsvise innsettingsoperasjonen skal fullføres før den blir tidsavbrutt. Den tillatte verdien er timespan. Standardverdien er 00:30:00 (30 minutter). | Tidsrom | No | writeBatchTimeout |
| Skrive bunkestørrelse | Antall rader som skal settes inn i SQL-tabellen per bunke. Som standard bestemmer tjenesten dynamisk riktig satsvis størrelse basert på radstørrelsen. | < antall rader > (heltall) |
No | writeBatchSize |
| Maksimalt antall samtidige tilkoblinger | Den øvre grensen for samtidige tilkoblinger som ble opprettet i datalageret under aktivitetskjøringen. Angi en verdi bare når du vil begrense samtidige tilkoblinger. | < øvre grense for samtidige tilkoblinger > (heltall) |
No | maxConcurrent Koble til ions |
| Deaktiver analyse av ytelsesmåledata | Denne innstillingen brukes til å samle inn måledata, for eksempel DTU, DWU, RU og så videre, for kopiering av ytelsesoptimalisering og anbefalinger. Hvis du er opptatt av denne virkemåten, merker du av for dette alternativet. | velg eller fjern merking (standard) | No | disableMetricsCollection: sann eller usann (standard) |