Konfigurer Azure Database for PostgreSQL i en kopiaktivitet
Denne artikkelen beskriver hvordan du bruker kopieringsaktiviteten i datasamlebåndet til å kopiere data fra og til Azure Database for PostgreSQL.
Støttet konfigurasjon
Hvis du vil ha konfigurasjonen av hver fane under kopieringsaktivitet, kan du gå til følgende inndelinger.
Generelt
Se Generelle innstillinger veiledning for å konfigurere generelt innstillinger-fanen.
Kilde
Gå til fanen Kilde for å konfigurere kopiaktivitetskilden. Se følgende innhold for detaljert konfigurasjon.
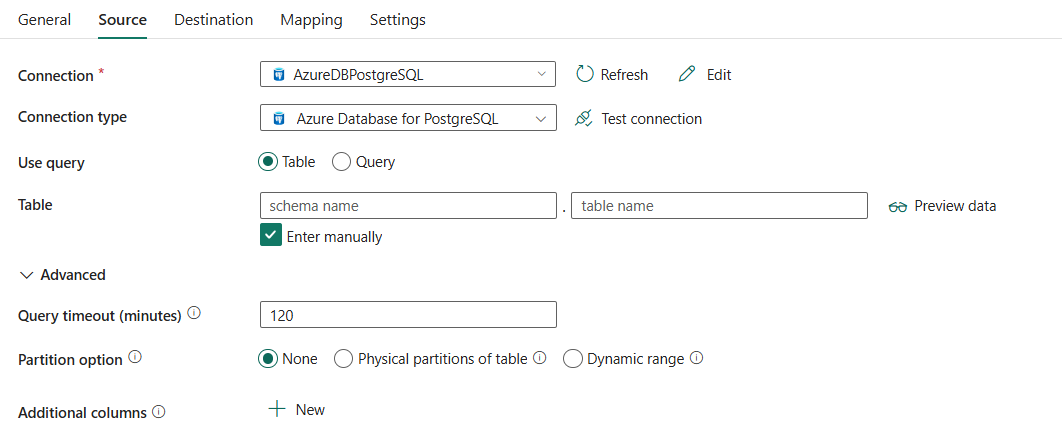
Følgende tre egenskaper er nødvendige:
- Connection: Velg en Azure Database for PostgreSQL-tilkobling fra tilkoblingslisten. Hvis det ikke finnes noen tilkobling, oppretter du en ny Azure Database for PostgreSQL-tilkobling.
- tilkoblingstype: Velg Azure Database for PostgreSQL.
-
Brukfor spørring: Velg tabell for å lese data fra den angitte tabellen, eller velg Spørring for å lese data ved hjelp av spørringer.
Hvis du velger tabell:
tabell: Velg tabellen fra rullegardinlisten, eller velg Skriv inn manuelt for å angi den manuelt for å lese data.

Hvis du velger spørring:
spørring: Angi den egendefinerte SQL-spørringen som skal leses data. Eksempel:
SELECT * FROM mytableellerSELECT * FROM "MyTable".Notat
I PostgreSQL behandles enhetsnavnet som skille mellom store og små bokstaver hvis det ikke oppgis.

Under Avansertkan du angi følgende felt:
tidsavbrudd for spørring (minutter): Angi ventetiden før du avslutter forsøket på å utføre en kommando og generere en feil, er standard 120 minutter. Hvis parameteren er angitt for denne egenskapen, er tillatte verdier tidsrom, for eksempel 02:00:00( 120 minutter). Hvis du vil ha mer informasjon, kan du se CommandTimeout.
partisjonsalternativ: Angir alternativene for datapartisjonering som brukes til å laste inn data fra Azure Database for PostgreSQL. Når et partisjonsalternativ er aktivert (det vil eksempel: ikke Ingen), kontrolleres graden av parallellitet for samtidig innlasting av data fra en Azure Database for PostgreSQL av Grad av kopi parallellitet i fanen innstillinger for kopieringsaktivitet.
Hvis du velger Ingen, velger du ikke å bruke partisjon.
Hvis du velger fysiske partisjoner av tabell:
Partisjonsnavn: Angi listen over fysiske partisjoner som må kopieres.
Hvis du bruker en spørring til å hente kildedataene, kan du koble
?AdfTabularPartitionNamei WHERE-setningsdelen. Du kan for eksempel se delen Parallell kopi fra Azure Database for PostgreSQL.
Hvis du velger dynamisk område:
partisjonskolonnenavn: Angi navnet på kildekolonnen i heltall eller dato/dato/klokkeslett-type (
int,smallint,bigint,date,timestamp without time zone,timestamp with time zoneellertime without time zone) som skal brukes av områdepartisjonering for parallell kopi. Hvis ikke angitt, oppdages primærnøkkelen for tabellen automatisk og brukes som partisjonskolonne.Hvis du bruker en spørring til å hente kildedataene, kan du koble
?AdfRangePartitionColumnNamei WHERE-setningsdelen. Du kan for eksempel se delen Parallell kopi fra Azure Database for PostgreSQL.partisjonens øvre grense: Angi maksimumsverdien for partisjonskolonnen for å kopiere data ut.
Hvis du bruker en spørring til å hente kildedataene, kan du koble
?AdfRangePartitionUpboundi WHERE-setningsdelen. Du kan for eksempel se delen Parallell kopi fra Azure Database for PostgreSQL. .Partisjon nedre bundet: Angi minimumsverdien for partisjonskolonnen for å kopiere data ut.
Hvis du bruker en spørring til å hente kildedataene, kan du koble
?AdfRangePartitionLowboundi WHERE-setningsdelen. Du kan for eksempel se delen Parallell kopi fra Azure Database for PostgreSQL.
Flere kolonner: Legg til flere datakolonner for å lagre kildefilens relative bane eller statiske verdi. Uttrykket støttes for sistnevnte.
Destinasjon
Gå til Mål-fanen for å konfigurere målet for kopiaktiviteten. Se følgende innhold for detaljert konfigurasjon.
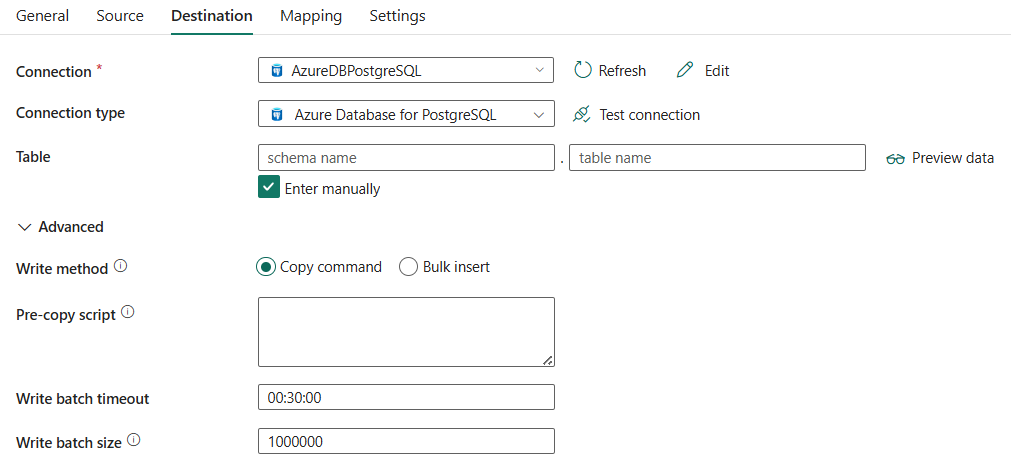
Følgende tre egenskaper er nødvendige:
- Connection: Velg en Azure Database for PostgreSQL-tilkobling fra tilkoblingslisten. Hvis det ikke finnes noen tilkobling, oppretter du en ny Azure Database for PostgreSQL-tilkobling.
- tilkoblingstype: Velg Azure Database for PostgreSQL.
- tabell: Velg tabellen fra rullegardinlisten, eller velg Skriv inn manuelt for å skrive inn data.
Under Avansertkan du angi følgende felt:
Skrivemetode: Velg metoden som brukes til å skrive data til Azure Database for PostgreSQL. Velg fra Kopier-kommandoen (standard, som er mer utførvendt) og Masseinnsetter.
forhåndskopiert skript: Angi en SQL-spørring for kopieringsaktiviteten som skal utføres før du skriver data til Azure Database for PostgreSQL i hver kjøring. Du kan bruke denne egenskapen til å rydde opp i de forhåndslastede dataene.
Skrive satsvis tidsavbrudd: Angi ventetiden for at den satsvise innsettingsoperasjonen skal fullføres før den blir tidsavbrutt. Den tillatte verdien er timespan. Standardverdien er 00:30:00 (30 minutter).
Skrive bunkestørrelse: Angi antall rader som er lastet inn i Azure Database for PostgreSQL per parti. Tillatt verdi er et heltall som representerer antall rader. Standardverdien er 1 000 000.
Kartlegging
Hvis du vil ha tilordning fanekonfigurasjon, kan du se Konfigurere tilordningene under tilordningsfanen.
Innstillinger
Hvis du vil ha Innstillinger fanekonfigurasjon, kan du gå til Konfigurere de andre innstillingene under innstillinger.
Parallell kopi fra Azure Database for PostgreSQL
Azure Database for PostgreSQL-koblingen i kopiaktivitet gir innebygd datapartisjonering for å kopiere data parallelt. Du finner alternativer for datapartisjonering på fanen Kilde i kopiaktiviteten.
Når du aktiverer partisjonert kopi, kjører kopieringsaktivitet parallelle spørringer mot Azure Database for PostgreSQL-kilden for å laste inn data etter partisjoner. Den parallelle graden styres av Grad av kopi parallellisme i fanen innstillinger for kopieringsaktivitet. Hvis du for eksempel angir Grad av kopi-parallellisme til fire, genererer og kjører tjenesten samtidig fire spørringer basert på det angitte partisjonsalternativet og innstillingene, og hver spørring henter en del av dataene fra Azure Database for PostgreSQL.
Du foreslås å aktivere parallell kopi med datapartisjonering, spesielt når du laster inn store mengder data fra Azure Database for PostgreSQL. Følgende er foreslåtte konfigurasjoner for ulike scenarioer. Når du kopierer data til filbasert datalager, anbefales det å skrive til en mappe som flere filer (bare angi mappenavn), i så fall er ytelsen bedre enn å skrive til én enkelt fil.
| Scenario | Foreslåtte innstillinger |
|---|---|
| Full belastning fra store tabeller, med fysiske partisjoner. |
partisjonsalternativ: Fysiske partisjoner i tabellen. Under kjøringen oppdager tjenesten automatisk de fysiske partisjonene, og kopierer data etter partisjoner. |
| Full belastning fra store tabeller, uten fysiske partisjoner, mens med en heltallskolonne for datapartisjonering. |
partisjonsalternativer: Dynamisk område. partisjonskolonne: Angi kolonnen som brukes til å partisjonere data. Hvis ikke angitt, brukes primærnøkkelkolonnen. |
| Last inn en stor mengde data ved hjelp av en egendefinert spørring, med fysiske partisjoner. |
partisjonsalternativ: Fysiske partisjoner i tabellen. spørring: SELECT * FROM ?AdfTabularPartitionName WHERE <your_additional_where_clause>.Partisjonsnavn: Angi partisjonsnavnene du vil kopiere data fra. Hvis ikke angitt, oppdager tjenesten automatisk de fysiske partisjonene i tabellen du angav i PostgreSQL-datasettet. Under kjøring erstatter tjenesten ?AdfTabularPartitionName med det faktiske partisjonsnavnet, og sender til Azure Database for PostgreSQL. |
| Last inn en stor mengde data ved hjelp av en egendefinert spørring, uten fysiske partisjoner, mens du har en heltallskolonne for datapartisjonering. |
partisjonsalternativer: Dynamisk område. spørring: SELECT * FROM ?AdfTabularPartitionName WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>.partisjonskolonne: Angi kolonnen som brukes til å partisjonere data. Du kan partisjonere mot kolonnen med heltall eller dato/datetime-datatype. partisjonens øvre grense og Partisjon nedre grense: Angi om du vil filtrere mot partisjonskolonnen for å hente data bare mellom nedre og øvre område. Under kjøring erstatter tjenesten ?AdfRangePartitionColumnName, ?AdfRangePartitionUpboundog ?AdfRangePartitionLowbound med det faktiske kolonnenavnet og verdiområder for hver partisjon, og sender til Azure Database for PostgreSQL. Hvis for eksempel partisjonskolonnen ID er angitt med nedre grense som 1 og øvre grense som 80, med parallell kopi angitt som 4, henter tjenesten data med 4 partisjoner. ID-ene deres er mellom henholdsvis [1,20], [21, 40], [41, 60] og [61, 80]. |
Anbefalte fremgangsmåter for innlasting av data med partisjonsalternativ:
- Velg distinkt kolonne som partisjonskolonne (for eksempel primærnøkkel eller unik nøkkel) for å unngå dataskyvhet.
- Hvis tabellen har innebygd partisjon, kan du bruke partisjonsalternativet «Fysiske partisjoner av tabellen» for å få bedre ytelse.
Tabellsammendrag
Tabellen nedenfor inneholder mer informasjon om kopieringsaktiviteten i Azure Database for PostgreSQL.
Kildeinformasjon
| Navn | Beskrivelse | Verdi | Påkrevd | JSON-skriptegenskap |
|---|---|---|---|---|
| tilkobling | Tilkoblingen til kildedatalageret. | < Azure Database for PostgreSQL-tilkoblingen > | Ja | forbindelse |
| tilkoblingstype | Kildetilkoblingstypen. | Azure Database for PostgreSQL | Ja | / |
| Bruk | Måten å lese data på. Bruk tabell for å lese data fra den angitte tabellen, eller bruk spørring for å lese data ved hjelp av spørringer. | • tabell • spørring |
Ja | • typeProperties (under typeProperties ->source)-skjema -bord •spørsmål |
| Tidsavbrudd for spørring (minutter) | Ventetiden før du avslutter forsøket på å utføre en kommando og generere en feil, er standard 120 minutter. Hvis parameteren er angitt for denne egenskapen, er tillatte verdier tidsrom, for eksempel 02:00:00( 120 minutter). Hvis du vil ha mer informasjon, kan du se CommandTimeout. | tidsrom | Nei | queryTimeout |
| Partisjonsnavn | Listen over fysiske partisjoner som må kopieres. Hvis du bruker en spørring til å hente kildedataene, kan du koble ?AdfTabularPartitionName i WHERE-setningsdelen. |
< partisjonsnavnene > | Nei | partitionNames |
| partisjonskolonnenavn | Navnet på kildekolonnen i heltall eller date/datetime-type (int, smallint, bigint, date, timestamp without time zone, timestamp with time zone eller time without time zone) som brukes av områdepartisjonering for parallell kopi. Hvis ikke angitt, oppdages primærnøkkelen for tabellen automatisk og brukes som partisjonskolonne. |
< navnene på partisjonskolonnen > | Nei | partitionColumnName |
| partisjonen øverst bundet | Maksimumsverdien for partisjonskolonnen for kopiering av data. Hvis du bruker en spørring til å hente kildedataene, kan du koble ?AdfRangePartitionUpbound i WHERE-setningsdelen. |
< partisjonen øverst bundet > | Nei | partitionUpperBound |
| Partisjon nedre grense | Minimumsverdien for partisjonskolonnen for å kopiere data ut. Hvis du bruker en spørring til å hente kildedataene, kan du koble ?AdfRangePartitionLowbound i WHERE-setningsdelen. |
< partisjonen nedre grense > | Nei | partitionLowerBound |
| flere kolonner | Legg til flere datakolonner for å lagre kildefilens relative bane eller statiske verdi. Uttrykket støttes for sistnevnte. | •Navn •Verdi |
Nei | additionalColumns: •navn •verdi |
Målinformasjon
| Navn | Beskrivelse | Verdi | Påkrevd | JSON-skriptegenskap |
|---|---|---|---|---|
| tilkobling | Tilkoblingen til måldatalageret. | < Azure Database for PostgreSQL-tilkoblingen > | Ja | forbindelse |
| tilkoblingstype | Måltilkoblingstypen. | Azure Database for PostgreSQL | Ja | / |
| tabell | Måldatatabellen for å skrive data. | < navnet på måltabellen > | Ja | typeProperties (under typeProperties ->sink):-skjema -bord |
| skrivemetode | Metoden som brukes til å skrive data til Azure Database for PostgreSQL. | • Kopier kommando (standard) • Masseinns |
Nei | writeMethod: • CopyCommand • BulkInsert |
| forhåndskopier skript | En SQL-spørring for kopieringsaktiviteten som skal kjøres før du skriver data til Azure Database for PostgreSQL i hver kjøring. Du kan bruke denne egenskapen til å rydde opp i de forhåndslastede dataene. | < det forhåndskopierte skriptet > | Nei | preCopyScript |
| Skrive tidsavbrudd for gruppe | Ventetiden for at den satsvise innsettingsoperasjonen skal fullføres før den blir tidsavbrutt. | tidsrom (standarden er 00:30:00 - 30 minutter) |
Nei | writeBatchTimeout |
| Skrive bunkestørrelse | Antall rader som er lastet inn i Azure Database for PostgreSQL per gruppe. | heltall (standarden er 1 000 000) |
Nei | writeBatchSize |