Transformer data ved hjelp av dbt
Merk
Apache Airflow-jobben drives av Apache Airflow.
dbt(Data Build Tool) er et kommandolinjegrensesnitt med åpen kildekode (CLI) som forenkler datatransformasjon og modellering i datalagre ved å administrere kompleks SQL-kode på en strukturert, vedlikeholdbar måte. Det gjør det mulig for datateam å opprette pålitelige, testbare transformasjoner i kjernen av analytiske datasamlebånd.
Når de er sammenkoblet med Apache Airflow, forbedres dbts transformasjonsfunksjoner av Airflows funksjoner for planlegging, orkestrering og oppgavebehandling. Denne kombinerte tilnærmingen, ved hjelp av dbts transformasjonsekspertise sammen med Airflows arbeidsflytadministrasjon, leverer effektive og robuste datasamlebånd, noe som til slutt fører til raskere og mer innsiktsfulle datadrevne beslutninger.
Denne opplæringen illustrerer hvordan du oppretter en Apache Airflow DAG som bruker dbt til å transformere data som er lagret i Microsoft Fabric Data Warehouse.
Forutsetning
Du må fullføre følgende forutsetninger for å komme i gang:
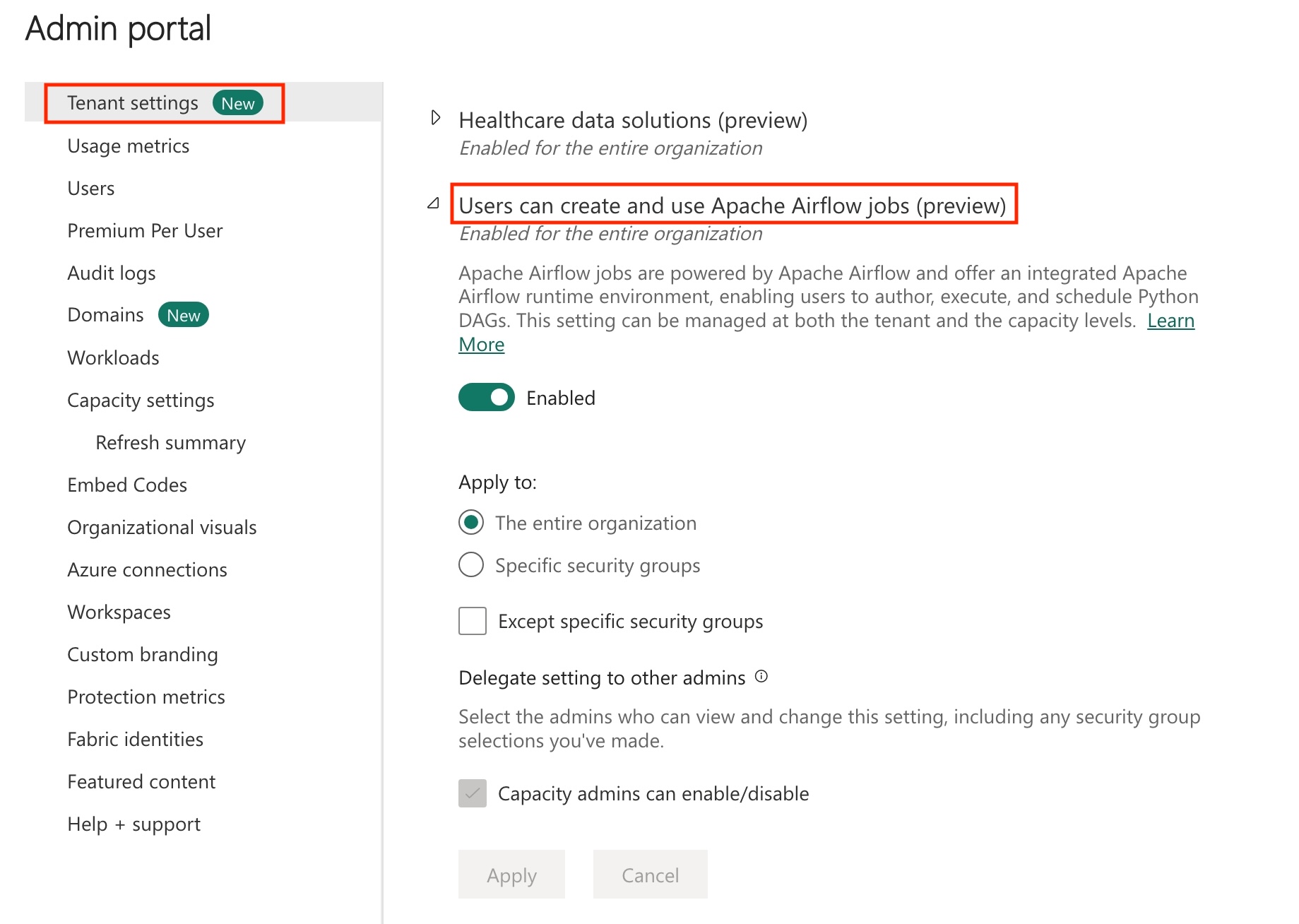
Aktiver Apache Airflow-jobb i leieren.
Merk
Siden Apache Airflow-jobben er i forhåndsvisningstilstand, må du aktivere den gjennom leieradministratoren. Hvis du allerede ser Apache Airflow Job, kan det hende at leieradministratoren allerede har aktivert den.
Gå til administrasjonsportalen –> Leierinnstillinger –> Under Microsoft Fabric –> Utvid inndelingen «Brukere kan opprette og bruke Apache Airflow Job (forhåndsvisning)».
Velg Bruk.
Opprett tjenestekontohaveren. Legg til tjenestekontohaveren
Contributorsom i arbeidsområdet der du oppretter datalageret.Hvis du ikke har en, oppretter du et fabric-lager. Inntak av eksempeldataene i lageret ved hjelp av datasamlebånd. For denne opplæringen bruker vi NYC Taxi-Green-eksemplet .

Transformere dataene som er lagret i Fabric-lageret ved hjelp av dbt
Denne delen veileder deg gjennom følgende trinn:
- Angi kravene.
- Opprett et dbt-prosjekt i stoffadministrert lagring levert av Apache Airflow-jobben..
- Opprett en Apache Airflow DAG for å organisere dbt-jobber
Angi kravene
Opprett en fil requirements.txt i dags mappen. Legg til følgende pakker som Apache Airflow-krav.
astronom-kosmos: Denne pakken brukes til å kjøre dbt kjerneprosjekter som Apache Airflow dags og Oppgavegrupper.
dbt-stoff: Denne pakken brukes til å opprette dbt-prosjekt, som deretter kan distribueres til et Fabric Data Warehouse
astronomer-cosmos==1.0.3 dbt-fabric==1.5.0
Opprett et dbt-prosjekt i stoffadministrert lagring levert av Apache Airflow-jobben.
I denne delen oppretter vi et eksempelprosjekt i Apache Airflow Job for datasettet
nyc_taxi_greenmed følgende katalogstruktur.dags |-- my_cosmos_dag.py |-- nyc_taxi_green | |-- profiles.yml | |-- dbt_project.yml | |-- models | | |-- nyc_trip_count.sql | |-- targetOpprett mappen som er navngitt
nyc_taxi_greenidagsmappen medprofiles.ymlfilen. Denne mappen inneholder alle filene som kreves for dbt-prosjektet.
Kopier innholdet nedenfor til
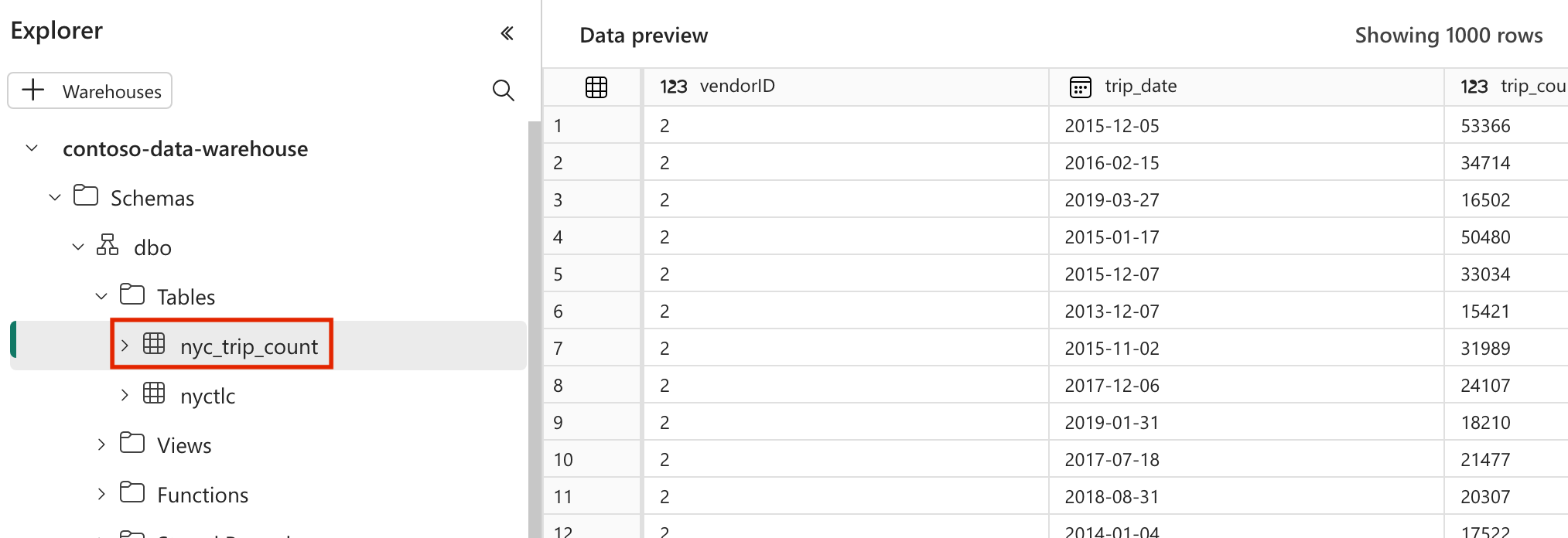
profiles.yml. Denne konfigurasjonsfilen inneholder detaljer for databasetilkobling og profiler som brukes av dbt. Oppdater plassholderverdiene, og lagre filen.config: partial_parse: true nyc_taxi_green: target: fabric-dev outputs: fabric-dev: type: fabric driver: "ODBC Driver 18 for SQL Server" server: <sql connection string of your data warehouse> port: 1433 database: "<name of the database>" schema: dbo threads: 4 authentication: ServicePrincipal tenant_id: <Tenant ID of your service principal> client_id: <Client ID of your service principal> client_secret: <Client Secret of your service principal>dbt_project.ymlOpprett filen, og kopier innholdet nedenfor. Denne filen angir konfigurasjonen på prosjektnivå.name: "nyc_taxi_green" config-version: 2 version: "0.1" profile: "nyc_taxi_green" model-paths: ["models"] seed-paths: ["seeds"] test-paths: ["tests"] analysis-paths: ["analysis"] macro-paths: ["macros"] target-path: "target" clean-targets: - "target" - "dbt_modules" - "logs" require-dbt-version: [">=1.0.0", "<2.0.0"] models: nyc_taxi_green: materialized: tablemodelsOpprett mappen inyc_taxi_greenmappen. I denne opplæringen oppretter vi eksempelmodellen i filen med navnetnyc_trip_count.sqlsom oppretter tabellen som viser antall turer per dag per leverandør. Kopier følgende innhold i filen.with new_york_taxis as ( select * from nyctlc ), final as ( SELECT vendorID, CAST(lpepPickupDatetime AS DATE) AS trip_date, COUNT(*) AS trip_count FROM [contoso-data-warehouse].[dbo].[nyctlc] GROUP BY vendorID, CAST(lpepPickupDatetime AS DATE) ORDER BY vendorID, trip_date; ) select * from final


Opprett en Apache Airflow DAG for å organisere dbt-jobber
Opprett filen som er navngitt
my_cosmos_dag.pyidagsmappen, og lim inn følgende innhold i den.import os from pathlib import Path from datetime import datetime from cosmos import DbtDag, ProjectConfig, ProfileConfig, ExecutionConfig DEFAULT_DBT_ROOT_PATH = Path(__file__).parent.parent / "dags" / "nyc_taxi_green" DBT_ROOT_PATH = Path(os.getenv("DBT_ROOT_PATH", DEFAULT_DBT_ROOT_PATH)) profile_config = ProfileConfig( profile_name="nyc_taxi_green", target_name="fabric-dev", profiles_yml_filepath=DBT_ROOT_PATH / "profiles.yml", ) dbt_fabric_dag = DbtDag( project_config=ProjectConfig(DBT_ROOT_PATH,), operator_args={"install_deps": True}, profile_config=profile_config, schedule_interval="@daily", start_date=datetime(2023, 9, 10), catchup=False, dag_id="dbt_fabric_dag", )
Kjør dag
Kjør DAG i Apache Airflow Job.
Hvis du vil se dag lastet inn i Apache Airflow-brukergrensesnittet, klikker du på
Monitor in Apache Airflow.



Validere dataene dine
- Etter en vellykket kjøring, for å validere dataene, kan du se den nye tabellen med navnet «nyc_trip_count.sql» opprettet i Fabric-datalageret.