Apache Spark-rådgiver for sanntidsråd om notatblokker
Apache Spark-rådgiveren analyserer kommandoer og kode som kjøres av Apache Spark, og viser råd i sanntid for notatblokkkjøringer. Apache Spark-rådgiveren har innebygde mønstre for å hjelpe brukerne med å unngå vanlige feil. Den gir anbefalinger for kodeoptimalisering, utfører feilanalyse og finner årsaken til feil.
Innebygde råd
Spark-rådgiveren, et verktøy integrert med Impulse, gir innebygde mønstre for å oppdage og løse problemer i Apache Spark-programmer. Denne artikkelen forklarer noen av mønstrene som er inkludert i verktøyet.
Du kan åpne ruten Nylige kjøringer basert på hvilken type råd du trenger.
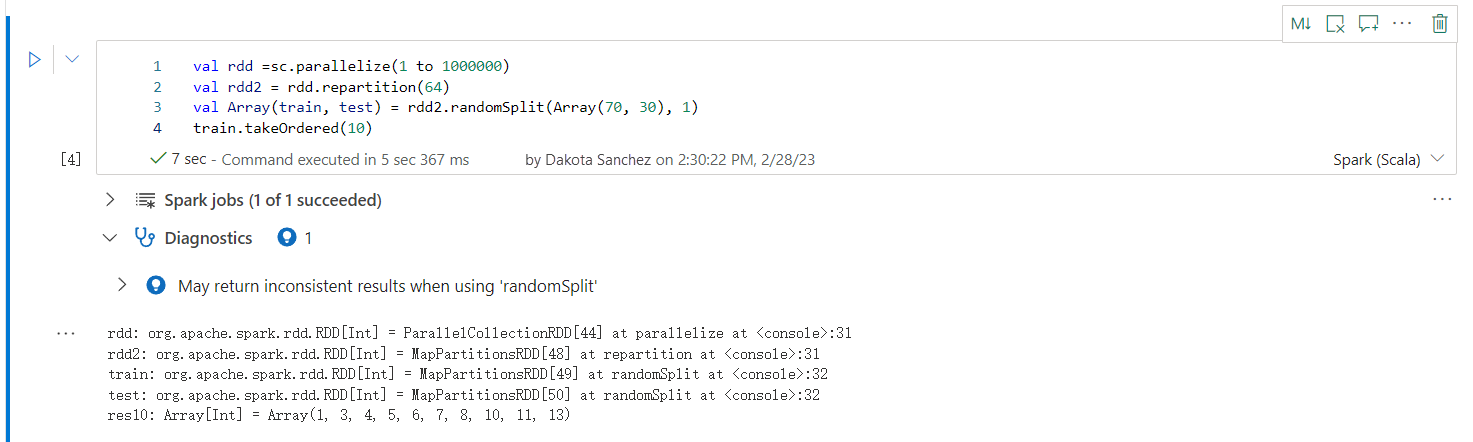
Kan returnere inkonsekvente resultater når du bruker randomSplit
Inkonsekvente eller unøyaktige resultater kan returneres når du arbeider med randomSplit-metoden. Bruk Apache Spark (RDD)-hurtigbufring før du bruker randomSplit()-metoden.
Method randomSplit() tilsvarer å utføre eksempel() på datarammen flere ganger. Der hvert eksempel refetches, partisjoner, og sorterer datarammen i partisjoner. Datadistribusjonen på tvers av partisjoner og sorteringsrekkefølge er viktig for både randomSplit() og sample(). Hvis en av dem endres ved datarefetch, kan det være duplikater eller manglende verdier på tvers av delinger. Og det samme utvalget som bruker samme frø, kan gi forskjellige resultater.
Disse inkonsekvensene kan ikke skje på hver kjøring, men hvis du vil eliminere dem fullstendig, bufrer du datarammen, partisjonerer på nytt på en kolonne eller bruker mengdefunksjoner, for eksempel groupBy.
Tabell-/visningsnavn er allerede i bruk
Det finnes allerede en visning med samme navn som den opprettede tabellen, eller det finnes allerede en tabell med samme navn som den opprettede visningen. Når dette navnet brukes i spørringer eller programmer, returneres bare visningen uansett hvilken som ble opprettet først. Hvis du vil unngå konflikter, kan du gi nytt navn til enten tabellen eller visningen.
Gjenkjenner ikke et tips
spark.sql("SELECT /*+ unknownHint */ * FROM t1")
Finner ikke et angitt relasjonsnavn
Finner ikke relasjonen(e) som er angitt i tipset. Kontroller at relasjonen(e) er stavet riktig og tilgjengelig innenfor hintomfanget.
spark.sql("SELECT /*+ BROADCAST(unknownTable) */ * FROM t1 INNER JOIN t2 ON t1.str = t2.str")
Et tips i spørringen hindrer at et annet tips blir brukt
Den valgte spørringen inneholder et tips som hindrer at et annet tips blir brukt.
spark.sql("SELECT /*+ BROADCAST(t1), MERGE(t1, t2) */ * FROM t1 INNER JOIN t2 ON t1.str = t2.str")
Aktiver spark.advise.divisionExprConvertRule.enable for å redusere overføring av avrundingsfeil
Denne spørringen inneholder uttrykket med dobbel type. Vi anbefaler at du aktiverer konfigurasjonen spark.advise.divisionExprConvertRule.enable, som kan bidra til å redusere divisjonsuttrykkene og redusere avrundingsfeiloverføringen.
"t.a/t.b/t.c" convert into "t.a/(t.b * t.c)"
Aktiver spark.advise.nonEqJoinConvertRule.enable for å forbedre spørringsytelsen
Denne spørringen inneholder tidkrevende sammenføyning på grunn av Or-betingelse i spørringen. Vi anbefaler at du aktiverer konfigurasjonen spark.advise.nonEqJoinConvertRule.enable, som kan bidra til å konvertere sammenføyningen utløst av "Or"-betingelsen til SMJ eller BHJ for å akselerere denne spørringen.
Brukeropplevelse
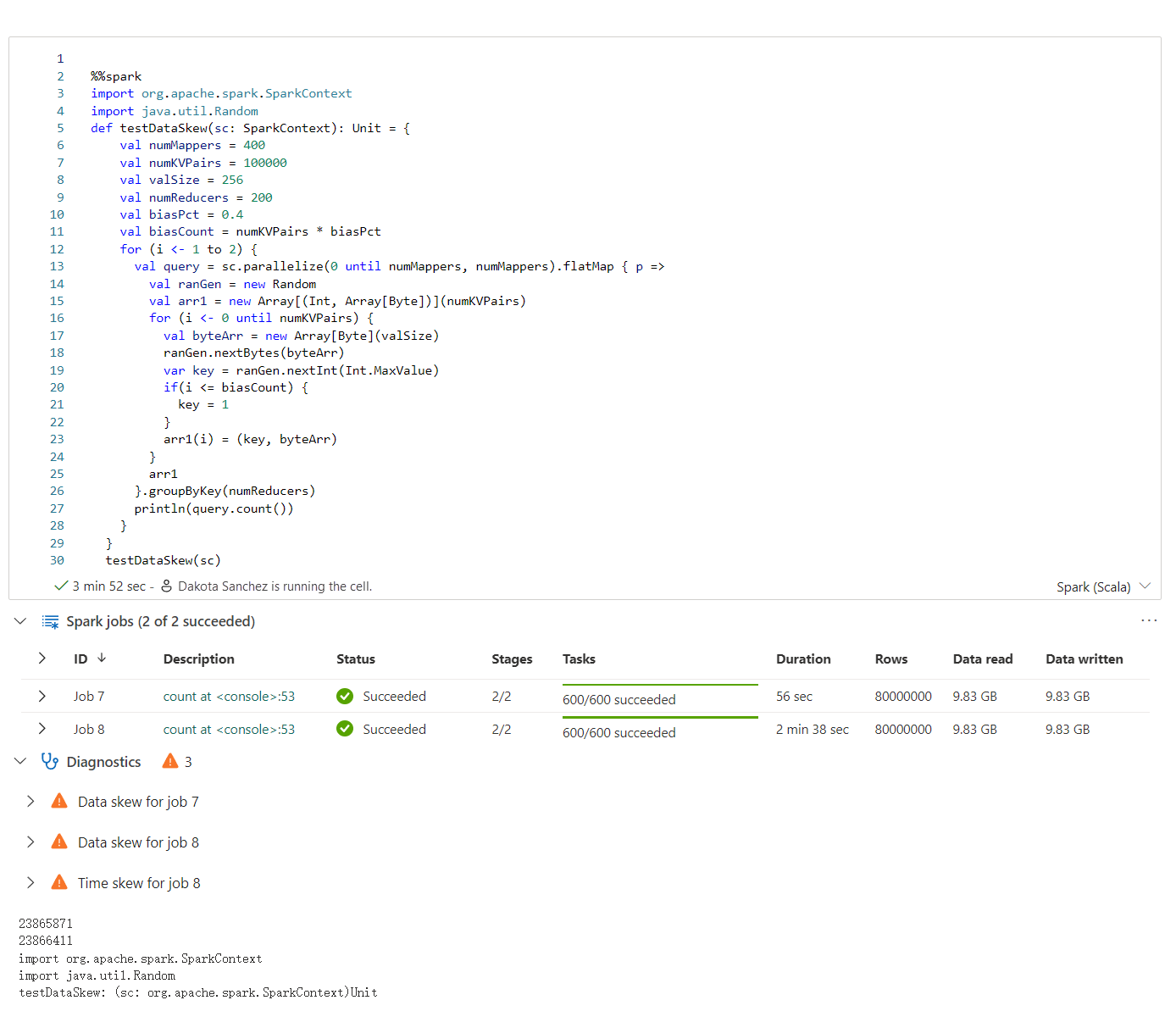
Apache Spark-rådgiveren viser råd, inkludert informasjon, advarsler og feil, ved notatblokkcelleutdata i sanntid.
Info
Advarsel
Feil
Spark Advisor-innstilling
Spark Advisor-innstillingen lar deg velge om du vil vise eller skjule bestemte typer Spark-råd etter dine behov. I tillegg har du fleksibilitet til å aktivere eller deaktivere Spark Advisor for notatblokkene i et arbeidsområde, basert på innstillingene dine.
Du kan få tilgang til Innstillingene for Spark Advisor på Fabric Notebook-nivå for å dra nytte av fordelene og sikre en produktiv opplevelse for redigering av notatblokker.