Planlegge og kjøre en Apache Spark-jobbdefinisjon
Lær hvordan du kjører en jobbdefinisjon for Microsoft Fabric Apache Spark og finner jobbdefinisjonsstatusen og detaljene.
Forutsetning
Før du kommer i gang, må du:
- Opprett en Microsoft Fabric-leierkonto med et aktivt abonnement. Opprett en konto gratis.
- Forstå Spark-jobbdefinisjonen: Se Hva er en Apache Spark-jobbdefinisjon?.
- Opprett en Spark-jobbdefinisjon: Se Hvordan du oppretter en Apache Spark-jobbdefinisjon i Fabric.
Slik kjører du en Spark-jobbdefinisjon
Det finnes to måter du kan kjøre en Spark-jobbdefinisjon på:
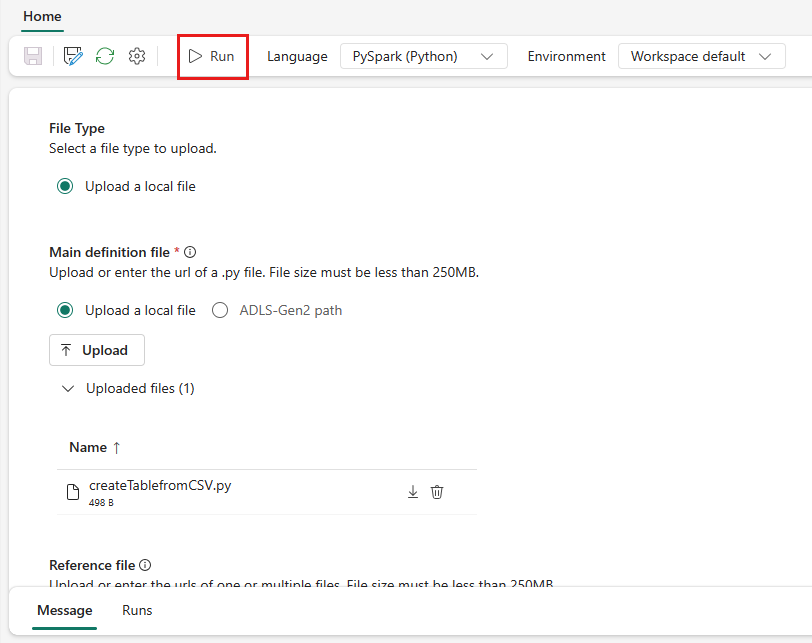
Kjør en Spark-jobbdefinisjon manuelt ved å velge Kjør fra Spark-jobbdefinisjonselementet i jobblisten.
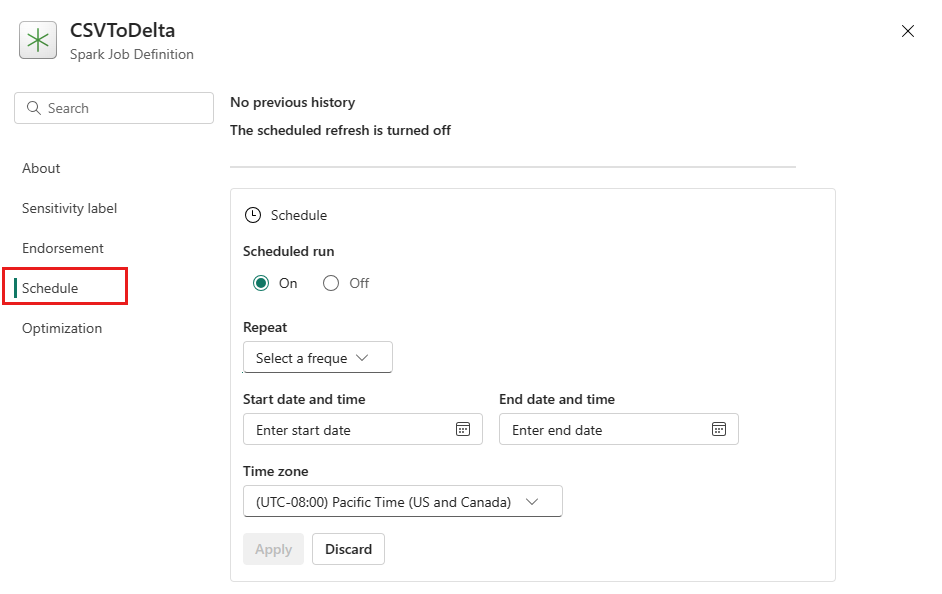
Planlegg en Spark-jobbdefinisjon ved å sette opp en tidsplanplan på fanen Innstillinger. Velg Innstillinger på verktøylinjen, og velg deretter Planlegg.
Viktig
Hvis du vil kjøre, må en Spark-jobbdefinisjon ha en hoveddefinisjonsfil og en standard lakehouse-kontekst.
Tips
For en manuell kjøring brukes kontoen til den påloggede brukeren til å sende inn jobben. For en kjøring som utløses av en tidsplan, brukes kontoen til brukeren som opprettet tidsplanplanen, til å sende inn jobben.
Tre til fem sekunder etter at du har sendt inn kjøringen, vises en ny rad under Kjør-fanen. Raden viser detaljer om den nye kjøringen. Status-kolonnen viser statusen for jobben nær sanntid, og Kolonnen Kjør type viser om jobben er manuell eller planlagt.
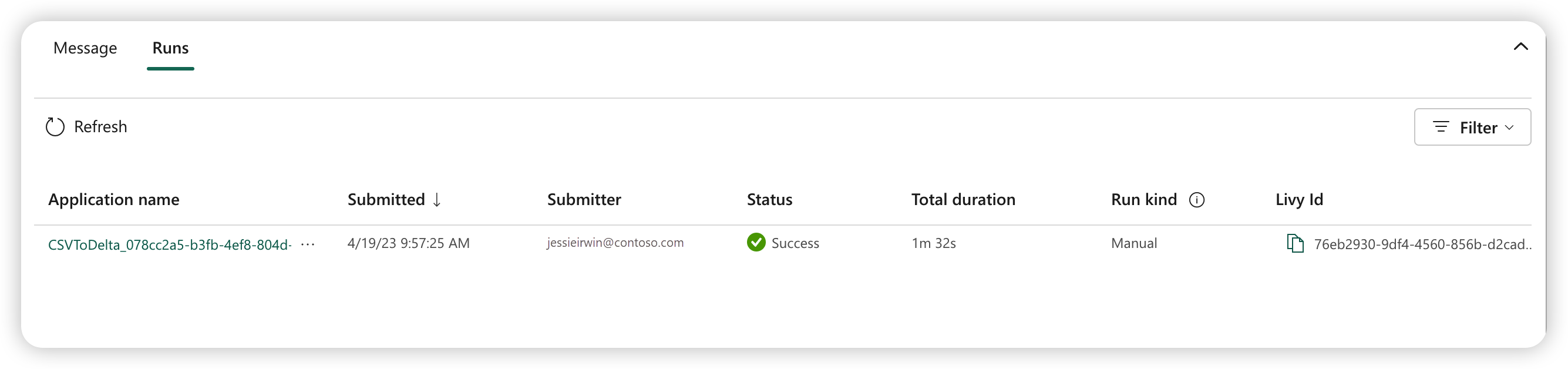
Hvis du vil ha mer informasjon om hvordan du overvåker en jobb, kan du se Overvåke jobbdefinisjonen for Apache Spark.
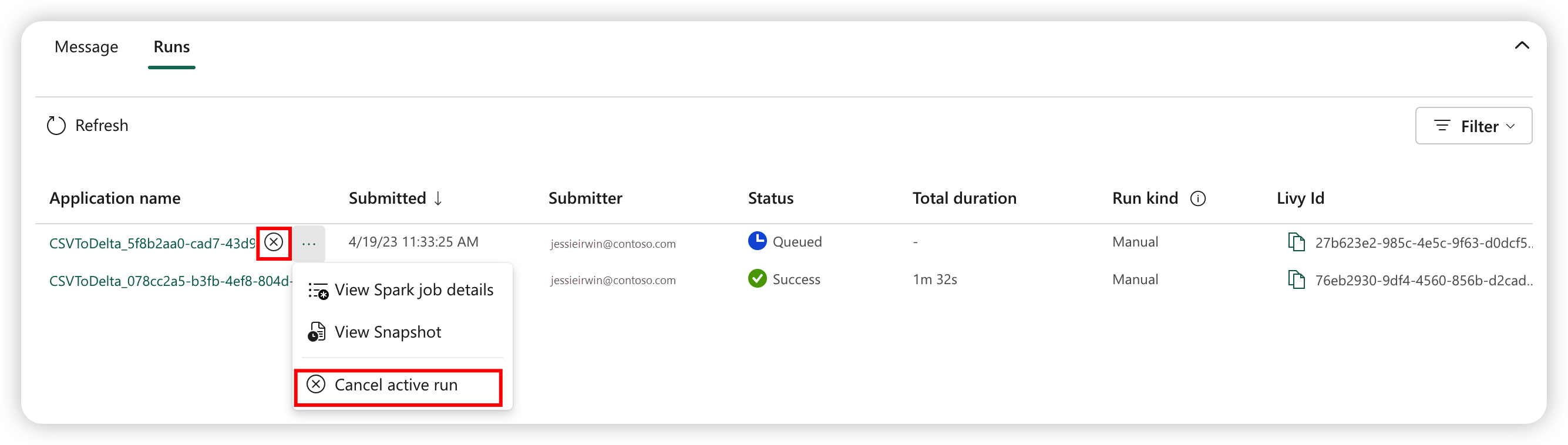
Slik avbryter du en kjørejobb
Når jobben er sendt, kan du avbryte jobben ved å velge Avbryt aktiv kjøring fra Spark-jobbdefinisjonselementet i jobblisten.
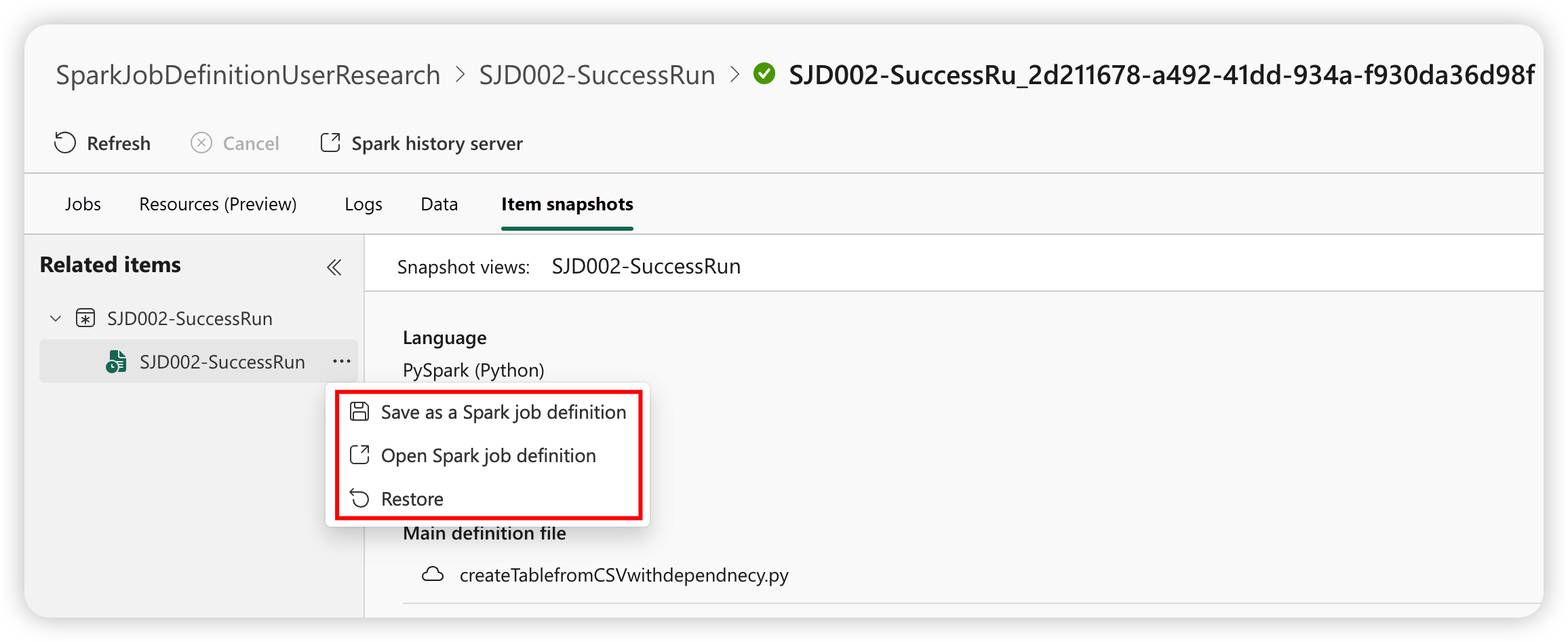
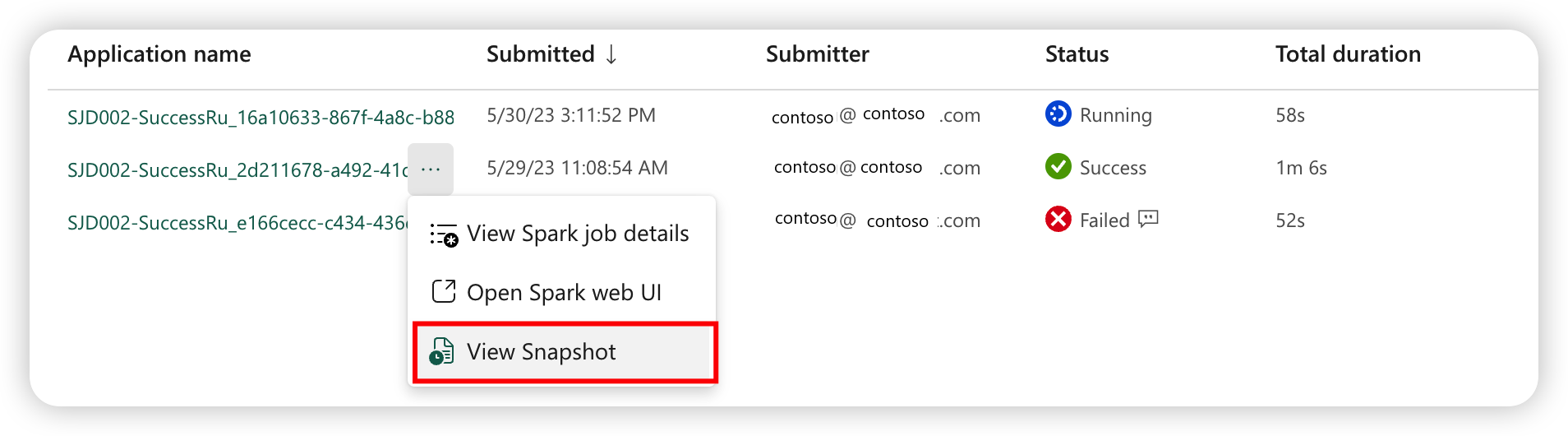
Øyeblikksbilde av spark-jobbdefinisjon
Spark-jobbdefinisjonen lagrer sin nyeste tilstand. Hvis du vil vise øyeblikksbildet av loggkjøringen, velger du Vis øyeblikksbilde fra spark-jobbdefinisjonselementet i jobblisten. Øyeblikksbildet viser tilstanden til jobbdefinisjonen når jobben sendes inn, inkludert hoveddefinisjonsfilen, referansefilen, kommandolinjeargumentene, det refererte lakehouse- og Spark-egenskapene.
Fra et øyeblikksbilde kan du utføre tre handlinger:
- Lagre som en Spark-jobbdefinisjon: Lagre øyeblikksbildet som en ny Spark-jobbdefinisjon.
- Åpne Spark-jobbdefinisjon: Åpne gjeldende Spark-jobbdefinisjon.
- Gjenopprett: Gjenopprett jobbdefinisjonen med øyeblikksbildet. Jobbdefinisjonen gjenopprettes til tilstanden da jobben ble sendt inn.