Opprinnelig utførelsesmotor for Fabric Spark
Den opprinnelige utførelsesmotoren er en banebrytende forbedring for Apache Spark-jobbkjøringer i Microsoft Fabric. Denne vektoriserte motoren optimaliserer ytelsen og effektiviteten til Spark-spørringene dine ved å kjøre dem direkte på infrastrukturen i lakehouse. Motorens sømløse integrasjon betyr at den ikke krever kodeendringer og unngår leverandørlåsing. Den støtter Apache Spark API-er og er kompatibel med Runtime 1.3 (Apache Spark 3.5) og fungerer med både Parquet- og Delta-formater. Uavhengig av dataenes plassering i OneLake, eller hvis du får tilgang til data via snarveier, maksimerer den opprinnelige kjøringsmotoren effektiviteten og ytelsen.
Den opprinnelige kjøringsmotoren øker spørringsytelsen betydelig, samtidig som driftskostnadene minimeres. Det gir en bemerkelsesverdig hastighetsforbedring, og oppnår opptil fire ganger raskere ytelse sammenlignet med tradisjonell OSS (åpen kildekode-programvare) Spark, som validert av TPC-DS 1 TB benchmark. Motoren er flink til å administrere en rekke databehandlingsscenarioer, alt fra rutinemessig datainntak, satsvise jobber og ETL-oppgaver (trekk ut, transformer, last inn) til komplekse datavitenskapsanalyser og responsive interaktive spørringer. Brukere drar nytte av akselerert behandlingstid, økt gjennomstrømming og optimalisert ressursutnyttelse.
Den opprinnelige kjøringsmotoren er basert på to viktige OSS-komponenter: Velox, et C++ databaseakselerasjonsbibliotek introdusert av Meta, og Apache Gluten (inkubating), et mellomlag som er ansvarlig for å avlaste JVM-baserte SQL-motorers utførelse til opprinnelige motorer introdusert av Intel.
Merk
Den opprinnelige kjøringsmotoren er for øyeblikket i offentlig forhåndsvisning. Hvis du vil ha mer informasjon, kan du se gjeldende begrensninger. Vi oppfordrer deg til å aktivere den opprinnelige kjøringsmotoren på arbeidsbelastningene dine uten ekstra kostnader. Du vil dra nytte av raskere jobbkjøring uten å betale mer - effektivt betaler du mindre for det samme arbeidet.
Når du skal bruke den opprinnelige kjøringsmotoren
Den opprinnelige kjøringsmotoren tilbyr en løsning for å kjøre spørringer på datasett i stor skala. den optimaliserer ytelsen ved hjelp av de opprinnelige egenskapene til underliggende datakilder og minimerer overhead som vanligvis er knyttet til databevegelse og serialisering i tradisjonelle Spark-miljøer. Motoren støtter ulike operatorer og datatyper, inkludert hash-aggregat for beregnet verdi, kringkast nestet løkkekobling (BNLJ) og nøyaktige tidsstempelformater. Hvis du imidlertid vil dra nytte av motorens egenskaper fullt ut, bør du vurdere de optimale brukstilfellene:
- Motoren er effektiv når du arbeider med data i Parquet- og Delta-formater, som den kan behandle opprinnelig og effektivt.
- Spørringer som involverer intrikate transformasjoner og aggregasjoner, drar betydelig nytte av den kolonnebaserte behandlings- og vektoriseringsfunksjonen til motoren.
- Ytelsesforbedring er mest bemerkelsesverdig i scenarioer der spørringene ikke utløser tilbakefallsmekanismen ved å unngå funksjoner eller uttrykk som ikke støttes.
- Motoren er godt egnet for spørringer som er beregningskrevende, i stedet for enkel eller I/O-bundet.
Hvis du vil ha informasjon om operatorene og funksjonene som støttes av den opprinnelige kjøringsmotoren, kan du se Apache Gluten-dokumentasjon.
Aktiver den opprinnelige kjøringsmotoren
Hvis du vil bruke de fullstendige funksjonene til den opprinnelige kjøringsmotoren i forhåndsvisningsfasen, er det nødvendig med bestemte konfigurasjoner. Følgende fremgangsmåter viser hvordan du aktiverer denne funksjonen for notatblokker, Spark-jobbdefinisjoner og hele miljøer.
Viktig
Den opprinnelige utførelsesmotoren støtter den nyeste GA runtime-versjonen, som er Runtime 1.3 (Apache Spark 3.5, Delta Lake 3.2). Med utgivelsen av den opprinnelige kjøringsmotoren i Runtime 1.3 har støtte for den forrige versjonen – Runtime 1.2 (Apache Spark 3.4, Delta Lake 2.4)– blitt fjernet. Vi oppfordrer alle kunder til å oppgradere til den nyeste Runtime 1.3. Hvis du bruker den opprinnelige kjøringsmotoren på Runtime 1.2, deaktiveres opprinnelig akselerasjon snart.
Aktiver på miljønivå
Aktiver den opprinnelige kjøringsmotoren på tvers av alle jobber og notatblokker som er knyttet til miljøet, for å sikre ensartede ytelsesforbedringer:
Gå til miljøinnstillingene.
Gå til Spark-databehandling.
Gå til Akselerasjon-fanen .
Merk av for Aktiver opprinnelig kjøringsmotor.
Lagre og publiser endringene.
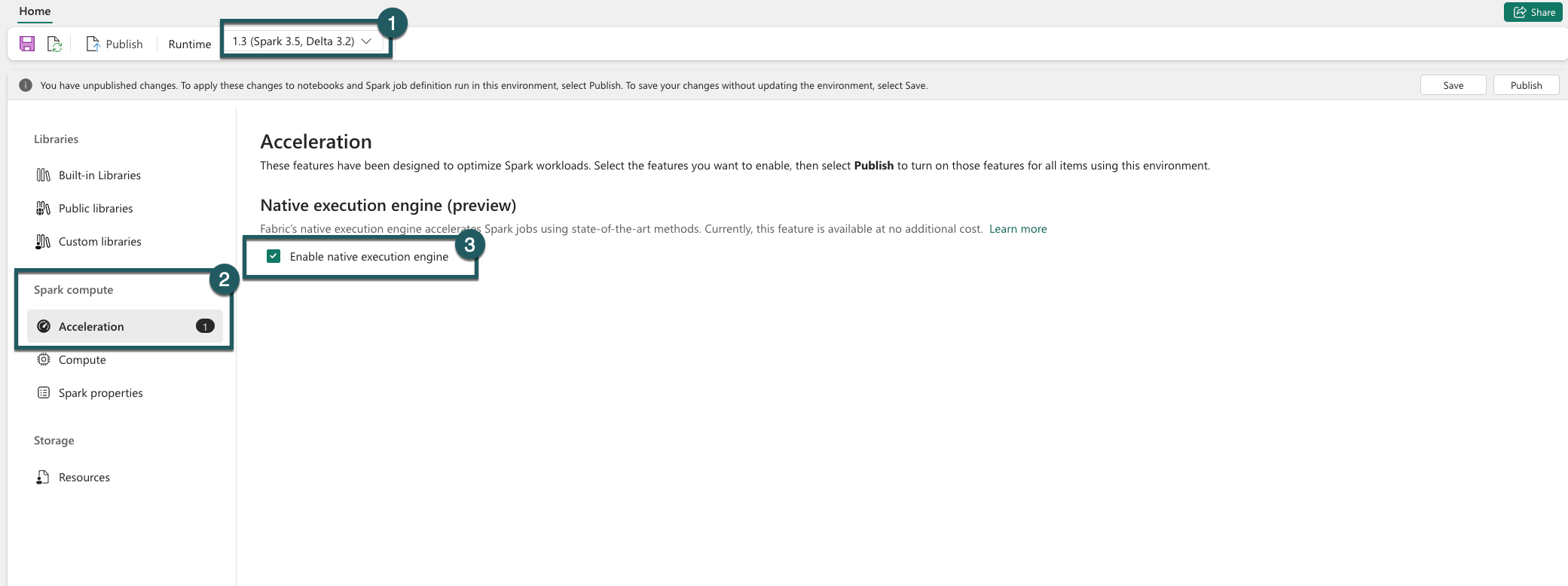

Når den er aktivert på miljønivå, arver alle etterfølgende jobber og notatblokker innstillingen. Denne arven sikrer at eventuelle nye økter eller ressurser som opprettes i miljøet, automatisk drar nytte av de forbedrede utførelsesfunksjonene.
Viktig
Tidligere ble den opprinnelige kjøringsmotoren aktivert via Spark-innstillinger i miljøkonfigurasjonen. Med vår nyeste oppdatering (utrulling pågår), har vi forenklet dette ved å introdusere en veksleknapp i Akselerasjon-fanen i miljøinnstillingene. Aktiver den opprinnelige kjøringsmotoren på nytt ved hjelp av den nye veksleknappen – hvis du vil fortsette å bruke den opprinnelige kjøringsmotoren, går du til Akselerasjon-fanen i miljøinnstillingene og aktiverer den gjennom veksleknappen. Den nye veksleinnstillingen i brukergrensesnittet prioriteres nå over eventuelle tidligere spark-egenskapskonfigurasjoner. Hvis du tidligere har aktivert den opprinnelige kjøringsmotoren via Spark-innstillinger, deaktiveres den til den aktiveres på nytt via veksleknappen for brukergrensesnittet.
Aktiver for en notatblokk eller spark-jobbdefinisjon
Hvis du vil aktivere den opprinnelige kjøringsmotoren for én enkelt notatblokk eller spark-jobbdefinisjon, må du innlemme de nødvendige konfigurasjonene i begynnelsen av kjøringsskriptet:
%%configure
{
"conf": {
"spark.native.enabled": "true",
}
}
Sett inn de nødvendige konfigurasjonskommandoene i den første cellen for notatblokker. For Spark-jobbdefinisjoner kan du inkludere konfigurasjonene i frontlinjen i Spark-jobbdefinisjonen. Den opprinnelige kjøringsmotoren er integrert med live-bassenger, så når du aktiverer funksjonen, trer den i kraft umiddelbart uten å kreve at du starter en ny økt.
Viktig
Konfigurasjon av den opprinnelige kjøringsmotoren må gjøres før oppstarten av Spark-økten. Når Spark-økten starter, spark.shuffle.manager blir innstillingen uforanderlig og kan ikke endres. Kontroller at disse konfigurasjonene er angitt i %%configure blokken i notatblokker eller i Spark-øktverktøyet for Spark-jobbdefinisjoner.
Kontroll på spørringsnivå
Mekanismene for å aktivere den opprinnelige kjøringsmotoren på leier-, arbeidsområde- og miljønivå, sømløst integrert med brukergrensesnittet, er under aktiv utvikling. I mellomtiden kan du deaktivere den opprinnelige kjøringsmotoren for bestemte spørringer, spesielt hvis de involverer operatorer som for øyeblikket ikke støttes (se begrensninger). Hvis du vil deaktivere, angir du Spark-konfigurasjonen spark.native.enabled til usann for den bestemte cellen som inneholder spørringen.
%%sql
SET spark.native.enabled=FALSE;

Når du har utført spørringen der den opprinnelige kjøringsmotoren er deaktivert, må du aktivere den på nytt for etterfølgende celler ved å angi spark.native.enabled til sann. Dette trinnet er nødvendig fordi Spark kjører kodeceller sekvensielt.
%%sql
SET spark.native.enabled=TRUE;
Identifiser operasjoner utført av motoren
Det finnes flere metoder for å finne ut om en operatør i Apache Spark-jobben ble behandlet ved hjelp av den opprinnelige kjøringsmotoren.
Spark UI- og Spark-loggserver
Få tilgang til Spark-brukergrensesnittet eller Spark-loggserveren for å finne spørringen du må undersøke. Hvis du vil ha tilgang til Spark Web UI, går du til Spark Job Definition og kjører det. Velg

Se etter eventuelle nodenavn som slutter med suffikset Transformer, *NativeFileScan eller VeloxColumnarToRowExeci spørringsplanen som vises i Spark UI-grensesnittet. Suffikset indikerer at den opprinnelige kjøringsmotoren utførte operasjonen. Noder kan for eksempel være merket som RollUpHashAggregateTransformer, ProjectExecTransformer, BroadcastHashJoinExecTransformer, ShuffledHashJoinExecTransformer eller BroadcastNestedLoopJoinExecTransformer.

DataFrame-forklaring
Alternativt kan du utføre df.explain() kommandoen i notatblokken for å vise utførelsesplanen. Se etter samme Transformer, *NativeFileScan eller VeloxColumnarToRowExec suffikser i utdataene. Denne metoden gir en rask måte å bekrefte om bestemte operasjoner håndteres av den opprinnelige kjøringsmotoren.

Tilbakefallsmekanisme
I noen tilfeller kan det hende at den opprinnelige kjøringsmotoren ikke kan kjøre en spørring på grunn av årsaker som funksjoner som ikke støttes. I disse tilfellene faller operasjonen tilbake til den tradisjonelle Spark-motoren. Denne automatiske tilbakefallsmekanismen sikrer at det ikke er noen avbrudd i arbeidsflyten.


Overvåk spørringer og datarammer utført av motoren
Hvis du vil forstå hvordan den opprinnelige kjøringsmotoren brukes på SQL-spørringer og DataFrame-operasjoner, og for å drille ned til fase- og operatornivåene, kan du se Spark UI og Spark History Server for mer detaljert informasjon om den opprinnelige kjøringen av motoren.
Fanen Opprinnelig kjøringsmotor
Du kan gå til den nye fanen Gluten SQL /DataFrame for å vise informasjon om glutenbygg og kjøring av spørringer. Spørringer-tabellen gir innsikt i antall noder som kjører på den opprinnelige motoren, og de som faller tilbake til JVM for hver spørring.

Spørringskjøringsdiagram
Du kan også velge spørringsbeskrivelsen for visualiseringen av Kjøringsplan for Apache Spark-spørringen. Utføringsdiagrammet gir opprinnelige utførelsesdetaljer på tvers av faser og deres respektive operasjoner. Bakgrunnsfarger skiller ut kjøringsmotorene: grønn representerer den opprinnelige kjøringsmotoren, mens lyseblå angir at operasjonen kjører på standard JVM-motor.

Begrensninger
Selv om den opprinnelige kjøringsmotoren forbedrer ytelsen for Apache Spark-jobber, må du merke deg gjeldende begrensninger.
- Noen Delta-spesifikke operasjoner støttes ikke (ennå fordi vi arbeider aktivt med det), inkludert sammenslåingsoperasjoner, kontrollpunktskanninger og slettingsvektorer.
- Enkelte Spark-funksjoner og -uttrykk er ikke kompatible med den opprinnelige kjøringsmotoren, for eksempel brukerdefinerte funksjoner (UDFs) og
array_containsfunksjonen, samt Spark-strukturert strømming. Bruk av disse inkompatible operasjonene eller funksjonene som en del av et importert bibliotek vil også føre til tilbakefall til Spark-motoren. - Skanninger fra lagringsløsninger som bruker private endepunkter, støttes ikke (ennå fordi vi arbeider aktivt med det).
- Motoren støtter ikke ANSI-modus, så den søker, og når ANSI-modus er aktivert, faller den automatisk tilbake til vanilla Spark.
Når du bruker datofiltre i spørringer, er det viktig å sikre at datatypene på begge sider av sammenligningen samsvarer for å unngå ytelsesproblemer. Datatyper som ikke samsvarer, kan ikke gi økt kjøring av spørringer og kan kreve eksplisitt avstøpning. Sørg alltid for at datatypene på venstre side (LHS) og høyre side (RHS) for en sammenligning er identiske, ettersom typer som ikke samsvarer, ikke alltid blir kastet automatisk. Hvis en typekonflikt ikke er uunngåelig, kan du bruke eksplisitt avstøpning til å samsvare med datatypene, for eksempel CAST(order_date AS DATE) = '2024-05-20'. Spørringer med datatyper som ikke samsvarer, som krever støping, blir ikke akselerert av den opprinnelige kjøringsmotoren, så det er avgjørende å sikre at typekonsekvens er avgjørende for å opprettholde ytelsen. For eksempel, i stedet order_date = '2024-05-20' for hvor order_date er DATETIME og strengen er DATE, eksplisitt kastet order_date for å DATE sikre konsekvente datatyper og forbedre ytelsen.