Bruk Livy-API-en til å sende inn og utføre Livy-satsvise jobber
Merk
Livy API for Fabric Dataingeniør ing er i forhåndsvisning.
Gjelder for:✅ Dataingeniør ing og datavitenskap i Microsoft Fabric
Send inn Spark-satsvise jobber ved hjelp av Livy API for Fabric Dataingeniør ing.
Forutsetning
Fabric Premium - eller Prøvekapasitet med lakehouse.
En ekstern klient som Visual Studio Code med Jupyter Notebooks, PySpark og Microsoft Authentication Library (MSAL) for Python.
Et Microsoft Entra-apptoken kreves for å få tilgang til Fabric Rest-API-en. Registrer et program med Microsofts identitetsplattform.
Noen data i lakehouse, dette eksemplet bruker NYC Taxi &Limousine Commission green_tripdata_2022_08 en parkett fil lastet til lakehouse.
Livy-API-en definerer et enhetlig endepunkt for operasjoner. Erstatt plassholderne {Entra_TenantID}, {Entra_ClientID}, {Fabric_WorkspaceID} og {Fabric_LakehouseID} med de riktige verdiene når du følger eksemplene i denne artikkelen.
Konfigurer Visual Studio Code for Livy API-bunken
Velg Lakehouse-innstillinger i Fabric Lakehouse.

Gå til livy-endepunktinndelingen.
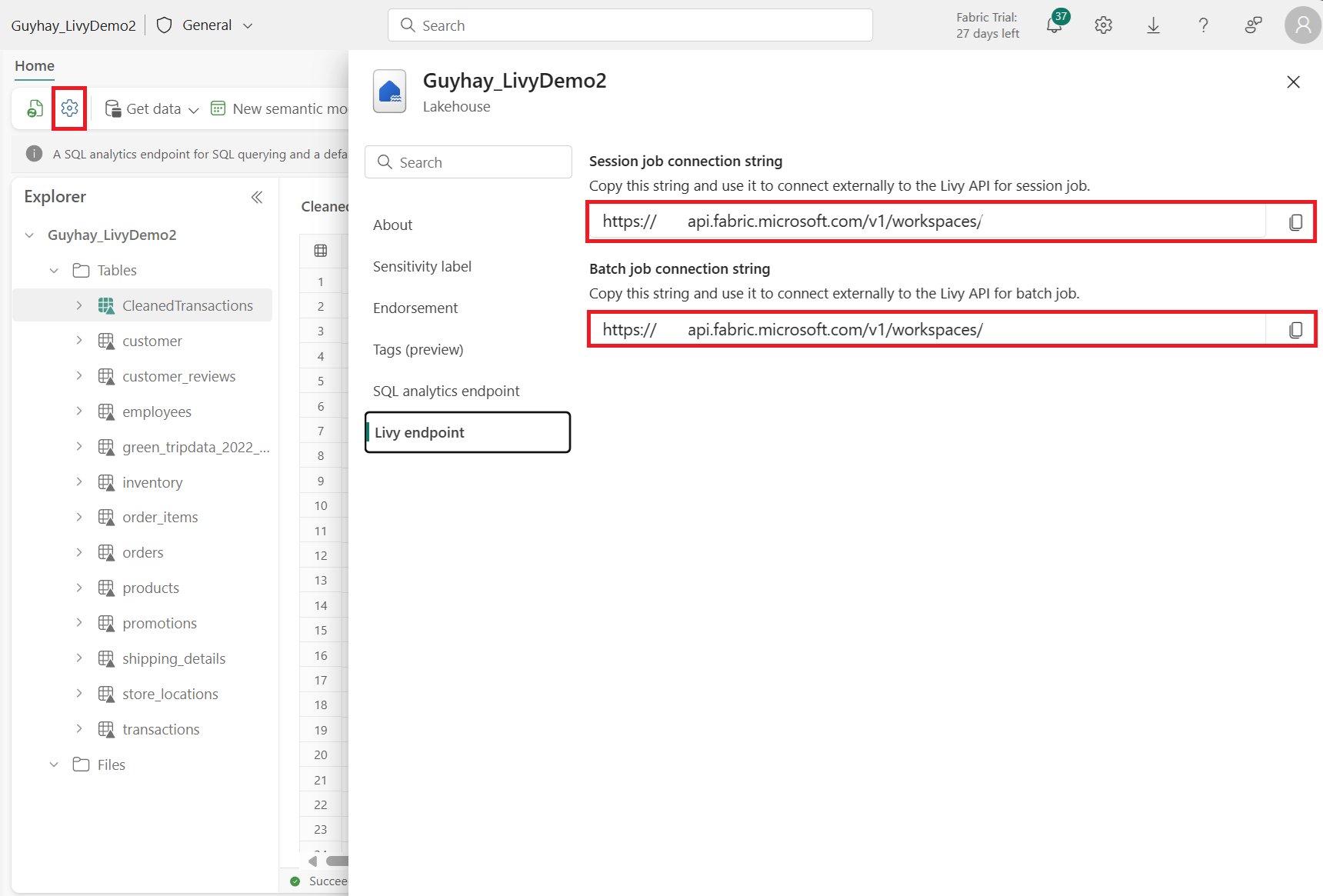
Kopier kjørselen tilkoblingsstreng (andre røde boksen i bildet) til koden.
Gå til administrasjonssenteret for Microsoft Entra, og kopier både program-ID-en (klient)- og katalog-ID-en (leier) til koden.
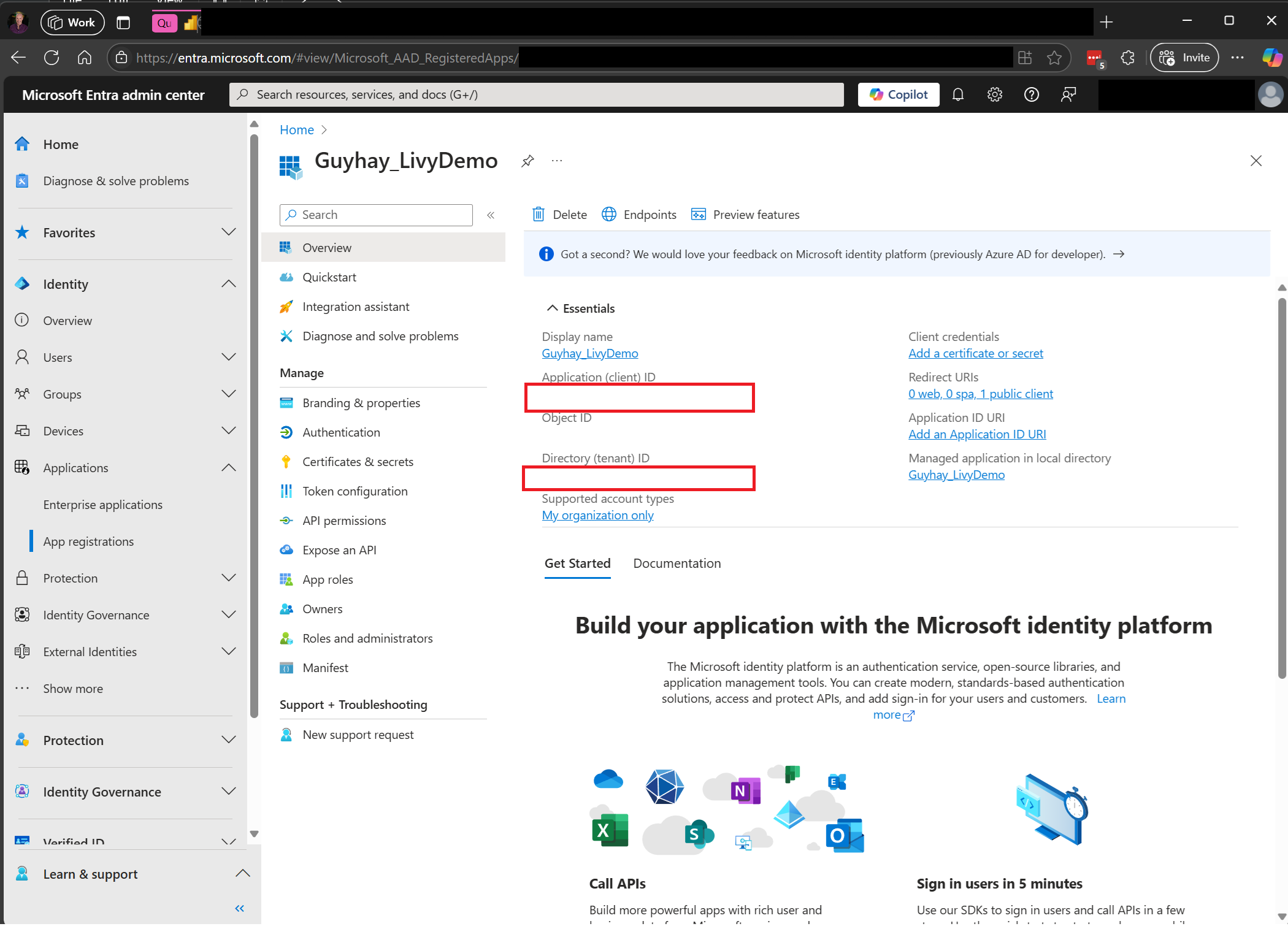



Opprett en Spark nyttelast og last opp til Lakehouse
Opprette en
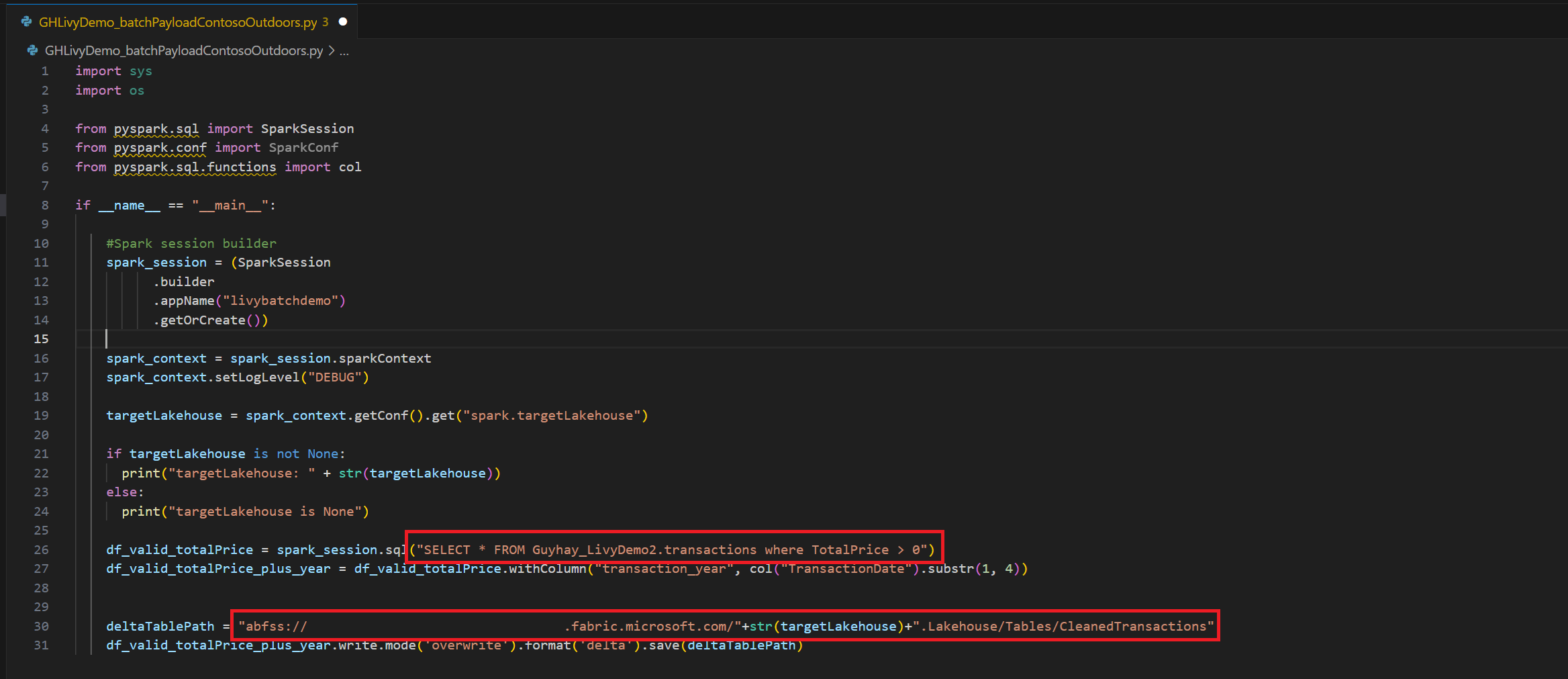
.ipynbnotatblokk i Visual Studio Code og sette inn følgende kodeimport sys import os from pyspark.sql import SparkSession from pyspark.conf import SparkConf from pyspark.sql.functions import col if __name__ == "__main__": #Spark session builder spark_session = (SparkSession .builder .appName("livybatchdemo") .getOrCreate()) spark_context = spark_session.sparkContext spark_context.setLogLevel("DEBUG") targetLakehouse = spark_context.getConf().get("spark.targetLakehouse") if targetLakehouse is not None: print("targetLakehouse: " + str(targetLakehouse)) else: print("targetLakehouse is None") df_valid_totalPrice = spark_session.sql("SELECT * FROM <YourLakeHouseDataTableName>.transactions where TotalPrice > 0") df_valid_totalPrice_plus_year = df_valid_totalPrice.withColumn("transaction_year", col("TransactionDate").substr(1, 4)) deltaTablePath = "abfss:<YourABFSSpath>"+str(targetLakehouse)+".Lakehouse/Tables/CleanedTransactions" df_valid_totalPrice_plus_year.write.mode('overwrite').format('delta').save(deltaTablePath)Lagre Python-filen lokalt. Denne Python-kodenyttelasten inneholder to Spark-setninger som fungerer på data i et Lakehouse og må lastes opp til Lakehouse. Du trenger ABFS-banen til nyttelasten for å referere til i den satsvise jobben i Livy API i Visual Studio Code og navnet på Lakehouse-tabellen i Select SQL-setningen..
Last opp Python-nyttelasten til fildelen av Lakehouse. > Hent data > Last opp filer > klikk i boksen Filer/inndata.
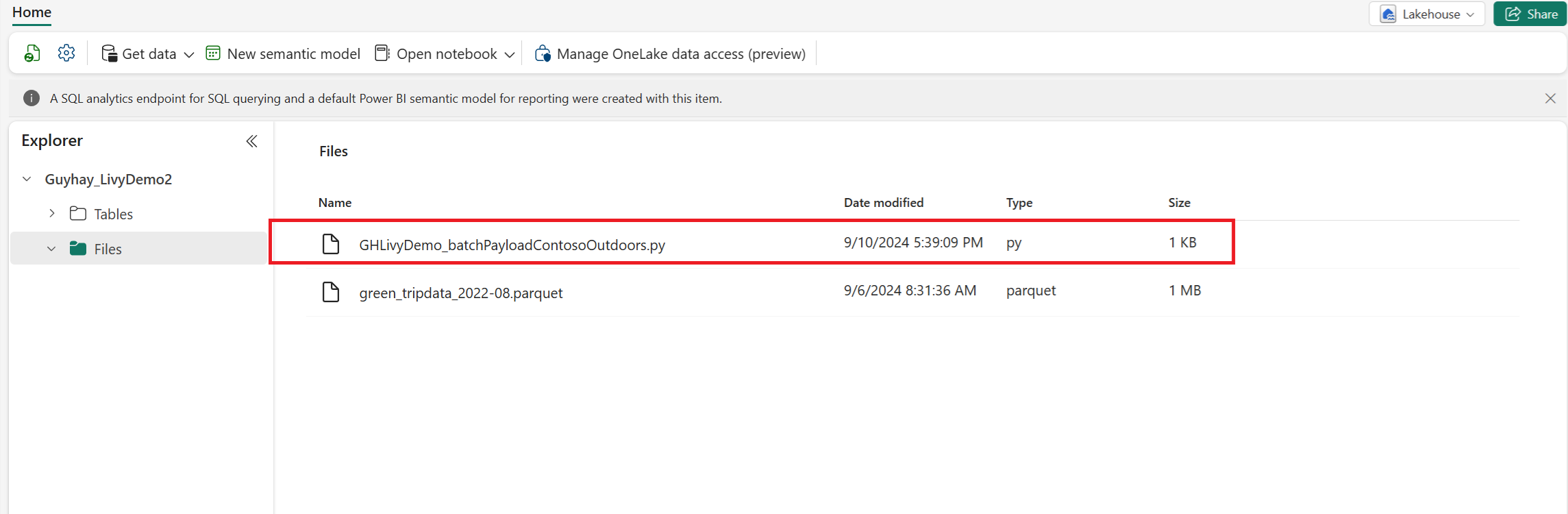
Når filen er i Filer-delen av Lakehouse, klikker du på de tre prikkene til høyre for nyttelastfilnavnet og velger Egenskaper.
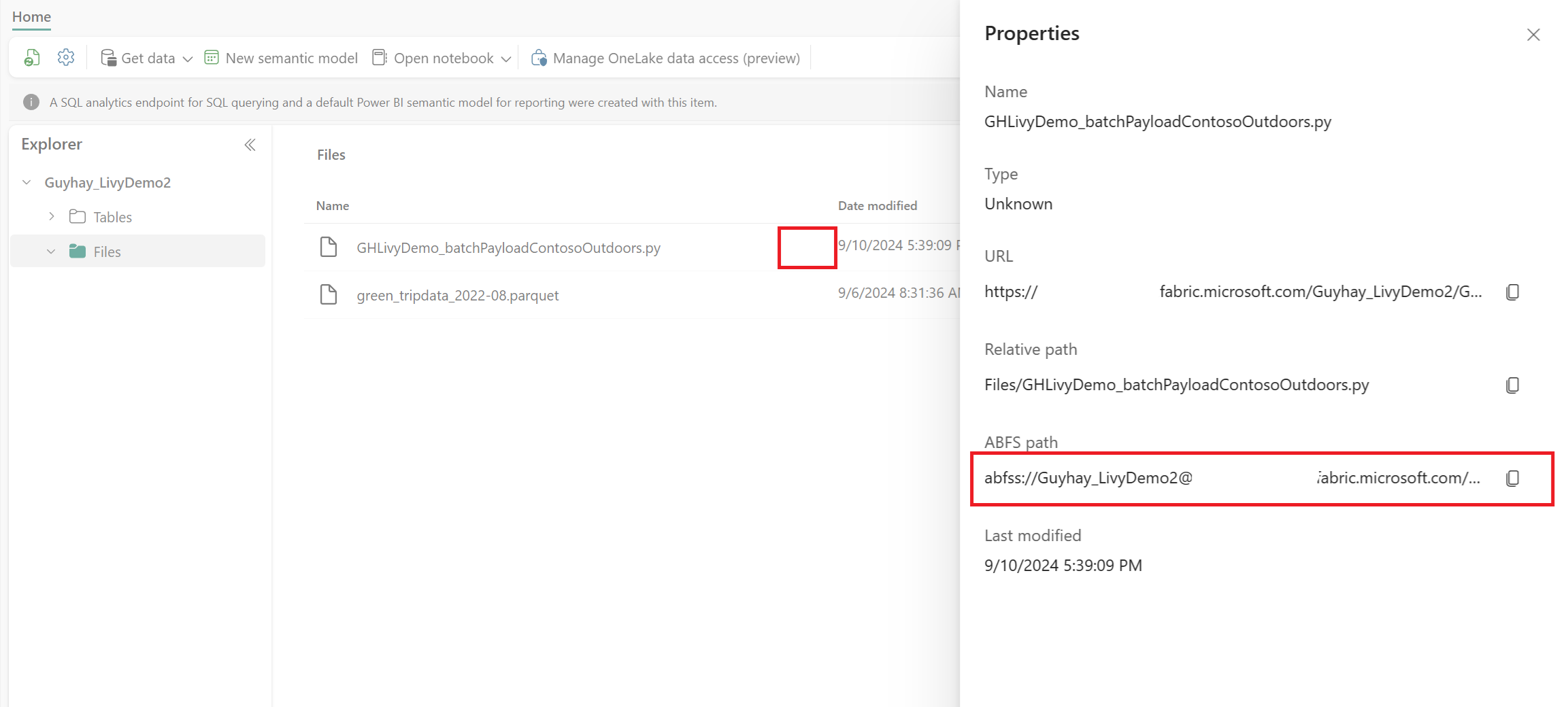
Kopier denne ABFS-banen til notatblokkcellen i trinn 1.



Opprett en livy API Spark-gruppeøkt
Opprett en
.ipynbnotatblokk i Visual Studio Code, og sett inn følgende kode.from msal import PublicClientApplication import requests import time tenant_id = "<Entra_TenantID>" client_id = "<Entra_ClientID>" workspace_id = "<Fabric_WorkspaceID>" lakehouse_id = "<Fabric_LakehouseID>" app = PublicClientApplication( client_id, authority="https://login.microsoftonline.com/43a26159-4e8e-442a-9f9c-cb7a13481d48" ) result = None # If no cached tokens or user interaction needed, acquire tokens interactively if not result: result = app.acquire_token_interactive(scopes=["https://api.fabric.microsoft.com/Lakehouse.Execute.All", "https://api.fabric.microsoft.com/Lakehouse.Read.All", "https://api.fabric.microsoft.com/Item.ReadWrite.All", "https://api.fabric.microsoft.com/Workspace.ReadWrite.All", "https://api.fabric.microsoft.com/Code.AccessStorage.All", "https://api.fabric.microsoft.com/Code.AccessAzureKeyvault.All", "https://api.fabric.microsoft.com/Code.AccessAzureDataExplorer.All", "https://api.fabric.microsoft.com/Code.AccessAzureDataLake.All", "https://api.fabric.microsoft.com/Code.AccessFabric.All"]) # Print the access token (you can use it to call APIs) if "access_token" in result: print(f"Access token: {result['access_token']}") else: print("Authentication failed or no access token obtained.") if "access_token" in result: access_token = result['access_token'] api_base_url_mist='https://api.fabric.microsoft.com/v1' livy_base_url = api_base_url_mist + "/workspaces/"+workspace_id+"/lakehouses/"+lakehouse_id +"/livyApi/versions/2023-12-01/batches" headers = {"Authorization": "Bearer " + access_token}Kjør notatblokkcellen, et popup-vindu skal vises i nettleseren, slik at du kan velge identiteten du vil logge på med.
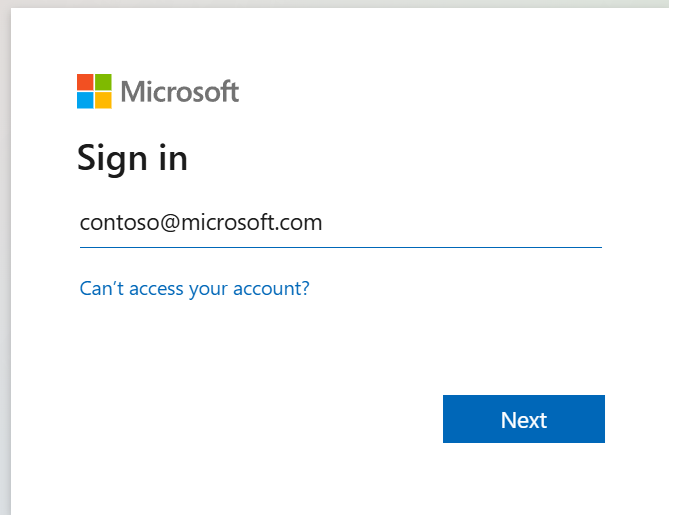
Når du har valgt identiteten du vil logge på med, blir du også bedt om å godkjenne API-tillatelsene for Microsoft Entra-appregistrering.
Lukk nettleservinduet etter at godkjenningen er fullført.

I Visual Studio Code skal du se Microsoft Entra-tokenet som returneres.
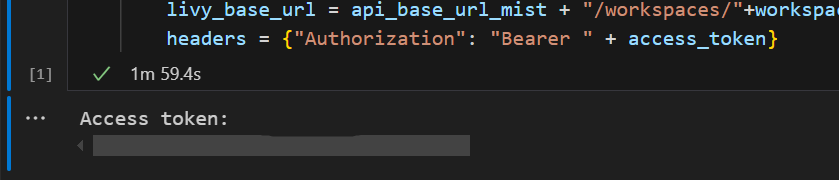
Legg til en annen notatblokkcelle, og sett inn denne koden.
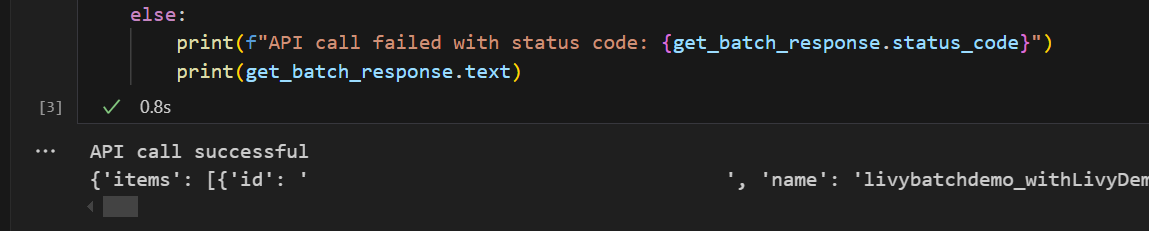
# call get batch API get_livy_get_batch = livy_base_url get_batch_response = requests.get(get_livy_get_batch, headers=headers) if get_batch_response.status_code == 200: print("API call successful") print(get_batch_response.json()) else: print(f"API call failed with status code: {get_batch_response.status_code}") print(get_batch_response.text)Kjør notatblokkcellen, og du skal se to linjer som skrives ut når livy-jobben opprettes.





Send inn en spark.sql-setning ved hjelp av livy-API-gruppeøkten
Legg til en annen notatblokkcelle, og sett inn denne koden.
# submit payload to existing batch session print('Submit a spark job via the livy batch API to ') newlakehouseName = "YourNewLakehouseName" create_lakehouse = api_base_url_mist + "/workspaces/" + workspace_id + "/items" create_lakehouse_payload = { "displayName": newlakehouseName, "type": 'Lakehouse' } create_lakehouse_response = requests.post(create_lakehouse, headers=headers, json=create_lakehouse_payload) print(create_lakehouse_response.json()) payload_data = { "name":"livybatchdemo_with"+ newlakehouseName, "file":"abfss://YourABFSPathToYourPayload.py", "conf": { "spark.targetLakehouse": "Fabric_LakehouseID" } } get_batch_response = requests.post(get_livy_get_batch, headers=headers, json=payload_data) print("The Livy batch job submitted successful") print(get_batch_response.json())Kjør notatblokkcellen, du bør se flere linjer som skrives ut når Livy Batch-jobben opprettes og kjøres.

Gå tilbake til Lakehouse for å se endringene.

Vise jobbene dine i overvåkingshuben
Du kan få tilgang til overvåkingshuben for å vise ulike Apache Spark-aktiviteter ved å velge Monitor i navigasjonskoblingene til venstre.
Når den satsvise jobben er fullført, kan du vise øktstatusen ved å navigere til Overvåking.
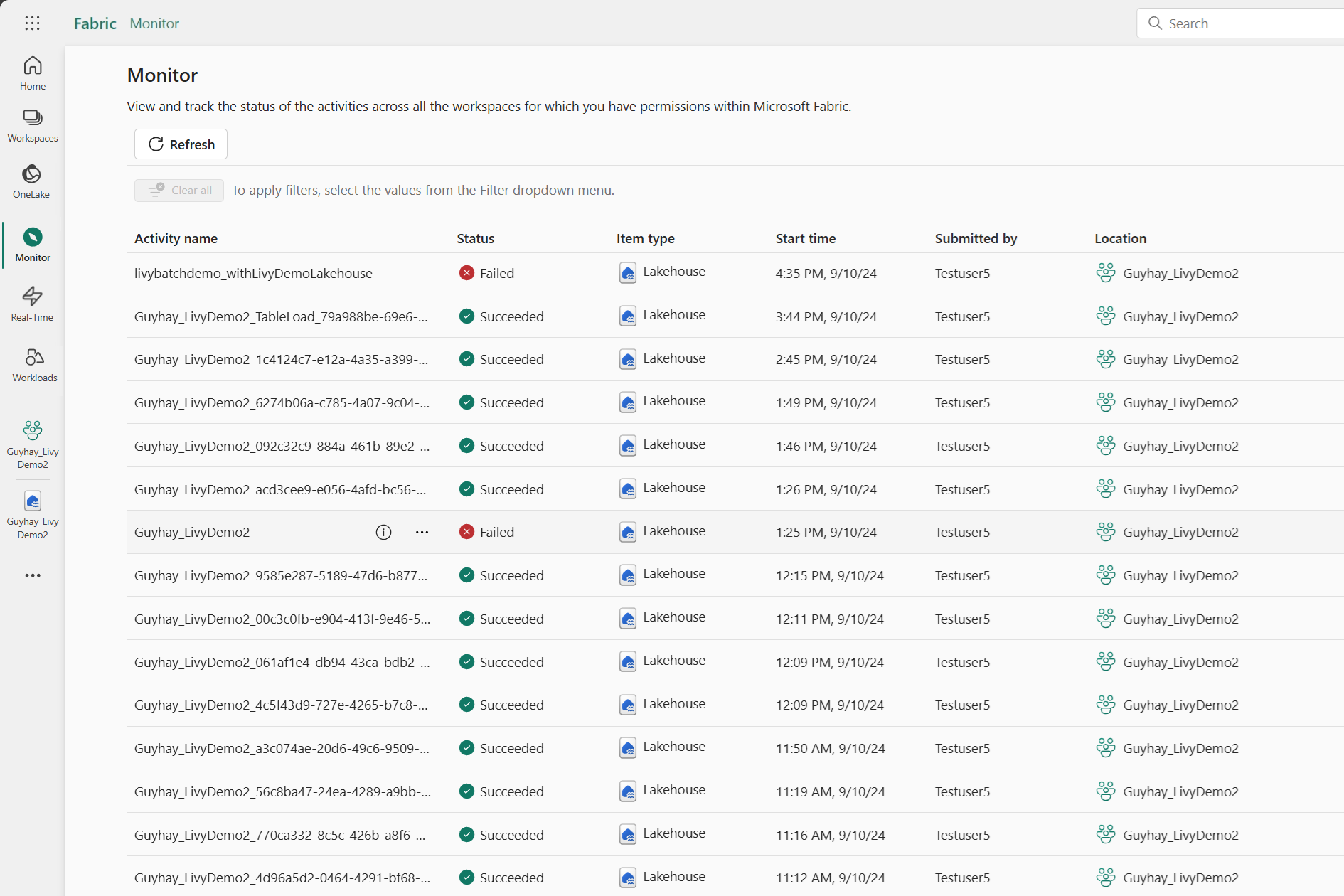
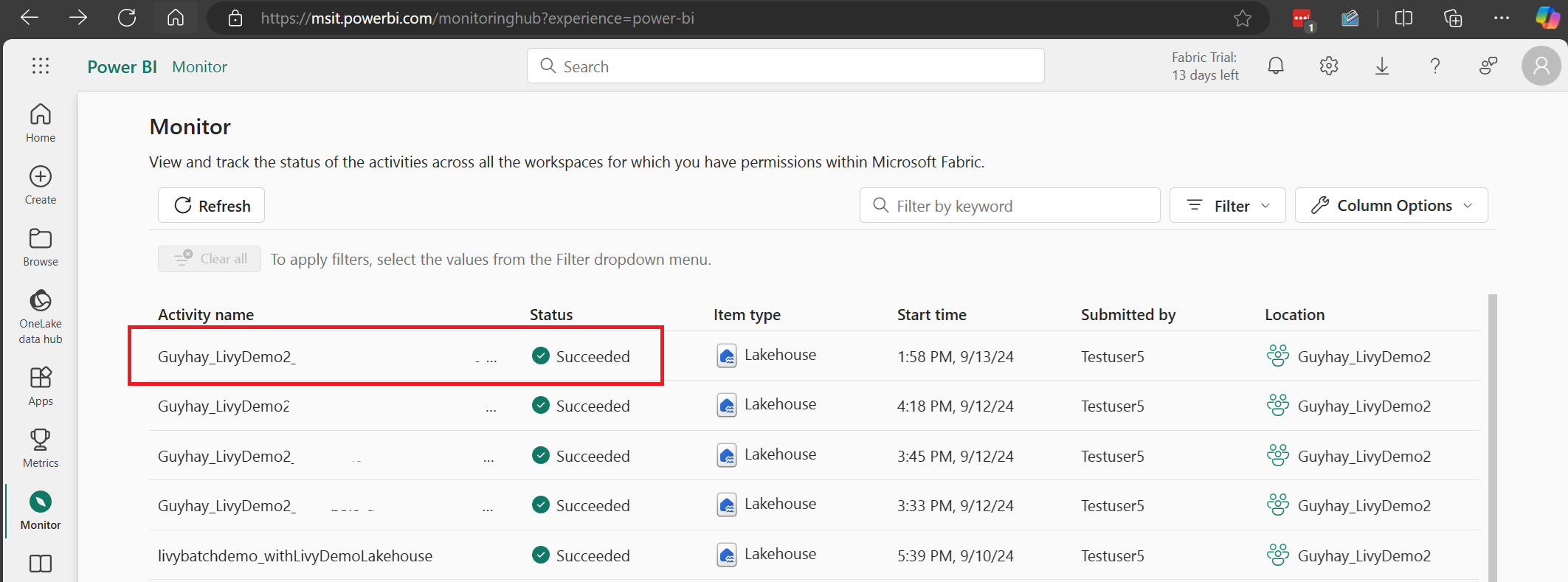
Velg og åpne det nyeste aktivitetsnavnet.
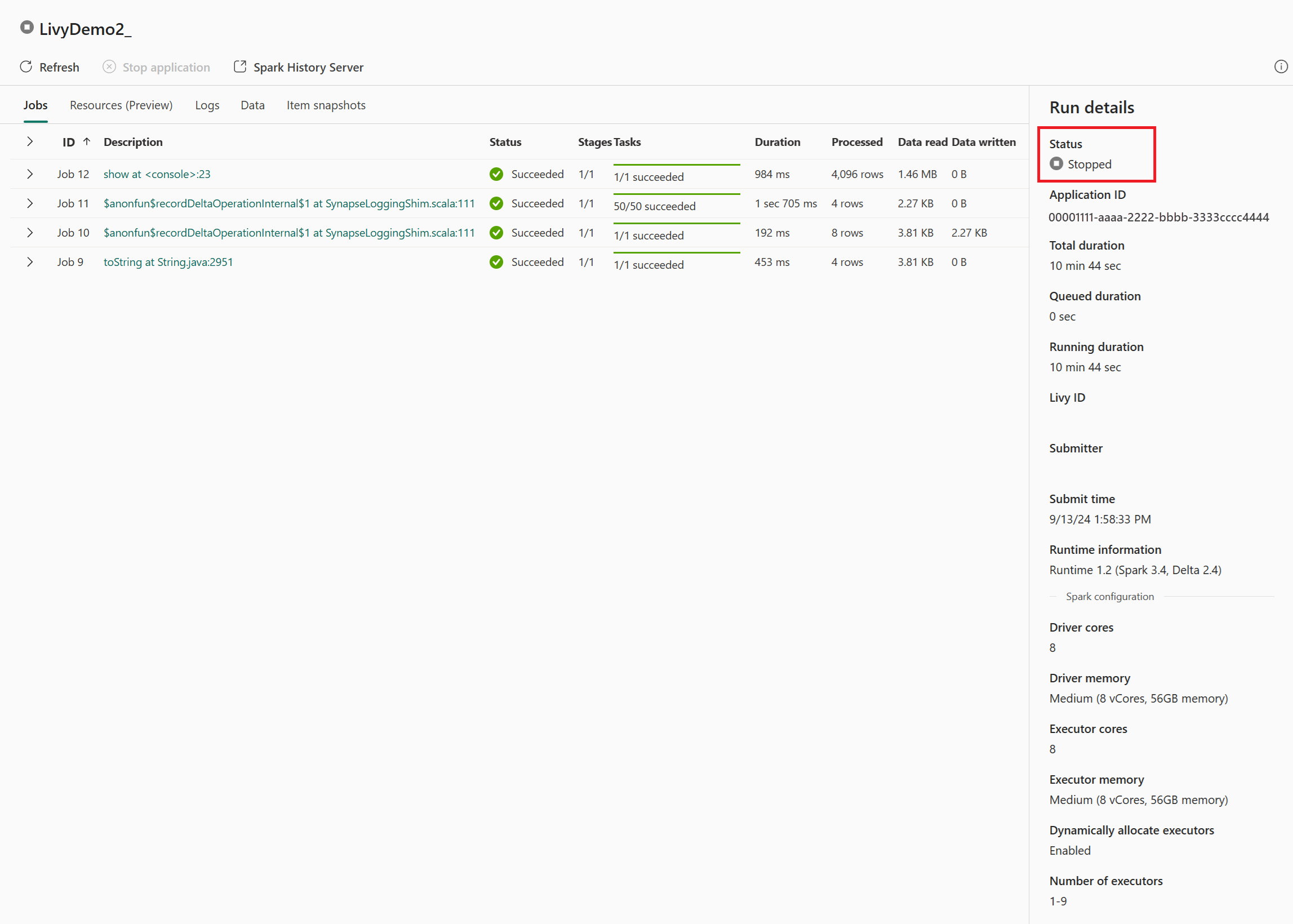
I dette livy API-økttilfellet kan du se den forrige satsvise innsendingen, kjøre detaljer, Spark-versjoner og konfigurasjon. Legg merke til stoppet status øverst til høyre.



Hvis du vil oppsummere hele prosessen, trenger du en ekstern klient, for eksempel Visual Studio Code, et Microsoft Entra-apptoken, Livy API-endepunkt-NETTADRESSE, godkjenning mot Lakehouse, en Spark-nyttelast i Lakehouse og til slutt en satsvis Livy API-økt.