Bruk utvidet Apache Spark-loggserver til å feilsøke og diagnostisere Apache Spark-programmer
Denne artikkelen gir veiledning om hvordan du bruker den utvidede Apache Spark-loggserveren til å feilsøke og diagnostisere fullførte og kjøre Apache Spark-programmer.
Få tilgang til Apache Spark-loggserveren
Apache Spark-loggserveren er nettbrukergrensesnittet for fullførte og kjørende Spark-programmer. Du kan åpne brukergrensesnittet for Apache Spark web (UI) fra fremdriftsindikatornotatblokken eller detaljsiden for Apache Spark-programmet.
Åpne Spark Web UI fra fremdriftsindikatornotatblokken
Når en Apache Spark-jobb utløses, er knappen for å åpne Spark web UI i handlingsalternativet Mer i fremdriftsindikatoren. Velg Spark web UI og vent i noen sekunder, og deretter vises spark-brukergrensesnittsiden.

Åpne spark-nettgrensesnittet fra detaljsiden for Apache Spark-programmet
Spark-nettgrensesnittet kan også åpnes via detaljsiden for Apache Spark-programmet. Velg Overvåk på venstre side av siden, og velg deretter et Apache Spark-program. Detaljsiden for programmet vises.

For et Apache Spark-program som har statusen kjører, viser knappen Spark-brukergrensesnittet. Velg Spark-brukergrensesnittet , og Spark UI-siden vises.

For et Apache Spark-program som har statusen avsluttet, kan statusen som avsluttes, stoppes, mislykkes, avbrytes eller fullføres. Knappen viser Spark-loggserveren. Velg Spark-loggserver , og Spark UI-siden vises.

Graf-fanen i Apache Spark-loggserver
Velg jobb-ID-en for jobben du vil vise. Velg deretter Graf på verktøymenyen for å få jobbgrafvisning.
Oversikt
Du kan se en oversikt over jobben din i det genererte jobbdiagrammet. Som standard viser grafen alle jobber. Du kan filtrere denne visningen etter jobb-ID.

Vis
Fremdrift-visningen er valgt som standard. Du kan kontrollere dataflyten ved å velge Les eller Skrevet i rullegardinlisten Vis .

Grafnoden viser fargene som vises i forklaringen på varmekartet.

Avspilling
Hvis du vil spille av jobben, velger du Avspilling. Du kan velge Stopp når som helst for å stoppe. Oppgavefargene viser ulike statuser når du spiller av:
| Color | Betydning |
|---|---|
| Grønn | Fullført: Jobben er fullført. |
| Oransje | Forsøkt på nytt: Forekomster av aktiviteter som mislyktes, men som ikke påvirker det endelige resultatet av jobben. Disse oppgavene hadde dupliserte eller prøver på nytt forekomster som kan lykkes senere. |
| Blå | Kjører: Oppgaven kjører. |
| Hvit | Venter eller hoppet over: Oppgaven venter på å kjøre, eller fasen har hoppet over. |
| Rød | Mislyktes: Oppgaven mislyktes. |
Bildet nedenfor viser grønne, oransje og blå statusfarger.

Bildet nedenfor viser grønne og hvite statusfarger.

Bildet nedenfor viser røde og grønne statusfarger.

Merk
Apache Spark-loggserveren tillater avspilling for hver fullførte jobb (men tillater ikke avspilling for ufullstendige jobber).
Zoom
Bruk muserullen til å zoome inn og ut på jobbgrafen, eller velg Zoom for å få den til å passe til skjermen.

Verktøytips
Hold pekeren over grafnoden for å se verktøytipset når det er mislykkede aktiviteter, og velg en fase for å åpne fasesiden.

Faser på jobbgraffanen har et verktøytips, og et lite ikon vises hvis de har oppgaver som oppfyller følgende betingelser:
| Betingelse | Bekrivelse |
|---|---|
| Dataskyv | Datalesestørrelse > gjennomsnittlig datalesestørrelse for alle oppgaver i dette stadiet * 2 og datalesestørrelse > 10 MB. |
| Tidsspyd | Kjøringstid > gjennomsnittlig kjøringstid for alle aktiviteter i dette stadiet * 2 og kjøringstid > 2 minutter. |
![]()
Beskrivelse av grafnode
Jobbgrafnoden viser følgende informasjon for hvert trinn:
- ID
- Navn eller beskrivelse
- Totalt aktivitetsnummer
- Data lest: summen av inndatastørrelse og lesestørrelse for tilfeldig rekkefølge
- Dataskriving: summen av utdatastørrelse og skrivestørrelse for tilfeldig rekkefølge
- Kjøringstidspunkt: tiden mellom starttidspunktet for det første forsøket og fullføringstiden for det siste forsøket
- Radantall: summen av inndataposter, utdataposter, tilfeldig lest oppføringer og tilfeldige skriveposter
- Fremdrift
Merk
Som standard viser jobbgrafnoden informasjon fra det siste forsøket i hvert trinn (bortsett fra kjøringstid for fase). Men under avspillingen viser grafnoden informasjon om hvert forsøk.
Datastørrelsen for lesing og skriving er 1 MB = 1000 KB = 1000 * 1000 byte.
Gi tilbakemelding
Send tilbakemelding med problemer ved å velge Gi oss tilbakemelding.

Fasenummergrense
For ytelsesvurdering er grafen som standard bare tilgjengelig når Spark-programmet har mindre enn 500 faser. Hvis det er for mange faser, vil det mislykkes med en feil som dette:
The number of stages in this application exceeds limit (500), graph page is disabled in this case.
Som en midlertidig løsning, før du starter et Spark-program, må du bruke denne Spark-konfigurasjonen for å øke grensen:
spark.ui.enhancement.maxGraphStages 1000
Legg imidlertid merke til at dette kan føre til dårlig ytelse på siden og API-en, fordi innholdet kan være for stort til at nettleseren kan hente og gjengi.
Utforsk Diagnose-fanen i Apache Spark-loggserveren
Hvis du vil ha tilgang til Diagnose-fanen, velger du en jobb-ID. Velg deretter Diagnose på verktøymenyen for å få jobbdiagnosevisningen. Diagnosefanen inneholder Dataspydd, Tidssskyv og Bruksanalyse for eksekutor.
Kontroller dataspydd, tidsskyvning og bruksanalyse for eksekutor ved å velge henholdsvis fanene.

Dataskyv
Når du velger Fanen Dataspydd , vises de tilsvarende skjev aktivitetene basert på de angitte parameterne.
Angi parametere – Den første delen viser parameterne, som brukes til å oppdage dataspydd. Standardregelen er: Lese aktivitetsdata er større enn tre ganger så mye som de gjennomsnittlige aktivitetsdataene som leses, og aktivitetsdataene som leses, er mer enn 10 MB. Hvis du vil definere din egen regel for skjev oppgaver, kan du velge parameterne. Inndelingene Skjev fase og Skjev tegn oppdateres tilsvarende.
Skjev fase – Den andre delen viser faser som har forskjøvet oppgaver som oppfyller vilkårene som er angitt tidligere. Hvis det er mer enn én skjev aktivitet i en fase, viser den skjeve fasetabellen bare den mest skjev aktiviteten (for eksempel de største dataene for dataskyv).
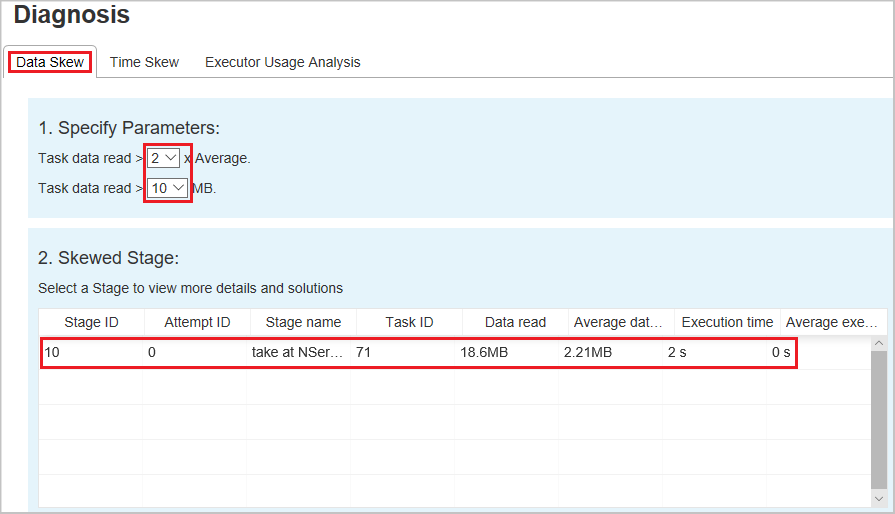
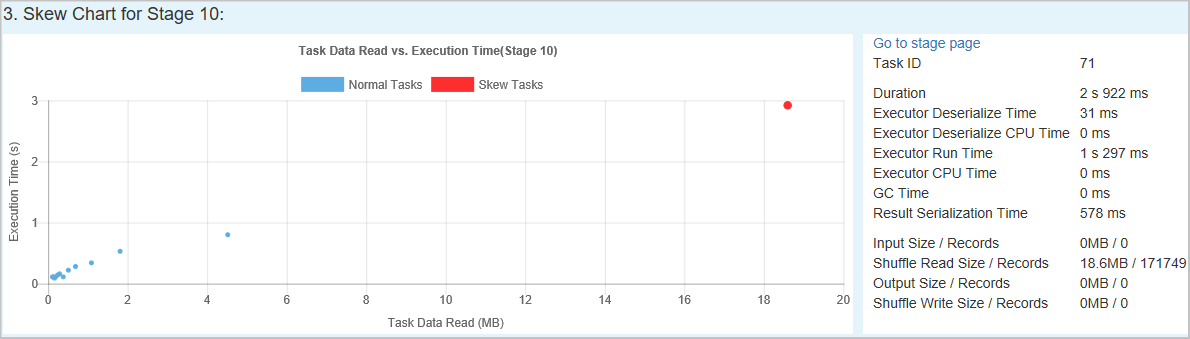
Skjev diagram – Når en rad i skjevfasetabellen er valgt, viser skjevdiagrammet flere aktivitetsdistribusjonsdetaljer basert på datalesing og kjøringstid. De skjeve aktivitetene merkes i rødt, og de vanlige oppgavene merkes i blått. Diagrammet viser opptil 100 eksempeloppgaver, og oppgavedetaljene vises i panelet nederst til høyre.


Tidsskyv
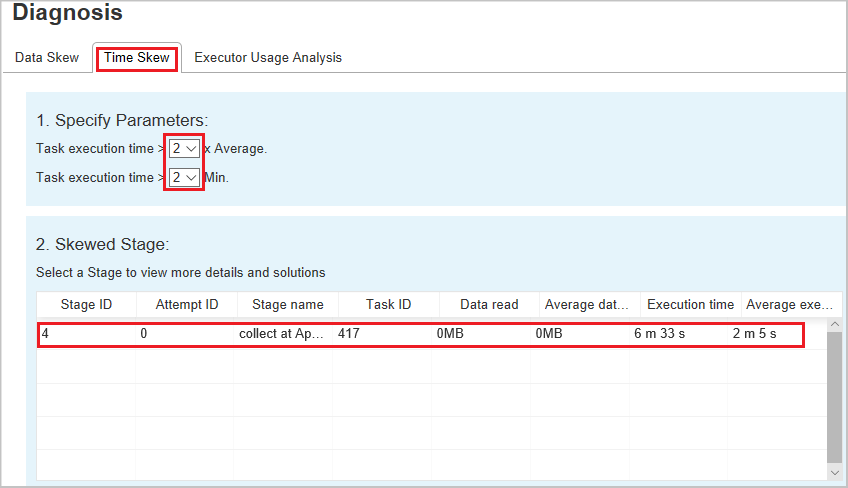
Fanen Forrige tidspunkt viser skjeve aktiviteter basert på aktivitetskjøringstid.
Angi parametere – Den første delen viser parameterne, som brukes til å oppdage tidsforskyvning. Standardkriteriene for å oppdage tidsforskyvelse er: aktivitetskjøringstiden er større enn tre ganger gjennomsnittlig kjøringstid, og aktivitetskjøringstiden er større enn 30 sekunder. Du kan endre parameterne basert på dine behov. Skjev fase og Skjev diagram viser tilsvarende faser og aktivitetsinformasjon, akkurat som dataskyvhet-fanen som er beskrevet tidligere.
Velg Tidsskyv, og deretter vises filtrert resultat i skjev fase-inndelingen i henhold til parameterne som er angitt i inndelingen Angi parametere. Velg ett element i skjev fase-delen , og deretter tegnes det tilsvarende diagrammet i del 3, og oppgavedetaljene vises i panelet nederst til høyre.

Executor Usage Analysis
Denne funksjonen er nå avskrevet i Fabric. Hvis du fremdeles vil bruke dette som en midlertidig løsning, kan du få tilgang til siden ved å eksplisitt legge til «/executorusage» bak banen «/diagnostic» i nettadressen, slik som dette:
