Evaluer den opprinnelige forutsigelsesmodellen for kundebetaling
Denne artikkelen forklarer hvordan du evaluerer en forutsigelsesmodell etter at du har aktivert Finance Insights og deretter generert og kalibrert den første modellen. Denne artikkelen omhandler modeller for å forutsi kundebetalinger. Det beskriver fremgangsmåten du kan bruke for å forstå forutsigelsesmodellen for kundebetaling, og vurdere effektiviteten.
Henter detaljer om modellen
På siden Parametere for økonomisk innsikt i Microsoft Dynamics 365 Finance vises koblingen Forbedre modellnøyaktighet ved siden av poengsummen for nøyaktighet.

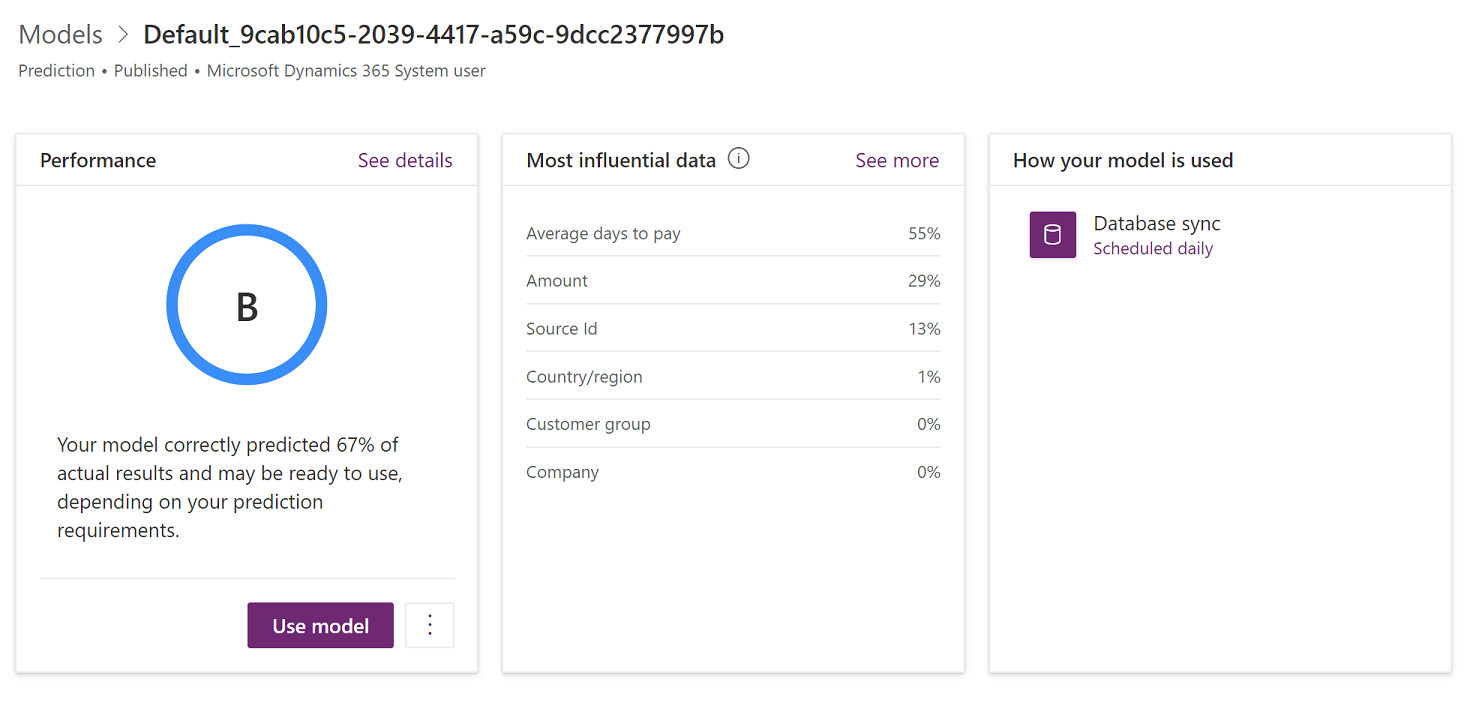
Denne koblingen tar deg til AI Builder, der du kan lære mer om den gjeldende modellen og forbedre den. Illustrasjonen nedenfor viser siden som er åpen.

Siden som åpnes, viser følgende informasjon:
I Ytelse-delen gir modellens ytelsesklasse et overslag over modellens kvalitet. Hvis du vil ha mer informasjon om denne klassen, kan du se Ytelse for prognosemodell i AI Builder-dokumentasjonen.
Delen Data med mest innflytelse viser hvor viktige forskjellige inndatatyper er for modellen din. Du kan evaluere denne listen og de tilsvarende prosentandelene for å fastslå om informasjonen samsvarer med det du vet om firmaet og markedet.
I Ytelse-delen velger du Se detaljer for å lære mer om klassen og andre hensyn. I illustrasjonen nedenfor viser detaljene at modellen bruker mindre informasjon enn det som anbefales. Derfor har systemet generert en advarsel.

Graver dypere
Selv om nøyaktighet er et godt utgangspunkt for evaluering av en modell, og ytelsesklassen gir perspektiv, gir AI Builder mer detaljerte måledata som du kan bruke i evalueringen. Hvis du vil laste ned detaljene, velger du ellipseknappen (...) i Ytelse-delen ved siden av Bruk modell-knappen, og deretter velger du alternativet for Last ned detaljerte mål.

Følgende illustrasjon viser formatet du kan laste ned dataene i.

Hvis du vil ha en dypere analyse av resultatene, er et godt utgangspunkt å gå gjennom matrisen "Forvirringsmatrise". Her finner du for eksempel dataene som vises for denne måleverdien i den forrige illustrasjonen.
{"name": "Confusion Matrix", "value": {"schema_type": "confusion_matrix", "schema_version": "1.0.0", "data": {"class_labels": ["0", "1", "2"], "matrix": [[71, 9, 21], [5, 0, 27], [2, 0, 45]]}}, "type": "dictionaryNumericalList", "isGlobalScore": false}
Du kan utvide disse dataene på følgende måte.
| Forventet Til planlagt tid | Forventet Forsinket | Forventet Svært sent | |
|---|---|---|---|
| Faktisk betaling Til planlagt tid | 71 | 0 | 21 |
| Faktisk forsinket betaling | 5 | 0 | 27 |
| Faktisk svært sen betaling | 2 | 0 | 45 |
Forvirringsmatrisen viser resultatet av et tilfeldig valgt testdatasett fra opplæringsprosessen. Siden disse lukkede fakturaene ikke ble brukt til å lære opp modellen, er de gode testtilfeller for modellen. I tillegg, fordi den faktiske statusen til fakturaen er kjent, kan modellens ytelse også vises.
Det første du ser etter, er den vanligste faktiske verdien. Selv om denne verdien ikke er perfekt justert til det overordnede datasettet, er det en fornuftig tilnærming. I dette tilfellet inntreffer Faktisk betaling Til planlagt tid for 92 av de 171 totale fakturaene og er den vanligste faktiske verdien. Derfor er det en god grunnlinje for modellen din. Hvis du nettopp gjettet at alle fakturaer ville være til rett tid, vil du ha rett 92 av 171 ganger (det vil si 54 prosent av tiden).
Det er viktig at du forstår hvor balansert datasettet er. I dette tilfellet ble 92 av 171 fakturaer betalt til rett tid, 32 ble betalt for sent, og 47 ble betalt svært sent. Disse verdiene angir et forholdsvis balansert datasett, fordi det er ikke-trivielle resultater i hver klassifisering. En situasjon der en av statusene har svært få resultater, kan være utfordrende for en maskinlæringsmodell.
Nøyaktigheten til modellen angir antallet korrekte prediksjoner for testens datasett. Disse riktige prediksjonene er verdiene som vises i fet skrift i det foregående eksemplet. I dette tilfellet gir verdiene en beregnet nøyaktighet på 67,8 prosent (= [71 + 0 + 45] ÷ 171). Denne verdien representerer en forbedring på 14 prosent over den opprinnelige antakelsen på 54 prosent og er én indikator for modellens kvalitet.
Hvis du ser nærmere på forvirringsmatrisen, vil du merke at modellen gjør en god jobb med å predikere fakturabetalinger som er til rett tid og betalinger som er svært sene. Den tar imidlertid feil om alle 32-fakturaene som faktisk er betalt sent (men ikke svært sent). Dette resultatet vil si at det kreves tilleggsutforsking og en forbedring av modellen.
Et tall som representerer ytelsen til modellen bedre enn nøyaktigheten, er F1-makroens poengsum. Denne poengsummen vurderer resultatene av hver klassifiseringstilstand (på tiden, forsinket og svært sen). Her finner du for eksempel dataene som vises for F1-makro-måleverdien i den forrige illustrasjonen.
{"name": "F1 Macro", "value": 0.4927170868347339, "type": "percentage", "isGlobalScore": false}
I dette tilfellet angir en F1-makropoengsum på ca. 49,3 prosent at modellen ikke gir effektive prediksjoner på tvers av hver tilstand, til tross for en generell nøyaktighetspoengsum som virker høy.
Forbedre modellen
Når du har forstått resultatene av den første modellen bedre, vil du kanskje forbedre modellen ved å legge til eller fjerne funksjonskolonner, eller ved å filtrere deler av datasettet som ikke støtter nøyaktige prediksjoner. Lukk AI Builder, og bruk deretter koblingen Forbedre modell i Dynamics 365 Finance til å starte AI Builder-prosessen på nytt. Du kan eksperimentere med forskjellige egenskaper uten å påvirke den publiserte modellen. Den publiserte modellen blir bare påvirket når du velger Publiser. Husk at det brukes en enkelt modell for din forekomst av Dynamics 365 Finance. Du bør derfor se nøye gjennom alle nye modeller før du publiserer den.
For mer informasjon
Hvis du vil ha mer informasjon om hvordan du evaluerer prediksjonsmodellene, kan du se Resultat av maskinlæringsmodeller