Use a lookup table for large parameter arrays in a For each task
For each tasks pass parameter arrays to nested tasks iteratively, to give each nested task information for its run. Parameter arrays are limited to 10,000 characters, or 48 KB if you use task value references to pass them. When you have a larger amount of data to pass to the nested tasks, you can't directly use the input, task values, or job parameters to pass that data.
One alternative to passing the complete data is to store the task data as a JSON file, and pass in a lookup key (into the JSON data) through the task input instead of the complete data. Nested tasks can use the key to retrieve the specific data needed for each iteration.
The following example shows a sample JSON configuration file, and how to pass parameters to a nested task that looks up the values in the JSON configuration.
Sample JSON configuration
This example configuration is a list of steps, with parameters (args) for each iteration (only three steps are shown for this example). Assume that this JSON file is saved as /Workspace/Users/<user>/copy-filtered-table-config.json. We reference this within the nested task.
{
"steps": [
{
"key": "table_1",
"args": {
"catalog": "my-catalog",
"schema": "my-schema",
"source_table": "raw_data_table_1",
"destination_table": "filtered_table_1",
"filter_column": "col_a",
"filter_value": "value_1"
}
}
{
"key": "table_2",
"args": {
"catalog": "my-catalog",
"schema": "my-schema",
"source_table": "raw_data_table_2",
"destination_table": "filtered_table_2",
"filter_column": "col_b",
"filter_value": "value_2"
}
},
{
"key": "table_3",
"args": {
"catalog": "my-catalog",
"schema": "my-schema",
"source_table": "raw_data_table_3",
"destination_table": "filtered_table_3",
"filter_column": "col_c",
"filter_value": "value_3"
}
},
]
}
Sample For each task
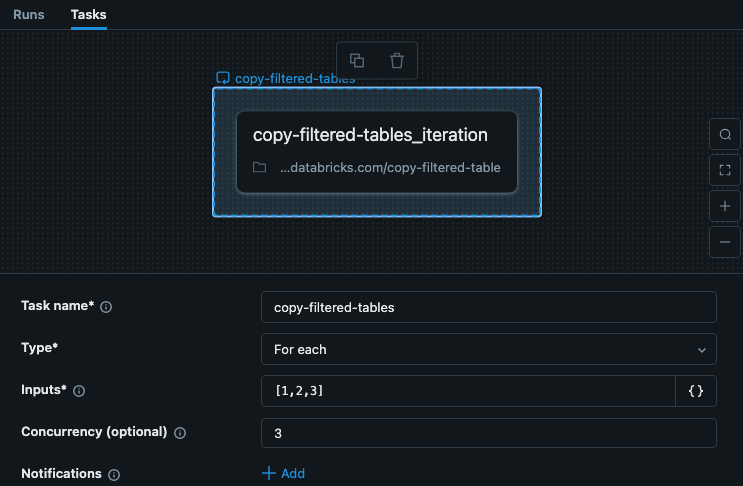
The For each task in your job includes input with the keys for each iteration. This example shows a task called copy-filtered-tables with the Inputs set to ["table_1","table_2","table_3"]. This list is limited to 10,000 characters, but because you are just passing keys, it is much smaller than the full data.
In this example the steps do not depend on other steps or tasks, so we can set a concurrency greater than 1 to make the task run faster.
Sample nested task
The nested task is passed the input from the parent For each task. In this case, we set up the input to be used as a Key for the configuration file. The following image shows the nested task, including setting up a Parameter called key with the value {{input}}.
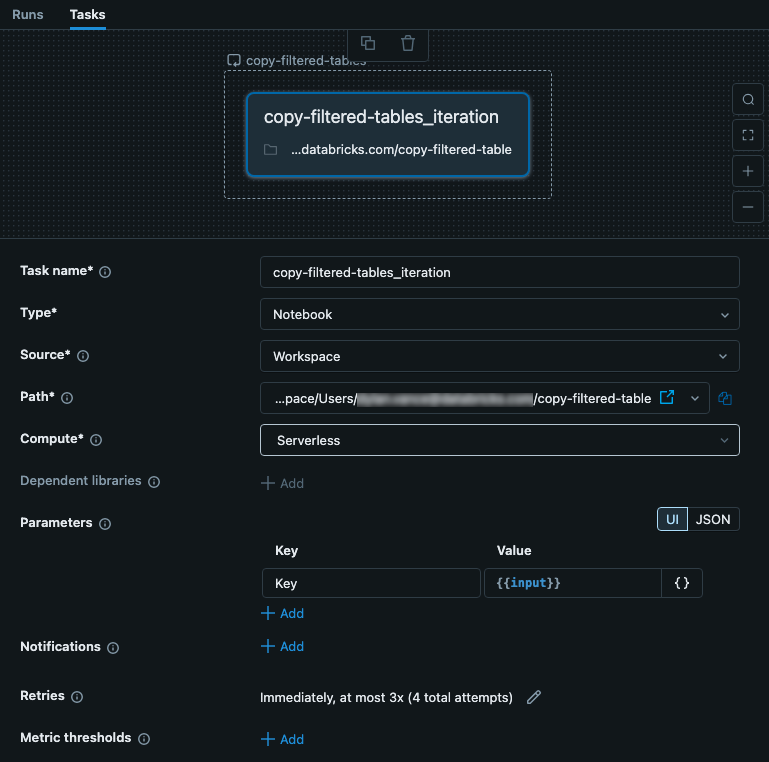
This task is a notebook that contains code. In your notebook, you can use the following Python code to read the input and use that as a key into the config JSON file. The data from the JSON file is used to read, filter, and write data from a table.
# copy-filtered-table (iteratable task code to read a table, filter by a value, and write as a new table)
from pyspark.sql.functions import expr
from types import SimpleNamespace
import json
# If the notebook is run outside of a job with a key parameter, this provides
# a default. This allows testing outside of a For each task
dbutils.widgets.text("key", "table_1", "key")
# load configuration (note that the path must be set to valid configuration file)
config_path = "/Workspace/Users/<user>/copy-filtered-table-config.json"
with open(config_path, "r") as file:
config = json.loads(file.read())
# look up step and arguments
key = dbutils.widgets.get("key")
current_step = next((step for step in config['steps'] if step['key'] == key), None)
if current_step is None:
raise ValueError(f"Could not find step '{key}' in the configuration")
args = SimpleNamespace(**current_step["args"])
# read the source table defined for the step, and filter it
df = spark.read.table(f"{args.catalog}.{args.schema}.{args.source_table}") \
.filter(expr(f"{args.filter_column} like '%{args.filter_value}%'"))
# write the filtered table to the destination
df.write.mode("overwrite").saveAsTable(f"{args.catalog}.{args.schema}.{args.destination_table}")