PowerShell 및 저장소 공간 직접 성능 기록을 사용한 스크립팅
Windows Server 2019에서 저장소 공간 Direct는 가상 머신, 서버, 드라이브, 볼륨, 네트워크 어댑터 등에 대한 광범위한 성능 기록을 기록하고 저장합니다. 성능 기록은 PowerShell에서 쉽게 쿼리하고 처리할 수 있으므로 원시 데이터에서 실제 답변으로 빠르게 이동할 수 있습니다.
- 지난 주에 CPU 스파이크가 있었나요?
- 실제 디스크에 비정상적인 대기 시간이 있나요?
- 현재 가장 많은 스토리지 IOPS를 사용하는 VM은 무엇입니까?
- 네트워크 대역폭이 포화되었나요?
- 이 볼륨은 언제 사용 가능한 공간이 부족합니까?
- 지난 달에 가장 많은 메모리를 사용한 VM은 무엇입니까?
Get-ClusterPerfcmdlet은 스크립팅을 위해 빌드됩니다. 연결을 처리하기 위해 파이프라인과 Get-VM 혹은 Get-PhysicalDisk와 같은 cmdlet의 입력을 허용하고, 출력을 Sort-Object, Where-Object나 Measure-Object유틸리티 cmdlet으로 파이프하여 강력한 쿼리를 신속하게 작성할 수 있습니다.
이 항목에서는 위의 6가지 질문에 답변하는 6개의 샘플 스크립트를 제공하고 설명합니다. 다양한 데이터 및 시간 범위에서 피크를 찾고, 평균을 찾고, 추세선을 표시하고, 이상값 검색을 실행하는 등 적용할 수 있는 패턴을 제공합니다. 복사, 확장 및 다시 사용할 수 있도록 무료 시작 코드로 제공됩니다.
참고 항목
간단히 하기 위해 샘플 스크립트는 고품질 PowerShell 코드에서 예상할 수 있는 오류 처리와 같은 항목을 생략합니다. 주로 생산용이 아닌 영감과 교육을 위한 것입니다.
샘플 1: CPU, 확인해 주세요!
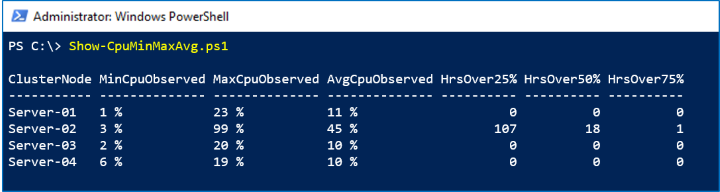
이 샘플에서는 LastWeek 시간 범위의 ClusterNode.Cpu.Usage 계열을 사용하여 클러스터의 모든 서버에 대한 최대("상위 워터 마크"), 최소 및 평균 CPU 사용량을 표시합니다. 또한 간단한 사분위수 분석을 수행하여 지난 8일 동안 CPU 사용량이 25%, 50%, 75%를 초과한 시간을 보여 줍니다.
스크린샷
아래 스크린샷에서는 Server-02가 지난 주에 설명할 수 없는 급증을 보였습니다.
작동 방식
Get-ClusterPerf 파이프에서 기본 제공 Measure-Object cmdlet으로의 출력은 Value 속성을 지정하기만 하면 됩니다. 플래그-Maximum-Minimum와 -Average과 함께, Measure-Object 는 처음 세 개의 열을 거의 무료로 제공합니다. 사분위수 분석을 수행하려면 Where-Object 수를 파이프하고 얼마나 많은 값이 -Gt(다음 보다 보다 큰 값) 25, 50, 혹은 75 였는지 계산할 수 있습니다. 마지막 단계는 Format-Hours 및 Format-Percent 도우미 기능을 사용하여 아름답게 하는 것입니다. 이는 분명히 선택 사항입니다.
스크립트
스크립트는 다음과 같습니다.
Function Format-Hours {
Param (
$RawValue
)
# Weekly timeframe has frequency 15 minutes = 4 points per hour
[Math]::Round($RawValue/4)
}
Function Format-Percent {
Param (
$RawValue
)
[String][Math]::Round($RawValue) + " " + "%"
}
$Output = Get-ClusterNode | ForEach-Object {
$Data = $_ | Get-ClusterPerf -ClusterNodeSeriesName "ClusterNode.Cpu.Usage" -TimeFrame "LastWeek"
$Measure = $Data | Measure-Object -Property Value -Minimum -Maximum -Average
$Min = $Measure.Minimum
$Max = $Measure.Maximum
$Avg = $Measure.Average
[PsCustomObject]@{
"ClusterNode" = $_.Name
"MinCpuObserved" = Format-Percent $Min
"MaxCpuObserved" = Format-Percent $Max
"AvgCpuObserved" = Format-Percent $Avg
"HrsOver25%" = Format-Hours ($Data | Where-Object Value -Gt 25).Length
"HrsOver50%" = Format-Hours ($Data | Where-Object Value -Gt 50).Length
"HrsOver75%" = Format-Hours ($Data | Where-Object Value -Gt 75).Length
}
}
$Output | Sort-Object ClusterNode | Format-Table
샘플 2: 화재, 화재, 대기 시간 이상값
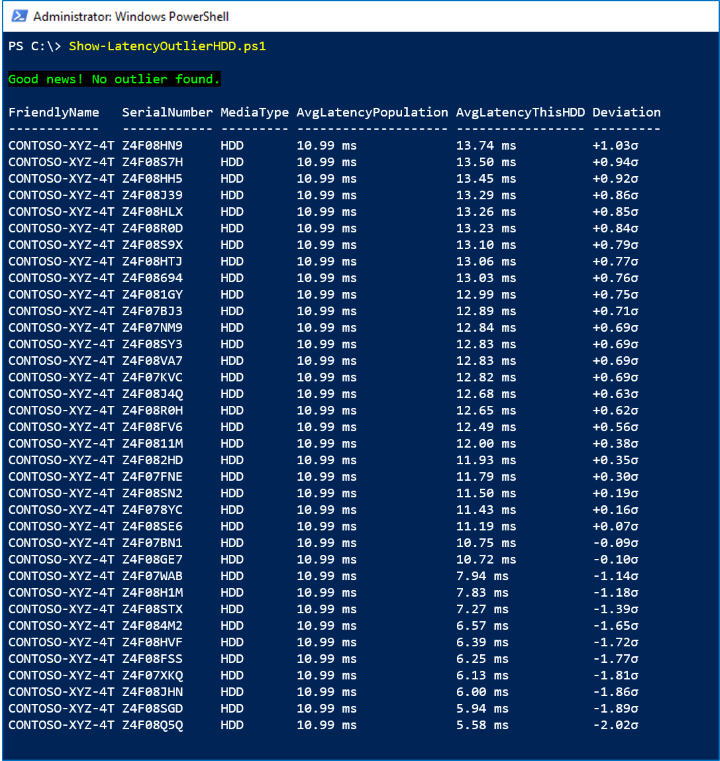
이 샘플에서는 LastHour 시간 범위의 PhysicalDisk.Latency.Average 계열을 사용하여 시간당 평균 대기 시간이 모집단 평균보다 +3σ(3개의 표준 편차)를 초과하는 드라이브로 정의된 통계 이상값을 찾습니다.
Important
간단히 하기 위해 이 스크립트는 낮은 분산에 대한 보호 장치를 구현하지 않고, 부분 누락된 데이터를 처리하지 않으며, 모델 또는 펌웨어 등을 구분하지 않습니다. 적절한 판단을 수행하고 하드 디스크를 교체할지 여부를 결정하기 위해 이 스크립트에만 의존하지 마세요. 교육용으로만 제공됩니다.
스크린샷
아래 스크린샷에는 이상값이 없습니다.
작동 방식
첫째, 유휴 또는 거의 유휴 드라이브는 PhysicalDisk.Iops.Total가 일관되게 -Gt 1 인지 확인함으로써 제외합니다. 모든 활성 HDD의 경우 Measure-Object -Average에서 지난 1시간 동안의 평균 대기 시간을 확보하기 위해 10초 간격으로 360개의 측정으로 구성된 LastHour 시간 프레임을 파이프합니다. 이것은 우리의 인구를 설정합니다.
모집단의 평균 μ 및 표준 편차 σ 를 찾기 위해 널리 알려진 수식을 구현합니다. 모든 활성 HDD의 경우 평균 대기 시간을 모집단 평균과 비교하고 표준 편차로 나눕니다. 원시 값을 유지하므로 결과를 Sort-Object 할 수 있지만 Format-Latency 및 Format-StandardDeviation도우미 함수를 사용하여 표시할 내용을 아름답게 만들 수 있습니다 - 확실한 선택 사항.
드라이브가 +3σ를 초과하는 경우 빨간색으로 Write-Host되고, 그렇지 않으면 녹색으로 됩니다.
스크립트
스크립트는 다음과 같습니다.
Function Format-Latency {
Param (
$RawValue
)
$i = 0 ; $Labels = ("s", "ms", "μs", "ns") # Petabits, just in case!
Do { $RawValue *= 1000 ; $i++ } While ( $RawValue -Lt 1 )
# Return
[String][Math]::Round($RawValue, 2) + " " + $Labels[$i]
}
Function Format-StandardDeviation {
Param (
$RawValue
)
If ($RawValue -Gt 0) {
$Sign = "+"
}
Else {
$Sign = "-"
}
# Return
$Sign + [String][Math]::Round([Math]::Abs($RawValue), 2) + "σ"
}
$HDD = Get-StorageSubSystem Cluster* | Get-PhysicalDisk | Where-Object MediaType -Eq HDD
$Output = $HDD | ForEach-Object {
$Iops = $_ | Get-ClusterPerf -PhysicalDiskSeriesName "PhysicalDisk.Iops.Total" -TimeFrame "LastHour"
$AvgIops = ($Iops | Measure-Object -Property Value -Average).Average
If ($AvgIops -Gt 1) { # Exclude idle or nearly idle drives
$Latency = $_ | Get-ClusterPerf -PhysicalDiskSeriesName "PhysicalDisk.Latency.Average" -TimeFrame "LastHour"
$AvgLatency = ($Latency | Measure-Object -Property Value -Average).Average
[PsCustomObject]@{
"FriendlyName" = $_.FriendlyName
"SerialNumber" = $_.SerialNumber
"MediaType" = $_.MediaType
"AvgLatencyPopulation" = $null # Set below
"AvgLatencyThisHDD" = Format-Latency $AvgLatency
"RawAvgLatencyThisHDD" = $AvgLatency
"Deviation" = $null # Set below
"RawDeviation" = $null # Set below
}
}
}
If ($Output.Length -Ge 3) { # Minimum population requirement
# Find mean μ and standard deviation σ
$μ = ($Output | Measure-Object -Property RawAvgLatencyThisHDD -Average).Average
$d = $Output | ForEach-Object { ($_.RawAvgLatencyThisHDD - $μ) * ($_.RawAvgLatencyThisHDD - $μ) }
$σ = [Math]::Sqrt(($d | Measure-Object -Sum).Sum / $Output.Length)
$FoundOutlier = $False
$Output | ForEach-Object {
$Deviation = ($_.RawAvgLatencyThisHDD - $μ) / $σ
$_.AvgLatencyPopulation = Format-Latency $μ
$_.Deviation = Format-StandardDeviation $Deviation
$_.RawDeviation = $Deviation
# If distribution is Normal, expect >99% within 3σ
If ($Deviation -Gt 3) {
$FoundOutlier = $True
}
}
If ($FoundOutlier) {
Write-Host -BackgroundColor Black -ForegroundColor Red "Oh no! There's an HDD significantly slower than the others."
}
Else {
Write-Host -BackgroundColor Black -ForegroundColor Green "Good news! No outlier found."
}
$Output | Sort-Object RawDeviation -Descending | Format-Table FriendlyName, SerialNumber, MediaType, AvgLatencyPopulation, AvgLatencyThisHDD, Deviation
}
Else {
Write-Warning "There aren't enough active drives to look for outliers right now."
}
샘플 3: 시끄러운 이웃? 즉, 쓰기입니다!
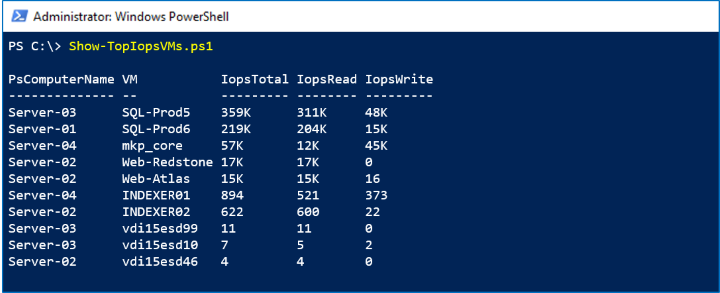
성능 기록도 지금 당장에 대한 질문에 답할 수 있습니다. 새로운 측정값은 10초마다 실시간으로 사용할 수 있습니다. 이 샘플에서는 MostRecent 시간 범위의 VHD.Iops.Total 시리즈를 사용하여 클러스터의 모든 호스트에서 가장 많은 스토리지 IOPS를 사용하는 가장 바쁜 가상 머신(일부는 "가장 시끄럽다"라고도 함)을 식별하고 해당 활동의 읽기/쓰기 분석을 표시합니다.
스크린샷
아래 스크린샷에는 스토리지 작업별 상위 10개 가상 머신이 표시됩니다.
작동 방식
cmdlet Get-VM는 Get-PhysicalDisk과 같이 클러스터를 인식하지 않으므로 로컬 서버에서만 VM을 반환합니다. 모든 서버에서 병렬로 쿼리하기 위해 호출을 Invoke-Command (Get-ClusterNode).Name { ... }로 래핑합니다. 모든 VM에 대해 측정값 VHD.Iops.Total VHD.Iops.Read 및 VHD.Iops.Write을 가져옵니다. -TimeFrame 매개 변수를 지정하지 않으면 각각에 대한 MostRecent 단일 데이터 포인트를 가져옵니다.
팁
이러한 시리즈는 이 VM의 활동의 합계를 모든 VHD/VHDX 파일에 반영합니다. 성능 기록이 자동으로 집계되는 예제입니다. VHD/VHDX별 분석을 가져오기 위해 VM 대신 개인 Get-VHD 을 Get-ClusterPerf로 파이프할 수 있습니다.
모든 서버의 결과는 $Output과 같으며, 이는 곧 Sort-Object를 하고나서 Select-Object -First 10이 됩니다. Invoke-Command은 결과를 PsComputerName 속성으로 데코레이팅하여 실행되는 위치를 알기 위해 인쇄할 수 있는 원본을 나타내어 VM이 어디서 실행중인지 알 수 있음을 명심하세요.
스크립트
스크립트는 다음과 같습니다.
$Output = Invoke-Command (Get-ClusterNode).Name {
Function Format-Iops {
Param (
$RawValue
)
$i = 0 ; $Labels = (" ", "K", "M", "B", "T") # Thousands, millions, billions, trillions...
Do { if($RawValue -Gt 1000){$RawValue /= 1000 ; $i++ } } While ( $RawValue -Gt 1000 )
# Return
[String][Math]::Round($RawValue) + " " + $Labels[$i]
}
Get-VM | ForEach-Object {
$IopsTotal = $_ | Get-ClusterPerf -VMSeriesName "VHD.Iops.Total"
$IopsRead = $_ | Get-ClusterPerf -VMSeriesName "VHD.Iops.Read"
$IopsWrite = $_ | Get-ClusterPerf -VMSeriesName "VHD.Iops.Write"
[PsCustomObject]@{
"VM" = $_.Name
"IopsTotal" = Format-Iops $IopsTotal.Value
"IopsRead" = Format-Iops $IopsRead.Value
"IopsWrite" = Format-Iops $IopsWrite.Value
"RawIopsTotal" = $IopsTotal.Value # For sorting...
}
}
}
$Output | Sort-Object RawIopsTotal -Descending | Select-Object -First 10 | Format-Table PsComputerName, VM, IopsTotal, IopsRead, IopsWrite
샘플 4: 그들이 말했듯이, "25 공연은 새로운 10 공연입니다"
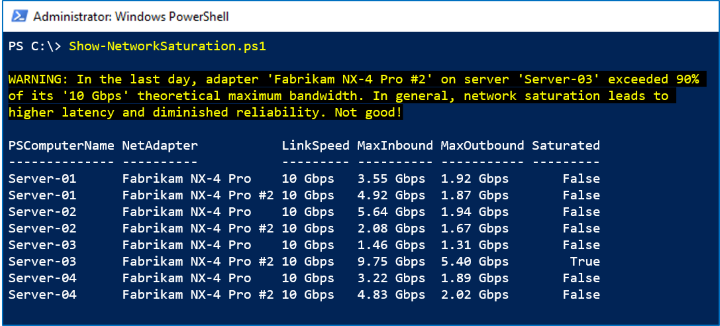
이 샘플에서는 LastDay 시간 범위의 NetAdapter.Bandwidth.Total계열을 사용하여 이론적 최대 대역폭의 >90%로 정의된 네트워크 포화의 징후를 찾습니다. 클러스터의 모든 네트워크 어댑터에 대해 마지막 날에 관찰된 가장 높은 대역폭 사용량을 명시된 링크 속도와 비교합니다.
스크린샷
아래 스크린샷에서는 마지막 날에 Fabrikam NX-4 Pro #2 하나가 최고조에 달했음을 알 수 있습니다.
작동 방식
우리는 Get-NetAdapter까지의 모든 서버로의 Invoke-Command 트릭을 반복 하고 Get-ClusterPerf으로 파이프합니다. 그 과정에서 "10Gbps"와 같은 LinkSpeed 문자열과 10000000000과 같은 원시 Speed 정수라는 두 가지 관련 속성을 가져옵니다. 마지막 날(미리 알림: LastDay 시간 범위의 각 측정값은 5분을 나타낸다)에서 평균 및 피크를 Measure-Object을 통해 가져오고 바이트당 8비트를 곱하여 사과 대 사과 비교를 얻습니다.
참고 항목
Chelsio와 같은 일부 공급업체는 네트워크 어댑터 성능 카운터에 RDMA(원격 직접 메모리 액세스) 작업을 포함하므로 NetAdapter.Bandwidth.Total시리즈에 포함됩니다. 멜라녹스와 같은 다른 사람들은 그렇지 않을 수 있습니다. 공급업체가 그렇지 않은 경우 이 스크립트의 버전에 NetAdapter.Bandwidth.RDMA.Total 계열을 추가하기만 하면 됩니다.
스크립트
스크립트는 다음과 같습니다.
$Output = Invoke-Command (Get-ClusterNode).Name {
Function Format-BitsPerSec {
Param (
$RawValue
)
$i = 0 ; $Labels = ("bps", "kbps", "Mbps", "Gbps", "Tbps", "Pbps") # Petabits, just in case!
Do { $RawValue /= 1000 ; $i++ } While ( $RawValue -Gt 1000 )
# Return
[String][Math]::Round($RawValue) + " " + $Labels[$i]
}
Get-NetAdapter | ForEach-Object {
$Inbound = $_ | Get-ClusterPerf -NetAdapterSeriesName "NetAdapter.Bandwidth.Inbound" -TimeFrame "LastDay"
$Outbound = $_ | Get-ClusterPerf -NetAdapterSeriesName "NetAdapter.Bandwidth.Outbound" -TimeFrame "LastDay"
If ($Inbound -Or $Outbound) {
$InterfaceDescription = $_.InterfaceDescription
$LinkSpeed = $_.LinkSpeed
$MeasureInbound = $Inbound | Measure-Object -Property Value -Maximum
$MaxInbound = $MeasureInbound.Maximum * 8 # Multiply to bits/sec
$MeasureOutbound = $Outbound | Measure-Object -Property Value -Maximum
$MaxOutbound = $MeasureOutbound.Maximum * 8 # Multiply to bits/sec
$Saturated = $False
# Speed property is Int, e.g. 10000000000
If (($MaxInbound -Gt (0.90 * $_.Speed)) -Or ($MaxOutbound -Gt (0.90 * $_.Speed))) {
$Saturated = $True
Write-Warning "In the last day, adapter '$InterfaceDescription' on server '$Env:ComputerName' exceeded 90% of its '$LinkSpeed' theoretical maximum bandwidth. In general, network saturation leads to higher latency and diminished reliability. Not good!"
}
[PsCustomObject]@{
"NetAdapter" = $InterfaceDescription
"LinkSpeed" = $LinkSpeed
"MaxInbound" = Format-BitsPerSec $MaxInbound
"MaxOutbound" = Format-BitsPerSec $MaxOutbound
"Saturated" = $Saturated
}
}
}
}
$Output | Sort-Object PsComputerName, InterfaceDescription | Format-Table PsComputerName, NetAdapter, LinkSpeed, MaxInbound, MaxOutbound, Saturated
샘플 5: 스토리지를 다시 트렌디하게 만드세요!
매크로 추세를 살펴보기 위해 성능 기록은 최대 1년 동안 유지됩니다. 이 샘플에서는 LastYear 기간의 Volume.Size.Available 계열을 사용하여 스토리지가 채워지는 속도를 결정하고 가득 찼을 때를 예측합니다.
스크린샷
아래 스크린샷에서는 백업 볼륨이 하루에 약 15GB를 추가하는 것을 볼 수 있습니다.
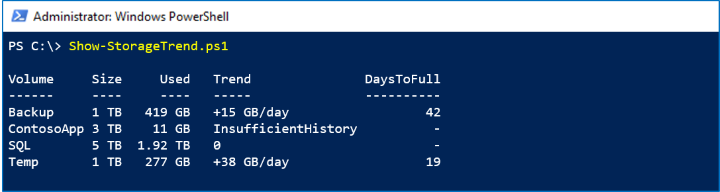
이 속도로 42일 후에 용량에 도달합니다.
작동 방식
LastYear기간에는 하루에 하나의 데이터 포인트가 있습니다. 추세선에 맞게 두 점만 엄격하게 필요하지만 실제로는 14일과 같이 더 많은 것을 요구하는 것이 좋습니다. 범위 [1, 14]의 x에 대해 (x, y) 점의 배열을 설정하는 데 Select-Object -Last 14을 사용합니다. 이러한 점을 사용하여 $A 및 $B를 찾을 수 있는 간단한 선형 최소 제곱 알고리즘을 구현하고 가장 적합한 y = ax + b의 줄을 매개 변수화합니다. 고등학교에 다시 오신 것을 환영합니다.
볼륨의 SizeRemaining 속성을 추세(기울기 $A)로 나누면 볼륨이 가득 찼을 때까지 스토리지 증가율의 현재 속도로 며칠을 조잡하게 예측할 수 있습니다. Format-Bytes, Format-Trend및 Format-Days 도우미 함수는 출력을 아름답게 합니다.
Important
이 추정치는 선형이며 가장 최근의 14일 단위만을 기반으로 합니다. 더 정교하고 정확한 기술이 존재합니다. 적절한 판단을 수행하고 스토리지 확장에 투자할지 여부를 결정하기 위해 이 스크립트에만 의존하지 마세요. 교육용으로만 제공됩니다.
스크립트
스크립트는 다음과 같습니다.
Function Format-Bytes {
Param (
$RawValue
)
$i = 0 ; $Labels = ("B", "KB", "MB", "GB", "TB", "PB", "EB", "ZB", "YB")
Do { $RawValue /= 1024 ; $i++ } While ( $RawValue -Gt 1024 )
# Return
[String][Math]::Round($RawValue) + " " + $Labels[$i]
}
Function Format-Trend {
Param (
$RawValue
)
If ($RawValue -Eq 0) {
"0"
}
Else {
If ($RawValue -Gt 0) {
$Sign = "+"
}
Else {
$Sign = "-"
}
# Return
$Sign + $(Format-Bytes ([Math]::Abs($RawValue))) + "/day"
}
}
Function Format-Days {
Param (
$RawValue
)
[Math]::Round($RawValue)
}
$CSV = Get-Volume | Where-Object FileSystem -Like "*CSV*"
$Output = $CSV | ForEach-Object {
$N = 14 # Require 14 days of history
$Data = $_ | Get-ClusterPerf -VolumeSeriesName "Volume.Size.Available" -TimeFrame "LastYear" | Sort-Object Time | Select-Object -Last $N
If ($Data.Length -Ge $N) {
# Last N days as (x, y) points
$PointsXY = @()
1..$N | ForEach-Object {
$PointsXY += [PsCustomObject]@{ "X" = $_ ; "Y" = $Data[$_-1].Value }
}
# Linear (y = ax + b) least squares algorithm
$MeanX = ($PointsXY | Measure-Object -Property X -Average).Average
$MeanY = ($PointsXY | Measure-Object -Property Y -Average).Average
$XX = $PointsXY | ForEach-Object { $_.X * $_.X }
$XY = $PointsXY | ForEach-Object { $_.X * $_.Y }
$SSXX = ($XX | Measure-Object -Sum).Sum - $N * $MeanX * $MeanX
$SSXY = ($XY | Measure-Object -Sum).Sum - $N * $MeanX * $MeanY
$A = ($SSXY / $SSXX)
$B = ($MeanY - $A * $MeanX)
$RawTrend = -$A # Flip to get daily increase in Used (vs decrease in Remaining)
$Trend = Format-Trend $RawTrend
If ($RawTrend -Gt 0) {
$DaysToFull = Format-Days ($_.SizeRemaining / $RawTrend)
}
Else {
$DaysToFull = "-"
}
}
Else {
$Trend = "InsufficientHistory"
$DaysToFull = "-"
}
[PsCustomObject]@{
"Volume" = $_.FileSystemLabel
"Size" = Format-Bytes ($_.Size)
"Used" = Format-Bytes ($_.Size - $_.SizeRemaining)
"Trend" = $Trend
"DaysToFull" = $DaysToFull
}
}
$Output | Format-Table
샘플 6: 메모리 돼지, 실행할 수 있지만 숨길 수 없습니다.
성능 기록은 전체 클러스터에 대해 중앙에서 수집되고 저장되므로 VM이 호스트 간에 이동하는 횟수에 관계없이 서로 다른 컴퓨터의 데이터를 함께 연결할 필요가 없습니다. 이 샘플은 LastMonth 기간의 VM.Memory.Assigned 시리즈를 사용하여 지난 35일 동안 가장 많은 메모리를 소비하는 가상 머신을 식별합니다.
스크린샷
아래 스크린샷에는 지난 달 메모리 사용량별 상위 10개 가상 머신이 표시됩니다.
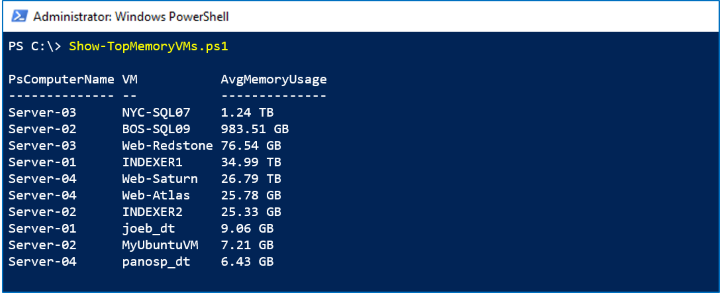
작동 방식
위에서 소개한 Invoke-Command 트릭을 Get-VM까지의 모든 서버에 반복 합니다. 모든 VM의 월평균을 구하기 위해 Measure-Object -Average을 사용한 다음, Sort-Object 이후에 Select-Object -First 10을 하여 리더보드를 확보합니다. (혹은 어쩌면 우리가 가장 원하는 것일 수도 있습니다.)
스크립트
스크립트는 다음과 같습니다.
$Output = Invoke-Command (Get-ClusterNode).Name {
Function Format-Bytes {
Param (
$RawValue
)
$i = 0 ; $Labels = ("B", "KB", "MB", "GB", "TB", "PB", "EB", "ZB", "YB")
Do { if( $RawValue -Gt 1024 ){ $RawValue /= 1024 ; $i++ } } While ( $RawValue -Gt 1024 )
# Return
[String][Math]::Round($RawValue) + " " + $Labels[$i]
}
Get-VM | ForEach-Object {
$Data = $_ | Get-ClusterPerf -VMSeriesName "VM.Memory.Assigned" -TimeFrame "LastMonth"
If ($Data) {
$AvgMemoryUsage = ($Data | Measure-Object -Property Value -Average).Average
[PsCustomObject]@{
"VM" = $_.Name
"AvgMemoryUsage" = Format-Bytes $AvgMemoryUsage.Value
"RawAvgMemoryUsage" = $AvgMemoryUsage.Value # For sorting...
}
}
}
}
$Output | Sort-Object RawAvgMemoryUsage -Descending | Select-Object -First 10 | Format-Table PsComputerName, VM, AvgMemoryUsage
정말 간단하죠. 이러한 샘플이 영감을 주고 시작하는 데 도움이 되기를 바랍니다. 저장소 공간 직접 성능 기록과 강력하고 스크립팅에 친숙한 Get-ClusterPerf cmdlet을 사용하면 질문하고 대답할 수 있습니다. – Windows Server 2019 인프라를 관리하고 모니터링할 때 복잡한 질문입니다.