Active Directory Domain Services의 용량 계획
이 문서에서는 AD DS(Active Directory Domain Services)에 대한 용량 계획에 대한 권장 사항을 제공합니다.
용량 계획의 목표
용량 계획은 성능 인시던트 문제 해결과 동일하지 않습니다. 용량 계획의 목표는 다음과 같습니다.
- 환경을 올바르게 구현하고 운영합니다.
- 성능 문제를 해결하는 데 소요된 시간을 최소화합니다.
용량 계획에서 조직은 클라이언트 성능 요구 사항을 충족하고 데이터 센터에서 하드웨어를 업그레이드하기에 충분한 시간을 제공하기 위해 사용량이 많은 기간 동안 40%라는 프로세서 사용률 기준 목표를 가질 수 있습니다. 한편, 성능 문제에 대한 모니터링 경고 임계값을 5분 간격으로 90%로 설정합니다.
용량 관리 임계값을 지속적으로 초과하는 경우 용량을 늘리기 위해 더 많거나 더 빠른 프로세서를 추가하거나 여러 서버에서 서비스를 크기 조정하는 것이 솔루션입니다. 성능 경고 임계값은 성능 문제가 클라이언트 환경에 부정적인 영향을 줄 때 즉각적인 조치를 취해야 하는 경우를 알 수 있습니다. 반면, 문제 해결 솔루션은 일회성 이벤트 해결에 더 많은 관심을 가집니다.
용량 관리는 방어 주행, 브레이크가 제대로 작동하는지 확인하는 것과 같이 교통 사고 예방 조치와 유사합니다. 성능 문제 해결은 경찰, 소방서, 응급 의료 전문가가 사고에 대응할 때와 비슷합니다.
지난 몇 년 동안 스케일업 시스템에 대한 용량 계획 지침이 크게 변경되었습니다. 시스템 아키텍처의 다음과 같은 변경 사항은 서비스 설계 및 크기 조정에 대한 기본 가정에 반합니다.
- 64비트 서버 플랫폼
- 가상화
- 전력 소비에 대한 관심 증가
- SSD 스토리지
- 클라우드 시나리오
용량 계획에 대한 접근 방식도 서버 기반 계획 연습에서 서비스 기반 계획 연습으로 바뀌고 있습니다. 수많은 Microsoft 및 타사 제품이 백엔드로 사용하는 완성도 높은 분산 서비스인 AD DS(Active Directory Domain Services)는 이제 다른 애플리케이션을 실행하는 데 필요한 용량을 확보하는 데 가장 중요한 제품 중 하나입니다.
계획을 시작하기 전 고려해야 할 중요한 정보
이 문서를 최대한 활용하려면 다음을 수행해야 합니다.
- Windows Server 2012 R2에 대한 성능 튜닝 지침을 읽고 이해했는지 확인합니다.
- Windows Server 플랫폼이 x64 기반 아키텍처임을 이해합니다. 또한 Active Directory 환경이 Windows Server 2003 x86(지원 수명 주기 종료 이후)에 설치되어 있고 1.5GB보다 작고 메모리에 쉽게 저장할 수 있는 DIT(디렉터리 정보 트리)가 있는 경우에도 이 문서의 지침이 계속 적용된다는 것을 이해해야 합니다.
- 용량 계획은 지속 프로세스이므로 빌드한 환경이 기대치를 얼마나 잘 충족하는지 정기적으로 검토해야 합니다.
- 하드웨어 비용이 변경됨에 따라 여러 하드웨어 수명 주기 동안 최적화가 발생한다는 것을 이해합니다. 예를 들어 메모리가 저렴해지면 코어당 비용이 감소하거나 다른 스토리지 옵션의 가격이 변경됩니다.
- 매일 사용량이 많은 시간대를 계획합니다. 30분 또는 시간 간격에 따라 계획을 수립하는 것을 권장합니다. 1시간보다 길게 간격을 설정하면 서비스가 실제 최대 용량에 도달하는 시점이 감춰질 수 있으며, 30분 미만의 간격을 설정하면 일시 증가가 실제보다 중요해 보이게 하는 부정확한 정보를 제공할 수 있습니다.
- 엔터프라이즈의 하드웨어 수명 주기 동안의 성장을 계획합니다. 이 계획에는 교차 방식으로 하드웨어를 업그레이드하거나 추가하는 전략이나 3~5년마다 완전히 새로 고침하는 전략이 포함될 수 있습니다. 성장 계획을 각각 사용하려면 Active Directory의 부하가 얼마나 커지는지 예측해야 합니다. 기록 데이터는 보다 정확하게 평가하는 데 도움이 될 수 있습니다.
- 내결함성을 계획합니다. 예상 N을 파생했으면 N - 1, N - 2, N - x를 포함하는 시나리오를 계획합니다.
성장 계획을 바탕으로 하나 이상의 서버를 손실해도 시스템이 최대 최대 용량 예상을 초과하지 않도록 조직의 필요에 따라 서버를 추가합니다.
또한 성장 및 내결함성 계획을 통합해야 합니다. 예를 들어 현재 배포에 부하를 지원하기 위해 DC(도메인 컨트롤러)가 하나 필요하지만 내년에 부하가 두 배로 증가하여 두 대의 DC를 수행해야 한다는 것을 알고 있지만 시스템에 내결함성을 지원할 수 있는 충분한 용량이 없습니다. 이러한 용량 부족을 방지하려면 세 개의 DC로 대신 시작하도록 계획해야 합니다. 예산에서 세 개의 DC를 허용하지 않는 경우, 두 개의 DC로 시작한 다음 3~6개월 후에 세 번째 DC를 추가할 계획입니다.
참고 항목
Active Directory 인식 애플리케이션을 추가하면 애플리케이션 서버 또는 클라이언트에서 부하가 오는지 여부에 관계없이 DC 부하에 눈에 띄는 영향을 미칠 수 있습니다.
세 부분으로 구성된 용량 계획 주기
계획 주기를 시작하기 전 조직에 필요한 서비스 품질을 결정해야 합니다. 이 문서의 모든 권장 사항 및 지침은 최적의 성능 환경을 위한 것입니다. 그러나 최적화가 불필요한 경우 선택적으로 완화할 수 있습니다. 예를 들어 조직에 더 높은 수준의 동시성 및 보다 일관된 사용자 환경이 필요하다면 데이터 센터 설정을 살펴봐야 합니다. 데이터 센터를 사용하면 중복성에 더 많은 주의를 기울이고 시스템 및 인프라 병목 상태를 최소화할 수 있습니다. 반면, 사용자가 소수인 위성 사무실의 배포를 계획하는 경우 하드웨어 및 인프라 최적화에 대해 걱정할 필요가 없으므로 저렴한 옵션을 선택할 수 있습니다.
다음으로 가상 머신 또는 물리적 머신을 사용할지 여부를 결정해야 합니다. 용량 계획 관점에서 볼 때 정답은 없습니다. 그러나 시나리오마다 사용할 다른 변수들을 제공한다는 점을 명심해야 합니다.
가상화 시나리오는 다음 두 가지 옵션을 제공합니다.
- 호스트당 게스트가 하나만 있는 직접 매핑.
- 호스트당 여러 게스트가 있는 공유 호스트 시나리오.
직접 매핑 시나리오를 실제 호스트와 동일하게 처리할 수 있습니다. 공유 호스트 시나리오를 선택하는 경우, 이후 섹션에서 고려해야 할 다른 변수를 소개합니다. 또한 공유 호스트는 시스템 성능 및 사용자 환경에 영향을 줄 수 있는 AD DS(Active Directory Domain Services)와 리소스를 두고 경쟁합니다.
이제 이러한 질문에 답변했으므로 용량 계획 주기 자체를 살펴보겠습니다. 용량 계획 주기마다 삼 단계 프로세스가 포함됩니다.
- 기존 환경을 측정하고, 시스템 병목 현상이 현재 있는 위치를 확인하며, 배포에 필요한 용량을 계획하는 데 필요한 환경 기본 사항을 가져옵니다.
- 용량 요구 사항에 따라 필요한 하드웨어를 결정합니다.
- 설정한 인프라가 사양 내에서 작동하고 있는지 모니터링하고 유효성을 검사합니다. 이 단계에서 수집하는 데이터는 용량 계획의 다음 주기에 대한 기준이 됩니다.
프로세스 적용
성능을 최적화하려면 다음 주요 구성 요소가 올바르게 선택되고 애플리케이션 부하에 맞게 조정되었는지 확인합니다.
- 메모리
- 네트워크
- 스토리지
- 프로세서
- Netlogon
AD DS에 대한 기본 스토리지 요구 사항 및 호환되는 클라이언트 소프트웨어의 일반적인 동작을 통해 최대 10,000~20,000명의 사용자가 있는 환경에서는 대부분의 최신 서버 클래스 시스템에서 해당 크기의 부하를 처리할 수 있으므로 물리적 하드웨어에 대한 용량 계획을 무시할 수 있습니다. 그러나 데이터 컬렉션 요약 테이블의 표에서는 기존 환경을 평가하여 올바른 하드웨어를 선택하는 방법을 설명합니다. 그 이후 섹션에서는 AD DS 관리자가 인프라를 평가하는 데 도움이 되는 하드웨어에 대한 기준 권장 사항 및 환경별 원칙에 대해 자세히 설명합니다.
계획하는 동안 유의해야 하는 기타 정보:
- 현재 데이터를 기준으로 하는 모든 크기 조정은 현재 환경에 대해서만 정확합니다.
- 예상 시 하드웨어의 수명 주기 동안 수요가 증가할 것으로 예상합니다.
- 현재 환경을 초과할지 아니면 수명 주기 동안 용량을 점진적으로 추가할지 결정하여 향후 성장을 수용합니다.
- 물리적 배포에 적용할 모든 용량 계획 원칙과 방법론도 가상화된 배포에도 적용됩니다. 그러나 가상화된 환경을 계획할 때는 도메인 관련 계획 또는 예상에 가상화 오버헤드를 추가해야 합니다.
- 용량 계획은 완벽하게 올바른 값이 아닌 예측이므로 완벽하게 정확할 것으로 기대하지 마세요. 항상 필요에 따라 용량을 조정하고 환경에 따라 작동하는지 지속적으로 유효성을 검사해야 합니다.
데이터 컬렉션 요약 테이블
다음 테이블에서는 하드웨어 예상을 결정하기 위한 조건을 나열하고 설명합니다.
작업 환경
| 구성 요소 | 추정 |
|---|---|
| 스토리지/데이터베이스 크기 | 각 사용자에게 40KB~60KB |
| RAM | 데이터베이스 크기 기본 운영 체제 권장 사항 제3자 애플리케이션 |
| 네트워크 | 1GB |
| CPU | 각 코어에 1,000명의 동시 사용자 |
상위 수준 평가 조건
| 구성 요소 | 평가 조건 | 계획 고려 사항 |
|---|---|---|
| 스토리지/데이터베이스 크기 | 오프라인 조각 모음 | |
| 스토리지/데이터베이스 성능 |
|
|
| RAM |
|
|
| 네트워크 |
|
|
| CPU |
|
|
| NetLogon |
|
|
계획
오랫동안 AD DS 크기 조정에 대한 일반적인 권장 사항은 데이터베이스 크기만큼 RAM을 넣는 것이었습니다. 이제 AD DS 환경과 이를 사용하는 에코시스템이 훨씬 더 커졌기 때문에 상황이 변화되었습니다. 컴퓨팅 성능이 향상되고 x86 아키텍처에서 x64로 전환하면 물리적 컴퓨터에서 AD DS를 실행하는 고객과 무관하게 성능을 위한 크기 조정의 미묘한 측면이 있었지만 가상화는 훨씬 더 큰 문제를 해결했습니다.
이러한 문제를 해결하기 위해 다음 섹션에서는 Active Directory의 서비스 요구 사항을 결정 및 계획하는 방법을 설명합니다. 환경의 물리적, 가상화 또는 혼합 여부에 관계없이 모든 환경에 이러한 지침을 적용할 수 있습니다. 성능을 최대화하려면 AD DS 환경을 프로세서에 최대한 근접하게 바인딩하는 것이 목표입니다.
RAM
RAM에 캐시할 수 있는 스토리지가 많을수록 디스크로 이동해야 할 필요성이 줄어듭니다. 서버 확장성을 최대화하기 위해 사용하는 최소 RAM 양은 현재 데이터베이스 크기, 총 시스템 값 크기, 운영 체제에 권장되는 양, 에이전트에 대한 공급업체 권장 사항(바이러스 백신 프로그램, 모니터링, 백업 등)의 합계와 같아야 합니다. 서버 수명 동안 향후 성장을 수용하기 위해 추가 RAM도 포함해야 합니다. 이러한 예상치는 데이터베이스 증가 및 환경 변화에 따라 변경됩니다.
RAM 최대화가 비용 효율적이지 않거나 불가능한 환경(예: 위성 위치) 또는 DIT(디렉터리 정보 트리)가 너무 큰 경우 스토리지로 건너뛰어 스토리지가 제대로 구성되었는지 확인합니다.
메모리 크기 조정에 고려해야 할 또 다른 중요한 사항은 페이지 파일의 크기 조정입니다. 디스크 크기 조정 시 메모리와 관련된 다른 모든 항목과 마찬가지로 디스크 사용량을 최소화하는 것이 목표입니다. 특히 페이징을 최소화하려면 RAM이 얼마나 많이 필요한가요? 다음 몇 가지 섹션에서는 이 질문에 대답하는 데 필요한 정보를 제공해야 합니다. AD DS 성능에 필수적으로 영향을 주지 않는 페이지 크기에 대한 다른 고려 사항은 운영 체제(OS) 권장 사항 및 메모리 덤프에 대한 시스템 구성입니다.
여러 복잡한 요인으로 인해 DC(도메인 컨트롤러)에 필요한 RAM 양을 결정하는 것이 쉽지 않을 수 있습니다.
- LSSAS(로컬 보안 기관 하위 시스템 서비스)가 메모리 압력 조건에서 RAM을 트리밍하여 인위적으로 요구 사항을 줄이기 때문에 기존 시스템이 항상 RAM 요구 사항을 신뢰할 수 있는 지표는 아닙니다.
- 개별 DC는 클라이언트가 관심 있는 데이터를 캐시하면 됩니다. 즉, 다양한 환경에 캐시된 데이터는 포함된 클라이언트의 종류에 따라 달라집니다. 예를 들어 Exchange Server가 있는 환경의 DC는 사용자만 인증하는 DC와는 다른 데이터를 수집합니다.
- 사례별로 각 DC에 대한 RAM을 평가하는 데 필요한 작업의 양은 종종 과도하며 환경의 변화에 따라 변경됩니다.
권장 사항의 기준은 보다 합리적인 의사 결정을 내리는 데 도움이 될 수도 있습니다.
- RAM에 더 많이 캐시할수록 디스크로 이동해야 할 필요성이 줄어듭니다.
- 스토리지는 컴퓨터에서 가장 느린 구성 요소입니다. 스핀들 기반 및 SSD 스토리지 미디어에 대한 데이터 액세스는 RAM에 대한 데이터 액세스보다 백만 배 느립니다.
RAM의 가상화 고려 사항
RAM을 최적화하는 목적은 디스크에 소요되는 시간을 최소화하는 것입니다. 또한 호스트에서 메모리 오버 커밋을 피해야 합니다. 가상화 시나리오에서 메모리 오버 커밋은 시스템이 실제 컴퓨터 자체에 있는 것보다 더 많은 RAM을 게스트에 할당하는 경우입니다. 오버 커밋은 자체적으로 문제가 되지 않지만 모든 게스트가 사용하는 총 메모리가 호스트 RAM의 기능을 초과하면 호스트가 페이지로 이동하게 됩니다. 페이징은 DC가 데이터를 가져오기 위해 NTDS.nit 또는 페이지 파일로 이동하거나 호스트가 RAM 데이터에 액세스하기 위해 디스크로 이동한 경우 성능 디스크 바인딩을 만듭니다. 결과적으로 이 프로세스는 성능과 전반적인 사용자 환경을 크게 줄입니다.
계산 요약 예제
| 구성 요소 | 예상 메모리(예) |
|---|---|
| 기본 운영 체제 권장 RAM(Windows Server 2008) | 2GB |
| LSASS 내부 작업 | 200MB |
| 모니터링 에이전트 | 100MB |
| 바이러스 백신 | 100MB |
| 데이터베이스(글로벌 카탈로그) | 8.5GB |
| 백업 실행을 위한 쿠션, 관리자가 영향 없이 로그온 | 1GB |
| 총계 | 12GB |
권장: 16GB
시간이 지나면서 데이터베이스에 더 많은 데이터가 추가되고 평균 서버 수명은 약 3~5년입니다. 333%의 증가 추정치에 따라 16GB는 물리적 서버에 배치할 적절한 양의 RAM입니다.
네트워크
이 섹션에서는 클라이언트 쿼리, 그룹 정책 설정 등을 포함한 배포에 필요한 총 대역폭 및 네트워크 용량을 평가하는 방법을 설명합니다. Network Interface(*)\Bytes Received/sec 및 Network Interface(*)\Bytes Sent/sec 데이터 성능 카운터를 사용하여 예상할 수 있는 데이터를 수집할 수 있습니다. 네트워크 인터페이스 카운터의 샘플 간격은 15분, 30분 또는 60분이어야 합니다. 이보다 낮으면 정확한 측정을 하기에는 휘발성이 너무 크고, 이보다 높으면 일일 최고치가 지나치게 원활하게 됩니다.
참고 항목
보통 DC에서 대부분의 네트워크 트래픽은 DC가 클라이언트 쿼리에 응답할 때 아웃바운드입니다. 결과적으로 이 섹션에서는 주로 아웃바운드 트래픽에 중점을 둡니다. 그러나 인바운드 트래픽에 대한 각 환경도 평가하는 것을 권장합니다. 이 문서의 지침을 사용하여 인바운드 네트워크 트래픽 요구 사항도 평가할 수 있습니다. 자세한 내용은 929851: Windows Vista 및 Windows Server 2008에서 TCP/IP의 기본 동적 포트 범위가 변경되었습니다를 참조하세요.
Bandwidth 요구 사항
네트워크 확장성에 대한 계획은 트래픽 양과 네트워크 트래픽의 CPU 부하라는 두 가지 범주를 다룹니다.
트래픽 지원을 위한 용량 계획 시 고려해야 할 두 가지가 있습니다. 먼저 DC 간에 얼마나 많은 Active Directory 복제 트래픽이 진행되는지 알아야 합니다. 둘째, 사이트 내 클라이언트-서버 트래픽을 평가해야 합니다. 사이트 내 트래픽은 주로 클라이언트에 다시 보내는 많은 양의 데이터를 기준으로 클라이언트에서 적은 양의 요청을 받습니다. 보통 100MB는 서버당 최대 5,000명의 사용자가 있는 환경에 충분합니다. 5,000명 이상의 사용자가 있는 환경에서는 1GB 네트워크 어댑터와 RSS(수신측 크기 조정) 지원을 대신 사용하는 것이 좋습니다.
특히 서버 통합 시나리오에서 사이트 내 트래픽 용량을 평가하려면 사이트의 모든 DC에서 Network Interface(*)\Bytes/sec 성능 카운터를 살펴보고 함께 추가한 다음 합계를 대상 DC 수로 나누어야 합니다. 이 숫자를 계산하는 쉬운 방법은 Windows 안정성 및 성능 모니터를 열고 누적 영역 보기를 보는 것입니다. 모든 카운터 크기가 동일하게 조정되었는지 확인합니다.
이 일반 규칙이 특정 환경에 적용되는지 확인하는 보다 복잡한 방법의 예제를 살펴보겠습니다. 이 예제에서는 다음과 같은 가정을 합니다.
- 목표는 가능한 한 적은 수의 서버로 사용 공간을 줄이는 것입니다. 한 서버가 부하를 전달한 다음 중복성을 위해 추가 서버를 배포하는 것이 좋습니다(n + 1 시나리오).
- 이 시나리오에서 현재 네트워크 어댑터는 100MB만 지원하며 전환된 환경에 있습니다.
- n 시나리오에서 최대 대상 네트워크 대역폭 사용률은 60%입니다(DC 손실).
- 각 서버에는 약 10,000개의 클라이언트가 연결되어 있습니다.
이제 Network Interface(*)\Bytes Sent/sec 카운터의 차트에서 이 예제 시나리오에 대해 말하는 내용을 살펴보겠습니다.
- 영업은 오전 5시 30분쯤 시작해서 오후 7시에 끝납니다.
- 가장 바쁜 기간은 오전 8시에서 오전 8시 15분까지이며, 가장 작업량이 많은 DC에서 초당 25바이트 이상 전송됩니다.
참고 항목
모든 성능 데이터는 기록되며, 오전 8시 15분에 최대 데이터 포인트는 오전 8:00부터 오전 8:15까지의 부하를 나타냅니다.
- 오전 4시 이전에 급증이 발생했으며, 가장 작업량이 많은 DC에서 초당 20바이트 이상이 전송되며, 이는 다른 표준 시간대의 부하 또는 백업과 같은 백그라운드 인프라 활동을 나타낼 수 있습니다. 오전 8시 피크가 이 활동을 초과하므로 관련이 없습니다.
- 사이트에는 5개의 DC가 있습니다.
- 최대 부하는 DC당 약 5.5MBps이며, 이는 100MB 연결의 44%를 나타냅니다. 이 데이터를 사용하면 오전 8시에서 오전 8시 15분 사이에 필요한 총 Bandwidth가 28MBps인 것으로 추정할 수 있습니다.
참고 항목
네트워크 인터페이스 송신/수신 카운터는 바이트 단위이지만 네트워크 Bandwidth는 비트 단위로 측정됩니다. 따라서 총 Bandwidth를 계산하려면 100MB ÷ 8 = 12.5MB 및 1GB ÷ 8 = 128MB를 수행해야 합니다.
데이터를 검토했으므로 어떤 결론을 내릴 수 있나요?
- 현재 환경은 60% 대상 사용률에서 n + 1 수준의 내결함성을 충족합니다. 하나의 시스템을 오프라인으로 전환하면 서버당 Bandwidth가 약 5.5MBps(44%)에서 약 7MBps(56%)로 이동합니다.
- 이전에 설명한 한 서버에 통합하는 목표에 따라 이러한 변경은 최대 대상 사용률과 100MB 연결의 사용률을 초과합니다.
- 1GB 연결을 사용하는 경우 이 값은 총 용량의 22%를 나타냅니다.
- n + 1 시나리오의 정상적인 작동 조건에서 클라이언트 로드는 서버당 약 14MBps 또는 총 용량의 11%에서 상대적으로 균등하게 분산됩니다.
- DC를 사용할 수 없는 동안 용량이 충분한지 확인하기 위해 서버당 정상 작동 대상은 약 30%의 네트워크 사용률 또는 서버당 38MBps입니다. 장애 조치 대상은 네트워크 사용률 60% 또는 서버당 72MBps입니다.
최종 시스템 배포에는 1GB 네트워크 어댑터와 해당 부하를 지원하는 네트워크 인프라에 연결되어 있어야 합니다. 네트워크 트래픽의 양 때문에 네트워크 통신의 CPU 부하가 AD DS의 최대 확장성을 잠재적으로 제한할 수 있습니다. 이 동일한 프로세스를 사용하여 DC에 대한 인바운드 통신을 예측할 수 있습니다. 그러나 대부분의 시나리오에서는 아웃바운드 트래픽보다 적기 때문에 인바운드 트래픽을 계산할 필요가 없습니다.
하드웨어가 서버당 5,000명 이상의 사용자가 있는 환경에서 RSS를 지원하는지 확인해야 합니다. 네트워크 트래픽이 많은 시나리오에서 인터럽트 부하 분산은 병목 현상일 수 있습니다. Processor(*)\% Interrupt Time 카운터를 확인하여 잠재적인 병목 상태를 감지하여 중단 시간이 CPU에 고르지 않게 분산되는지 확인할 수 있습니다. RSS 지원 NIC(네트워크 인터페이스 컨트롤러)는 이러한 제한을 완화하고 확장성을 높일 수 있습니다.
참고 항목
데이터 센터를 통합하거나 위성 위치에서 DC를 사용 중지할 경우 더 많은 용량이 필요한지 예측하는 비슷한 방법을 사용할 수 있습니다. 필요한 용량을 예측하려면 클라이언트에 대한 아웃바운드 및 인바운드 트래픽에 대한 데이터를 살펴보면 됩니다. 그 결과 트래픽의 양이 WAN(광역 네트워크) 링크에 생성됩니다.
경우에 따라 인증서 검사가 WAN에서 과도한 시간 초과를 충족하지 못하는 경우와 같이 트래픽이 느리기 때문에 예상보다 많은 트래픽이 발생할 수 있습니다. 이러한 이유로 WAN 크기 조정 및 사용률은 반복적이고 지속적인 프로세스여야 합니다.
네트워크 Bandwidth에 대한 가상화 고려 사항
물리적 서버에 대한 일반적인 권장 사항은 5,000명 이상의 사용자를 지원하는 서버의 경우 1GB입니다. 여러 게스트가 기본 가상 스위치 인프라를 공유하기 시작하면 호스트에 시스템의 모든 게스트를 지원하기에 적절한 네트워크 Bandwidth가 있는지 여부에 주의해야 합니다. 네트워크 트래픽이 가상 스위치를 통해 이동하거나 실제 스위치에 직접 연결된 호스트에서 VM으로 실행되는 DC가 네트워크에 포함되는지 여부에 상관없이 대역폭을 고려해야 합니다. 가상 스위치는 업링크가 연결에서 전송하는 데이터의 양을 지원해야 하는 구성 요소입니다. 즉, 스위치에 연결된 실제 호스트 네트워크 어댑터가 DC 부하와 실제 네트워크 어댑터에 연결된 가상 스위치를 공유하는 다른 모든 게스트를 지원할 수 있어야 합니다.
네트워크 계산 요약 예제
다음 테이블에는 네트워크 용량을 계산하는 데 사용할 수 있는 예제 시나리오의 값이 포함되어 있습니다.
| 시스템 | 최대 대역폭 |
|---|---|
| DC 1 | 6.5MBps |
| DC 2 | 6.25MBps |
| DC 3 | 6.25MBps |
| DC 4 | 5.75MBps |
| DC 5 | 4.75MBps |
| 총계 | 28.5MBps |
이 테이블에 따라 권장되는 대역폭은 72MBps(28.5MBps ÷ 40%)입니다.
| 대상 시스템 수 | 총 Bandwidth(위부터) |
|---|---|
| 2 | 28.5MBps |
| 정상적인 동작의 결과 | 28.5 ÷ 2 = 14.25MBps |
언제나처럼 시간이 지남에 따라 클라이언트 부하가 증가한다고 가정해야 하므로 가능한 한 빠르게 이 증가를 계획해야 합니다. 최소 50%의 예상 네트워크 트래픽 증가를 계획하는 것을 권장합니다.
스토리지
스토리지 용량을 계획할 때 고려해야 할 두 가지가 있습니다.
- 용량 또는 스토리지 크기
- 성능
용량이 중요하지만 성능도 무시할 수 없을만큼 중요합니다. 현재 하드웨어 비용으로는 대부분의 환경에서 두 가지 요소 중 하나가 주요 관심사가 될 만큼 충분히 크지 않습니다. 따라서 일반적으로 데이터베이스 크기만큼 RAM을 넣는 것을 권장합니다. 그러나 이러한 권장 사항은 더 큰 환경의 위성 위치에 비해 과용될 수 있습니다.
크기 조정
스토리지 평가
4GB 및 9GB 드라이브가 가장 일반적인 드라이브 크기였던 시기와 Active Directory가 처음 도입된 시기를 비교했을 때, 이제는 Active Directory의 크기 조정이 가장 큰 환경을 제외한 모든 환경에 대한 고려 사항도 아닙니다. 180GB 범위에서 사용 가능한 가장 작은 하드 드라이브 크기를 사용하면 전체 운영 체제, SYSVOL, NTDS.dit가 하나의 드라이브에 쉽게 맞을 수 있습니다. 그러므로 이 영역에 너무 많이 투자하지 않는 것이 좋습니다.
유일한 권장 사항은 스토리지를 조각 모음할 수 있도록 NTS.dit 크기의 110%를 사용할 수 있게 하는 것입니다. 그 외에도 향후 성장을 수용하는 데 일반적인 고려 사항들이 있습니다.
스토리지를 평가하려는 경우, 먼저 NTDS.dit 및 SYSVOL의 크기가 얼마나 커야 하는지 평가해야 합니다. 이러한 측정값은 고정 디스크 및 RAM 할당의 크기를 모두 조정하는 데 도움이 됩니다. 구성 요소는 상대적으로 비용이 저렴하기 때문에 계산할 때 매우 정확할 필요가 없습니다. 스토리지 평가에 대한 자세한 내용은 스토리지 제한 및 Active Directory 사용자 및 조직 단위에 대한 증가 예상치를 참조하세요.
참고 항목
이전 단락에 연결된 문서는 Windows 2000에서 Active Directory의 릴리스 동안 수행한 데이터 크기 추정치를 기반으로 합니다. 사용자 고유의 예상을 만들 때, 사용자 환경에서 개체의 실제 크기를 반영하는 개체 크기를 사용합니다.
여러 도메인이 있는 기존 환경을 검토할 때 데이터베이스 크기가 변하는 것을 확인할 수 있습니다. 이러한 변형을 발견하면 가장 작은 GC(글로벌 카탈로그) 및 GC가 아닌 크기를 이용합니다.
데이터베이스 크기는 OS 버전마다 다를 수 있습니다. Windows Server 2003과 같은 이전 OS 버전을 실행하는 DC의 데이터베이스 크기는 Windows Server 2008 R2와 같은 이후 버전을 실행하는 DC보다 작습니다. Active Directory REcycle Bin 또는 자격 증명 로밍과 같은 기능을 사용하는 DC는 데이터베이스 크기에도 영향을 줄 수 있습니다.
참고 항목
- 새 환경에서는 동일한 도메인에 있는 100,000명의 사용자가 약 450MB의 공간을 사용합니다. 채우는 특성은 사용된 총 공간 양에 큰 영향을 미칠 수도 있습니다. 특성은 Microsoft Exchange Server 및 Lync를 비롯한 타사 제품과 Microsoft 제품의 많은 개체들로 채워집니다. 따라서 환경의 제품 포트폴리오를 기준으로 평가하는 것이 좋습니다. 그러나 가장 큰 환경을 제외한 모든 환경의 정확한 추정에 대한 계산 및 테스트를 수행하는 것은 상당한 시간이나 노력의 가치가 없을 수 있음을 명심해야 합니다.
- 사용 가능한 여유 공간이 NTDS.dit 크기의 110%인지 확인하여 오프라인 조각 모음을 사용 설정합니다. 이 여유 공간으로 서버의 3~5년 하드웨어 수명 동안의 성장을 계획할 수도 있습니다. 스토리지가 있는 경우, 스토리지용 DIT의 300%에 해당하는 여유 공간을 할당하는 것이 증가 및 배출을 수용하는 안전한 방법입니다.
스토리지에 대한 가상화 고려 사항
단일 볼륨에 여러 VHD(가상 하드 디스크) 파일을 할당하는 경우 DIT 크기(DIT의 100% + 여유 공간 110%)의 210% 이상의 고정 상태 디스크를 사용하여 요구 사항에 맞게 충분한 공간을 확보해야 합니다.
스토리지 계산 요약 예제
다음 테이블에서는 가상 스토리지 시나리오의 공간 요구 사항을 예측하는 데 사용하는 값을 나열합니다.
| 평가 단계에서 수집된 데이터 | 크기 |
|---|---|
| NTDS.dit 크기 | 35GB |
| 오프라인 조각 모음을 허용하는 한정자 | 2.1GB |
| 필요한 총 스토리지 | 73.5GB |
참고 항목
스토리지 예측에는 SYSVOL, OS, 페이지 파일, 임시 파일, 설치 관리자 파일 등의 로컬 캐시된 데이터 및 애플리케이션에 필요한 스토리지의 양도 포함되어야 합니다.
스토리지 성능
모든 컴퓨터 내에서 가장 느린 구성 요소인 스토리지는 클라이언트 환경에 부정적인 영향을 가장 많이 미칠 수 있습니다. 이 문서의 RAM 크기 조정 권장 사항을 실현할 수 없을 정도로 큰 환경의 경우 스토리지 용량 계획을 간과하면 시스템 성능이 저하될 수 있습니다. OS, 로그, 데이터베이스를 별도의 실제 디스크에 배치하는 일반적인 권장 사항이 모든 시나리오에서 보편적으로 적용되지 않기 때문에 사용 가능한 스토리지 기술의 복잡성과 종류는 위험을 더욱 높입니다.
디스크에 대한 이전 권장 사항에서는 디스크가 격리된 I/O를 허용하는 전용 스핀들이라고 가정했습니다. 이 가정에서는 다음 스토리지 유형이 도입되어 더 이상 true가 아닙니다.
- RAID
- 새 스토리지 유형 및 가상화 및 공유 스토리지 시나리오
- SAN(스토리지 영역 네트워크)의 공유 스핀들
- SAN 또는 네트워크 연결 스토리지의 VHD 파일
- 반도체 드라이브(SSDs)
- 더 큰 스핀들 기반 스토리지를 캐싱하는 SSD 스토리지 계층과 같은 계층화된 스토리지 아키텍처
RAID, SAN, NAS, JBOD, 스토리지 공간, VHD와 같은 공유 스토리지는 백엔드 스토리지에 배치하는 다른 워크로드에 의해 오버로드될 수 있습니다. 또한 이러한 스토리지 유형은 물리적 디스크와 AD 애플리케이션 간의 SAN, 네트워크 또는 드라이버 문제로 인해 제한 및 지연이 발생할 수 있습니다. 명확히 하자면 이러한 구성은 나쁜 구성은 아니지만 더 복잡하므로 모든 구성 요소가 의도한 대로 작동하는지 확인하기 위해 각별한 주의를 기울여야 합니다. 자세한 설명은 이 문서의 뒷부분에 있는 부록 C 및 부록 D를 참조하세요. 또한 SSD는 한 번에 하나의 I/O만 처리할 수 있는 하드 드라이브로 인해 제한되지 않지만 여전히 오버로드할 수 있는 I/O 제한이 있습니다.
요약하자면, 스토리지 아키텍처에 상관없이 모든 스토리지 성능 계획의 목표는 필요한 수의 I/O를 항상 사용할 수 있고 허용 가능한 기간 내에 수행되도록 하는 것입니다. 로컬로 연결된 스토리지가 있는 시나리오의 경우 설계 및 계획에 대한 자세한 내용은 부록 C를 참조하세요. 백엔드 스토리지 솔루션을 지원하는 공급업체와의 대화뿐만 아니라 더 복잡한 스토리지 시나리오에 부록의 원칙을 적용할 수 있습니다.
현재 사용 가능한 스토리지 옵션의 수로 인해 솔루션이 AD DS 배포의 요구 사항을 충족하는지 확인하는 동안 하드웨어 지원팀 또는 공급업체에 문의하는 것이 좋습니다. 이러한 대화 중에는 특히 데이터베이스가 RAM에 비해 너무 큰 경우 다음 성능 카운터가 유용할 수 있습니다.
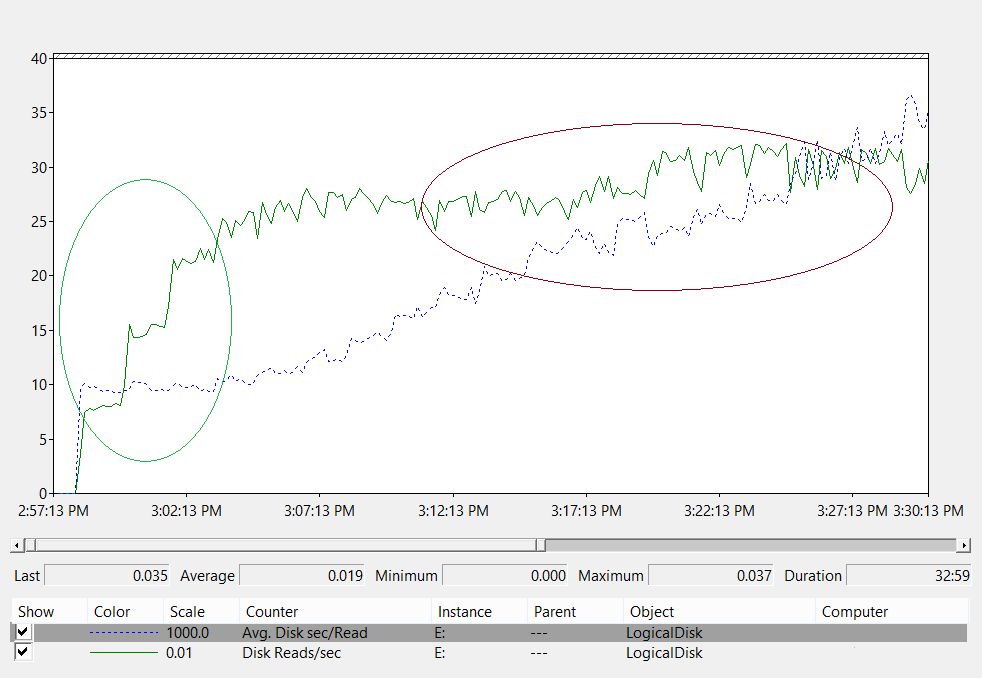
LogicalDisk(*)\Avg Disk sec/Read(예를 들어 NTDS.dit가 드라이브 D에 저장된 경우 전체 경로는LogicalDisk(D:)\Avg Disk sec/Read일 수 있습니다.)LogicalDisk(*)\Avg Disk sec/WriteLogicalDisk(*)\Avg Disk sec/TransferLogicalDisk(*)\Reads/secLogicalDisk(*)\Writes/secLogicalDisk(*)\Transfers/sec
데이터를 제공할 때는 15분, 30분 또는 60분 간격으로 샘플링되어 현재 환경을 가장 정확하게 파악할 수 있게 해야 합니다.
결과 평가
이 섹션에서는 데이터베이스가 일반적으로 가장 까다로운 구성 요소이므로 데이터베이스의 읽기에 중점을 둡니다. <NTDS Log>)\Avg Disk sec/Write 및 LogicalDisk(<NTDS Log>)\Writes/sec)을(를) 대체하여 로그 파일에 쓰기에 동일한 논리를 적용할 수 있습니다.
LogicalDisk(<NTDS>)\Avg Disk sec/Read 카운터는 현재 스토리지의 크기가 적절한지 여부를 보여 줍니다. 값이 디스크 유형의 예상 디스크 액세스 시간과 거의 같으면 LogicalDisk(<NTDS>)\Reads/sec 카운터는 유효한 측정값입니다. 결과가 디스크 유형의 디스크 액세스 시간과 거의 같으면 LogicalDisk(<NTDS>)\Reads/sec 카운터는 유효한 측정값입니다. 백엔드 스토리지의 제조업체 사양에 따라 변경될 수 있지만 대략적인 LogicalDisk(<NTDS>)\Avg Disk sec/Read 범위는 다음과 같습니다.
- 7200rpm: 9~12.5밀리초(ms)
- 10,000rpm: 6 ~ 10ms
- 15,000rpm: 4 ~ 6ms
- SSD – 1 ~ 3ms
다른 원본에서 스토리지 성능이 15ms에서 20ms로 저하되었다는 소식을 들을 수 있습니다. 해당 값과 이전 목록의 값 간의 차이점은 목록 값이 정상 작동 범위를 표시한다는 점입니다. 다른 값은 문제 해결용이며, 이는 클라이언트 환경이 눈에 띄게 될 정도로 성능이 저하된 시기를 식별하는 데 도움이 됩니다. 자세한 내용은 부록 C를 참조하세요.
LogicalDisk(<NTDS>)\Reads/sec은(는) 시스템이 현재 수행하고 있는 I/O의 양입니다.LogicalDisk(<NTDS>)\Avg Disk sec/Read이(가) 백엔드 스토리지의 최적 범위 내에 있는 경우, 스토리지 크기를 조정하는 데LogicalDisk(<NTDS>)\Reads/sec을(를) 직접 사용할 수 있습니다.LogicalDisk(<NTDS>)\Avg Disk sec/Read이(가) 백엔드 스토리지의 최적 범위 내에 있지 않은 경우,LogicalDisk(<NTDS>)\Avg Disk sec/Read÷ 물리적 미디어 디스크 액세스 시간 ×LogicalDisk(<NTDS>)\Avg Disk sec/Read수식에 따라 추가 I/O가 필요합니다.
이러한 계산을 수행할 때 고려해야 할 사항은 다음과 같습니다.
- 서버에 최적 이하의 RAM이 있는 경우, 결과 값이 너무 높아서 계획에 유용할 만큼 정확하지 않습니다. 그러나 여전히 최악의 시나리오를 예측하는 데 사용할 수 있습니다.
- RAM을 추가하거나 최적화하는 경우, 읽기 I/O
LogicalDisk(<NTDS>)\Reads/Sec양도 감소합니다. 이렇게 감소하면 스토리지 솔루션이 원래 계산에서 추측한 만큼 강력하지 않을 수도 있습니다. 안타깝게도 계산은 개별 환경, 특히 클라이언트 부하에 따라 크게 달라지기 때문에 이 명령문의 의미에 대해 더 구체적으로 설명할 수 없습니다. 그러나 RAM을 최적화한 후 스토리지 크기를 조정하는 것을 권장합니다.
성능에 대한 가상화 고려 사항
이전 섹션과 마찬가지로 여기서의 목표는 공유 인프라가 모든 소비자의 총 부하를 지원할 수 있게 하는 것입니다. 다음 시나리오를 계획할 때 이 목표를 염두에 두어야 합니다.
- SAN, NAS 또는 iSCSI 인프라에서 다른 서버 또는 애플리케이션과 동일한 미디어를 공유하는 물리적 CD.
- 미디어를 공유하는 SAN, NAS 또는 iSCSI 인프라에 대한 통과 액세스를 이용하는 사용자입니다.
- 공유 미디어의 VHD 파일을 로컬로 사용하거나 SAN, NAS 또는 iSCSI 인프라를 이용하는 사용자.
게스트 사용자의 관점에서 스토리지에 액세스하기 위해 호스트를 통과해야 하는 경우, 사용자가 액세스 권한을 얻기 위해 추가 코드 경로를 따라 이동해야 하므로 성능에 영향을 줍니다. 성능 테스트는 호스트 시스템이 활용하는 프로세서의 양에 따라 가상화가 처리량에 영향을 미친다는 점을 나타냅니다. 또한 프로세서 활용률을 게스트 사용자가 호스트에 요구하는 리소스 수의 영향을 받습니다. 이러한 요구는 가상화된 시나리오에서 처리 요구 사항에 대해 수행해야 하는 처리를 위한 가상화 고려 사항에 영향을 줍니다. 자세한 내용은 부록 A를 참조하세요.
더 복잡한 문제는 현재 사용할 수 있는 스토리지 옵션의 수이며, 이는 각각 성능에 큰 영향을 미칩니다. 이러한 옵션에는 통과 스토리지, SCSI 어댑터, IDE가 포함됩니다. 물리적 환경에서 가상 환경으로 마이그레이션할 때 승수 1.10을 사용하여 가상화된 게스트 사용자에 대해 다양한 스토리지 옵션을 조정해야 합니다. 그러나 스토리지가 로컬인지, SAN인지, NAS인지 여부에 따라 또는 iSCSI가 더 중요하기 때문에 다른 스토리지 시나리오 간에 전송할 때 조정을 고려할 필요가 없습니다.
가상화 계산 예제
정상 작동 조건에서 정상 시스템에 필요한 I/O 양을 결정합니다.
- LogicalDisk(
<NTDS Database Drive>) ÷ 피크 기간 15분 동안 초당 전송 - 기본 스토리지의 용량이 초과되는 스토리지에 필요한 I/O 양을 확인하기 위해 다음을 수행합니다.
필요한 IOPS = (LogicalDisk(
<NTDS Database Drive>)) ÷ 평균 디스크 읽기/초 ÷<Target Avg Disk Read/sec>) × LogicalDisk(<NTDS Database Drive>)\읽기/초
| 카운터 | 값 |
|---|---|
실제 LogicalDisk(<NTDS Database Drive>)\평균 디스크 초/전송 |
0.02초(20밀리초) |
대상 LogicalDisk(<NTDS Database Drive>)\평균 디스크 초/전송 |
0.01초 |
| 이용 가능한 I/O의 변경에 대한 승수 | 0.02 ÷ 0.01 = 2 |
| 값 이름 | 값 |
|---|---|
LogicalDisk(<NTDS Database Drive>)\전송/초 |
400 |
| 이용 가능한 I/O의 변경에 대한 승수 | 2 |
| 사용량이 많은 기간 동안 필요한 총 IOPS | 800 |
캐시를 웜해야 하는 속도를 확인하려면 다음을 수행해야 합니다.
- 캐시 온난화에 사용할 수 있는 최대 시간을 결정합니다. 일반적인 시나리오에서 허용되는 시간은 디스크에서 전체 데이터베이스를 로드하는 데 걸리는 시간입니다. RAM이 전체 데이터베이스를 로드할 수 없는 경우 전체 RAM을 채우는 데 걸리는 시간을 사용합니다.
- 사용하지 않을 공간을 제외하고 데이터베이스 크기를 결정합니다. 자세한 내용은 스토리지 평가를 참조하세요.
- 데이터베이스 크기를 8KB로 나누어 데이터베이스를 로드하는 데 필요한 총 I/O 수를 가져옵니다.
- 총 I/O를 지정된 시간 프레임의 초 수로 나눕니다.
계산되는 숫자는 대부분 정확하지만 고정 캐시 크기를 ESE로 구성하지 않았기 때문에 부정확할 수 있으며(확장 가능한 스토리지 엔진), 기본적으로 변수 캐시 크기를 사용하므로 AD DS는 이전에 로드한 페이지를 제거합니다.
| 수집할 데이터 포인트 | 값 |
|---|---|
| 웜할 수 있는 최대 시간 | 10분(600초) |
| 데이터베이스 크기 | 2GB |
| 계산 단계 | 수식 | 결과 |
|---|---|---|
| 페이지의 데이터베이스 크기 계산 | (2 GB × 1024 × 1024) = KB의 데이터베이스 크기 | 2,097,152 KB |
| 데이터베이스의 페이지 수 계산 | 2,097,152 KB ÷ 8 KB = 페이지 수 | 262,144페이지 |
| 캐시를 완전히 웜하는 데 필요한 IOPS 계산 | 262,144페이지 ÷ 600초 = IOPS 필요 | 437 IOPS |
처리
Active Directory 프로세서 사용량 평가
처리 용량을 관리하는 것이 대부분의 환경에서 가장 주의를 기울여야 하는 구성 요소입니다. 배포에 필요한 CPU 용량을 평가하는 경우, 다음 두 가지를 고려해야 합니다.
- 환경의 애플리케이션은 비용이 많이 들고 비효율적인 검색 추적에 설명된 기준에 따라 공유 서비스 인프라 내에서 의도한 대로 작동합니까? 더 큰 환경에서 제대로 코딩되지 않은 애플리케이션은 CPU 부하를 휘발성으로 만들고, 다른 애플리케이션을 희생하여 CPU 시간을 너무 많이 사용하며, 용량 요구를 높이고, DC에 부하를 고르지 않게 분산할 수 있습니다.
- AD DS는 처리 요구 사항이 매우 다양한, 잠재적 클라이언트가 많은 분산 환경입니다. 각 클라이언트의 예상 비용은 사용 패턴 및 AD DS를 사용하는 애플리케이션 수에 따라 달라질 수 있습니다. 네트워크와 마찬가지로 각 클라이언트를 한 번에 하나씩 보는 대신 환경에서 필요한 총 용량을 평가하기 위해 접근해야 합니다.
프로세서 부하에 대한 유효한 데이터 없이는 정확한 추측을 수행할 수 없으므로 스토리지 예상을 완료한 후에만 이 예상을 수행해야 합니다. 프로세서 문제를 해결하기 전에 스토리지로 인해 병목 현상이 발생하지 않도록 하는 것도 중요합니다. 프로세서 대기 상태를 제거하면 더 이상 데이터를 기다릴 필요가 없기 때문에 CPU 사용률이 증가합니다. 따라서 가장 주의를 기울여야 하는 성능 카운터는 Logical Disk(<NTDS Database Drive>)\Avg Disk sec/Read 및 Process(lsass)\ Processor Time입니다. Logical Disk(<NTDS Database Drive>)\Avg Disk sec/Read 카운터가 10밀리초 또는 15밀리초를 초과하면 Process(lsass)\ Processor Time 데이터가 인위적으로 낮아지고 스토리지 성능과 관련된 문제가 발생합니다. 가장 정확한 데이터를 위해 샘플 간격을 15, 30 또는 60분으로 설정하는 것을 권장합니다.
처리 개요
도메인 컨트롤러에 대한 용량 계획을 계획하려면 처리 능력을 잘 알고 있어야 합니다. 최대 성능을 보장하기 위해 시스템 크기를 조정하는 경우, 항상 병목 상태인 구성 요소가 있으며, 적절한 크기의 도메인 컨트롤러에서 이 구성 요소는 프로세서입니다.
환경의 수요를 사이트별로 검토하는 네트워킹 섹션과 마찬가지로 요구되는 컴퓨팅 용량에 동일한 작업을 수행해야 합니다. 사용 가능한 네트워킹 기술이 일반 수요를 훨씬 초과하는 네트워킹 섹션과 달리 CPU 용량 크기 조정에 더 많이 주의를 기울입니다. 중간 크기의 모든 환경, 1,000명이 넘는 동시 사용자가 CPU에 상당한 부하를 부과할 수 있습니다.
아쉽게도 AD를 활용하는 클라이언트 애플리케이션의 엄청난 가변성으로 인해 CPU당 사용자의 일반적인 추정치는 모든 환경에 비참하게 적용할 수 없습니다. 특히 컴퓨팅 요구 사항은 사용자 동작 및 애플리케이션 프로필의 적용을 받습니다. 따라서 각 환경의 크기를 개별 조정해야 합니다.
대상 사이트 동작 프로필
전체 사이트에 대한 용량 계획인 경우 목표는 N + 1 용량 설계여야 합니다. 이 설계에서는 사용량이 많은 기간 동안 하나의 시스템이 실패하더라도 서비스를 허용 가능한 품질 수준으로 계속 진행할 수 있습니다. N 시나리오에서 모든 상자의 로드는 사용량이 많은 기간 동안 80%~100% 미만이어야 합니다.
또한 사이트의 애플리케이션 및 클라이언트는 DC를 찾기 위해 권장되는 DsGetDcName 함수 메서드를 사용하며, 이를 사소한 일시적인 급증만 사용하여 균등하게 배포되어야 합니다.
이제 대상 및 오프 대상에 있는 환경의 두 가지 예를 살펴보겠습니다. 먼저 의도한 대로 작동하고 용량 계획 목표를 초과하지 않는 환경의 예제를 살펴보겠습니다.
첫 번째 예제에서는 다음을 가정합니다.
- 사이트의 5개 DC 각각에는 CPU가 4개 있습니다.
- 업무 시간 동안 총 대상 CPU 사용량은 정상 작동 조건(N + 1)에서 40%이고, 그렇지 않을 경우 60%(N)입니다. 업무 외 시간에는 백업 소프트웨어 및 기타 유지 관리 프로세스가 사용 가능한 모든 리소스를 사용할 것으로 예상하기 때문에 대상 CPU 사용량은 80%입니다.
이제 다음 이미지와 같이 각 DC에 대한 (Processor Information(_Total)\% Processor Utility) 차트를 살펴보겠습니다.
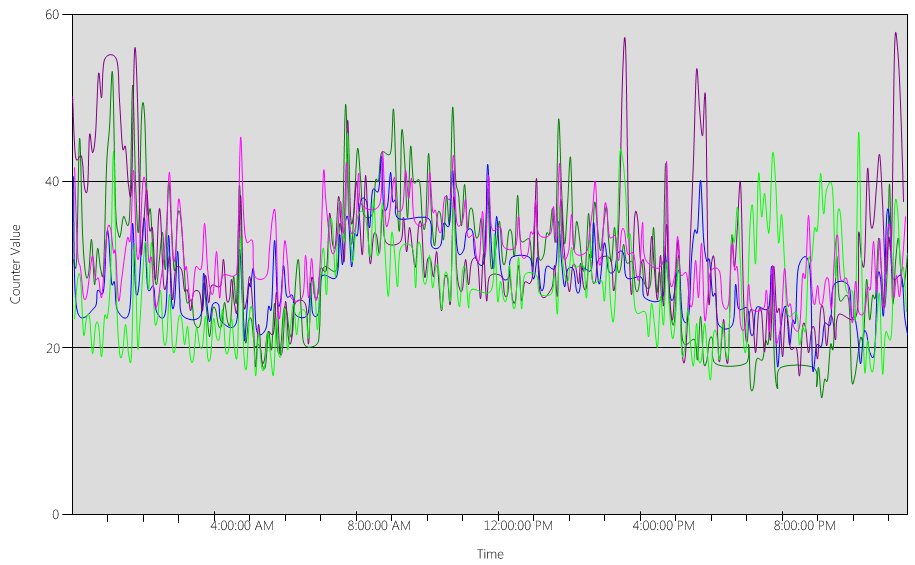
부하는 상대적으로 균등하게 분산되므로 클라이언트가 DC 로케이터 및 작성이 잘 된 검색을 사용할 때 예상되는 것입니다.
몇 가지 5분 간격으로 10%, 때로는 20%로 급증합니다. 하지만 이러한 급증으로 인해 CPU 사용량이 용량 계획 목표를 초과하지 않는 한 조사할 필요가 없습니다.
모든 시스템의 피크 기간은 오전 8:00에서 오전 9:15 사이입니다. 평균 영업일은 오전 5:00부터 오후 5:00까지입니다. 따라서 오후 5시에서 오전 4시 사이에 발생하는 임의로 급증하는 CPU 사용량은 업무 시간 외이므로 용량 계획 문제에 포함할 필요가 없습니다.
참고 항목
잘 관리되는 시스템에서는 사용량이 많은 기간 동안 발생하는 급증은 일반적으로 백업 소프트웨어, 전체 시스템 바이러스 백신 검사, 하드웨어 또는 소프트웨어 인벤토리, 소프트웨어 또는 패치 배포 등으로 인해 발생합니다. 이러한 급증은 업무 시간 외에 발생하므로 용량 계획 목표를 초과하는 것으로 계산되지 않습니다.
각 시스템은 약 40%이고 모두 동일한 수의 CPU를 가지고 있으므로 그 중 하나가 오프라인 상태가 되면 나머지 시스템은 약 53%로 실행됩니다. 시스템 D에는 균등하게 분할되어 System A 및 C의 기존 40% 부하에 추가되는 40% 부하가 있습니다. 이 선형 가정은 완벽하게 정확하지는 않지만 측정하기에 충분한 정확도를 제공합니다.
다음으로, CPU 사용량이 좋지 않고 용량 계획 목표를 초과하는 환경의 예를 살펴보겠습니다.
이 예제에서는 40%에서 실행되는 두 개의 DC가 있습니다. 한 도메인 컨트롤러가 오프라인 상태가 되어 나머지 DC의 예상 CPU 사용량이 80%에 도달합니다. 이 수준의 CPU 사용량은 용량 계획의 임계값을 훨씬 초과하며, 부하 프로필의 10%에서 20%까지 헤드룸의 양을 제한하기 시작합니다. 결과적으로, 모든 스파이크는 잠재적으로 N 시나리오 동안 DC를 90% 또는 심지어 100%로 유도하여 응답성을 감소시킬 수 있습니다.
CPU 요구 계산
Process\% Processor Time 성능 카운터는 모든 애플리케이션 스레드가 CPU에 소비하는 총 시간을 추적한 다음, 해당 합계를 경과된 총 시스템 시간으로 나눕니다. 다중 CPU 시스템의 다중 스레드 애플리케이션은 100% CPU 시간을 초과할 수 있으며, Processor Information\% Processor Utility 카운터와는 매우 다르게 데이터를 해석합니다. 실제로 Process(lsass)\% Processor Time 카운터는 시스템에서 프로세스의 요구를 지원하는 데 필요한 CPU 수를 100%로 추적합니다. 예를 들어 카운터의 값이 200%인 경우 전체 AD DS 로드를 지원하려면 시스템에서 100%에서 실행되는 두 개의 CPU가 필요합니다. 100% 용량으로 실행되는 CPU가 전력 및 에너지 소비 측면에서 가장 비용 효율적이지만 부록 A에 설명된 이유로 인해 시스템이 100%에서 실행되지 않을 때 다중 스레드 시스템이 더 반응합니다.
클라이언트 부하의 일시적인 급증을 수용하려면 시스템 용량의 40%에서 60% 사이의 최고 기간 CPU를 대상으로 하는 것을 권장합니다. 예를 들어 대상 사이트 동작 프로필의 첫 번째 예제에서는 AD DS 로드를 지원하려면 3.33 CPU(60% 대상)와 5개의 CPU(40% 대상) 사이가 필요합니다. OS 및 기타 필수 에이전트(예: 바이러스 백신, 백업, 모니터링 등)의 요구에 따라 용량을 추가해야 합니다. 환경별로 CPU 에이전트에 대한 에이전트의 영향을 평가해야 하지만 보통 단일 CPU에서 에이전트 프로세스의 경우 5%에서 10% 사이를 할당할 수 있습니다. 이 예제를 다시 보기 위해, 사용량이 많은 기간 동안 부하를 지원하려면 3.43(60% 목표)에서 5.1(40% 대상) CPU가 필요합니다.
이제 특정 프로세스에 대한 계산 예제를 살펴보겠습니다. 이 경우 LSASS 프로세스를 살펴봅니다.
LSASS 프로세스에 대한 CPU 사용량 계산
이 예제에서 시스템은 중복성을 위해 추가 서버가 있는 동안 한 서버가 AD DS 로드를 수행하는 N + 1 시나리오입니다.
다음 차트에서는 이 예제 시나리오의 모든 프로세서 전반의 LSASS 프로세스의 프로세서 시간을 보여 줍니다. 이 데이터는 Process(lsass)\% Processor Time 성능 카운터에서 수집되었습니다.
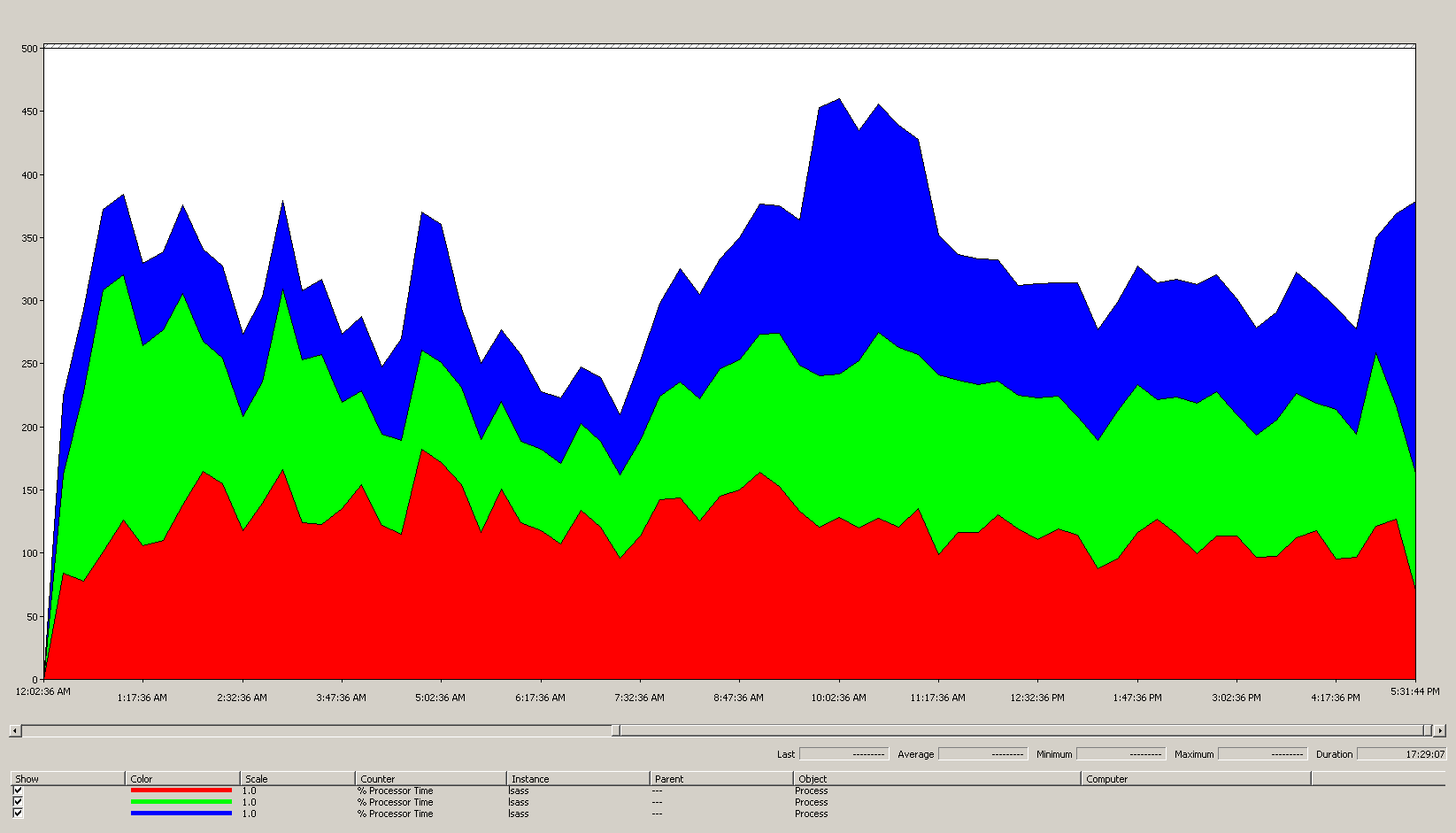
다음은 이 차트에서 시나리오 환경에 대해 알려주는 내용입니다.
- 사이트에는 세 개의 도메인 컨트롤러가 있습니다.
- 영업일은 오전 7시경에 시작하여 오후 5시에 종료됩니다.
- 하루 중 가장 바쁜 시간은 오전 9:30부터 오전 11:00까지입니다.
참고 항목
모든 성능 데이터는 기록됩니다. 오전 9시 15분의 최대 데이터 포인트는 오전 9시에서 오전 9시 15분까지의 부하를 나타냅니다.
- 오전 7시 이전의 급증은 다른 표준 시간대 또는 백업과 같은 백그라운드 인프라 작업의 추가 부하를 나타낼 수도 있습니다. 그러나 이 급증은 오전 9시 30분의 피크 활동보다 낮기 때문에 우려의 원인이 아닙니다.
최대 부하 시 lsass 프로세스는 100%에서 실행되는 약 4.85CPU를 사용하며 이는 단일 CPU에서 485%가 됩니다. 이러한 결과는 시나리오 사이트에서 AD DS를 처리하기 위해 약 12/25CPU가 필요하다는 점을 시사합니다. 백그라운드 프로세스에 권장되는 5%~10% 추가 용량을 가져오는 경우 서버는 현재 부하를 지원하기 위해 12.30~12.25CPU가 필요합니다. 향후 성장을 예상하는 예측은 이 숫자를 훨씬 더 높입니다.
LDAP 가중치를 조정하는 경우
LdapSrvWeight 튜닝을 고려해야 하는 특정 시나리오가 있습니다. 용량 계획의 컨텍스트에서 애플리케이션, 사용자 로드 또는 기본 시스템 기능이 균등하게 분산되지 않을 때 조정합니다.
다음 섹션에서는 LDAP(Lightweight Directory Access Protocol) 가중치를 조정해야 하는 두 가지 예제 시나리오에 대해 설명합니다.
예제 1: PDC 에뮬레이터 환경
PDC(기본 도메인 컨트롤러) 에뮬레이터를 사용하는 경우, 고르지 않게 분산된 사용자 또는 애플리케이션 동작이 한 번에 여러 환경에 영향을 줄 수 있습니다. PDC 에뮬레이터의 CPU 리소스는 그룹 정책 관리 도구, 이차 인증 시도, 신뢰 설정 등과 같은 여러 도구와 작업이 대상을 지정하기 때문에 배포의 다른 곳보다 더 많은 요구가 많이 발생합니다.
- CPU 사용률에 크게 차이가 있는 경우에만 PDC 에뮬레이터를 조정해야 합니다. 튜닝은 PDC 에뮬레이터의 부하를 줄이고 다른 DC의 부하를 늘려 부하 분산을 더 많이 허용해야 합니다.
- 이 경우 PDC 에뮬레이터에 대해 50에서 75 사이의
LDAPSrvWeight값을 설정합니다.
| 시스템 | 기본값을 사용하는 CPU 사용률 | 새로운 LdapSrvWeight | 예상되는 새 CPU 사용률 |
|---|---|---|---|
| DC 1(PDC 에뮬레이터) | 53% | 57 | 40% |
| DC 2 | 33% | 100 | 40% |
| DC 3 | 33% | 100 | 40% |
PDC 에뮬레이터 역할이 전송되거나, 특히 사이트의 다른 도메인 컨트롤러로 압수되면 새 PDC 에뮬레이터에서 CPU 사용률이 크게 증가합니다.
이 예제 시나리오에서는 대상 사이트 동작 프로필을 기반으로 이 사이트의 세 도메인 컨트롤러에 모두 4개의 CPU가 있다고 가정합니다. 정상적인 조건에서 이러한 DC 중 하나에 8개의 CPU가 있는 경우 어떻게 될까요? 40%의 사용률과 20%의 사용률에 1개의 DC가 있습니다. 이 구성이 반드시 나쁜 것은 아니지만 LDAP 가중치 튜닝을 사용하여 부하를 더 잘 분산할 수도 있습니다.
예제 2: CPU 수가 다른 환경
동일한 사이트에 CPU 수와 속도가 다른 서버가 있는 경우, 균등하게 분산되어 있는지 확인해야 합니다. 예를 들어 사이트에 8코어 서버 2개와 4코어 서버 1개가 있는 경우 4코어 서버는 다른 두 서버의 처리 능력의 절반만 가지고 있습니다. 클라이언트 부하가 균등하게 분산되는 경우, 4코어 서버는 CPU 부하를 관리하기 위해 8코어 서버 2개보다 두 배 더 열심히 작업해야 합니다. 그 위에 8코어 서버 중 하나가 오프라인 상태가 되면 4코어 서버가 오버로드됩니다.
| 시스템 | 프로세서 정보\ % 프로세서 유틸리티(_Total) 기본값을 사용하는 CPU 사용률 |
새로운 LdapSrvWeight | 예상되는 새 CPU 사용률 |
|---|---|---|---|
| 4-CPU DC 1 | 40 | 100 | 30% |
| 4-CPU DC 2 | 40 | 100 | 30% |
| 8-CPU DC 3 | 20 | 200 | 30% |
"N + 1" 시나리오에 대한 계획은 가장 중요합니다. 한 DC가 오프라인으로 전환되는 영향은 모든 시나리오에 맞게 계산되어야 합니다. 부하 분산이 짝수인 바로 앞의 시나리오에서는 모든 서버에서 부하가 균등하게 분산된 'N' 시나리오 동안 부하를 60% 보장하기 위해 비율이 일관되게 유지되므로 분산이 잘 됩니다. PDC 에뮬레이터 튜닝 시나리오 또는 사용자 또는 애플리케이션 부하가 불균형한 일반적인 시나리오를 살펴보면 효과는 매우 다릅니다.
| 시스템 | 튜닝된 사용률 | 새로운 LdapSrvWeight | 예상되는 새 사용률 |
|---|---|---|---|
| DC 1(PDC 에뮬레이터) | 40% | 85 | 47% |
| DC 2 | 40% | 100 | 53% |
| DC 3 | 40% | 100 | 53% |
처리를 위한 가상화 고려 사항
가상화된 환경에 대한 용량 계획인 경우 호스트 수준과 게스트 수준이라는 두 가지 수준을 고려해야 합니다. 호스트 수준에서 비즈니스 주기의 최대 기간을 식별해야 합니다. 가상 머신의 CPU에서 게스트 스레드를 예약하는 것은 물리적 컴퓨터의 CPU에서 AD DS 스레드를 가져오는 것과 유사하기 때문에 기본 호스트의 40%에서 60%를 사용하는 것이 좋습니다. 게스트 수준에서 기본 스레드 예약 원칙은 변경되지 않기 때문에 CPU 사용량은 40%에서 60% 범위 내에서 유지하는 것이 좋습니다.
호스트당 게스트가 한 명씩 있는 직접 매핑 시나리오에서는 예측하기 위해 이전 섹션에서 수행한 모든 용량 계획 예상을 가져와야 합니다. 공유 호스트 시나리오의 경우, 기본 프로세서의 효율성에 약 10%의 영향이 있습니다. 즉, 사이트에서 대상 40%에 10개의 CPU가 필요한 경우 모든 N 게스트에 할당해야 하는 권장 가상 CPU 수는 11개입니다. 물리적 서버와 가상 서버의 분산이 혼합된 사이트에서 이 한정자는 VM(가상 머신)에만 적용됩니다. 예를 들어 N + 1 시나리오에서 CPU가 10개인 물리적 또는 직접 매핑된 서버 1개는 DC용으로 예약된 CPU가 11개 더 있는 호스트의 CPU가 11개인 게스트 1명과 거의 같습니다.
AD DS 부하를 지원하는 데 필요한 CPU 수를 분석하고 계산하는 동안 실제 하드웨어를 구입하려는 경우, 시장에서 사용할 수 있는 하드웨어 유형이 예상과 정확히 일치하지 않을 수 있습니다. 그러나 가상화를 사용할 때는 그러한 문제가 없습니다. VM을 사용하면 VM에 원하는 정확한 사양으로 CPU를 많이 추가할 수 있기 때문에 사이트에 컴퓨팅 용량을 추가하는 데 필요한 노력이 줄어듭니다. 그러나 가상화는 게스트가 더 많은 CPU가 필요할 때 기본 하드웨어를 사용할 수 있도록 보장하는 데 필요한 컴퓨팅 기능을 정확하게 평가할 책임이 없습니다. 언제나 그렇듯이 성장을 위해 미리 계획할 것을 잊지 마십시오.
가상화 계산 요약 예제
| 시스템 | 피크 CPU |
|---|---|
| DC 1 | 120% |
| DC 2 | 147% |
| DC 3 | 218% |
| 총 CPU 사용량 | 485% |
| 대상 시스템 수 | 총 Bandwidth(위부터) |
|---|---|
| 40% 대상에 필요한 CPU | 4.85 ÷ .4 = 12.25 |
이 시나리오에서 성장을 미리 계획할 때 향후 3년 동안 수요가 50% 증가할 것으로 가정하는 경우 해당 시점까지 18.375 CPU(12.25 × 1.5)가 있는지 확인해야 합니다. 또는 첫 해 이후 수요를 검토한 다음 결과에 따라 용량을 추가할 수 있습니다.
NTLM에 대한 교차 신뢰 클라이언트 인증 로드
상호 신뢰 클라이언트 인증 로드 평가
수많은 환경에 트러스트로 연결된 도메인이 하나 이상 있을 수 있습니다. Kerberos를 사용하지 않는 다른 도메인의 ID에 대한 인증 요청은 두 도메인 컨트롤러 간의 보안 채널을 사용하여 트러스트를 트래버스해야 합니다. 사용자가 사이트에서 액세스하려는 도메인 컨트롤러는 대상 도메인 또는 대상 도메인을 향한 경로의 어딘가에 있는 다른 도메인 컨트롤러에 연결됩니다. DC가 신뢰할 수 있는 도메인의 다른 DC에 대해 수행할 수 있는 호출 수는 *MaxConcurrentAPI 설정에 따라 제어됩니다. 보안 채널이 DC가 서로 통신하는 데 필요한 부하 양을 처리할 수 있게 하기 위해 MaxConcurrentAPI를 튜닝하거나 포리스트에 있는 경우 바로 가기 트러스트를 만들 수 있습니다. MaxConcurrentApi 설정을 사용하여 NTLM 인증에 대한 성능 튜닝을 수행하는 방법에서 트러스트 간에 트래픽 볼륨을 확인하는 방법에 대해 자세히 알아봅니다.
이전 시나리오와 마찬가지로 데이터를 유용하게 사용하려면 하루 중 사용량이 많은 기간에 데이터를 수집해야 합니다.
참고 항목
인트라포레스트 및 포리스트 간 시나리오는 인증이 여러 트러스트를 트래버스하게 할 수 있습니다. 즉, 프로세스의 각 단계에서 조정해야 합니다.
가상화 계획
가상화를 위한 용량 계획 시 유의해야 할 사항이 있습니다.
- 대부분의 애플리케이션은 기본적으로 또는 특정 구성에서 NTLM(네트워크 수준 신뢰 관리자) 인증을 사용합니다.
- 활성 클라이언트 수가 증가함에 따라 애플리케이션 서버에서 더 많은 용량을 가질 필요가 있습니다.
- 클라이언트는 때때로 제한된 시간 동안 세션을 열어 두고 대신 이메일 끌어오기 동기화와 같은 서비스에 대해 정기적으로 다시 연결합니다.
- 인터넷 액세스를 위해 인증이 필요한 웹 프록시 서버는 높은 NTLM 부하를 유발할 수 있습니다.
이러한 애플리케이션은 NTLM 인증에 대한 큰 부하를 생성할 수 있으며, 특히 사용자와 리소스가 서로 다른 도메인에 있는 경우 DC에 상당한 스트레스를 줄 수 있습니다.
교차 신뢰 부하를 관리하기 위해 수행할 수 있는 여러 가지 방법이 있으며, 종종 동시에 함께 사용할 수 있고, 사용해야 합니다.
- 사용자가 있는 도메인에서 사용하는 서비스를 찾아 교차 신뢰 클라이언트 인증을 줄입니다.
- 사용 가능한 보안 채널 수를 증가시킵니다. 이러한 채널을 바로 가기 트러스트라고 하며, 포리스트 내 및 포리스트 간 트래픽과 관련이 있습니다.
- MaxConcurrentAPI에 대한 기본 설정을 튜닝합니다.
기존 서버에서 MaxConcurrentAPI를 튜닝하려면 다음 수식을 사용합니다.
New_MaxConcurrentApi_setting ≥ (semaphore_acquires + semaphore_time-outs) × average_semaphore_hold_time ÷ time_collection_length
자세한 내용은 KB 문서 2688798: MaxConcurrentApi 설정을 사용하여 NTLM 인증에 대한 성능 튜닝을 수행하는 방법을 참조하세요.
가상화 고려 사항
가상화는 운영 체제 튜닝 설정이므로 특별히 고려해야 할 사항은 없습니다.
가상화 튜닝 계산 예제
| 데이터 형식 | 값 |
|---|---|
| 세마포어 획득(최소) | 6,161 |
| 세마포어 획득(최대) | 6,762 |
| 세마포어 시간 제한 | 0 |
| 평균 세마포어 보류 시간 | 0.012 |
| 수집 기간(초) | 1:11분(71초) |
| 수식(KB 2688798) | ((6762 - 6161) + 0) × 0.012 / |
| MaxConcurrentAPI의 최솟값 | ((6762 - 6161) + 0) × 0.012 ÷ 71 = .101 |
이 기간 동안 해당 시스템은 기본값이 허용됩니다.
용량 계획 목표 준수 모니터링
이 문서 전체에서 계획 및 크기 조정이 사용률 대상으로 이동하는 방법에 대해 논의했습니다. 다음 테이블에는 시스템이 의도한 대로 작동하도록 모니터링해야 하는 권장 임계값이 요약되어 있습니다. 이러한 임계값은 성능 임계값이 아니라 용량 계획 임계값입니다. 이러한 임계값을 초과하는 서버는 계속 작동하지만 사용자 수요가 증가함에 따라 성능 문제가 발생하기 전에 애플리케이션이 본래 용도대로 작동하는지 확인해야 합니다. 애플리케이션이 정상인 경우, 하드웨어 업그레이드 또는 기타 구성 변경 사항을 평가하기 시작해야 합니다.
| 범주 | 성능 카운터 | 간격/샘플링 | 대상 | Warning |
|---|---|---|---|---|
| 프로세서 | Processor Information(_Total)\% Processor Utility |
60분 | 40% | 60% |
| RAM(Windows Server 2008 R2 이하 버전) | 메모리\이용 가능 MB | < 100MB | 해당 없음 | < 100MB |
| RAM(Windows Server 2012) | 메모리\장기 평균 대기 캐시 수명 | 30분 | 테스트해야 함 | 테스트해야 함 |
| 네트워크 | 네트워크 인터페이스(*)\수신 바이트/초 네트워크 인터페이스(*)\수신 바이트/초 |
30분 | 40% | 60% |
| 스토리지 | LogicalDisk((<NTDS Database Drive>))\평균 디스크 초/읽기LogicalDisk(( |
60분 | 10ms | 15ms |
| AD 서비스 | Netlogon(*)\평균 세마포어 중지 시간 | 60분 | 0 | 1초 |
부록 A: CPU 크기 조정 조건
이 부록은 환경의 CPU 크기 조정 요구 사항을 예측하는 데 도움이 되는 유용한 용어 및 개념에 대해 설명합니다.
정의: CPU 크기 조정
프로세서(마이크로프로세서)는 프로그램 지침을 읽고 실행하는 구성 요소입니다.
다중 코어 프로세서에는 동일한 통합 회로에 여러 CPU가 있습니다.
다중 CPU 시스템에는 동일한 통합 회로에 없는 여러 CPU가 있습니다.
논리 프로세서는 운영 체제 관점에서 단일 논리 컴퓨팅 엔진이 있는 프로세서입니다.
이러한 정의에는 하이퍼 스레드, 다중 코어 프로세서의 코어 1개 또는 단일 코어 프로세서가 포함됩니다.
오늘날의 서버 시스템에는 여러 프로세서, 다중 코어 프로세서, 하이퍼 스레딩이 있으므로 이러한 정의는 두 시나리오를 모두 포함하도록 일반화됩니다. 논리 프로세서라는 용어는 이용 가능한 컴퓨팅 엔진의 OS 및 애플리케이션 관점을 나타내기 때문에 사용합니다.
스레드 수준 병렬 처리
각 스레드에는 자체 스택 및 지침이 있으므로 각 스레드는 별도의 작업입니다. AD DS는 다중 스레드이며 Ntdsutil.exe를 사용하여 Active Directory에서 LDAP 정책을 보고 설정하는 방법의 지침에 따라 사용 가능한 스레드 수를 조정할 수 있으며 여러 논리 프로세서에서 잘 확장됩니다.
데이터 수준 병렬 처리
데이터 수준 병렬 처리는 서비스가 동일한 프로세스에 대해 여러 스레드 간에 데이터를 공유하고 여러 프로세스에서 많은 스레드를 공유하는 경우입니다. AD DS 프로세스만으로도 단일 프로세스에 대해 여러 스레드에서 데이터를 공유하는 서비스로 계산됩니다. 데이터에 대한 모든 변경 내용은 캐시의 모든 수준, 모든 코어, 공유 메모리에 대한 업데이트의 모든 실행 중인 스레드에 반영됩니다. 모든 메모리 위치가 명령 처리를 계속하기 전 변경 내용에 맞게 조정되므로 쓰기 작업 중에 성능이 저하할 수 있습니다.
CPU 속도 및 다중 코어 고려 사항
일반적으로 논리 프로세서가 빨라질수록 일련의 명령을 처리하는 데 필요한 시간이 줄어듭니다. 논리 프로세서가 많을수록 동시에 더 많은 작업을 실행할 수 있습니다. 그러나 이러한 규칙은 공유 메모리에서 데이터 가져오기, 데이터 수준 병렬 처리 대기, 여러 스레드 관리 오버헤드와 같이 더 복잡한 시나리오에서는 적용되지 않습니다. 결과적으로 다중 코어 시스템의 확장성은 선형이 아닙니다.
이러한 변경이 발생하는 이유를 이해하려면 이러한 시나리오를 고속도로처럼 생각하는게 도움이 됩니다. 각 스레드는 개별 자동차이고, 각 차선은 코어이며, 속도 제한은 클록 속도로 생각해봅시다.
고속도로에 자동차가 하나뿐이라면 2차선이나 12차선이 있는지는 중요하지 않습니다. 그 차는 속도 제한 내에서 속력을 냅니다.
스레드에 필요한 데이터를 즉시 사용할 수 없는 경우, 스레드는 메모리에서 관련 데이터를 가져올 때까지 지침을 처리할 수 없습니다. 마치 고속도로 일부가 폐쇄되는 것과 같습니다. 고속도로에 자동차가 하나만 있더라도 도로가 다시 개방될 때까지 아무 데도 갈 수 없기 때문에 속도 제한은 주행 능력에 영향을 미치지 않습니다.
자동차 수의 증가에 따라 고속도로가 자동차 수를 관리해야 하는 오버헤드도 증가합니다. 운전자는 도로가 대부분 비어있는 늦은 저녁과는 달리 혼잡한 시간 동안 고속도로에서 운전할 때 더 열심히 집중해야 합니다. 또한 다른 차선에 대해서만 걱정할 필요가 있는 2차선 고속도로에서 운전하는 것은 5개의 다른 차선이 있는 6차선 고속도로에서 운전하는 것보다 집중을 덜 합니다.
요약하자면, 프로세서를 더 추가해야 하는지 아니면 더 빠른 프로세서를 추가해야 하는지에 대한 질문은 매우 주관적이고 사례별로 고려해야 합니다. 특히 AD DS의 경우 처리 요구 사항은 환경 요인에 따라 달라지며 단일 환경 내에서는 서버마다 다를 수 있습니다. 그 결과, 이 문서의 이전 섹션에서는 매우 정확한 계산에 많이 투자하지 않았습니다. 예산 기반 구매 결정을 내릴 때, 먼저 프로세서 사용량을 40% 또는 특정 환경에 필요한 수로 최적화하는 것이 좋습니다. 시스템이 최적화되지 않은 경우, 추가 프로세서를 구입해도 이점이 많지 않습니다.
응답 시간 및 시스템 활동 수준이 성능에 미치는 영향
큐 이론은 대기 선 또는 큐의 수학적 연구입니다. 컴퓨팅을 위한 큐 이론에서 사용률 법칙은 t 수식으로 표현됩니다.
U k = B ÷ T
U k가 사용률인 경우 B는 사용량이 많은 시간이며 T는 시스템을 관찰하는 데 소요된 총 시간입니다. Microsoft 컨텍스트에서 이는 실행 상태에 있는 100나노초(ns) 간격 스레드의 수를 지정된 시간 간격으로 사용할 수 있는 100-ns 간격으로 나눈 값을 의미합니다. 프로세서 개체 및 PERF_100NSEC_TIMER_INV에 나타난 프로세서 사용률의 백분율을 계산하는 것과 동일한 수식입니다.
큐 이론은 또한 다음 수식을 제공합니다. N = U k ÷ (1 - U k) 식으로 사용률에 따라 대기 항목의 수를 추정, 여기서 N은 큐의 길이입니다. 모든 사용률 간격에 관해 이 수식을 차트로 표시하면 지정된 CPU 로드에서 큐를 프로세서에 가져오는 데 걸리는 시간에 대한 다음 추정치가 제공됩니다.
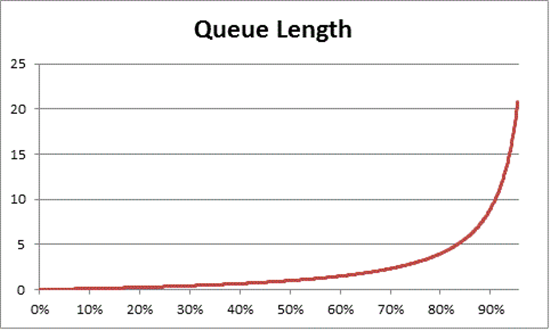
이 예측에 따라 50% CPU 부하 후 평균 대기에는 일반적으로 큐에 다른 항목이 하나 포함되며 CPU 사용률이 70%로 빠르게 증가하는 것을 확인할 수 있습니다.
큐 이론이 AD DS 배포에 적용되는 방식을 이해하기 위해 CPU 속도와 다중 코어 고려 사항에 사용한 고속도로 비유로 돌아가겠습니다.
오후 중반의 바쁜 시간대는 40%에서 70%의 용량 범위로 떨어질 것입니다. 운전할 차선을 선택하는 능력이 심각하게 제한되지 않는 충분한 트래픽이 있습니다. 다른 운전자가 길을 갈 가능성은 높지만, 혼잡 시간대와 마찬가지로 차선의 다른 차량 간에 안전한 간격을 찾아야 하는 것과 동일한 수준의 작업이 불필요합니다.
혼잡 시간대가 다가오면 도로 시스템은 100% 용량에 접근합니다. 혼잡 시간대에 차선을 변경하는 것은 자동차가 너무 가깝기 때문에 차선을 변경할 때 기동할 여지가 많지 않아서 매우 어려워집니다.
따라서 장기 평균 용량을 40%로 추정하면 비정상적인 부하 급증에 대한 여유 공간을 더 확보할 수 있습니다. 이러한 급증은 실행하는 데 시간이 걸리는 어설프게 코딩된 쿼리 등의 일시적인 부하 급증이든, 휴일 주말 다음 날 아침 활동이 급증하는 것과 같이 일반적인 부하가 비정상적으로 급증하는 경우이든 마찬가지입니다.
이전 문은 프로세서 시간 계산의 백분율을 사용률 법칙 수식과 동일한 것으로 간주합니다. 이 간소화 버전은 새 사용자에게 개념을 도입하기 위한 것입니다. 그러나 고급 계산의 경우 다음 참조를 가이드로 사용할 수 있습니다.
- PERF_100NSEC_TIMER_INV 해석
- B = 유휴 스레드가 논리 프로세서에서 소비하는 100-ns 간격의 수입니다. X 변수 변경, PERF_100NSEC_TIMER_INV 계산
- T = 지정된 시간 범위의 총 100-ns 간격 수입니다. Y 변수 변경, PERF_100NSEC_TIMER_INV 계산.
- U k = 유휴 스레드 또는 % 유휴 시간별 논리 프로세서의 사용률 백분율.
- 계산 작업:
- U k = 1 – %프로세서 시간
- %프로세서 시간 = 1 – U k
- %프로세서 시간 = 1 – B / T
- %프로세서 시간 = 1 – X1 – X0 / Y1 – Y0
용량 계획에 해당 개념 적용
이전 섹션의 계산에서는 시스템에 필요한 논리 프로세서 수를 결정하는 것이 매우 복잡해 보일 수 있습니다. 따라서 시스템 크기를 조정하는 방법은 현재 부하에 따라 최대 대상 사용률을 결정한 다음 해당 대상에 도달하는 데 필요한 논리 프로세서 수를 계산하는 데 집중하는 것입니다. 또한 예측이 완벽하게 정확할 필요는 없습니다. 논리 프로세서 속도는 동기화에 큰 영향을 주지만 성능은 다른 영역의 영향을 받을 수도 있습니다.
- 캐시 효율성
- 메모리 일관성 요구 사항
- 스레드 예약 및 동기화
- 불완전하게 분산된 클라이언트 부하
컴퓨팅 성능은 상대적으로 저렴하기 때문에 필요한 CPU의 정확한 수를 계산하는 데 너무 많은 시간을 투자할 가치가 없습니다.
또한 40% 권장 사항이 필수 요구 사항이 아니라는 점을 기억해야 합니다. 이 방법을 계산을 위한 합리적인 시작법으로 사용합니다. 다양한 AD 사용자에게는 다양한 수준의 응답성이 필요합니다. 프로세서 액세스 대기 시간이 증가하여 클라이언트 성능에 눈에 띄게 영향을 주지 않으면서 환경이 80% 또는 90% 사용률로 지속 평균으로 실행될 수 있는 상황도 있을 수 있습니다.
또한 시스템에는 RAM 액세스, 디스크 액세스, 네트워크를 통해 응답 전송을 포함하여 튜닝해야 하는 논리 프로세서보다 훨씬 느린 다른 영역도 있습니다. 예시:
디스크 바인딩된 90% 사용률로 실행되는 시스템에 프로세서를 추가하는 경우, 성능이 크게 향상되지 않을 수 있습니다. 시스템을 더 자세히 살펴보면, I/O 작업이 완료되기를 기다리고 있기 때문에 프로세서에 연결되지 않는 스레드가 많이 있습니다.
디스크 바인딩된 문제를 해결하면 스레드가 이전에 대기 중 상태가 중단되어 CPU 시간에 대한 경쟁이 더 치열해질 수 있습니다. 결과적으로 90% 사용률은 100%가 됩니다. 사용률을 관리 가능한 수준으로 되돌리려면 두 구성 요소를 모두 조정해야 합니다.
참고 항목
Processor Information(*)\% Processor Utility카운터는 터보 모드가 있는 시스템에서 100%를 초과할 수 있습니다. 터보 모드를 사용하면 CPU가 단기간 동안 정격 프로세서 속도를 초과할 수 있습니다. 자세한 정보가 필요한 경우, CPU 제조업체의 설명서 및 카운터 설명을 참조하세요.
전체 시스템 사용률 고려 사항에 대한 논의에는 가상화 게스트로 도메인 컨트롤러도 포함됩니다. 응답 시간 및 시스템 활동 수준이 성능에 미치는 영향은 가상화된 시나리오에서 호스트와 게스트 모두에 적용됩니다. 게스트가 한 명뿐인 호스트에서 DC 또는 시스템은 실제 하드웨어와 거의 동일한 성능을 갖습니다. 호스트에 게스트를 더 추가하면 기본 호스트의 사용률이 증가하고 프로세서에 액세스하기 위한 대기 시간도 증가하게 됩니다. 그러므로 호스트 및 게스트 수준 모두에서 논리 프로세서 사용률을 관리해야 합니다.
이전 섹션의 고속도로 비유를 다시 살펴보겠습니다. 이번에는 게스트 VM을 고속 버스로 상상해 봅시다. 대중 교통이나 학교 버스가 아닌 고속 버스는 정차하지 않고 운전자의 목적지로 바로 이동합니다.
이제 다음 네 가지 시나리오를 상상해 보겠습니다.
- 시스템의 사용량이 적은 기간은 늦은 밤에 고속 버스를 타는 것과 같습니다. 운전자가 타면 다른 승객은 거의 없으며 도로는 거의 비어 있습니다. 버스가 겪을 교통 체증이 없기 때문에 운전자가 자신의 차에서 운전한 것처럼 쉽고 빠릅니다. 그러나 운전자의 이동 시간도 현지 속도 제한에 의해 제한됩니다.
- 시스템의 CPU 사용률이 너무 높은, 작업량이 많은 시간은 고속도로의 대부분의 차선이 닫힌 심야 주행과 같습니다. 버스 자체는 거의 비어 있지만, 제한 차선을 주행하는 남은 교통량으로 인해 도로는 여전히 막혀 있습니다. 운전자는 원하는 모든 곳에 자유롭게 앉을 수 있지만 실제 주행 시간은 버스 외부의 교통량에 따라 결정됩니다.
- 사용량이 많은 시간에 CPU 사용률이 높은 시스템은 혼잡 시간대의 버스와 같습니다. 여행은 더 오래 걸릴뿐만 아니라 버스가 승객들로 가득 차 있기 때문에 버스에서 내리는 것이 더 어렵습니다. 대기 시간을 단축하기 위해 게스트 시스템에 논리 프로세서를 추가하는 것은 버스를 추가하여 교통 문제를 해결하는 것과 같습니다. 문제는 버스의 수가 아니라 여행 시간입니다.
- 사용량이 많은 시간에 CPU 사용률이 높은 시스템은 주로 빈 도로에서 야간에 사람들로 붐비는 버스와 같습니다. 운전자는 좌석을 찾거나 버스에서 내리는 데 어려움을 겪을 수 있지만 버스가 모든 승객을 픽업하면 매우 매끄럽습니다. 이 시나리오는 버스를 추가하여 성능이 향상되는 유일한 시나리오입니다.
이전 예제를 기반으로 0%에서 100% 사용률 사이에 다양한 수준의 성능 영향을 주는 많은 사례가 있음을 알 수 있습니다. 또한 논리 프로세서를 추가해도 특정 시나리오 이외의 성능이 반드시 향상되는 것은 아닙니다. 호스트 및 게스트에 권장되는 40% CPU 사용률 목표에 이러한 원칙을 적용하는 것은 매우 간단해야 합니다.
부록 B: 다양한 프로세서 속도에 대한 고려 사항
처리에서 데이터를 수집하는 동안 프로세서가 100% 클록 속도로 실행되고 모든 교체 시스템의 처리 속도가 동일하다고 가정합니다. 이러한 가정이 정확하지 않음에도 불구하고, 특히 기본 전원 계획이 분산된 Windows Server 2008 R2 이상 버전에서는 이러한 가정이 여전히 기존의 예측에 적합합니다. 잠재적인 오류는 증가할 수 있지만 프로세서 속도가 증가함에 따라 여유롭게 안전해집니다.
- 예를 들어 11.25 CPU를 요구하는 시나리오에서 데이터를 수집할 때 프로세서가 절반 속도로 실행되는 경우 수요의 정확한 예측은 5.125 ÷ 2입니다.
- 클록 속도를 두 배로 늘리면 기록된 기간 내에 발생하는 처리 횟수의 두 배가 되도록 보장할 수 없습니다. 프로세서가 RAM 또는 다른 구성 요소를 기다리는 데 소요되는 시간은 거의 동일하게 유지됩니다. 그러므로 더 빠른 프로세서는 시스템이 데이터를 가져올 때까지 기다리는 동안 유휴 시간이 더 많이 소요될 수 있습니다. 가장 낮은 공통 분모를 고수하고, 예측값을 기존처럼 유지하고, 결과를 부정확하게 만들 수 있는 프로세서 속도 간의 선형 비교를 가정하지 않는 것이 좋습니다.
교체 하드웨어의 프로세서 속도가 현재 하드웨어보다 낮을 경우, 필요한 프로세서 수를 비례적으로 늘려야 합니다. 예를 들어 사이트 부하를 유지하기 위해 프로세서 10개가 필요하다고 계산하는 시나리오를 살펴보겠습니다. 현재 프로세서는 3.3GHz에서 실행되며 2.6GHz에서 실행하도록 대체하려는 프로세서입니다. 기존 프로세서 10개만 교체하면 속도가 21% 감소합니다. 속도를 높이려면 10개 대신 최소 12개의 프로세서를 가져와야 합니다.
그러나 이러한 가변성이 용량 관리 프로세서 사용률 목표를 변경하지는 않습니다. 프로세서 클록 속도는 부하 수요에 따라 동적으로 조정되므로 더 높은 부하에서 시스템을 실행하면 CPU가 더 높은 클록 속도 상태에서 더 많은 시간을 소모하게 됩니다. 궁극적인 목표는 최고 업무 시간 동안 CPU를 100% 클록 속도 상태에서 40% 사용률로 만드는 것입니다. 사용량이 적은 시나리오에서는 CPU 속도를 제한하여 전력을 절약할 수 있습니다.
참고 항목
전원 계획을 고성능으로 설정하여 데이터 수집 중 프로세서에서 전원 관리를 끌 수 있습니다. 전원 관리를 해제하면 대상 서버에서 CPU 사용량을 정확하게 확인할 수 있습니다.
다른 프로세서에 대한 추정치를 조정하려면 Standard Performance Evaluation Corporation의 SPECint_rate2006 벤치마크를 사용하는 것을 권장합니다. 이 벤치마크를 사용하려면:
SPEC(Standard Performance Evaluation Corporation) 웹사이트로 이동합니다.
결과를 선택합니다.
CPU2006을 입력하고 검색을 선택합니다.
사용 가능한 구성에 대한 드롭다운 메뉴에서 모든 SPEC CPU2006을 선택합니다.
검색 양식 요청 필드에서 단순을 선택한 다음 이동을 선택합니다.
단순 요청에서 대상 프로세서에 대한 검색 조건을 입력합니다. 예를 들어 ES-2630 프로세서를 찾으려는 경우 드롭다운 메뉴에서 프로세서를 선택한 다음 검색 필드에 프로세서 이름을 입력합니다. 완료되면 단순 페치 실행을 선택합니다.
검색 결과에서 서버 및 프로세서 구성을 찾습니다. 검색 엔진이 정확한 일치 항목을 반환하지 않는 경우, 가능한 가장 가까운 일치 항목을 찾습니다.
결과 및 코어 수 열에 값을 기록합니다.
다음 수식을 사용하여 한정자를 결정합니다.
((대상 플랫폼 코어당 점수 값) ×(기준 플랫폼의 코어당 MHz)) ÷((코어당 기준 점수 값) ×(대상 플랫폼의 코어당 MHz))
예를 들어 ES-2630 프로세서의 한정자를 찾는 방법은 다음과 같습니다.
(35.83 × 2000) ÷ (33.75 × 2300) = 0.92
이 한정자가 필요한 것으로 예상하는 프로세서 수를 곱합니다.
ES-2630 프로세서 예제의 경우 0.92 × 10.3 = 10.35 프로세서입니다.
부록 C: 운영 체제가 스토리지와 상호 작용하는 방법
응답 시간과 시스템 작업 수준이 성능에 미치는 영향에서 논의한 큐 이론 개념이 스토리지에도 적용됩니다. 이러한 개념을 효과적으로 적용하려면 OS에서 I/O를 처리하는 방법을 잘 알고 있어야 합니다. Windows OS에서 OS는 각 실제 디스크에 대한 I/O 요청을 보유하는 큐를 만듭니다. 그러나 실제 디스크가 반드시 단일 디스크는 아닙니다. OS는 배열 컨트롤러 또는 SAN의 스핀들 집계를 실제 디스크로 등록할 수도 있습니다. 배열 컨트롤러와 SAN은 다음 이미지와 같이 여러 디스크를 단일 배열 집합으로 집계하고, 여러 파티션으로 분할한 뒤, 각 파티션을 실제 디스크로 사용할 수도 있습니다.
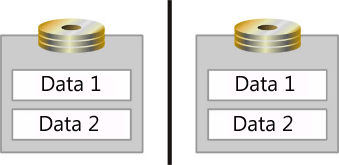
이 그림에서 두 스핀들은 데이터 스토리지의 논리 영역으로 미러링되고 데이터 1과 데이터 2로 구분됩니다. OS는 이러한 각 논리 영역을 개별 실제 디스크로 등록합니다.
이제 실제 디스크를 정의하는 내용을 명확히 설명했으므로 이 부록의 정보를 보다 잘 이해할 수 있도록 다음 용어를 숙지해야 합니다.
- 스핀들은 서버에 물리적으로 설치된 디바이스입니다.
- 배열은 컨트롤러에서 집계한 스핀들의 컬렉션입니다.
- 배열 파티션은 집계된 배열의 분할입니다.
- LUN(논리 단위 번호)은 컴퓨터에 연결된 SCSI 디바이스의 배열입니다. 이 문서에서는 SAN에 관한 이야기를 할 때 이러한 용어를 사용합니다.
- 디스크에는 OS가 단일 실제 디스크로 등록하는 모든 스핀들 또는 파티션이 포함됩니다.
- 파티션은 OS가 실제 디스크로 등록하는 내용의 논리적 분할입니다.
운영 체제 아키텍처 고려 사항
OS는 등록하는 각 디스크에 대해 FIFO(선입 선출) I/O 큐를 만듭니다. 이러한 디스크는 스핀들, 배열 또는 배열 파티션일 수 있습니다. OS는 I/O 처리 방법에 관해서는 활성 큐가 많을수록 좋습니다. OS가 FIFO 큐를 직렬화할 때, 도착 순서대로 스토리지 하위 시스템에 발급된 모든 FIFO I/O 요청을 처리해야 합니다. 각 디스크와 스핀들 또는 배열의 상관 관계를 지정하는 경우, OS는 각 고유한 디스크 집합에 대한 I/O 큐를 유지 관리하여 디스크 전체에서 부족한 I/O 리소스에 대한 경쟁을 제거하고 I/O 수요를 단일 디스크로 격리합니다. 그러나 Windows Server 2008에서는 I/O 우선 순위 지정 형식의 예외가 도입되었습니다. 우선 순위가 낮은 I/O를 사용하도록 설계된 애플리케이션은 OS가 수신한 시기와 상관없이 큐의 뒤쪽으로 이동됩니다. 애플리케이션은 낮은 우선 순위 설정을 기본값을 일반 우선 순위로 사용하도록 특별히 코딩되지 않았습니다.
간소화된 스토리지 하위 시스템 소개
이 섹션에서는 간소화된 스토리지 하위 시스템에 대해 설명합니다. 컴퓨터 내의 단일 하드 드라이브 예제로 시작하겠습니다. 이 시스템을 주요 스토리지 하위 시스템 구성 요소로 세분화할 경우, 다음을 얻을 수 있습니다.
- 한 개의 10,000RPM 초고속 SCSI HD(초고속 SCSI에는 20MBps 전송 속도 포함)
- 1개의 SCSI 버스(케이블)
- 1개의 초고속 SCSI 어댑터
- 1개의 32비트 33MHz PCI 버스
참고 항목
이 예제에서는 시스템에서 일반적으로 실린더 하나의 데이터를 유지하는 디스크 캐시를 반영하지 않습니다. 이 경우 첫 번째 I/O에는 10ms가 필요하며 디스크는 전체 실린더를 읽습니다. 다른 모든 순차 I/O는 캐시로 충족됩니다. 결과적으로 디스크 내 캐시는 순차 I/O 성능을 향상시킬 수 있습니다.
구성 요소를 식별하면 시스템에서 전송 가능한 데이터의 양과 처리 가능한 I/O의 양에 대한 아이디어를 얻을 수 있습니다. I/O의 양과 시스템 전송 가능 데이터의 양은 서로 관련되지만 동일한 값은 아닙니다. 이 상관 관계는 블록 크기 및 디스크 I/O가 임의 또는 순차적인지 여부에 따라 달라집니다. 시스템은 모든 데이터를 디스크에 블록으로 쓰지만 애플리케이션이 서로 다른 블록 크기를 사용할 수 있습니다.
다음으로 구성 요소별로 이러한 항목을 분석하겠습니다.
하드 드라이브 액세스 시간
평균 10,000-RPM 하드 드라이브에는 7ms의 검색 시간과 3ms의 액세스 시간이 있습니다. 검색 시간은 읽기 또는 쓰기 헤드가 플래터 위치로 이동하는 데 걸리는 평균 시간입니다. 액세스 시간은 헤드가 올바른 위치에 있을 경우 디스크에 데이터를 읽거나 쓰는 데 걸리는 평균 시간입니다. 따라서 10,000-RPM HD에서 고유한 데이터 블록을 읽는 평균 시간에는 데이터 블록당 총 10ms 또는 0.010초의 검색 및 액세스 시간이 모두 포함됩니다.
모든 디스크 액세스에서 헤드가 디스크의 새 위치로 이동해야 하는 경우 읽기 또는 쓰기 동작을 임의 호출합니다. 모든 I/O가 임의인 경우 10,000-RPM HD는 초당 약 100I/O(IOPS)를 처리할 수 있습니다.
하드 드라이브의 인접한 섹터에서 모든 I/O가 발생하면 순차 I/O라고 합니다. 첫 번째 I/O가 완료된 후 읽기 또는 쓰기 헤드는 하드 드라이브가 다음 데이터 블록을 저장하는 시작 부분에 있기 때문에 순차 I/O에는 검색 시간이 없습니다. 예를 들어 10,000-RPM HD는 다음 수식에 따라 초당 약 333I/O를 처리할 수 있습니다.
I/O당 초당 1000ms ÷ 3ms
지금까지 하드 드라이브의 전송 속도는 예제와 관련 없습니다. 하드 드라이브 크기에 상관없이 10,000-RPM HD에서 처리할 수 있는 실제 IOPS 양은 항상 약 100개의 임의 또는 300개의 순차 I/O입니다. 드라이브에 쓰는 애플리케이션에 따라 블록 크기가 변경되면, I/O당 끌어온 데이터 양도 변경됩니다. 예를 들어 블록 크기가 8KB인 경우 총 800KB의 하드 드라이브에서 100개의 I/O 작업을 읽거나 하드 드라이브에 쓰게 됩니다. 그러나 블록 크기가 32KB인 경우 100 I/O는 하드 드라이브에 3,200KB(3.2MB)를 읽거나 씁니다. SCSI 전송 속도가 전송된 총 데이터 양을 초과하는 경우, 더 빠른 전송 속도를 얻는 것은 아무것도 변경되지 않습니다. 자세한 내용은 다음 테이블을 참조합니다.
| 설명 | 7200RPM 9ms 검색, 4ms 액세스 | 10,000RPM 7ms 검색, 3ms 액세스 | 15,000RPM 4ms 검색, 2ms 액세스 |
|---|---|---|---|
| 임의 I/O | 80 | 100 | 150 |
| 순차 I/O | 250 | 300 | 500 |
| 10,000RPM 드라이브 | 8KB 블록 크기(Active Directory Jet) |
|---|---|
| 임의 I/O | 800KB/s |
| 순차 I/O | 2400KB/s |
SCSI 백플레인
이 예제 시나리오에서 리본 케이블인 SCSI 백플레인이 스토리지 하위 시스템의 처리량에 미치는 영향은 블록 크기에 따라 달라집니다. I/O가 8KB 블록에 있는 경우 버스에서 처리할 수 있는 I/O의 양은 얼마입니까? 이 시나리오에서 SCSI 버스는 20MBps 또는 20480KB/s입니다. 20480KB/s를 8KB 블록으로 나눈 값은 SCSI 버스에서 지원하는 최대 약 2500IOPS를 생성합니다.
참고 항목
다음 테이블의 그림은 예제 시나리오를 나타냅니다. 연결된 스토리지 디바이스는 대부분 현재 훨씬 더 높은 처리량을 제공하는 PCI Express를 사용합니다.
| 블록 크기당 SCSI 버스에서 지원하는 I/O | 2KB 블록 크기 | 8KB 블록 크기(AD Jet)(SQL Server 7.0/SQL Server 2000) |
|---|---|---|
| 20Mbps | 10,000 | 2,500 |
| 40MBps | 20,000 | 5,000 |
| 128MBps | 65,536 | 16,384 |
| 320MBps | 160,000 | 40,000 |
이전 표와 같이 예제 시나리오에서는 스핀들 최대값이 나열된 임계값보다 낮은 100 I/O이므로 버스에서 병목 현상이 발생하지 않습니다.
참고 항목
이 시나리오에서 SCSI 버스가 100% 효율적이라고 가정합니다.
SCSI 어댑터
시스템에서 처리할 수 있는 I/O 양을 확인하려면 제조업체의 사양을 확인해야 합니다. I/O 요청을 적절한 디바이스로 전달하려면 처리 능력이 요구되므로 시스템에서 처리할 수 있는 I/O의 정도는 SCSI 어댑터 또는 배열 컨트롤러 프로세서에 따라 달라집니다.
이 예제 시나리오에서는 시스템에서 1,000I/O를 처리할 수 있다고 가정합니다.
PCI 버스
PCI 버스는 자주 간과되는 구성 요소입니다. 이 예제 시나리오에서는 PCI 버스가 병목 상태가 아닙니다. 그러나 시스템이 스케일업되면 향후 병목 상태가 될 수 있습니다.
이 수식을 통해 예제 시나리오에서 PCI 버스가 데이터를 전송할 수 있는 양을 확인할 수 있습니다.
32비트 ÷ 바이트당 8비트 × 33MHz = 133MBps
그러므로 33Mhz에서 작동하는 32비트 PCI 버스가 133MBps의 데이터를 전송할 수 있다고 가정할 수 있습니다.
참고 항목
이 수식의 결과는 전송된 데이터의 이론적 한계를 나타냅니다. 실제로 대부분의 시스템은 최대 한도의 약 50%까지만 도달합니다. 특정 버스트 시나리오에서 시스템은 단기간 동안 제한의 75%에 도달할 수 있습니다.
66MHz 64비트 PCI 버스는 다음 수식을 기반으로 이론적으로 최대 528MBps를 지원할 수 있습니다.
64비트 ÷ 바이트당 8비트 × 66Mhz = 528MBps
네트워크 어댑터 또는 이차 SCSI 컨트롤러와 같은 다른 디바이스를 추가하면 모든 디바이스가 대역폭을 공유하고 제한된 처리 리소스를 위해 서로 경쟁할 수 있으므로 시스템에서 사용할 수 있는 대역폭이 줄어듭니다.
스토리지 하위 시스템 분석으로 병목 현상 찾기
이 시나리오에서 스핀들은 요청 가능한 I/O의 양을 제한하는 요소입니다. 따라서 이 병목 현상은 시스템에서 전송 가능한 데이터의 양을 제한합니다. 이 예제는 AD DS 시나리오이므로 전송 가능한 데이터의 양은 8KB 단위로 초당 100개의 임의 I/O이며 Jet 데이터베이스에 액세스할 때 초당 총 800KB입니다. 반면 로그 파일에만 할당하도록 구성하는 스핀들의 최대 처리량은 8KB 할부에서 초당 300개의 순차 I/O로 제한되며 총 2,400KB 또는 초당 2.4MB로 제한됩니다.
이제 예제 구성의 구성 요소를 분석했으므로 스토리지 하위 시스템에서 구성 요소를 추가 및 변경할 때 병목 현상이 발생할 수 있는 위치를 보여 주는 테이블을 살펴보겠습니다.
| 주의 | 병목 상태 분석 | 디스크 | 버스 | 어댑터 | PCI 버스 |
|---|---|---|---|---|---|
| 두 번째 디스크 추가 후의 도메인 컨트롤러 구성입니다. 디스크 구성은 800KB/s의 병목 상태를 나타냅니다. | 디스크 1개 추가(총=2) I/O는 임의 4KB 블록 크기 10,000RPM HD |
총 200I/O 총 800KB/s. |
|||
| 7개의 디스크를 추가한 후에도 디스크 구성은 3,200KB/s의 병목 상태를 나타냅니다. | 디스크 7개 추가(총=8) I/O는 임의 4KB 블록 크기 10,000RPM HD |
총 800I/O. 총 3200KB/s. |
|||
| I/O를 순차 변경하면 네트워크 어댑터가 1000 IOPS로 제한되므로 병목 상태가 됩니다. | 디스크 7개 추가(총=8) I/O는 순차적 4KB 블록 크기 10,000RPM HD |
디스크에 2400 I/O 초를 읽고 쓸 수 있으며, 컨트롤러는 1000 IOPS로 제한됩니다. | |||
| 네트워크 어댑터를 10,000IOPS 지원 SCSI 어댑터로 바꾼 후 병목 현상이 디스크 구성으로 돌아갑니다. | 디스크 7개 추가(총=8) I/O는 임의 4KB 블록 크기 10,000RPM HD SCSI 어댑터 업그레이드(현재 10,000I/O 지원) |
총 800I/O. 총 3200KB/s |
|||
| 블록 크기를 32KB로 증가시키면 버스는 20MBps만 지원하므로 병목 상태가 됩니다. | 디스크 7개 추가(총=8) I/O는 임의 32KB 블록 크기 10,000RPM HD |
총 800I/O. 디스크에 25,600KB/s(25MBps)를 읽거나 쓸 수 있습니다. 버스는 20MBps만 지원합니다. |
|||
| 버스를 업그레이드하고 디스크를 더 추가한 후 디스크가 병목 상태로 유지됩니다. | 디스크 13개 추가(총=14) 디스크가 14개인 두 번째 SCSI 어댑터 추가 I/O는 임의 4KB 블록 크기 10,000RPM HD 320MBps SCSI 버스로 업그레이드 |
2800I/O 11,200KB/s(10.9MBps) |
|||
| I/O를 순차 변경한 후 디스크는 병목 상태를 유지합니다. | 디스크 13개 추가(총=14) 디스크가 14개인 두 번째 SCSI 어댑터 추가 I/O는 순차적 4KB 블록 크기 10,000RPM HD 320MBps SCSI 버스로 업그레이드 |
8,400I/O 33,600KB\s (32.8MB\s) |
|||
| 더 빠른 하드 드라이브를 추가한 후 디스크는 병목 상태를 유지합니다. | 디스크 13개 추가(총=14) 디스크가 14개인 두 번째 SCSI 어댑터 추가 I/O는 순차적 4KB 블록 크기 15,000RPM HD 320MBps SCSI 버스로 업그레이드 |
14,000I/O 56,000KB/s (54.7MBps) |
|||
| 블록 크기를 32KB로 증가시키면 PCI 버스가 병목 상태가 됩니다. | 디스크 13개 추가(총=14) 디스크가 14개인 두 번째 SCSI 어댑터 추가 I/O는 순차적 32KB 블록 크기 15,000RPM HD 320MBps SCSI 버스로 업그레이드 |
14,000I/O 448,000KB/s (437MBps)는 스핀들 읽기/쓰기 제한입니다. PCI 버스는 이론적 최대 133MBps(최대 75% 효율)를 지원합니다. |
RAID 소개
스토리지 하위 시스템에 배열 컨트롤러를 도입하는 경우, 해당 특성이 크게 변경되지는 않습니다. 배열 컨트롤러는 계산 시 SCSI 어댑터만 대체합니다. 그러나 다양한 배열 수준을 사용할 경우 디스크에 데이터를 읽고 쓰는 비용은 변경됩니다.
RAID 0에서 데이터를 작성하면 RAID 집합의 모든 디스크에 걸쳐 스트라이프됩니다. 읽기 또는 쓰기 작업 중 시스템은 각 디스크에서 데이터를 가져오거나 푸시하여 이 특정 기간 동안 시스템에서 전송할 수 있는 데이터의 양을 증가합니다. 따라서 10,000개의 RPM 드라이브를 사용하는 이 예제에서는 RAID 0을 사용하여 I/O 작업 100개를 수행할 수 있습니다. 시스템에서 지원하는 총 I/O 양은 스핀들당 초당 N 스핀들 100 1/O 또는 스핀들당 초당 100 I/O를 × N 스핀들입니다.

RAID 1에서 시스템은 중복성을 위해 한 쌍의 스핀들 간에 데이터를 미러링하거나 중복합니다. 시스템에서 읽기 I/O 작업을 수행할 경우, 집합의 두 스핀들에서 데이터를 읽을 수 있습니다. 이 미러링을 사용하면 읽기 작업 중에 두 디스크에 대한 I/O 용량을 이용할 수 있습니다. 그러나 RAID 1은 시스템에서 스핀들 쌍에 기록된 데이터를 미러링해야 하기 때문에 쓰기 작업에 성능 이점을 제공하지 않습니다. 미러링으로 인해 쓰기 작업이 더 오래 소요되지는 않지만 시스템에서 동시에 둘 이상의 읽기 작업을 수행할 수 없습니다. 따라서 모든 쓰기 I/O 작업에는 두 개의 읽기 I/O 작업이 발생합니다.
다음 수식은 이 시나리오에서 발생하는 I/O 작업의 수를 계산합니다.
읽기 I/O + 2 × 쓰기 I/O = 사용 가능한 총 사용 가능한 디스크 I/O
읽기 비율과 배포의 스핀들 수를 알고 있는 경우, 이 수식을 사용하여 배열에서 지원할 수 있는 I/O 양을 계산할 수 있습니다.
스핀들당 최대 IOPS × 2개의 스핀들 × [(% 읽기 + % 쓰기) ÷(% 읽기 + 2× % 쓰기)] = 총 IOPS
RAID 1과 RAID 0을 모두 사용하는 시나리오에서는 읽기 및 쓰기 작업의 비용으로 RAID 1과 동일하게 동작합니다. 그러나 이제 I/O가 미러링된 각 집합에 걸쳐 스트라이프됩니다. 즉, 수식이 다음과 같이 변경됩니다.
스핀들당 최대 IOPS × 2개의 스핀들 × [(% 읽기 + % 쓰기) ÷(% 읽기 + 2× % 쓰기)] = 총 I/O
RAID 1 집합에서 RAID 1 집합의 N 번호를 스트라이프하면 배열에서 처리할 수 있는 총 I/O는 RAID 1 집합당 N × I/O가 됩니다.
N × {스핀들당 최대 IOPS × 2개의 스핀들 × [(% 읽기 + % 쓰기) ÷ (% 읽기 + 2 × % 쓰기)]} = 총 IOPS
시스템이 N 스핀들 간에 데이터를 스트라이프하고 + 1 스핀들에서 패리티 정보를 쓰기 때문에 RAID 5 N + 1 RAID를 호출하는 경우가 있습니다. 그러나 RAID 5는 RAID 1 또는 RAID 1 + 0보다 쓰기 I/O를 수행할 경우 더 많은 리소스를 사용합니다. RAID 5는 운영 체제가 배열에 쓰기 I/O를 제출할 때마다 다음 프로세스를 수행합니다.
- 이전 데이터를 읽습니다.
- 이전 패리티를 읽습니다.
- 새 데이터를 씁니다.
- 새 패리티를 씁니다.
OS가 배열 컨트롤러에 보내는 모든 쓰기 I/O 요청을 완료하기 위해 4개의 I/O 작업이 필요합니다. 따라서 N + 1 RAID 쓰기 요청은 완료하는 데 읽기 I/O의 4배 정도 걸립니다. 즉, OS의 I/O 요청 수를 스핀들이 가져오는 요청 수로 변환하는 수를 확인하기 위해 다음 수식을 사용합니다.
읽기 I/O + 4 × 쓰기 I/O = 총 I/O
마찬가지로 쓰기에 대한 읽기 비율과 스핀들 수를 알고 있는 RAID 1 집합에서 이 수식을 사용하여 배열에서 지원 가능한 I/O 양을 식별할 수 있습니다.
스핀들당 IOPS ×(스핀들 – 1) × [(%읽기 + % 쓰기) ÷ (% 읽기 + 4 × % 쓰기)] = 총 IOPS
참고 항목
이전 수식의 결과에서는 패리티로 손실된 드라이브가 포함되지 않습니다.
SAN 소개
SAN(스토리지 영역 네트워크)을 환경에 도입하는 경우 이전 섹션에서 설명한 계획 원칙에는 영향을 미치지 않습니다. 그러나 SAN이 연결된 모든 시스템의 I/O 동작을 변경할 수 있다는 점을 고려해야 합니다. SAN을 사용할 때의 주요 이점 중 하나는 내부 또는 외부에 연결된 스토리지보다 더 많은 중복성을 제공하지만 용량 계획에서 내결함성 요구 사항을 고려해야 한다는 것이기도 합니다. 또한 시스템에 더 많은 구성 요소를 도입할 때 이러한 새 부분을 계산에 고려해야 합니다.
이제 SAN을 해당 구성 요소로 세분화하겠습니다.
- SCSI 또는 파이버 채널 하드 드라이브
- 스토리지 단위 채널 백플레인
- 스토리지 단위 자체
- 스토리지 컨트롤러 모듈
- 한 개 이상의 SAN 스위치
- 한 개 이상의 HBA(호스트 버스 어댑터)
- 주변 장치 구성 요소 상호 연결(PCI) 버스
중복성을 위해 시스템을 디자인할 경우, 하나 이상의 원래 구성 요소가 작동을 중지하는 위기 시나리오에서 시스템이 계속 작동하도록 추가 구성 요소를 포함해야 합니다. 그러나 용량을 계획할 때는 시스템 기준 용량의 정확한 추정치를 얻기 위해 사용 가능한 리소스에서 중복 구성 요소를 제외해야 합니다. 이러한 구성 요소는 비상 사태가 발생하지 않는 한 일반적으로 온라인 상태가 아닙니다. 예를 들어 SAN에 두 개의 컨트롤러 모듈이 있는 경우 이용 가능한 총 I/O 처리량을 계산할 때만 사용해야 합니다. 원래 모듈의 작동이 중지되지 않는 한 다른 처리량은 켜지지 않습니다. 또한 중복 SAN 스위치, 스토리지 단위 또는 스핀들을 I/O 계산으로 가져오면 안 됩니다.
또한 용량 계획은 사용량이 가장 많은 기간만 고려하기 때문에 중복 구성 요소를 사용 가능한 리소스로 간주해서는 안 됩니다. 버스트 또는 기타 비정상적인 시스템 동작을 수용하기 위해 최대 사용률이 시스템의 80% 포화도를 초과해서는 안 됩니다.
SCSI 또는 파이버 채널 하드 드라이브의 동작 분석 시 이전 섹션에서 설명한 원칙에 따라 분석해야 합니다. 각 프로토콜마다의 장점과 단점이 있음에도 불구하고 디스크당 성능을 제한하는 가장 중요한 것은 하드 드라이브의 기계적 제한 사항입니다.
스토리지 단위에서 채널을 분석할 때 SCSI 버스에서 사용할 수 있는 리소스 수를 계산할 때와 동일한 방법을 사용해야 합니다. Bandwidth를 블록 크기로 나눕니다. 예를 들어 스토리지 단위에 각각 20MBps의 최대 전송 속도를 지원하는 6개의 채널이 있는 경우 사용 가능한 총 I/O 및 데이터 전송량은 100MBps입니다. 총 100MBps가 아닌 120MBps인 이유는 스토리지 채널의 총 처리량이 채널 중 하나가 갑자기 중단된 경우 사용할 처리량을 초과해서는 안 되므로 5개의 작동 채널만 남게 됩니다. 물론 이 예제에서는 시스템이 모든 채널에 부하 및 내결함성을 균등하게 분산한다고 가정합니다.
이전 예제를 I/O 프로필로 전환할 수 있는지 여부는 애플리케이션 동작에 따라 다릅니다. Active Directory Jet I/O의 경우 최댓값은 초당 약 12,500I/O 또는 I/O당 100MBps ÷ 8KB입니다.
컨트롤러 모듈이 지원하는 처리량을 이해하기 위해 제조업체 사양도 가져와야 합니다. 이 예제에서 SAN에는 각각 7,500I/O를 지원하는 두 개의 컨트롤러 모듈이 있습니다. 중복성을 사용하지 않는 경우 총 시스템 처리량은 15,000IOPS입니다. 그러나 중복성이 필요한 시나리오에서는 7,500IOPS인 컨트롤러 중 하나의 제한에 따라 최대 처리량을 계산합니다. 블록 크기가 4KB라고 가정하면 이 임계값은 스토리지 채널이 지원할 수 있는 최대 12,500IOPS보다 훨씬 낮으므로 분석에서 병목 현상이 발생할 수 있습니다. 그러나 계획 목적으로 계획해야 하는 최대 I/O는 10,400I/O입니다.
데이터가 컨트롤러 모듈을 벗어날 경우, 1GBps 또는 128MBps로 평가된 파이버 채널 연결을 전송합니다. 이 크기는 모든 스토리지 장치 채널에서 총 100MBps의 대역폭을 초과하기 때문에 시스템에 병목 현상이 발생하지 않습니다. 또한 이 전송은 중복성으로 인해 두 파이버 채널 중 하나에만 있으므로 하나의 파이버 채널 연결이 작동을 중지하는 경우 나머지 연결은 여전히 데이터 전송 수요를 처리할 수 있는 충분한 용량을 가집니다.
그 뒤 데이터는 서버로 가는 중 SAN 스위치를 전송합니다. 스위치는 들어오는 요청을 처리한 다음 적절한 포트로 전달해야 하므로 처리 가능한 I/O의 양을 제한합니다. 그러나 제조업체 사양을 살펴보면 스위치 제한에 대해 알 수 있습니다. 예를 들어 시스템에 두 개의 스위치가 있고 각 스위치가 10,000IOPS를 처리할 수 있는 경우 총 처리량은 20,000IOPS가 됩니다. 내결함성 규칙에 따라 하나의 스위치가 작동을 중지하면 총 시스템 처리량은 10,000IOPS가 됩니다. 따라서 정상적인 상황에서는 80% 이상의 사용률 또는 8,000I/O를 사용하면 안 됩니다.
마지막으로, 서버에 설치하는 HBA는 처리 가능한 I/O의 양을 제한합니다. 일반적으로 중복성을 위해 두 번째 HBA를 설치하지만 SAN 스위치와 마찬가지로 시스템에서 처리할 수 있는 I/O 양을 계산하면 총 처리량은 N - 1 HBA가 됩니다.
캐싱 고려 사항
캐시는 모든 스토리지 시스템 위치에서 전반적인 성능에 큰 영향을 미칠 수 있는 구성 요소 중 하나입니다. 그러나 캐싱 알고리즘에 대한 자세한 분석은 이 문서에서 다루지 않습니다. 대신 디스크 하위 시스템의 캐싱에 대해 알아야 할 사항의 빠른 목록을 제공합니다.
- 캐싱은 많은 작은 쓰기 작업을 더 큰 I/O 블록으로 버퍼링하기 때문에 지속적인 순차 쓰기 I/O를 향상시킵니다. 또한 많은 작은 블록 대신 몇 가지 큰 블록에 스토리지 작업을 분해합니다. 이 최적화는 총 임의 및 순차 I/O 작업을 줄여 다른 I/O 작업에 더 많은 리소스를 사용할 수 있게 합니다.
- 캐싱은 스핀들이 데이터를 커밋할 수 있게 될 때까지 쓰기만 버퍼링하므로 스토리지 하위 시스템의 지속적인 쓰기 I/O 처리량을 향상하지 않습니다. 스핀들에서 사용 가능한 모든 I/O가 오랜 시간 동안 데이터에 의해 포화될 경우 캐시가 결국 채워집니다. 캐시를 비우려면 추가 스핀들을 제공하거나 시스템이 따라잡을 수 있도록 버스트 간 충분한 시간을 제공하여 캐시를 지우기에 충분한 I/O를 제공해야 합니다.
- 캐시가 클수록 버퍼에 더 많은 데이터가 허용되므로 캐시가 더 긴 포화 기간을 처리할 수 있습니다.
- 일반적인 스토리지 하위 시스템에서는 시스템에서 캐시에 데이터를 쓰기만 하기 때문에 OS에서 캐시를 사용하여 쓰기 성능이 향상되었습니다. 그러나 기본 미디어가 I/O 작업으로 포화되면 캐시가 채워지고 쓰기 성능이 일반 디스크 속도로 돌아갑니다.
- 읽기 I/O를 캐시할 때 캐시는 데이터를 책상에 순차 저장하고 캐시를 미리 읽을 수 있도록 할 때 가장 유용합니다. 다음 섹터에 시스템이 다음에 요청할 데이터가 포함된 것처럼 캐시가 즉시 다음 섹터로 이동할 수 있는 경우를 미리 읽습니다.
- 읽기 I/O가 임의인 경우 드라이브 컨트롤러에서 캐싱해도 디스크에서 읽을 수 있는 데이터의 양을 증가하지 않습니다. OS 또는 애플리케이션 기반 캐시 크기가 하드웨어 기반 캐시 크기보다 큰 경우, 디스크 읽기 속도를 향상시키려는 시도는 아무것도 변경되지 않습니다.
- Active Directory에서 캐시는 시스템에서 보유하는 RAM 양에 의해서만 제한됩니다.
SSD 고려 사항
SSD(반도체 드라이브)는 스핀들 기반 하드 디스크와 근본적으로 다릅니다. SSD는 낮은 대기 시간의, 더 높은 I/O 볼륨을 처리할 수 있습니다. SSD는 기가바이트당 비용 단위로 비용이 많이 들 수 있지만 I/O당 비용 측면에서 매우 저렴합니다. 그러나 SSD를 사용하는 용량 계획에는 스핀들에 대해 물어볼 수 있는 것과 동일한 질문, 즉 처리할 수 있는 IOPS 수와 해당 IOPS의 대기 시간은 얼마인가요?
다음은 SSD를 계획할 때 고려해야 할 몇 가지 사항입니다.
- IOPS 및 대기 시간 모두 제조업체 설계가 적용됩니다. 경우에 따라 특정 SSD 설계가 스핀들 기반 기술보다 성능이 더 나빠질 수 있습니다. SSD 또는 스핀들 사용 여부를 결정할 때, 모든 기술이 특정 방식으로 작동한다고 가정하는 대신 드라이브로 제조업체 사양 드라이브를 검토하고 유효성을 검사해야 합니다.
- IOPS 형식은 읽기 또는 쓰기 여부에 따라 다른 값을 가질 수 있습니다. AD DS 서비스는 주로 읽기 기반이기 때문에 dto 다른 애플리케이션 시나리오와 비교하는 데 사용하는 쓰기 기술의 영향을 덜 받습니다.
- 쓰기 내구성은 SSD 셀의 수명이 제한되어 있고 많이 사용하면 결국 저하된다는 가정입니다. 데이터베이스 드라이브의 경우 주로 읽는 I/O 프로필은 셀의 쓰기 내구성을 걱정할 필요가 없는 지점까지 확장합니다.
요약
스토리지가 집의 실내 배관과 같다고 상상해 보십시오. 데이터를 저장하는 미디어의 IOPS는 가정의 주 배출구와 같습니다. 주 배수구가 막히거나 크기 또는 파이프 붕괴로 인해 제한되면 배수구가 다시 막히고 물 사용량이 많을 때 제대로 작동하지 않습니다. 이 시나리오는 공유 환경에 동일한 기본 미디어가 있는 동일한 SAN, NAS 또는 iSCSI에서 공유 스토리지를 사용하는 하나 이상의 시스템이 있는 경우와 같습니다. 사용자 요구가 시스템의 유지 능력을 초과하기 때문에 성능이 저하됩니다.
마찬가지로 가상의 배관 시나리오에서는 다른 방법을 사용하여 막힘 및 기타 성능 문제를 해결할 수 있습니다.
- 축소된 배관 파이프 또는 너무 작은 배출을 해결하려면 파이프를 제대로 크기가 조정된 파이프로 바꿔야 합니다. 공유 스토리지 측면에서는 인프라 전체에서 공유 시스템에 새 하드웨어를 추가하거나 사용량을 재배포하는 것과 같습니다.
- 배출 막힘을 수행하려면 기본 문제 및 해당 위치를 식별한 다음 적절한 도구로 제거해야 합니다. 예를 들어, 부엌 싱크대 드레이닝의 비교적 간단한 막힘을 제거하기 위해 플런저 또는 드레이닝 클리너만 필요하지만, 막힌 물체를 포함하는 더 복잡한 막힘 문제에는 드레인 스네이크가 필요할 수 있습니다. 마찬가지로 공유 스토리지 시스템에서 성능 문제의 원인을 파악하면 시스템 수준 백업을 만들거나, 모든 서버에서 바이러스 백신 검사를 동기화하거나, 사용량이 많은 기간 동안 실행하는 조각 모음 소프트웨어를 동기화해야 하는지 여부를 파악할 수 있습니다.
배관 설계 대부분에서 여러 배수구가 주 배수구로 공급됩니다. 배수구가 막힐 때 물은 막힌 지점의 뒤쪽에 갇혀 있습니다. 접합 지점이 막히는 경우 해당 접합 지점 뒤의 모든 배수구가 배수를 중지합니다. 스토리지에서 접합 지점이 막히는 것은 오버로드된 스위치, 드라이버 호환성 문제 또는 동기화되지 않은 소프트웨어 작업과 같습니다. IOPS 및 I/O 크기를 측정하여 스토리지 시스템의 부하 처리 가능 여부를 확인한 다음 필요에 따라 시스템을 조정해야 합니다.
부록 D: 더 많은 RAM이 선택지가 아닌 환경에서 스토리지 문제 해결
가상화된 스토리지 전에 많은 스토리지 권장 사항이 다음 두 가지 용도로 제공되었습니다.
- OS 스핀들의 성능 문제가 데이터베이스 및 I/O 프로필의 성능에 영향을 주지 않도록 I/O를 격리합니다.
- 스핀들 기반 하드 드라이브 및 캐시가 AD DS 로그 파일의 순차 I/O와 함께 사용될 때 시스템에 제공할 수 있는 성능의 향상을 활용합니다. 순차 I/O를 별도의 물리적 드라이브로 격리하면 처리량도 증가할 수 있습니다.
새 스토리지 옵션을 사용하면 이전 스토리지 권장 사항을 기반으로 한 수많은 기본 가정이 더 이상 사실이 아닙니다. iSCSI, SAN, NAS, 가상 디스크 이미지 파일과 같은 가상화된 스토리지 시나리오는 종종 여러 호스트에서 기본 스토리지 미디어를 공유합니다. 이러한 차이는 I/O를 격리하고 순차 I/O를 최적화해야 한다는 가정을 부정합니다. 이제 공유 미디어에 액세스하는 다른 호스트는 도메인 컨트롤러에 대한 응답성을 줄일 수 있습니다.
스토리지 성능을 위한 용량 계획에 다음 세 가지를 고려해야 합니다.
- 콜드 캐시 상태
- 웜 캐시 상태
- 백업 및 복원
콜드 캐시 상태는 처음에 도메인 컨트롤러를 다시 부팅하거나 Active Directory 서비스를 다시 시작할 때이기 때문에 RAM에 Active Directory 데이터가 없습니다. 웜 캐시 상태는 도메인 컨트롤러가 안정적인 상태로 작동하고 데이터베이스를 캐시한 경우를 말합니다. 성능 디자인 측면에서 콜드 캐시를 웜하게 하는 것은 스프린트와 같으며, 완전히 따뜻한 캐시가 있는 서버를 실행하는 것은 마라톤과 같습니다. 용량을 추정할 때 두 가지 모두 고려해야 하므로 이러한 상태와 이러한 상태와 이러한 상태의 다양한 성능 프로필을 정의하는 것이 중요합니다. 예를 들어 웜 캐시 상태 중에 전체 데이터베이스를 캐시할 수 있는 RAM이 충분하다고 해서 콜드 캐시 상태 중에 성능을 최적화하는 데 도움이 되지는 않습니다.
두 캐시 시나리오에서 가장 중요한 것은 스토리지가 디스크에서 메모리로 데이터를 이동할 수 있는 속도입니다. 캐시를 데우면 쿼리가 데이터를 재사용하고, 캐시 적중률이 증가하며, 디스크로 이동하여 데이터를 검색하는 빈도가 감소함에 따라 시간이 지나면서 성능이 향상됩니다. 결과적으로 디스크로 이동해야 하는 경우 성능이 저하됩니다. 성능 저하는 일시적이고 캐시가 웜 상태와 시스템에서 허용하는 최대 크기에 도달하면 보통 사라집니다.
Active Directory에서 사용 가능한 IOPS를 측정하여 시스템이 디스크에서 데이터를 가져올 수 있는 빈도를 측정할 수 있습니다. 사용 가능한 IOPS 수에는 기본 스토리지에서 사용할 수 있는 IOPS 수도 적용됩니다. 계획 관점에서 볼 때 캐시 및 백업 또는 복원 상태를 따뜻하게 하는 것은 일반적으로 사용량이 많은 시간에 발생하며 DC 부하의 영향을 받는 예외적인 이벤트이므로 사용량이 적은 시간에만 이러한 상태를 입력하는 것 외에는 일반적인 권장 사항을 제공할 수 없습니다.
대부분의 경우에는 AD DS는 주로 읽기 I/O이며 90%의 읽기 비율과 10% 쓰기가 가능합니다. 읽기 I/O는 사용자 환경의 일반적인 병목 상태이지만, 쓰기 I/O는 쓰기 성능을 저하시키는 병목 현상입니다. 캐시는 NTDS.dit 파일에 대한 I/O 작업이 주로 임의이기 때문에 최소한의 이점을 읽기 I/O에 제공하는 경향이 있습니다. 그러므로 주요 우선 순위는 읽기 I/O 프로필 스토리지를 올바르게 구성하는 것입니다.
정상적인 운영 조건에서 스토리지 계획의 목표는 시스템이 AD DS에서 디스크로 요청을 반환하는 대기 시간을 최소화하는 것입니다. 미해결 및 보류 중인 I/O 작업의 수는 디스크의 경로 수보다 이하여야 합니다. 성능 모니터링 시나리오의 경우 일반적으로 LogicalDisk((<NTDS Database Drive>))\Avg Disk sec/Read 카운터가 20ms 미만이어야 합니다. 스토리지 유형에 따라 2~6밀리초 범위 내에서 가능한 한 스토리지 속도에 근접하게 운영 임계값을 훨씬 낮게 설정해야 합니다.
다음 선형 그래프는 스토리지 시스템 내의 디스크 대기 시간 측정을 보여 줍니다.
이 선형 그래프를 분석해 보겠습니다.
- 녹색으로 원을 그리는 차트의 왼쪽 영역에는 부하가 800IOPS에서 2,400IOPS로 증가함에 따라 대기 시간이 10ms로 일관됨을 보여 줍니다. 이 영역은 기본 스토리지가 I/O 요청을 얼마나 빨리 처리할 수 있는지에 대한 기준입니다. 그러나 이 기준은 사용하는 스토리지 솔루션 종류의 영향을 받습니다.
- 적갈색으로 원을 그리는 차트의 오른쪽 영역에는 기준선과 데이터 수집 끝 사이의 시스템 처리량이 표시됩니다. 처리량 자체는 변경되지 않지만 대기 시간이 높아집니다. 이 영역에서는 요청 볼륨이 기본 스토리지의 실제 한도를 초과할 때마다 큐에서 스토리지 하위 시스템으로 전송되기를 기다리는 데 요청이 더 오래 소요되는 방법을 보여 줍니다.
이제 이 데이터가 알려주는 내용에 대해 생각해 보겠습니다.
먼저 큰 그룹의 멤버십을 쿼리하는 사용자가 시스템이 디스크에서 1MB의 데이터를 읽어야 하는 경우를 가정해 보겠습니다. 필요한 I/O 양과 해당 값으로 작업이 소요되는 시간을 평가할 수 있습니다.
- 각 Active Directory 데이터베이스 페이지의 크기는 8KB입니다.
- 시스템에서 읽어야 하는 최소 페이지 수는 128개입니다.
- 따라서 다이어그램의 기준 영역에서 시스템은 디스크에서 데이터를 로드하고 클라이언트로 반환하는 데 최소 1.28초가 소요됩니다. 처리량이 권장 최댓값보다 훨씬 높은 20ms 표시에서 프로세스는 2.5초가 걸립니다.
이러한 숫자에 따라 다음 수식을 사용하여 캐시가 얼마나 빨리 준비되는지 계산할 수 있습니다.
I/O당 2,400IOPS × 8KB
이 계산을 실행한 후 이 시나리오의 캐시 웜 속도는 20MBps라고 할 수 있습니다. 즉, 시스템은 53초마다 약 1GB의 데이터베이스를 RAM에 로드합니다.
참고 항목
구성 요소가 디스크를 적극적으로 읽거나 쓰면서 짧은 기간 동안 대기 시간이 상승하는 것이 정상입니다. 예를 들어 시스템이 백업하거나 AD DS에서 가비지 수집 시 대기 시간이 증가합니다. 원래 사용량 추정치를 기반으로 이러한 정기적인 이벤트에 대한 추가 공간을 제공해야 합니다. 전반적인 작동에 영향을 주지 않고 이러한 급증을 수용할 수 있는 충분한 처리량을 제공하는 것을 목표로 합니다.
스토리지 시스템의 설계 방법에 따라 캐시가 얼마나 빨리 준비되는지에 대한 물리적 제한이 있습니다. 기본 스토리지가 수용할 수 있는 속도까지 캐시를 준비할 수 있는 유일한 방법은 들어오는 수신되는 요청입니다. 사용량이 많은 기간 동안 캐시를 미리 준비하려고 하는 스크립트를 실행하면 실제 클라이언트 요청과 경쟁하고, 전체 부하가 증가하며, 클라이언트 요청과 관련이 없는 데이터를 로드하고, 성능이 저하됩니다. 인공 측정값을 사용하여 캐시가 준비되게 하지 않는 것을 권장합니다.