SQL Server에서 좁고 넓은 계획을 사용하여 UPDATE 성능 문제 해결
적용 대상: SQL Server
UPDATE 어떤 경우에는 문이 더 빨라지고 다른 경우에는 속도가 느려질 수 있습니다. 업데이트된 행 수와 시스템의 리소스 사용량(차단, CPU, 메모리 또는 I/O)을 포함하여 이러한 분산으로 이어질 수 있는 여러 가지 요인이 있습니다. 이 문서에서는 분산의 한 가지 특정 이유, 즉 SQL Server에서 만든 쿼리 계획 선택에 대해 설명합니다.
좁고 넓은 계획은 무엇입니까?
클러스터형 UPDATE 인덱스 열에 대해 문을 실행하면 클러스터형 인덱스가 아닌 인덱스에 클러스터 인덱스 키가 포함되어 있으므로 SQL Server는 클러스터형 인덱스 자체뿐만 아니라 모든 비클러스터형 인덱스도 업데이트합니다.
SQL Server에는 업데이트를 수행하는 두 가지 옵션이 있습니다.
좁은 계획: 클러스터형 인덱스 키 업데이트와 함께 비클러스터형 인덱스 업데이트를 수행합니다. 이 간단한 접근 방식은 이해하기 쉽습니다. 클러스터형 인덱스를 업데이트한 다음 클러스터되지 않은 모든 인덱스를 동시에 업데이트합니다. SQL Server는 한 행을 업데이트하고 모두 완료될 때까지 다음 행으로 이동합니다. 이 방법을 좁은 계획 업데이트 또는 행별 업데이트라고 합니다. 그러나 업데이트할 비클러스터형 인덱스 데이터의 순서가 클러스터형 인덱스 데이터의 순서가 아닐 수 있으므로 이 작업은 상대적으로 비용이 많이 듭니다. 업데이트에 많은 인덱스 페이지가 포함된 경우 데이터가 디스크에 있을 때 많은 수의 임의 I/O 요청이 발생할 수 있습니다.
광범위한 계획: 성능을 최적화하고 임의 I/O를 줄이기 위해 SQL Server는 광범위한 계획을 선택할 수 있습니다. 클러스터형 인덱스 업데이트와 함께 비클러스터형 인덱스 업데이트는 수행하지 않습니다. 대신 먼저 메모리의 모든 비클러스터형 인덱스 데이터를 정렬한 다음, 모든 인덱스를 해당 순서로 업데이트합니다. 이 방법을 광범위한 계획(인덱스별 업데이트라고도 함)이라고 합니다.
다음은 좁고 넓은 계획의 스크린샷입니다.

SQL Server는 언제 광범위한 계획을 선택하나요?
SQL Server에서 광범위한 계획을 선택하려면 다음 두 가지 조건을 충족해야 합니다.
- 영향을 받은 행 수가 250개보다 큽니다.
- 클러스터되지 않은 인덱스(인덱스 페이지 수 * 8KB)의 리프 수준 크기는 최대 서버 메모리 설정의 1/1000 이상입니다.
좁고 넓은 계획은 어떻게 작동합니까?
범위가 좁고 넓은 계획의 작동 방식을 이해하려면 다음 환경에서 다음 단계를 수행합니다.
- SQL Server 2019 CU11
- 최대 서버 메모리 = 1,500MB
다음 스크립트를 실행하여 각각 41,501개의 행, 열에 하나의 클러스터형 인덱스 및 나머지 열
c1에 5개의 비클러스터형 인덱스가 있는 테이블을mytable1만듭니다.CREATE TABLE mytable1(c1 INT,c2 CHAR(30),c3 CHAR(20),c4 CHAR(30),c5 CHAR(30)) GO WITH cte AS ( SELECT ROW_NUMBER() OVER(ORDER BY c1.object_id) id FROM sys.columns CROSS JOIN sys.columns c1 ) INSERT mytable1 SELECT TOP 41000 id,REPLICATE('a',30),REPLICATE('a',20),REPLICATE('a',30),REPLICATE('a',30) FROM cte GO INSERT mytable1 SELECT TOP 250 50000,c2,c3,c4,c5 FROM mytable1 GO INSERT mytable1 SELECT TOP 251 50001,c2,c3,c4,c5 FROM mytable1 GO CREATE CLUSTERED INDEX ic1 ON mytable1(c1) CREATE INDEX ic2 ON mytable1(c2) CREATE INDEX ic3 ON mytable1(c3) CREATE INDEX ic4 ON mytable1(c4) CREATE INDEX ic5 ON mytable1(c5)다음 세 가지 T-SQL
UPDATE문을 실행하고 쿼리 계획을 비교합니다.UPDATE mytable1 SET c1=c1 WHERE c1=1 OPTION(RECOMPILE)- 한 행이 업데이트됨UPDATE mytable1 SET c1=c1 WHERE c1=50000 OPTION(RECOMPILE)- 250개 행이 업데이트됩니다.UPDATE mytable1 SET c1=c1 WHERE c1=50001 OPTION(RECOMPILE)- 251개 행이 업데이트됩니다.
첫 번째 기준(영향을 받는 행 수의 임계값은 250)을 기준으로 결과를 검사합니다.
다음 스크린샷은 첫 번째 조건을 기반으로 하는 결과를 보여줍니다.

예상대로 쿼리 최적화 프로그램은 영향을 받은 행 수가 250개 미만이므로 처음 두 쿼리에 대해 좁은 계획을 선택합니다. 영향을 받은 행 수가 250보다 큰 251이므로 세 번째 쿼리에 광범위한 계획이 사용됩니다.
두 번째 기준(리프 인덱스 크기의 메모리가 최대 서버 메모리 설정의 1/1000 이상)을 기준으로 결과를 검사합니다.
다음 스크린샷은 두 번째 조건을 기반으로 하는 결과를 보여줍니다.

세 번째
UPDATE쿼리에 대해 광범위한 계획이 선택됩니다. 그러나 인덱ic3스(열c3)는 계획에 표시되지 않습니다. 이 문제는 두 번째 기준이 충족되지 않기 때문에 발생합니다. 리프 페이지 인덱스 크기는 설정 최대 서버 메모리와 비교됩니다.열
c2의 데이터 형식은char(30)열c4이고c4, 열c3의 데이터 형식은 .입니다char(20). 각 인덱ic3스 행의 크기가 다른 행보다 작으므로 리프 페이지 수가 다른 행보다 작습니다.DMF(동적 관리 함수)
sys.dm_db_database_page_allocations의 도움으로 각 인덱스의 페이지 수를 계산할 수 있습니다. 인덱스의 경우 각 인덱스에ic2ic4ic5는 214페이지가 있고 그 중 209개는 리프 페이지입니다(결과는 약간 다를 수 있음). 리프 페이지에서 사용하는 메모리는 209 x 8 = 1,672KB입니다. 따라서 비율은 1672/(1500 x 1024) = 0.00108854101이며 1/1000보다 큽니다. 그러나ic3161페이지만 있습니다. 그 중 159페이지는 리프 페이지입니다. 비율은 159 x 8/(1500 x 1024) = 0.000828125이며 1/1000(0.001)보다 작습니다.조건을 충족하기 위해 더 많은 행을 삽입하거나 최대 서버 메모리를 줄이면 계획이 변경됩니다. 인덱스 리프 수준 크기를 1/1000보다 크게 만들려면 다음 명령을 실행하여 최대 서버 메모리 설정을 1,200으로 낮출 수 있습니다.
sp_configure 'show advanced options', 1; GO RECONFIGURE; GO sp_configure 'max server memory', 1200; GO RECONFIGURE GO UPDATE mytable1 SET c1=c1 WHERE c1=50001 OPTION(RECOMPILE) --251 rows are updated.이 경우 159 x 8/(1200 x 1024) = 0.00103515625 > 1/1000. 이 변경 후
ic3계획에 표시됩니다.자세한
show advanced options내용은 Transact-SQL 사용을 참조하세요.다음 스크린샷은 넓은 계획이 메모리 임계값에 도달할 때 모든 인덱스를 사용한다는 것을 보여줍니다.




넓은 계획이 좁은 계획보다 빠르나요?
대답은 데이터 및 인덱스 페이지가 버퍼 풀에 캐시되는지 여부에 따라 달라집니다.
데이터는 버퍼 풀에 캐시됩니다.
데이터가 버퍼 풀에 이미 있는 경우 넓은 계획이 포함된 쿼리는 I/O 성능(논리적 읽기가 아닌 물리적 읽기)을 개선하도록 설계되었기 때문에 좁은 계획에 비해 추가적인 성능 이점을 제공하지는 않습니다.
데이터가 버퍼 풀에 있을 때 넓은 계획이 좁은 계획보다 빠른지 테스트하려면 다음 환경에서 다음 단계를 수행합니다.
SQL Server 2019 CU11
최대 서버 메모리: 30,000MB
데이터 크기는 64MB이고 인덱스 크기는 약 127MB입니다.
데이터베이스 파일은 두 개의 서로 다른 실제 디스크에 있습니다.
- I:\sql19\dbWideplan.mdf
- H:\sql19\dbWideplan.ldf
다음 명령을 실행하여 다른 테이블을
mytable2만듭니다.CREATE TABLE mytable2(C1 INT,C2 INT,C3 INT,C4 INT,C5 INT) GO CREATE CLUSTERED INDEX IC1 ON mytable2(C1) CREATE INDEX IC2 ON mytable2(C2) CREATE INDEX IC3 ON mytable2(C3) CREATE INDEX IC4 ON mytable2(C4) CREATE INDEX IC5 ON mytable2(C5) GO DECLARE @N INT=1 WHILE @N<1000000 BEGIN DECLARE @N1 INT=RAND()*4500 DECLARE @N2 INT=RAND()*100000 DECLARE @N3 INT=RAND()*100000 DECLARE @N4 INT=RAND()*100000 DECLARE @N5 INT=RAND()*100000 INSERT mytable2 VALUES(@N1,@N2,@N3,@N4,@N5) SET @N+=1 END GO UPDATE STATISTICS mytable2 WITH FULLSCAN다음 두 쿼리를 실행하여 쿼리 계획을 비교합니다.
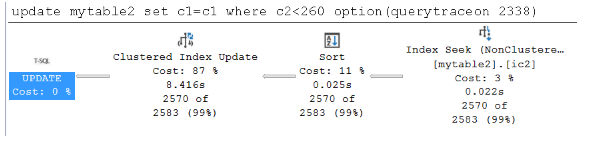
update mytable2 set c1=c1 where c2<260 option(querytraceon 8790) --trace flag 8790 will force Wide plan update mytable2 set c1=c1 where c2<260 option(querytraceon 2338) --trace flag 2338 will force Narrow plan자세한 내용은 추적 플래그 8790 및 추적 플래그 2338을 참조하세요.
넓은 계획이 있는 쿼리는 0.136초가 걸리고, 좁은 계획이 있는 쿼리는 0.112초밖에 걸리지 않습니다. 두 기간이 매우 가깝고 문이 실행되기 전에
UPDATE데이터가 버퍼에 이미 있으므로 인덱스별 업데이트(넓은 계획)가 덜 유용합니다.다음 스크린샷은 데이터가 버퍼 풀에 캐시될 때의 넓고 좁은 계획을 보여줍니다.


데이터가 버퍼 풀에 캐시되지 않음
데이터가 버퍼 풀에 없을 때 넓은 계획이 좁은 계획보다 빠른지 테스트하려면 다음 쿼리를 실행합니다.
참고 항목
테스트를 수행할 때는 SQL Server의 유일한 워크로드이고 디스크는 SQL Server 전용인지 확인합니다.
CHECKPOINT
GO
DBCC DROPCLEANBUFFERS
GO
WAITFOR DELAY '00:00:02' --wait for 1~2 seconds
UPDATE mytable2 SET c1=c1 WHERE c2 < 260 OPTION (QUERYTRACEON 8790) --force Wide plan
CHECKPOINT
GO
DBCC DROPCLEANBUFFERS
GO
WAITFOR DELAY '00:00:02' --wait for 1~2 SECONDS
UPDATE mytable2 SET c1=c1 WHERE c2 < 260 OPTION (QUERYTRACEON 2338) --force Narrow plan
광범위한 계획이 있는 쿼리는 3.554초가 걸리고, 계획이 좁은 쿼리는 6.701초가 걸립니다. 이번에는 광범위한 계획 쿼리가 더 빠르게 실행됩니다.
다음 스크린샷은 데이터가 버퍼 풀에 캐시되지 않은 경우의 광범위한 계획을 보여줍니다.

다음 스크린샷은 데이터가 버퍼 풀에 캐시되지 않는 경우의 좁은 계획을 보여줍니다.
데이터가 버퍼에 없는 경우 넓은 계획 쿼리가 항상 좁은 쿼리 계획보다 빠른가요?
대답은 "항상"입니다. 데이터가 버퍼에 없을 때 넓은 계획 쿼리가 항상 좁은 쿼리 계획보다 빠른지 테스트하려면 다음 단계를 수행합니다.
다음 명령을 실행하여 다른 테이블을
mytable2만듭니다.SELECT c1,c1 AS c2,c1 AS C3,c1 AS c4,c1 AS C5 INTO mytable3 FROM mytable2 GO CREATE CLUSTERED INDEX IC1 ON mytable3(C1) CREATE INDEX IC2 ON mytable3(C2) CREATE INDEX IC3 ON mytable3(C3) CREATE INDEX IC4 ON mytable3(C4) CREATE INDEX IC5 ON mytable3(C5) GO이
mytable3값은 데이터를 제외하고 동일합니다mytable2.mytable3에는 값이 같은 5개의 열이 모두 있으므로 클러스터형이 아닌 인덱스의 순서가 클러스터형 인덱스의 순서를 따릅니다. 이러한 데이터 정렬은 광범위한 계획의 이점을 최소화합니다.다음 명령을 실행하여 쿼리 계획을 비교합니다.
CHECKPOINT GO DBCC DROPCLEANBUFFERS go UPDATE mytable3 SET c1=c1 WHERE c2<12 OPTION(QUERYTRACEON 8790) --tf 8790 will force Wide plan CHECKPOINT GO DBCC DROPCLEANBUFFERS GO UPDATE mytable3 SET c1=c1 WHERE c2<12 OPTION(QUERYTRACEON 2338) --tf 2338 will force Narrow plan두 쿼리의 기간이 크게 줄어듭니다. 넓은 계획은 0.304초가 걸리며, 이는 이번에는 좁은 계획보다 약간 느립니다.
다음 스크린샷은 넓고 좁은 사용 시 성능 비교를 보여 줍니다.


광범위한 계획이 적용되는 시나리오
다음은 광범위한 계획이 적용되는 다른 시나리오입니다.
클러스터형 인덱스 열에는 고유 또는 기본 키가 있으며 여러 행이 업데이트됩니다.
시나리오를 재현하는 예제는 다음과 같습니다.
CREATE TABLE mytable4(c1 INT primary key,c2 INT,c3 INT,c4 INT)
GO
CREATE INDEX ic2 ON mytable4(c2)
CREATE INDEX ic3 ON mytable4(c3)
CREATE INDEX ic4 ON mytable4(c4)
GO
INSERT mytable4 VALUES(0,0,0,0)
INSERT mytable4 VALUES(1,1,1,1)
다음 스크린샷은 클러스터 인덱스가 고유 키를 가지고 있을 때 광범위한 계획이 사용됨을 보여줍니다.

자세한 내용은 고유 인덱스 유지 관리를 검토 하세요.
클러스터 인덱스 열이 파티션 구성표에 지정됨
시나리오를 재현하는 예제는 다음과 같습니다.
CREATE TABLE mytable5(c1 INT,c2 INT,c3 INT,c4 INT)
GO
IF EXISTS (SELECT * FROM sys.partition_schemes WHERE name='PS1')
DROP PARTITION SCHEME PS1
GO
IF EXISTS (SELECT * FROM sys.partition_functions WHERE name='PF1')
DROP PARTITION FUNCTION PF1
GO
CREATE PARTITION FUNCTION PF1(INT) AS
RANGE right FOR VALUES
(2000)
GO
CREATE PARTITION SCHEME PS1 AS
PARTITION PF1 all TO
([PRIMARY])
GO
CREATE CLUSTERED INDEX c1 ON mytable5(c1) ON PS1(c1)
CREATE INDEX c2 ON mytable5(c2)
CREATE INDEX c3 ON mytable5(c3)
CREATE INDEX c4 ON mytable5(c4)
GO
UPDATE mytable5 SET c1=c1 WHERE c1=1
다음 스크린샷은 파티션 구성표에 클러스터형 열이 있을 때 광범위한 계획이 사용됨을 보여줍니다.

클러스터형 인덱스 열은 파티션 구성표의 일부가 아니며 파티션 구성표 열이 업데이트됩니다.
시나리오를 재현하는 예제는 다음과 같습니다.
CREATE TABLE mytable6(c1 INT,c2 INT,c3 INT,c4 INT)
GO
IF EXISTS (SELECT * FROM sys.partition_schemes WHERE name='PS2')
DROP PARTITION SCHEME PS2
GO
IF EXISTS (SELECT * FROM sys.partition_functions WHERE name='PF2')
DROP PARTITION FUNCTION PF2
GO
CREATE PARTITION FUNCTION PF2(int) AS
RANGE right FOR VALUES
(2000)
GO
CREATE PARTITION SCHEME PS2 AS
PARTITION PF2 all TO
([PRIMARY])
GO
CREATE CLUSTERED INDEX c1 ON mytable6(c1) ON PS2(c2) --on c2 column
CREATE INDEX c3 ON mytable6(c3)
CREATE INDEX c4 ON mytable6(c4)
다음 스크린샷은 파티션 구성표 열을 업데이트할 때 광범위한 계획이 사용됨을 보여줍니다.

결론
SQL Server는 다음 조건이 동시에 충족되면 광범위한 계획 업데이트를 선택합니다.
- 영향을 받은 행 수가 250개보다 큽니다.
- 리프 인덱스의 메모리는 최대 서버 메모리 설정의 1/1000 이상입니다.
넓은 계획은 추가 메모리를 소비하는 대신 성능을 향상시킵니다.
예상 쿼리 계획을 사용하지 않는 경우 잘못된 통계(올바른 데이터 크기를 보고하지 않음), 최대 서버 메모리 설정 또는 매개 변수에 민감한 계획과 같은 기타 관련 없는 문제 때문일 수 있습니다.
광범위한 계획을 사용하는 문의 기간
UPDATE은 몇 가지 요인에 따라 달라지며, 경우에 따라 좁은 계획보다 더 오래 걸릴 수 있습니다.추적 플래그 8790 은 광범위한 계획을 강제로 적용합니다. 추적 플래그 2338 은 좁은 계획을 강제로 적용합니다.