SQL Server에서 높은 CPU 사용량 문제 해결
적용 대상: SQL Server
이 문서에서는 Microsoft SQL Server 실행하는 컴퓨터에서 CPU 사용량이 많아 발생하는 문제를 진단하고 해결하는 절차를 제공합니다. SQL Server CPU 사용량이 많은 원인은 여러 가지가 있을 수 있지만 가장 일반적인 원인은 다음과 같습니다.
- 다음 조건으로 인해 테이블 또는 인덱스 검색으로 인해 발생하는 높은 논리 읽기:
- 오래된 통계
- 누락된 인덱스
- PSP(매개 변수에 민감한 계획) 문제
- 잘못 설계된 쿼리
- 워크로드 증가
다음 단계를 사용하여 SQL Server CPU 사용량이 많은 문제를 해결할 수 있습니다.
1단계: SQL Server CPU 사용량이 많은지 확인
다음 도구 중 하나를 사용하여 SQL Server 프로세스가 실제로 CPU 사용량이 많은데 원인이 되는지 확인합니다.
작업 관리자: 프로세스 탭에서 SQL Server Windows NT-64 비트의 CPU 열 값이 100%에 가까운지 확인합니다.
성능 및 리소스 모니터(perfmon)
- 카운터:
Process/%User Time,% Privileged Time - 인스턴스: sqlservr
- 카운터:
다음 PowerShell 스크립트를 사용하여 60초 동안 카운터 데이터를 수집할 수 있습니다.
$serverName = $env:COMPUTERNAME $Counters = @( ("\\$serverName" + "\Process(sqlservr*)\% User Time"), ("\\$serverName" + "\Process(sqlservr*)\% Privileged Time") ) Get-Counter -Counter $Counters -MaxSamples 30 | ForEach { $_.CounterSamples | ForEach { [pscustomobject]@{ TimeStamp = $_.TimeStamp Path = $_.Path Value = ([Math]::Round($_.CookedValue, 3)) } Start-Sleep -s 2 } }지속적으로 90%를 초과하는 경우
% User Time(% 사용자 시간은 각 프로세서의 프로세서 시간 합계이며 최대값은 100% * (CPU 없음)) SQL Server 프로세스로 인해 CPU 사용량이 높습니다. 그러나% Privileged time이 90%를 지속적으로 초과하는 경우 바이러스 백신 소프트웨어, 기타 드라이버 또는 컴퓨터의 다른 OS 구성 요소로 인해 CPU 사용량이 많아집니다. 시스템 관리자와 협력하여 이 동작의 근본 원인을 분석해야 합니다.성능 대시보드: SQL Server Management Studio에서 SQLServerInstance>를 마우스 오른쪽 단추로 클릭하고< 보고서>표준 보고서>성능 대시보드를 선택합니다.
대시보드는 가로 막대형 차트가 있는 시스템 CPU 사용률 이라는 그래프를 보여 줍니다. 어두운 색은 SQL Server 엔진 CPU 사용률을 나타내고 밝은 색은 전체 운영 체제 CPU 사용률을 나타냅니다(참조는 그래프의 범례 참조). 순환 새로 고침 단추 또는 F5 를 선택하여 업데이트된 사용률을 확인합니다.
2단계: CPU 사용량에 영향을 주는 쿼리 식별
Sqlservr.exe 프로세스에서 CPU 사용량을 증가시키는 경우 가장 일반적인 이유는 테이블 또는 인덱스 검색을 수행하는 SQL Server 쿼리이며 그 다음은 정렬, 해시 작업 및 루프(중첩 루프 연산자 또는 WHILE(T-SQL)입니다. 쿼리가 현재 사용 중인 CPU의 양을 파악하려면 전체 CPU 용량에서 다음 문을 실행합니다.
DECLARE @init_sum_cpu_time int,
@utilizedCpuCount int
--get CPU count used by SQL Server
SELECT @utilizedCpuCount = COUNT( * )
FROM sys.dm_os_schedulers
WHERE status = 'VISIBLE ONLINE'
--calculate the CPU usage by queries OVER a 5 sec interval
SELECT @init_sum_cpu_time = SUM(cpu_time) FROM sys.dm_exec_requests
WAITFOR DELAY '00:00:05'
SELECT CONVERT(DECIMAL(5,2), ((SUM(cpu_time) - @init_sum_cpu_time) / (@utilizedCpuCount * 5000.00)) * 100) AS [CPU from Queries as Percent of Total CPU Capacity]
FROM sys.dm_exec_requests
현재 높은 CPU 활동을 담당하는 쿼리를 식별하려면 다음 명령문을 실행합니다.
SELECT TOP 10 s.session_id,
r.status,
r.cpu_time,
r.logical_reads,
r.reads,
r.writes,
r.total_elapsed_time / (1000 * 60) 'Elaps M',
SUBSTRING(st.TEXT, (r.statement_start_offset / 2) + 1,
((CASE r.statement_end_offset
WHEN -1 THEN DATALENGTH(st.TEXT)
ELSE r.statement_end_offset
END - r.statement_start_offset) / 2) + 1) AS statement_text,
COALESCE(QUOTENAME(DB_NAME(st.dbid)) + N'.' + QUOTENAME(OBJECT_SCHEMA_NAME(st.objectid, st.dbid))
+ N'.' + QUOTENAME(OBJECT_NAME(st.objectid, st.dbid)), '') AS command_text,
r.command,
s.login_name,
s.host_name,
s.program_name,
s.last_request_end_time,
s.login_time,
r.open_transaction_count
FROM sys.dm_exec_sessions AS s
JOIN sys.dm_exec_requests AS r ON r.session_id = s.session_id CROSS APPLY sys.Dm_exec_sql_text(r.sql_handle) AS st
WHERE r.session_id != @@SPID
ORDER BY r.cpu_time DESC
현재 쿼리가 CPU를 구동하지 않는 경우 다음 명령문을 실행하여 과거 CPU 바운드 쿼리를 찾을 수 있습니다.
SELECT TOP 10 qs.last_execution_time, st.text AS batch_text,
SUBSTRING(st.TEXT, (qs.statement_start_offset / 2) + 1, ((CASE qs.statement_end_offset WHEN - 1 THEN DATALENGTH(st.TEXT) ELSE qs.statement_end_offset END - qs.statement_start_offset) / 2) + 1) AS statement_text,
(qs.total_worker_time / 1000) / qs.execution_count AS avg_cpu_time_ms,
(qs.total_elapsed_time / 1000) / qs.execution_count AS avg_elapsed_time_ms,
qs.total_logical_reads / qs.execution_count AS avg_logical_reads,
(qs.total_worker_time / 1000) AS cumulative_cpu_time_all_executions_ms,
(qs.total_elapsed_time / 1000) AS cumulative_elapsed_time_all_executions_ms
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(sql_handle) st
ORDER BY(qs.total_worker_time / qs.execution_count) DESC
3단계: 통계 업데이트
CPU 사용량이 가장 높은 쿼리를 식별한 후 이러한 쿼리에서 사용되는 테이블의 통계를 업데이트합니다. sp_updatestats 시스템 저장 프로시저를 사용하여 현재 데이터베이스에 있는 모든 사용자 정의 테이블 및 내부 테이블의 통계를 업데이트할 수 있습니다. 예시:
exec sp_updatestats
참고 항목
sp_updatestats 시스템 저장 프로시저는 현재 데이터베이스의 모든 사용자 정의 테이블 및 내부 테이블을 기준으로 UPDATE STATISTICS를 실행합니다. 정기적인 유지 관리를 위해 통계가 정기적인 일정 유지 관리를 통해 최신 상태로 유지되는지 확인합니다. Adaptive Index Defrag와 같은 솔루션을 사용하여 하나 이상의 데이터베이스에 대한 인덱스 조각 모음 및 통계 업데이트를 자동으로 관리합니다. 이 절차는 다른 매개 변수 사이에서 조각화 수준에 따라 인덱스를 다시 작성하거나 다시 구성할지 여부를 자동으로 선택하고 통계를 선형 임계값으로 업데이트합니다.
sp_updatestats에 대한 자세한 내용은 sp_updatestats를 참조하세요.
그래도 SQL Server에서 CPU 용량을 과도하게 사용하는 경우 다음 단계로 이동합니다.
4단계: 누락된 인덱스 추가
인덱스가 누락되어 실행 중인 쿼리가 느려지고 CPU 사용량이 높아질 수 있습니다. 누락된 인덱스를 식별하고 생성하여 이러한 성능 영향을 개선할 수 있습니다.
다음 쿼리를 실행하여 CPU 사용량이 높고 쿼리 계획에 하나 이상의 누락된 인덱스가 포함된 쿼리를 식별합니다.
-- Captures the Total CPU time spent by a query along with the query plan and total executions SELECT qs_cpu.total_worker_time / 1000 AS total_cpu_time_ms, q.[text], p.query_plan, qs_cpu.execution_count, q.dbid, q.objectid, q.encrypted AS text_encrypted FROM (SELECT TOP 500 qs.plan_handle, qs.total_worker_time, qs.execution_count FROM sys.dm_exec_query_stats qs ORDER BY qs.total_worker_time DESC) AS qs_cpu CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS q CROSS APPLY sys.dm_exec_query_plan(plan_handle) p WHERE p.query_plan.exist('declare namespace qplan = "http://schemas.microsoft.com/sqlserver/2004/07/showplan"; //qplan:MissingIndexes')=1식별된 쿼리에 대한 실행 계획을 검토하고 필요한 변경을 수행하여 쿼리를 조정합니다. 다음 스크린샷은 SQL Server 쿼리에 대한 누락된 인덱스가 표시되는 예를 보여줍니다. 쿼리 계획의 누락된 인덱스 부분을 마우스 오른쪽 버튼으로 클릭한 다음 누락된 인덱스 세부 정보를 선택하여 SQL Server Management Studio의 다른 창에서 인덱스를 생성합니다.
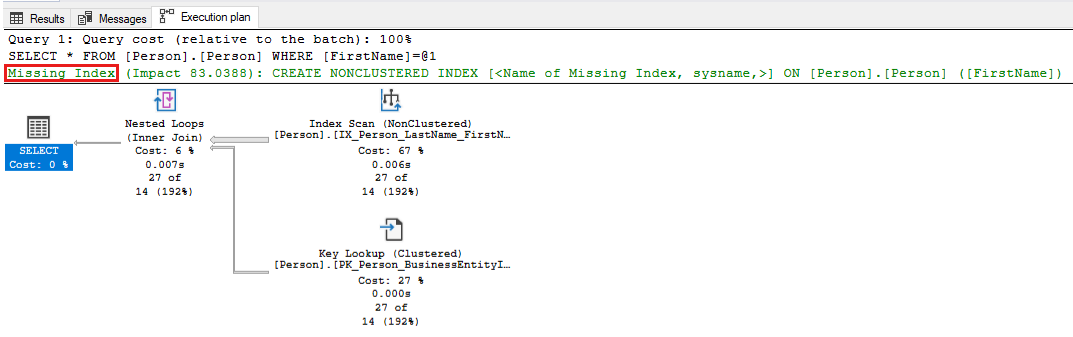
다음 쿼리를 사용하여 누락된 인덱스를 확인하고 향상된 측정값이 높은 권장 인덱스를 적용합니다. improvement_measure 값이 가장 높은 출력의 상위 5개 또는 10개 권장 사항으로 시작합니다. 이러한 인덱스는 성능에 가장 큰 긍정적인 영향을 줍니다. 이러한 인덱스를 적용할지 여부를 결정하고 애플리케이션에 대한 성능 테스트가 수행되었는지 확인합니다. 그런 다음 원하는 애플리케이션 성능 결과를 얻을 때까지 누락된 인덱스 권장 사항을 계속 적용합니다. 이 주제에 대한 자세한 내용은 누락된 인덱스 제안으로 비클러스터형 인덱스 조정을 참조하세요.
SELECT CONVERT(VARCHAR(30), GETDATE(), 126) AS runtime, mig.index_group_handle, mid.index_handle, CONVERT(DECIMAL(28, 1), migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans)) AS improvement_measure, 'CREATE INDEX missing_index_' + CONVERT(VARCHAR, mig.index_group_handle) + '_' + CONVERT(VARCHAR, mid.index_handle) + ' ON ' + mid.statement + ' (' + ISNULL(mid.equality_columns, '') + CASE WHEN mid.equality_columns IS NOT NULL AND mid.inequality_columns IS NOT NULL THEN ',' ELSE '' END + ISNULL(mid.inequality_columns, '') + ')' + ISNULL(' INCLUDE (' + mid.included_columns + ')', '') AS create_index_statement, migs.*, mid.database_id, mid.[object_id] FROM sys.dm_db_missing_index_groups mig INNER JOIN sys.dm_db_missing_index_group_stats migs ON migs.group_handle = mig.index_group_handle INNER JOIN sys.dm_db_missing_index_details mid ON mig.index_handle = mid.index_handle WHERE CONVERT (DECIMAL (28, 1), migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans)) > 10 ORDER BY migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans) DESC

5단계: 매개 변수에 민감한 문제 조사 및 해결
DBCC FREEPROCCACHE 명령을 사용하여 계획 캐시를 해제하고 높은 CPU 사용량 문제를 해결하는지 확인할 수 있습니다. 문제가 해결되면 매개 변수에 민감한 문제(PSP, "매개변수 스니핑 문제"라고도 함)를 나타냅니다.
참고 항목
매개 변수 없이 DBCC FREEPROCCACHE을(를) 사용하면 계획 캐시에서 컴파일된 모든 계획이 제거됩니다. 이렇게 하면 새 쿼리 실행이 다시 컴파일되므로 각 새 쿼리에 대해 한 번 더 긴 기간이 발생합니다. 가장 좋은 방법은 DBCC FREEPROCCACHE ( plan_handle | sql_handle )을(를) 사용하여 문제를 일으킬 수 있는 쿼리를 식별한 다음 해당 개별 쿼리를 처리하는 것입니다.
매개 변수에 민감한 문제를 완화하려면 다음 방법을 사용하세요. 각 방법에는 관련된 절충안과 단점이 있습니다.
RECOMPILE 쿼리 힌트를 사용합니다. 2단계에서 식별된 하나 이상의 고성능 CPU 쿼리에
RECOMPILE쿼리 힌트를 추가할 수 있습니다. 이 힌트는 컴파일 CPU 사용량의 약간 증가와 각 쿼리 실행에 대한 최적의 성능 사이의 균형을 유지하는 데 도움이 됩니다. 자세한 내용은 매개 변수 및 실행 계획 재사용, 매개 변수 민감도 및 RECOMPILE 쿼리 힌트를 참조하세요.다음은 이 힌트를 쿼리에 적용하는 방법의 예입니다.
SELECT * FROM Person.Person WHERE LastName = 'Wood' OPTION (RECOMPILE)실제 매개변수 값을 데이터의 대부분의 값을 포함하는 보다 일반적인 매개변수 값으로 재정의하려면 OPTIMIZE FOR 쿼리 힌트를 사용합니다. 이 옵션을 사용하려면 최적의 매개변수 값 및 관련 계획 특성에 대한 완전히 이해해야 합니다. 다음은 쿼리에서 이 힌트를 사용하는 방법의 예입니다.
DECLARE @LastName Name = 'Frintu' SELECT FirstName, LastName FROM Person.Person WHERE LastName = @LastName OPTION (OPTIMIZE FOR (@LastName = 'Wood'))밀도 벡터 평균으로 실제 매개 변수 값을 무시하려면 OPTIMIZE FOR UNKNOWN 쿼리 힌트를 사용합니다. 지역 변수에서 들어오는 매개 변수 값을 캡처한 다음 매개변수 자체를 사용하는 대신 술어 내에서 지역 변수를 사용하여 이를 수행할 수도 있습니다. 이렇게 하면 평균 밀도가 허용 가능한 성능을 제공하기에 충분할 수 있습니다.
매개 변수 스니핑을 완전히 비활성화하려면 DISABLE_PARAMETER_SNIFFING 쿼리 힌트를 사용합니다. 다음은 쿼리에서 사용하는 방법의 예입니다.
SELECT * FROM Person.Address WHERE City = 'SEATTLE' AND PostalCode = 98104 OPTION (USE HINT ('DISABLE_PARAMETER_SNIFFING'))캐시에서 재컴파일을 방지하려면 KEEPFIXED PLAN 쿼리 힌트를 사용합니다. 이 해결 방법은 "충분히 좋은" 공통 계획이 이미 캐시에 있는 계획이라고 가정합니다. 또한 자동 통계 업데이트를 사용하지 않도록 설정하여 좋은 계획이 제거되고 새로운 잘못된 계획이 컴파일될 가능성을 줄일 수 있습니다.
애플리케이션 코드가 수정될 때까지 임시 솔루션으로 DBCC FREEPROCCACHE 명령을 사용합니다. 이
DBCC FREEPROCCACHE (plan_handle)명령을 사용하여 문제를 일으키는 계획만 제거할 수 있습니다. 예를 들어 AdventureWorks에서Person.Person테이블을 참조하는 쿼리 계획을 찾으려면 이 쿼리를 사용하여 쿼리 핸들을 찾을 수 있습니다. 그런 다음 쿼리 결과의 두 번째 열에 생성된DBCC FREEPROCCACHE (plan_handle)을(를) 사용하여 캐시에서 특정 쿼리 계획을 해제할 수 있습니다.SELECT text, 'DBCC FREEPROCCACHE (0x' + CONVERT(VARCHAR (512), plan_handle, 2) + ')' AS dbcc_freeproc_command FROM sys.dm_exec_cached_plans CROSS APPLY sys.dm_exec_query_plan(plan_handle) CROSS APPLY sys.dm_exec_sql_text(plan_handle) WHERE text LIKE '%person.person%'
6단계: SARGability 문제 조사 및 해결
SQL Server 엔진이 인덱스 검색을 사용하여 쿼리 실행 속도를 높일 수 있는 경우 쿼리의 조건자는 SARGable(검색 ARGument 가능)으로 간주됩니다. 많은 쿼리 디자인은 SARGability를 방지하고 테이블 또는 인덱스 검사 및 높은 CPU 사용량으로 이끕니다. 문자열 리터럴 값과 비교하기 전에 모든 ProductNumber을(를) 검색하고 여기에 SUBSTRING() 함수를 적용해야 하는 AdventureWorks 데이터베이스에 대한 다음 쿼리를 고려합니다. 보시다시피 테이블의 모든 행을 먼저 가져온 다음 비교하기 전에 함수를 적용해야 합니다. 테이블에서 모든 행을 가져오는 것은 테이블 또는 인덱스 검사를 의미하므로 CPU 사용량이 증가합니다.
SELECT ProductID, Name, ProductNumber
FROM [Production].[Product]
WHERE SUBSTRING(ProductNumber, 0, 4) = 'HN-'
검색 조건자의 열에 함수 또는 계산을 적용하면 일반적으로 쿼리를 비정형으로 만들고 CPU 사용량이 높아집니다. 솔루션에는 일반적으로 SARGable을 만들기 위해 창의적인 방식으로 쿼리를 다시 작성하는 작업이 포함됩니다. 이 예에 대한 가능한 해결책은 쿼리 술어에서 함수를 제거하고 다른 열을 검색하고 동일한 결과를 달성하는 이 재작성입니다.
SELECT ProductID, Name, ProductNumber
FROM [Production].[Product]
WHERE Name LIKE 'Hex%'
다음은 영업 관리자가 대량 주문에 대해 10%의 판매 수수료를 제공하고 $300보다 큰 수수료가 있는 주문을 확인하려는 또 다른 예입니다. 논리적이지만 비구성적인 방법은 다음과 같습니다.
SELECT DISTINCT SalesOrderID, UnitPrice, UnitPrice * 0.10 [10% Commission]
FROM [Sales].[SalesOrderDetail]
WHERE UnitPrice * 0.10 > 300
다음은 계산이 술어의 다른 쪽으로 이동되는 쿼리의 덜 직관적이지만 SARGable 재작성입니다.
SELECT DISTINCT SalesOrderID, UnitPrice, UnitPrice * 0.10 [10% Commission]
FROM [Sales].[SalesOrderDetail]
WHERE UnitPrice > 300/0.10
SARGability는 WHERE 절뿐만 아니라 JOINs, HAVING, GROUP BY 및 ORDER BY 절에도 적용됩니다. 쿼리에서 SARGability 방지의 빈번한 발생은 열 스캔으로 이어지는 WHERE 또는 JOIN 절에서 사용되는 CONVERT(), CAST(), ISNULL(), COALESCE() 함수와 관련됩니다. 데이터 형식 변환의 경우(CONVERT 또는 CAST), 솔루션은 동일한 데이터 형식을 비교하고 있는지 확인하는 것일 수 있습니다. 다음은 JOIN에서 T1.ProdID 열이 INT 데이터 형식으로 명시적으로 변환되는 예입니다. 변환은 조인 열에 대한 인덱스 사용을 무효화합니다. 데이터 형식이 다르고 SQL Server가 데이터 형식 중 하나를 변환하여 조인을 수행하는 암시적 변환에서도 동일한 문제가 발생합니다.
SELECT T1.ProdID, T1.ProdDesc
FROM T1 JOIN T2
ON CONVERT(int, T1.ProdID) = T2.ProductID
WHERE t2.ProductID BETWEEN 200 AND 300
T1 테이블 검색을 피하기 위해 적절한 계획과 설계 후에 ProdID 열의 기본 데이터 형식을 변경한 다음 변환 함수 ON T1.ProdID = T2.ProductID을(를) 사용하지 않고 두 열을 결합할 수 있습니다.
또 다른 솔루션은 동일한 CONVERT() 함수를 사용하는 계산 열을 T1에 만든 다음 인덱스로 만드는 것입니다. 이렇게 하면 쿼리 최적화 프로그램에서 쿼리를 변경할 필요 없이 해당 인덱스 사용을 허용합니다.
ALTER TABLE dbo.T1 ADD IntProdID AS CONVERT (INT, ProdID);
CREATE INDEX IndProdID_int ON dbo.T1 (IntProdID);
경우에 따라 SARGability를 허용하기 위해 쿼리를 쉽게 다시 작성할 수 없습니다. 이러한 경우 인덱스가 있는 계산 열이 도움이 될 수 있는지 확인하거나 더 높은 CPU 시나리오로 이어질 수 있다는 인식과 함께 쿼리를 그대로 유지합니다.
7단계: 고부하 추적 기능 사용 안 함
SQL Server 성능에 영향을 미치고 CPU 사용량을 증가시키는 SQL 추적 또는 XEvent 추적 기능을 확인합니다. 예를 들어 다음 이벤트를 사용하면 많은 SQL Server 작업을 추적하는 경우 높은 CPU 사용량이 발생할 수 있습니다.
- 쿼리 계획 XML 이벤트(
query_plan_profile,query_post_compilation_showplan,query_post_execution_plan_profile,query_post_execution_showplan,query_pre_execution_showplan) - 문 수준 이벤트(
sql_statement_completed,sql_statement_starting,sp_statement_starting,sp_statement_completed) - 로그인 이벤트 및 로그아웃 이벤트(
login,process_login_finish,login_event,logout) - 잠금 이벤트(
lock_acquired,lock_cancel,lock_released) - 대기 이벤트(
wait_info,wait_info_external) - SQL 감사 이벤트(해당 그룹의 감사된 그룹 및 SQL Server 활동에 따라 다름)
활성 XEvent 또는 서버 추적을 식별하려면 다음 쿼리를 실행합니다.
PRINT '--Profiler trace summary--'
SELECT traceid, property, CONVERT(VARCHAR(1024), value) AS value FROM::fn_trace_getinfo(
default)
GO
PRINT '--Trace event details--'
SELECT trace_id,
status,
CASE WHEN row_number = 1 THEN path ELSE NULL end AS path,
CASE WHEN row_number = 1 THEN max_size ELSE NULL end AS max_size,
CASE WHEN row_number = 1 THEN start_time ELSE NULL end AS start_time,
CASE WHEN row_number = 1 THEN stop_time ELSE NULL end AS stop_time,
max_files,
is_rowset,
is_rollover,
is_shutdown,
is_default,
buffer_count,
buffer_size,
last_event_time,
event_count,
trace_event_id,
trace_event_name,
trace_column_id,
trace_column_name,
expensive_event
FROM
(SELECT t.id AS trace_id,
row_number() over(PARTITION BY t.id order by te.trace_event_id, tc.trace_column_id) AS row_number,
t.status,
t.path,
t.max_size,
t.start_time,
t.stop_time,
t.max_files,
t.is_rowset,
t.is_rollover,
t.is_shutdown,
t.is_default,
t.buffer_count,
t.buffer_size,
t.last_event_time,
t.event_count,
te.trace_event_id,
te.name AS trace_event_name,
tc.trace_column_id,
tc.name AS trace_column_name,
CASE WHEN te.trace_event_id in (23, 24, 40, 41, 44, 45, 51, 52, 54, 68, 96, 97, 98, 113, 114, 122, 146, 180) THEN CAST(1 as bit) ELSE CAST(0 AS BIT) END AS expensive_event FROM sys.traces t CROSS APPLY::fn_trace_geteventinfo(t.id) AS e JOIN sys.trace_events te ON te.trace_event_id = e.eventid JOIN sys.trace_columns tc ON e.columnid = trace_column_id) AS x
GO
PRINT '--XEvent Session Details--'
SELECT sess.NAME 'session_name', event_name, xe_event_name, trace_event_id,
CASE WHEN xemap.trace_event_id IN(23, 24, 40, 41, 44, 45, 51, 52, 54, 68, 96, 97, 98, 113, 114, 122, 146, 180)
THEN Cast(1 AS BIT)
ELSE Cast(0 AS BIT)
END AS expensive_event
FROM sys.dm_xe_sessions sess
JOIN sys.dm_xe_session_events evt
ON sess.address = evt.event_session_address
INNER JOIN sys.trace_xe_event_map xemap
ON evt.event_name = xemap.xe_event_name
GO
8단계: 스핀 잠금 경합으로 인한 높은 CPU 사용량 수정
스핀 잠금 경합으로 인한 일반적인 높은 CPU 사용량을 해결하려면 다음 섹션을 참조하세요.
스핀 잠금 경합 SOS_CACHESTORE
SQL Server 인스턴스에서 스핀 잠금 경합이 심 SOS_CACHESTORE 하거나 계획되지 않은 쿼리 워크로드에서 쿼리 계획이 자주 제거되는 경우 다음 문서를 참조하고 명령을 사용하여 추적 플래그 T174 를 DBCC TRACEON (174, -1) 사용하도록 설정합니다.
해결 방법: 임시 SQL Server 계획 캐시에서 SOS_CACHESTORE 스핀 잠금 경합은 SQL Server에서 CPU 사용량을 증가시킵니다.
T174 사용으로 높은 CPU 조건이 확인되면 SQL Server 구성 관리자를 사용하여 시작 매개 변수로 사용하도록 설정합니다.
대용량 메모리 컴퓨터에서 SOS_BLOCKALLOCPARTIALLIST 스핀 잠금 경합으로 인한 임의 높은 CPU 사용량
스핀 잠금 경합으로 인해 SQL Server 인스턴스에서 임의 SOS_BLOCKALLOCPARTIALLIST 로 높은 CPU 사용량이 발생하는 경우 SQL Server 2019에 누적 업데이트 21을 적용하는 것이 좋습니다. 이 문제를 해결하는 방법에 대한 자세한 내용은 임시 완화를 제공하는 버그 참조 2410400 및 DBCC DROPCLEANBUFFERS 를 참조하세요.
고급 컴퓨터의 XVB_list 스핀 잠금 경합으로 인한 높은 CPU 사용량
SQL Server 인스턴스가 높은 구성 컴퓨터(CPU(최신 세대 프로세서)가 많은 고급 시스템)의 스핀 잠금 경합 XVB_LIST 으로 인해 높은 CPU 시나리오가 발생하는 경우 TF8101과 함께 추적 플래그 TF8102를 사용하도록 설정합니다.
참고 항목
CPU 사용량이 많을 경우 다른 많은 스핀 잠금 유형에서 스핀 잠금 경합이 발생할 수 있습니다. 스핀 잠금에 대한 자세한 내용은 SQL Server에서 스핀 잠금 경합 진단 및 해결을 참조 하세요.
9단계: 가상 머신 환경 구성
가상 머신을 사용하는 경우 CPU를 과도하게 프로비전하지 않고 CPU가 올바르게 구성되었는지 확인합니다. 자세한 내용은 ESX/ESXi 가상 머신 성능 문제 해결(2001003)을 참조하세요.
10단계: 더 많은 CPU를 사용하도록 시스템 강화
개별 쿼리 인스턴스에서는 CPU 용량을 거의 사용하지 않지만 모든 쿼리의 워크로드 전체로 인해 CPU 사용량이 많은 경우 CPU를 더 추가하여 컴퓨터를 확장하는 것이 좋습니다. 다음 쿼리를 사용하여 실행당 평균 및 최대 CPU 사용량의 특정 임계값을 초과하고 시스템에서 여러 번 실행된 쿼리의 수를 찾습니다(환경에 맞게 두 변수의 값을 수정해야 합니다).
-- Shows queries where Max and average CPU time exceeds 200 ms and executed more than 1000 times
DECLARE @cputime_threshold_microsec INT = 200*1000
DECLARE @execution_count INT = 1000
SELECT qs.total_worker_time/1000 total_cpu_time_ms,
qs.max_worker_time/1000 max_cpu_time_ms,
(qs.total_worker_time/1000)/execution_count average_cpu_time_ms,
qs.execution_count,
q.[text]
FROM sys.dm_exec_query_stats qs CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS q
WHERE (qs.total_worker_time/execution_count > @cputime_threshold_microsec
OR qs.max_worker_time > @cputime_threshold_microsec )
AND execution_count > @execution_count
ORDER BY qs.total_worker_time DESC