Always On 가용성 그룹 장애 조치(failover) 문제 해결
참고
이 문서에 설명된 수동 분석을 자동화하려면 AGDiag를 사용하여 가용성 그룹 상태 이벤트 진단을 참조하세요.
이 문서에서는 가용성 그룹이 장애 조치(failover)된 이유를 확인하는 데 도움이 되는 문제 해결 단계를 제공합니다.
Always On 상태 문제 또는 장애 조치(failover)의 증상 및 효과
Always On 기본 복제본(replica), 기본 클러스터 및 시스템 상태를 호스팅하는 Microsoft SQL Server instance 상태를 보장하기 위해 다양한 메커니즘을 통해 강력한 상태 모니터링을 구현합니다. Windows 클러스터 또는 Always On 상태 문제가 식별되면 프로덕션 워크로드가 일시적으로 중단됩니다.
상태 상태가 검색되면 일반적으로 다음과 같은 이벤트 시퀀스가 발생합니다. 이 문제 해결사 전체에서 상태 이벤트는 다음 이벤트를 참조하여 언급됩니다.
가용성 그룹 복제본 및 데이터베이스는 주 역할에서 해결 역할로 전환됩니다.
가용성 그룹 데이터베이스는 오프라인으로 전환되며 더 이상 액세스할 수 없습니다.
Windows 클러스터는 가용성 그룹 클러스터된 리소스를 실패로 표시합니다.
Windows 클러스터는 가용성 그룹 역할을 다시 온라인 상태로 전환하려고 시도합니다(원래 또는 자동 장애 조치(failover) 파트너 복제본(replica)).
가용성 그룹 역할은 Always On 및 Windows 클러스터 상태 모니터링에서 정상으로 검색된 경우 성공적으로 온라인 상태가 됩니다.
성공하면 가용성 그룹 복제본 및 데이터베이스가 기본 역할로 전환되고 가용성 그룹 데이터베이스가 온라인 상태가 되어 애플리케이션에서 액세스할 수 있습니다.
애플리케이션이 가용성 그룹 데이터베이스에 액세스할 수 없음
상태 상태가 검색되면 가용성 그룹 복제본(replica) 데이터베이스가 해결 역할로 전환되고 가용성 그룹 데이터베이스가 오프라인 상태가 됩니다. 복제본(replica) 기본 역할(원래 복제본(replica) 서버 또는 장애 조치(failover) 파트너 복제본(replica) 서버)에서 온라인 상태가 되면 복제본(replica) 및 데이터베이스가 다시 온라인으로 전환됩니다. 복제본(replica) 및 데이터베이스가 확인되고 오프라인 상태인 동안 해당 가용성 그룹 데이터베이스에 액세스하려는 모든 애플리케이션은 실패하고 "오류 983" 메시지를 Unable to access availability database...생성합니다. 이 오류는 실패한 로그인 시도를 기록하도록 SQL Server 구성된 경우 Microsoft SQL Server 오류 로그에도 기록됩니다.
Logon Error: 983, Severity: 14, State: 1.
Logon Unable to access availability database '<databasename>' because the database replica is not in the PRIMARY or SECONDARY role. Connections to an availability database is permitted only when the database replica is in the PRIMARY or SECONDARY role. Try the operation again later.
가용성 그룹이 기본 역할에서 다시 온라인 상태가 되기 전에 해결 역할에 있는 기간은 일반적으로 몇 초 또는 1초 미만만 지속됩니다.
Always On 가용성 그룹 상태 이벤트 또는 장애 조치(failover) 식별 및 진단
1. Always On 상태 추세 식별
단일 Always On 상태 이벤트를 조사하거나 간헐적으로 생산을 중단하는 최근 또는 지속적인 상태 문제 추세가 있을 수 있습니다. 다음 질문은 이러한 상태 문제와 관련이 있을 수 있는 프로덕션 환경의 최근 변경 내용을 좁히거나 상관 관계를 지정하는 데 도움이 될 수 있습니다.
- Always On 또는 클러스터 상태 이벤트 추세는 언제 시작되나요?
- 특정 날짜에 상태 이벤트가 발생합니까?
- 상태 이벤트는 하루 중 특정 시간에 발생합니까?
- 상태 이벤트는 해당 월의 특정 날짜 또는 주에 발생합니까?
추세를 감지하는 경우 시스템에서 예약된 유지 관리(가상 환경의 호스트 시스템), ETL 일괄 처리 및 이러한 상태 이벤트와 상관 관계가 있을 수 있는 기타 작업을 검사. 시스템이 가상 머신인 경우 중단 시 발생할 수 있는 변경 내용에 대해 호스트 시스템을 조사합니다.
상태 문제의 시간과 상관 관계가 있을 수 있는 바쁜 임시 프로덕션 워크로드를 고려합니다(예: 사용자가 시스템에 처음 로그온하거나 점심 식사 후 돌아온 후).
참고
주 및 월 내내 성능 데이터를 수집하는 계획을 고려하는 것이 좋습니다. 시스템이 가장 바쁜 시기를 더 잘 이해하기 위해 , Memory::Available MBytes및 MSSQLServer:SQL Statistics::Batch Requests/sec와 같은 Processor Information::% Processor TimeWindows 성능 모니터 카운터를 측정할 수 있습니다.
2. 클러스터 로그 검토
Windows 클러스터 로그는 Always On 또는 클러스터 상태 이벤트의 종류와 이벤트를 발생시킨 검색된 상태 상태를 식별하는 데 사용할 수 있는 가장 포괄적인 로그입니다. 클러스터 로그를 생성하고 열려면 다음 단계를 수행합니다.
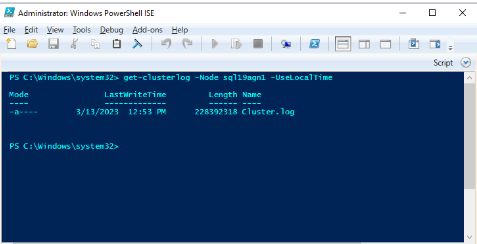
Windows PowerShell 사용하여 상태 이벤트 발생 시 기본 복제본(replica) 호스트하는 클러스터 노드에서 Windows 클러스터 로그를 생성합니다. 예를 들어 'sql19agn1'을 SQL Server 기반 서버 이름으로 사용하여 관리자 권한 PowerShell 창에서 다음 cmdlet을 실행합니다.
get-clusterlog -Node sql19agn1 -UseLocalTime
참고
기본적으로 로그 파일은 %WINDIR%\cluster\reports에 만들어집니다.
3. 클러스터 로그에서 상태 이벤트 찾기
Always On 여러 상태 모니터링 메커니즘을 사용하여 가용성 그룹 상태를 모니터링합니다. Windows 클러스터 상태 이벤트(Windows 클러스터가 클러스터 노드 간에 상태 문제를 검색하는 경우) 외에도 Always On 다음과 같은 네 가지 종류의 상태 검사를 제공합니다.
- SQL Server 서비스가 실행되고 있지 않습니다.
- SQL Server 임대 제한 시간
- SQL Server 상태 검사 제한 시간
- SQL Server 내부 상태 문제
클러스터 로그에서 문자열[hadrag] Resource Alive result 0을 검색하여 이러한 Always On 특정 상태 이벤트를 찾을 수 있습니다. 이 문자열은 이러한 이벤트가 검색되면 클러스터 로그에 저장됩니다. 예를 들면
00001334.00002ef4::2019/06/24-18:24:36.153 ERR [RES] SQL Server Availability Group : [hadrag] Resource Alive result 0.
도구를 사용하여 클러스터 로그에서 모든 상태 이벤트를 찾을 수 있으므로 Always On 상태 문제에 대한 요약 보고서를 생성할 수 있습니다. 이는 연대순 추세를 식별하고 특정 종류의 Always On 상태 상태가 되풀이되는지 여부를 확인하는 데 유용할 수 있습니다. 다음 스크린샷은 텍스트 편집기(이 경우 NotePad++)를 사용하여 문자열이 포함된 [hadrag] Resource Alive result 0 클러스터 로그의 모든 줄을 찾는 방법을 보여 줍니다.

장애 조치(failover)를 트리거한 상태 문제 종류 확인
기본 복제본(replica) 클러스터 로그에서 찾을 수 있는 상태 문제의 종류를 확인하려면 다음 몇 섹션에 설명된 문제와 비교합니다.
클러스터 상태 이벤트
Microsoft Windows 클러스터는 클러스터의 멤버 서버 상태를 모니터링합니다. 상태 문제가 감지되면 클러스터 구성원 서버가 클러스터에서 제거될 수 있습니다. 또한 클러스터 리소스(제거된 클러스터 멤버 서버에서 호스트되는 가용성 그룹 역할 포함)는 자동 장애 조치(failover)를 위해 구성된 경우 복제본(replica) 가용성 그룹 장애 조치(failover) 파트너로 이동됩니다.
클러스터 상태 이벤트의 증상
다음은 클러스터 로그의 클러스터 상태 이벤트의 예입니다. 이를 찾으려면 가용성 그룹 역할 변경 또는 장애 조치(failover) 중에 또는 Cluster service has terminated 를 검색 Lost quorum 할 수 있습니다.
00000fe4.00001628::2022/12/15-14:26:02.654 WARN [QUORUM] Node 1: Lost quorum (1)
00000fe4.00001628::2022/12/15-14:26:02.654 WARN [QUORUM] Node 1: goingAway: 0, core.IsServiceShutdown: 0
00000fe4.00001628::2022/12/15-14:26:02.654 WARN lost quorum (status = 5925)
00000fe4.00001628::2022/12/15-14:26:02.654 INFO [NETFT] Cluster Service preterminate succeeded.
00000fe4.00001628::2022/12/15-14:26:02.654 WARN lost quorum (status = 5925), executing OnStop
00000fe4.00001628::2022/12/15-14:26:02.654 INFO [DM]: Shutting down, so unloading the cluster database.
00000fe4.00001628::2022/12/15-14:26:02.654 INFO [DM] Shutting down, so unloading the cluster database (waitForLock: false).
000019cc.000019d0::2022/12/15-14:26:02.654 WARN [RHS] Cluster service has terminated. Cluster.Service.Running.Event got signaled.
이 이벤트를 식별하는 또 다른 방법은 Windows 시스템 이벤트 로그를 검색하는 것입니다.
Critical SQL19AGN1.CSSSQL 1135 Microsoft-Windows-FailoverClusterin Node Mgr NT AUTHORITY\SYSTEM Cluster node 'SQL19AGN2' was removed from the active failover cluster membership. The Cluster service on this node may have stopped. This could also be due to the node having lost communication with other active nodes in the failover cluster. Run the Validate a Configuration wizard to check your network configuration. If the condition persists, check for hardware or software errors related to the network adapters on this node. Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
Critical SQL19AGN1.CSSSQL 1177 Microsoft-Windows-FailoverClusterin Quorum Manager NT AUTHORITY\SYSTEM The Cluster service is shutting down because quorum was lost. This could be due to the loss of network connectivity between some or all nodes in the cluster, or a failover of the witness disk. Run the Validate a Configuration wizard to check your network configuration. If the condition persists, check for hardware or software errors related to the network adapter. Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
클러스터 상태 이벤트 진단
Windows 이벤트 로그(이벤트 1135 및 1177)의 오류는 네트워크 연결이 이벤트의 원인임을 시사합니다. 이것이 클러스터 상태 문제가 검색되는 가장 일반적인 이유입니다. 다음 예제에서는 다른 클러스터 멤버 서버가 가용성 그룹 주 복제본(replica) 호스트하는 이 서버와 통신할 수 없으며 이 문제로 인해 클러스터에서 클러스터 노드가 제거되었음을 보여 줍니다.
00000fe4.00001edc::2022/12/14-22:44:36.870 INFO [NODE] Node 1: New join with n3: stage: 'Attempt Initial Connection' status (10060) reason: 'Failed to connect to remote endpoint <endpoint address>'
00000fe4.00001620::2022/12/15-14:26:02.050 INFO [IM] got event: Remote endpoint <endpoint address> unreachable from <endpoint address>
00000fe4.00001620::2022/12/15-14:26:02.050 WARN [NDP] All routes for route (virtual) local <local address> to remote <remote address> are down
00000fe4.0000179c::2022/12/15-14:26:02.053 WARN [NODE] Node 1: Connection to Node 2 is broken. Reason GracefulClose(1226)' because of 'channel to remote endpoint <endpoint address> is closed'
클러스터 로그에서 노드에 대한 연결 실패의 증거를 검색할 수 있습니다. 를 찾Lost quorum은 클러스터 로그의 위치에서 , unreachable및 is broken와 같은 Failed to connect to remote endpoint문자열을 뒤로 검색합니다.
클러스터 상태 이벤트 해결
클러스터 상태 모니터링이 호스트 환경에 적합한지 확인합니다. Microsoft Azure에서 호스트되는 SQL Server Always On 가용성 그룹에 대한 자세한 내용은 Windows Server 장애 조치(failover) 클러스터 개요 - Azure VM의 SQL Server 참조하세요.
필요한 경우 Microsoft Windows 고가용성 지원에 문의하여 지원 인시던트 열기를 고려하세요.
SQL Server 서비스가 중단됨: Always On 상태 이벤트
Always On 상태 모니터링은 가용성 그룹 기본 복제본(replica) 호스트하는 SQL Server 서비스가 더 이상 실행되고 있지 않은지 여부를 검색할 수 있습니다.
SQL Server 서비스 종료의 증상
다음은 프로세스 ID0를 반환했기 때문에 QueryServiceStatusEx 실패를 나타내는 가용성 그룹 역할 'ag'에 대한 클러스터 로그 보고서의 샘플입니다.
00001898.0000185c::2023/02/27-13:27:41.121 ERR [RES] SQL Server Availability Group <ag>: [hadrag] QueryServiceStatusEx returned a process id 0
00001898.0000185c::2023/02/27-13:27:41.121 ERR [RES] SQL Server Availability Group <ag>: [hadrag] SQL server service is not alive
00001898.0000185c::2023/02/27-13:27:41.121 ERR [RES] SQL Server Availability Group <ag>: [hadrag] Resource Alive result 0.
00001898.0000185c::2023/02/27-13:27:41.121 WARN [RHS] Resource ag IsAlive has indicated failure.
SQL 서비스 종료 이벤트 진단 및 resolve
Windows 시스템 이벤트 로그 및 SQL Server 오류 로그에서 예기치 않은 SQL Server 종료를 확인합니다.
시스템 종료 또는 관리 종료로 SQL Server 종료된 경우 SQL Server 오류 로그에 다음 항목이 표시됩니다.
2023-03-10 09:38:46.73 spid9s SQL Server 서비스 제어 관리자의 '중지' 요청에 대한 응답으로 종료됩니다. 정보 메시지일 뿐입니다. 사용자 작업은 필요하지 않습니다.
Windows 시스템 이벤트 로그에는 다음 오류 항목이 표시됩니다.
정보 2023년 3월 10일 오전 9:41:06 서비스 제어 관리자 7036 없음 MSSQLSERVER(SQL Server) 서비스가 중지됨 상태로 들어갔습니다.
SQL Server 예기치 않게 종료되면 Windows 시스템 이벤트 로그에 다음 오류 항목이 표시됩니다.
오류 2023년 3월 10일 오전 8:37:46 서비스 제어 관리자 7034 없음 MSSQLSERVER(SQL Server) 서비스가 예기치 않게 종료되었습니다. 이 작업을 1번 수행했습니다.
SQL Server 오류 로그의 끝을 확인하여 단서를 확인합니다. 오류 로그가 갑자기 종료되면 강제로 종료되었음을 의미합니다. instance 작업 관리자를 사용하여 SQL Server 종료된 경우 SQL Server 오류 보고서에는 프로세스가 종료될 수 있는 내부 문제에 대한 정보가 표시되지 않습니다.
SQL Server 내부 상태 문제로 인해 SQL Server 예기치 않게 종료되는 경우 SQL 오류 로그 끝에 치명적인 예외(생성되는 덤프 파일 진단 포함)의 단서가 있을 수 있습니다. 단서를 검토하고 필요한 조치를 취합니다. 덤프 파일을 찾으면 Microsoft SQL Server 지원에 문의하고 추가 조사를 위해 SQL Server 오류 로그 및 덤프 파일 콘텐츠를 제공하는 것이 좋습니다.
임대 제한 시간: Always On 상태 이벤트
Always On "임대" 메커니즘을 사용하여 SQL Server 설치된 컴퓨터의 상태를 모니터링합니다. 기본 임대 제한 시간은 20초입니다.
Always On 임대 시간 제한 이벤트의 증상
클러스터 로그에서 Always On 임대 시간 제한의 샘플 출력은 다음과 같습니다. 이러한 문자열을 검색하여 클러스터 로그에서 임대 제한 시간을 찾을 수 있습니다.
00001a0c.00001c5c::2023/01/04-15:36:54.762 ERR [RES] SQL Server Availability Group : [hadrag] Availability Group lease is no longer valid
00001a0c.00001c5c::2023/01/04-15:36:54.762 ERR [RES] SQL Server Availability Group : [hadrag] Resource Alive result 0.
00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] Lease timeout detected, logging perf counter data collected so far
00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] Date/Time, Processor time(%), Available memory(bytes), Avg disk read(secs), Avg disk write(secs)
00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:35:57.0, 98.068572, 509227008.000000, 0.000395, 0.000350 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:7.0, 12.314941, 451817472.000000, 0.000278, 0.000266 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:17.0, 17.270742, 416096256.000000, 0.000376, 0.000292 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:27.0, 38.399895, 416301056.000000, 0.000446, 0.000304 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:37.0, 100.000000, 417517568.000000, 0.001292, 0.000666
임대 제한 시간에 대한 자세한 내용은 메커니즘의 임대 메커니즘 섹션 및 Always On 가용성 그룹에 대한 임대, 클러스터 및 상태 검사 시간 제한 지침을 참조하세요.
임대 시간 제한 이벤트 진단 및 resolve Always On
임대 시간 초과를 트리거할 수 있는 두 가지 기본 문제가 있습니다.
덤프 파일 진단 SQL Server: SQL Server 액세스 위반, 어설션 또는 스케줄러 교착 상태와 같은 특정 내부 상태 이벤트를 검색하면 SQL Server \LOG 폴더에 진단 덤프 파일(.mdmp)이 생성됩니다.
시스템 전체 성능 문제: 임대 시간 제한이 반드시 SQL Server 상태를 나타내는 것은 아닙니다. 대신 SQL Server 기반 서버의 상태에도 영향을 주는 시스템 전체 상태 문제를 나타낼 수 있습니다. 자세한 문제 해결 단계는 MSSQLSERVER_19407 참조하세요.
1. 덤프 파일 진단 SQL Server
SQL Server 액세스 위반, 어설션 또는 교착 상태 스케줄러와 같은 내부 상태 문제를 검색할 수 있습니다. 이 경우 프로그램은 진단을 위해 SQL Server 프로세스의 SQL Server \LOG 폴더에 미니 덤프 파일(.mdmp)을 생성합니다. 미니 덤프 파일이 디스크에 기록되는 동안 SQL Server 프로세스가 몇 초 동안 중지됩니다. 이 시간 동안 SQL Server 프로세스 내의 모든 스레드는 고정된 상태입니다. 여기에는 Always On 상태 모니터링으로 모니터링되는 임대 스레드가 포함됩니다. 따라서 Always On 임대 시간 초과를 검색할 수 있습니다.
**Dump thread - spid = 0, EC = 0x0000000000000000
***Stack Dump being sent to C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\LOG\SQLDump0001.txt
* *******************************************************************************
*
* BEGIN STACK DUMP:
* 11/02/14 21:21:10 spid 1920
*
* Deadlocked Schedulers
*
* *******************************************************************************
* -------------------------------------------------------------------------------
* Short Stack Dump
Stack Signature for the dump is 0x00000000000002BA
Error: 19407, Severity: 16, State: 1.
The lease between availability group 'ag' and the Windows Server Failover Cluster has expired. A connectivity issue occurred between the instance of SQL Server and the Windows Server Failover Cluster. To determine whether the availability group is failing over correctly, check the corresponding availability group resource in the Windows Server Failover Cluster.
이 문제를 resolve 근본 원인에 대해 덤프 파일 진단을 조사해야 합니다. 추가 조사를 위해 Microsoft SQL Server 지원에 문의하여 SQL Server 오류 로그 및 덤프 파일 콘텐츠를 제공하는 것이 좋습니다.
2. 높은 CPU 사용량 또는 기타 시스템 성능 문제
임대 제한 시간은 SQL Server 포함하여 전체 시스템에 영향을 주는 성능 문제를 나타냅니다. 시스템 문제를 진단하려면 Always On 상태 진단 클러스터 로그에 성능 모니터 데이터를 보고하고 임대 시간 제한 이벤트를 포함합니다. 성능 데이터는 임대 시간 제한 이벤트까지 약 50초 동안 지속되며 CPU 사용률, 사용 가능한 메모리 및 디스크 대기 시간에 대해 보고합니다.
다음은 클러스터 로그에서 임대 시간 초과를 보여 주는 보고된 성능 데이터의 예입니다. 이 샘플 출력에서는 임대 시간 제한과 관련될 수 있는 전체 CPU 사용률이 높습니다.
00000f90.000015c0::2020/08/07-14:16:41.378 WARN [RES] SQL Server Availability Group: [hadrag] Lease timeout detected, logging perf counter data collected so far
00000f90.000015c0::2020/08/07-14:16:41.382 WARN [RES] SQL Server Availability Group: [hadrag] Date/Time, Processor time(%), Available memory(bytes), Avg disk read(secs), Avg disk write(secs)
00000f90.000015c0::2020/08/07-14:16:41.431 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:20.0, 83.266073, 31700828160.000000, 0.018094, 0.015752
00000f90.000015c0::2020/08/07-14:16:41.431 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:30.0, 93.653224, 31697063936.000000, 0.038590, 0.026897
00000f90.000015c0::2020/08/07-14:16:41.431 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:40.0, 94.270691, 31696265216.000000, 0.166000, 0.038962
00000f90.000015c0::2020/08/07-14:16:41.434 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:50.0, 90.272016, 31695409152.000000, 0.215141, 0.106084
00000f90.000015c0::2020/08/07-14:16:41.434 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:16:1.0, 99.991336, 31695892480.000000, 0.046983, 0.035440
성능 데이터에 임대 시간 초과 시 높은 CPU 사용률, 낮은 메모리 상태 또는 높은 디스크 대기 시간이 표시되는 경우 주 복제본(replica) 하루 종일 성능 모니터 데이터 수집을 시작하여 이러한 증상을 조사합니다. 더 오랜 기간 동안 성능 모니터 데이터를 캡처하여 이러한 리소스에 대한 기준 및 최대값을 더 잘 식별하고 임대 제한 시간이 발생할 때 이러한 리소스의 변경 내용을 모니터링할 수 있습니다. 이 데이터를 수집할 때 이러한 리소스 문제 및 상태 이벤트의 시간과 상관 관계가 있는 특정 예약된 워크로드 또는 임시 워크로드가 SQL Server 있는지 여부를 고려합니다.
또한 다음을 포함하여 동일한 시스템 리소스 사용량을 보고하는 카운터를 캡처해야 합니다.
Processor Information::% Processor TimeMemory::Available MBytesLogical Disk::Avg. Disk sec/ReadLogical Disk::Avg. Disk sec/WriteLogical Disk::Avg. Disk Read Queue LengthLogical Disk::Avg. Disk Write Queue LengthMSSQLServer:SQL Statistics::Batch Requests/sec
상태 검사 시간 제한: Always On 상태 이벤트
가용성 그룹이 복제본(replica) 주 역할로 전환되면 Always On 상태 모니터링은 SQL Server instance 대한 로컬 ODBC 연결을 설정합니다. Always On 연결되고 모니터링하는 동안 가용성 그룹의 상태 검사 시간 제한(기본값은 30초)에 대해 설정된 기간 내에 SQL Server ODBC 연결에 대해 응답하지 않으면 상태 검사 시간 제한 이벤트가 트리거됩니다. 이 경우 가용성 그룹은 기본 역할에서 해결 역할로 전환되고 이 작업을 수행하도록 구성된 경우 장애 조치(failover)를 시작합니다.
상태 검사 시간 제한에 대한 자세한 내용은 메커니즘의 "상태 검사 시간 제한 작업" 섹션 및 Always On 가용성 그룹에 대한 임대, 클러스터 및 상태 검사 시간 제한 지침을 참조하세요.
다음은 클러스터 로그에 보고된 Always On 상태 검사 시간 제한입니다.
0000211c.00002d70::2021/02/24-02:50:01.890 WARN [RES] SQL Server Availability Group: [hadrag] Failed to retrieve data column. Return code -1
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <AG>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <AG>: [hadrag] Resource Alive result 0.
0000211c.00002594::2021/02/24-02:50:02.453 WARN [RHS] Resource AG IsAlive has indicated failure.
00001278.00002ed8::2021/02/24-02:50:02.453 INFO [RCM] HandleMonitorReply: FAILURENOTIFICATION for 'AG', gen(0) result 1/0.
상태 진단 및 resolve Always On 상태 검사 제한 시간 이벤트
다음 섹션에서는 검색되고 보고된 Always On 상태 검사 시간 제한과 관련이 있는 "빵 부스러기" 이벤트에 대한 SQL Server 로그를 검토하는 데 도움이 됩니다. 여기에서 검토되는 로그에는 클러스터 로그(상태 검사 시간 초과가 확인됨), system_health 확장 이벤트 로그 및 SQL Server 오류 로그(둘 다 SQL Server \LOG 폴더에 있음) 및 Windows 시스템 이벤트 로그가 포함됩니다. 이러한 로그와 다른 로그를 사용하여 상태 검사 시간 제한의 원인을 scope 데 도움이 될 수 있는 상관 관계를 지정하는 이벤트를 찾습니다.
1. 비수익 스케줄러 이벤트 확인
Always On 상태 검사 시간 제한은 SQL Server "비수익" 이벤트로 인해 자주 발생합니다. SQL Server 스레드가 스케줄러에서 생성되지 않았음을 감지하면 생성되지 않는 스케줄러 이벤트가 발생했음을 보고합니다. CPU 시간을 받지 못하는 동일한 스케줄러에 다른 작업이 표시되는 경우 이는 비수익 스케줄러의 기본 표시입니다. 이 동작으로 인해 특정 CPU 시간 스케줄러에 할당된 해당 작업 및 "굶주리기" 워크로드의 실행이 지연될 수 있습니다.
비수익 스케줄러 이벤트에 대해 검사 하려면 다음 단계를 수행합니다.
SQL Server
system_health확장 이벤트 로그를 확인하여 Always On 상태 검사 시간 제한 이벤트 전후에 특정 종류의 비수익 스케줄러 이벤트가 보고되었는지 확인합니다. 찾을 수 있는 비수익 이벤트에는 다음이 포함됩니다.scheduler_monitor_non_yielding_ring_buffer_recordedscheduler_monitor_non_yielding_iocp_ring_buffer_recordedscheduler_monitor_stalled_dispatcher_ring_buffer_recordedscheduler_monitor_non_yielding_rm_ring_buffer_recorded
주 복제본(replica) SQL Server 시스템 상태 확장 이벤트 로그를 의심스러운 상태 검사 시간 제한 시간으로 엽니다.
SQL Server Management Studio(SSMS)에서 파일 > 열기로 이동하고 확장 이벤트 파일 병합을 선택합니다.
추가 버튼을 선택합니다.
파일 열기 대화 상자에서 SQL Server \LOG 디렉터리의 파일로 이동합니다.
Control 키를 누른 다음 이름이 로 시작하는
system_health_xxx.xel파일을 선택합니다.열기>확인을 선택합니다.
결과를 필터링합니다. 이름 열 아래에서 이벤트를 마우스 오른쪽 단추로 클릭하고 이 값으로 필터링을 선택합니다.
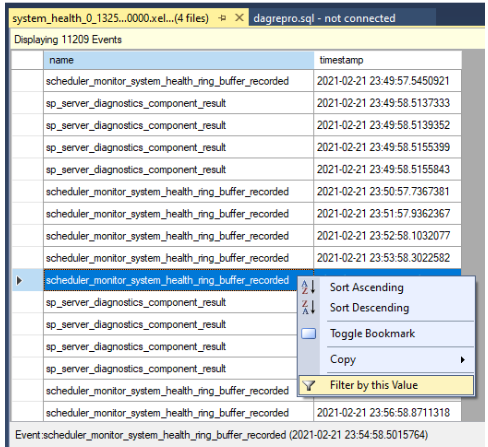
다음 스크린샷과 같이 이름 열의 값에 가 포함된 행을 정렬하는 필터를 정의합니다
yield. 로그에 기록system_health되었을 수 있는 모든 종류의 비수익 이벤트를 반환합니다.
타임스탬프를 비교하여 상태 검사 시간 초과 시 비수익 이벤트가 있었는지 확인합니다. 클러스터 로그에 보고된 상태 검사 시간 제한은 다음과 같습니다.
0000211c.00002594::2021/02/24-21:50:02.452 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost 0000211c.00002594::2021/02/24-21:50:02.452 ERR [RES] SQL Server Availability Group < SQL19AGN1>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel 0000211c.00002594::2021/02/24-21:50:02.452 ERR [RES] SQL Server Availability Group < SQL19AGN1: [hadrag] Resource Alive result 0.상태 검사 시간 초과 시 발생한 비수익 이벤트가 있음을 확인할 수 있습니다.
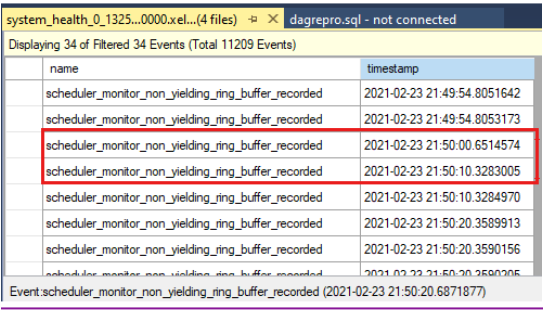
생성되지 않는 이벤트가 검색되면 비수익 이벤트의 원인을 검사. SQL Server 지원 팀에 문의하여 수익률이 없는 이벤트를 조사하는 것이 좋습니다.
2. SQL Server 오류 로그 확인
상태 검사 시간 제한 시 이벤트 상관 관계를 지정하려면 SQL Server 오류 로그를 확인합니다. 이러한 이벤트는 상태 검사 시간 제한의 근본 원인을 scope 추가 단계를 제안하는 "빵 부스러기"를 제공할 수 있습니다.
예를 들어 다음 로그 항목은 클러스터 로그에서 상태 검사 시간 초과가 발생했음을 보여줍니다.
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <SQL19AGN1>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <SQL19AGN1>: [hadrag] Resource Alive result 0.
SQL Server 오류 로그에서 상태 검사 시간 초과 후 몇 초 이내에 심각한 I/O 대기 시간이 감지되었다고 SQL Server.
2021-02-23 20:49:54.64 spid12s SQL Server has encountered 1 occurrence(s) of I/O requests taking longer than 15 seconds to complete on file [C:\Program Files\Microsoft SQL Server\MSSQL15.MSSQLSERVER\MSSQL\DATA\agdb_log.ldf] in database id 12. The OS file handle is 0x0000000000001594. The offset of the latest long I/O is: 0x000030435b0000. The duration of the long I/O is: 26728 ms.
상태 검사 시간 제한 이벤트와 관련될 수 있는 가능한 시스템 단서는 시스템 이벤트 로그를 검토합니다. Windows 시스템 이벤트 로그를 검토할 때 동일한 상태 검사 시간 제한에 대해 동시에 보고되는 I/O 문제를 찾을 수 있습니다.
02/23/2021,08:50:16 PM,Warning,SQL19AGN1.CSSSQL.local.local,<...>,"Reset to device, \Device\<device ID>, was issued."
02/23/2021,08:50:16 PM,Warning,SQL19AGN1.CSSSQL.local.local,<...>,"The IO operation at logical block address <block address> for Disk 6 (PDO name: \Device\<device ID>) was retried."
SQL Server 상태: Always On 상태 이벤트
Always On 다양한 종류의 SQL Server 상태 이벤트를 모니터링합니다. 가용성 그룹 기본 복제본(replica) 호스트하는 동안 SQL Server 다른 구성 요소를 사용하여 SQL Server 상태에 대해 보고하는 를 지속적으로 실행 sp_server_diagnostics 합니다. 상태 문제가 검색되면 sp_server_diagnostics 해당 특정 구성 요소에 대한 오류를 보고한 다음 결과를 Always On 상태 검색 프로세스로 다시 보냅니다. 오류가 보고되면 가용성 그룹이 이 작업을 수행하도록 구성된 경우 가용성 그룹 역할에 실패한 상태 및 가능한 장애 조치(failover)가 표시됩니다.
Always On SQL Server 상태 이벤트의 증상
다음은 클러스터 로그에서 보고 sp_server_diagnostics 한 SQL Server 상태 문제의 예입니다. SQL Server 시스템 구성 요소에서 상태 모니터링을 Always On "오류" 상태를 보고하고 "contoso-ag" 가용성 그룹이 실패한 상태로 전환됩니다.
참고
SQL Server 상태 문제는 상태 검사 시간 제한과 유사한 보고서를 생성합니다. 두 상태 이벤트 모두 를 보고합니다Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel. SQL Server 상태 이벤트의 차이점은 SQL Server 구성 요소가 "경고"에서 "오류"로 변경되었다고 보고한다는 것입니다.
INFO [RES] SQL Server Availability Group: [hadrag] SQL Server component 'system' health state has been changed from 'warning' to 'error' at 2019-06-20 15:05:52.330
ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, the state of system component is error
ERR [RES] SQL Server Availability Group <contoso-ag>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel
ERR [RES] SQL Server Availability Group <contoso-ag>: [hadrag] Resource Alive result 0.
ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, the state of system component is error
WARN [RHS] Resource contoso-ag IsAlive has indicated failure.
INFO [RCM] HandleMonitorReply: FAILURENOTIFICATION for 'contoso-ag', gen(0) result 1/0.
상태 이벤트 진단 및 resolve SQL Server
SQL Server Health에서 보고하는 상태 문제의 종류는 근본 원인 분석의 방향을 결정해야 합니다.
기본적으로 가용성 그룹을 FAILURE_CONDITION_LEVEL 배포할 때 은 3으로 설정됩니다. 이렇게 하면 일부 SQL Server 상태 프로필에 대한 모니터링이 활성화됩니다. 기본 수준에서 Always On SQL Server 너무 많은 덤프 파일, 쓰기 액세스 위반 또는 분리된 스핀 잠금을 생성할 때 상태 이벤트를 트리거합니다. 가용성 그룹을 수준 4 또는 5로 설정하면 모니터링되는 SQL Server 상태 문제의 유형이 확장됩니다. SQL Server 상태 Always On 모니터에 대한 자세한 내용은 가용성 그룹에 대한 유연한 자동 장애 조치(failover) 정책 구성 - SQL Server Always On 참조하세요.
Always On 특정 상태 문제를 식별하려면 다음 단계를 수행합니다.
주 복제본(replica) SQL Server 클러스터 진단 확장 이벤트 로그를 의심스러운 SQL Server 상태 이벤트가 발생한 시간까지 엽니다.
SSMS에서 파일>열기로 이동한 다음 확장 이벤트 파일 병합을 선택합니다.
추가를 선택합니다.
파일 열기 대화 상자에서 SQL Server \LOG 디렉터리의 파일로 이동합니다.
Control 키를 누르고 이름이 와 일치하는
<servername>_<instance>_SQLDIAG_xxx.xel파일을 선택한 다음, 확인열기>를 선택합니다.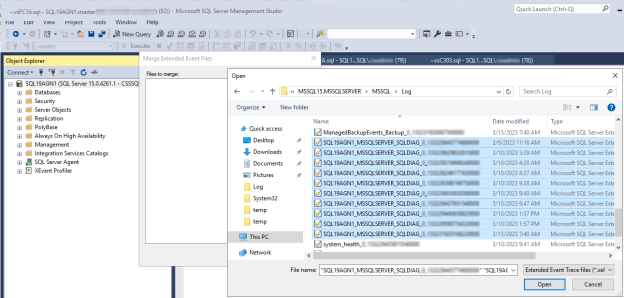
다음 스크린샷과 같이 확장 이벤트를 포함하는 새 탭 창이 SSMS에 표시됩니다.
SQL Server 상태 문제를 조사하려면 값이 인 를
component_health_resultstate_desc찾습니다error. 다음은 Always On 상태 모니터링에 오류를 다시 보고한 시스템 구성 요소 이벤트의 예입니다.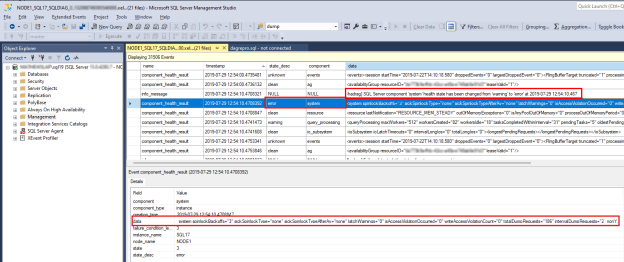
아래쪽 창에서 데이터 열을 두 번 클릭합니다. 그러면 검토를 위해 새 SSMS 창에서 자세한 구성 요소 데이터가 열립니다. 시스템 구성 요소 데이터는 다음과 같습니다.

'totalDumprequests=186' 데이터는 이 SQL Server 너무 많은 덤프 파일 진단 이벤트가 생성되었음을 나타냅니다. 시스템 구성 요소가 오류 상태를 보고한 이유입니다. Always On 상태 모니터링이 이 오류 상태를 수신하면 가용성 그룹 상태 이벤트가 트리거됩니다. 또한 시스템 구성 요소 데이터에 제공된 데이터에서 쓰기 액세스 위반 또는 분리된 스핀 잠금이 검색되지 않은 것을 확인할 수 있습니다.
필요한 경우 SQL Server 지원에 문의하여 이러한 내부 SQL Server 상태 문제의 근본 원인을 찾는 데 추가 지원을 받으려면 지원 인시던트에 문의하세요.


