솔루션 아키텍처 살펴보기
시작하기 전에 아키텍처를 탐색하여 모든 요구 사항을 이해해 보겠습니다. 모델을 프로덕션 환경에 도입한다는 것은 솔루션을 확장하고 다른 팀과 협력해야 한다는 것을 의미합니다. 데이터 과학자, 데이터 엔지니어 및 인프라 팀과 함께 다음 접근 방식을 사용하기로 결정했습니다.
- 모든 데이터는 데이터 엔지니어가 관리하는 Azure Blob Storage에 저장됩니다.
- 인프라 팀은 Azure Machine Learning 작업 영역과 같은 필요한 Azure 리소스를 만듭니다.
- 데이터 과학자는 모델 개발 및 학습이라는 내부 루프에 집중합니다.
- 기계 학습 엔지니어는 학습된 모델을 사용하여 외부 루프에 배포합니다.
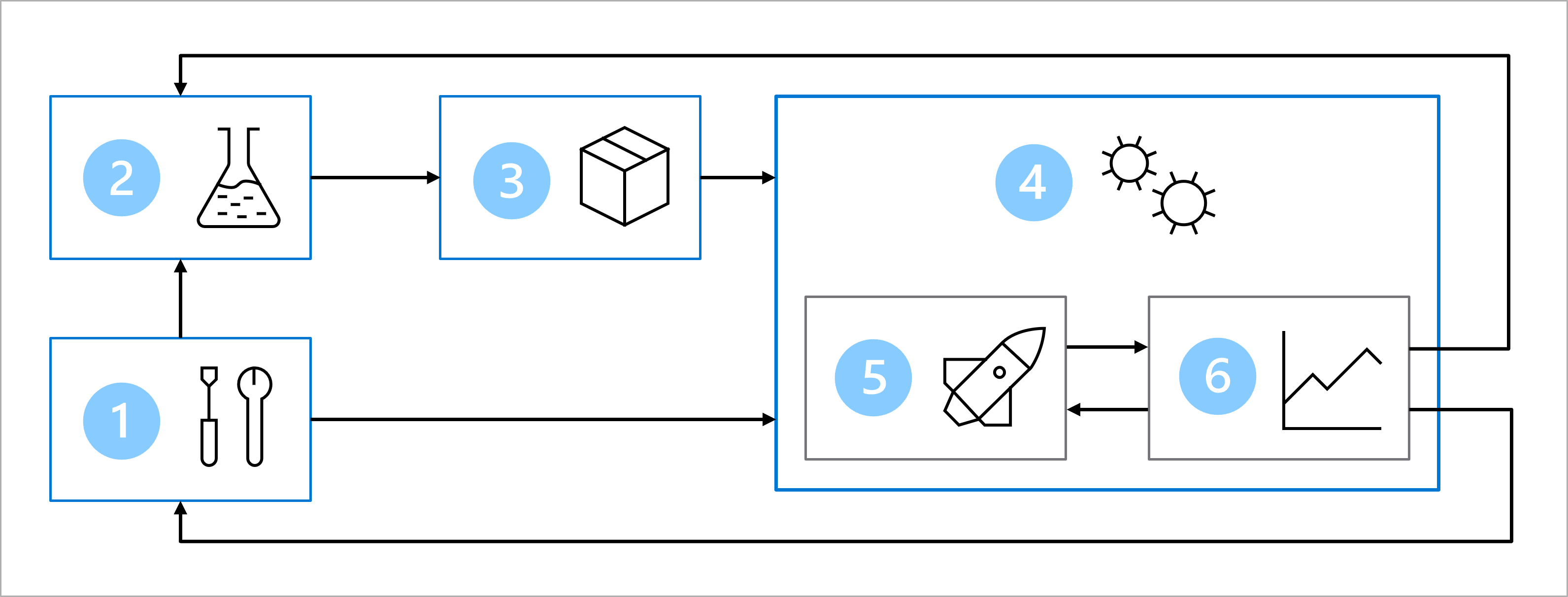
더 큰 팀과 함께 MLOps(기계 학습 작업)를 달성하기 위한 아키텍처를 설계했습니다.
참고
다이어그램은 MLOps 아키텍처의 간소화된 표현입니다. 더 자세한 아키텍처를 보려면 MLOps(v2) 솔루션 가속기에서 다양한 사용 사례를 살펴봅니다.
MLOps 아키텍처의 주요 목표는 강력하고 재현 가능한 솔루션을 만드는 것입니다. 이를 위해 아키텍처에는 다음이 포함됩니다.
- 설치: 솔루션에 필요한 모든 Azure 리소스를 만듭니다.
- 모델 개발(내부 루프): 모델을 학습하고 평가하기 위해 데이터를 탐색하고 처리합니다.
- 연속 통합: 모델을 패키지하고 등록합니다.
- 모델 배포(외부 루프): 모델을 배포합니다.
- 지속적인 배포: 모델을 테스트하고 프로덕션 환경으로 승격합니다.
- 모니터링: 모델 및 엔드포인트 성능을 모니터링합니다.
프로젝트의 이 시점에서 Azure Machine Learning 작업 영역이 생성되고, 데이터가 Azure Blob Storage에 저장되고, 데이터 과학 팀이 모델을 학습시켰습니다.
모델을 프로덕션에 배포하여 내부 루프 및 모델 개발에서 외부 루프로 이동하려고 합니다. 따라서 데이터 과학 팀의 출력을 Azure Machine Learning에서 강력하고 재현 가능한 파이프라인으로 변환해야 합니다.
모든 코드가 스크립트로 저장되도록 하고 Azure Machine Learning 작업으로 스크립트를 실행하면 나중에 모델 학습을 자동화하고 모델을 다시 학습하는 것이 더 쉬워집니다.
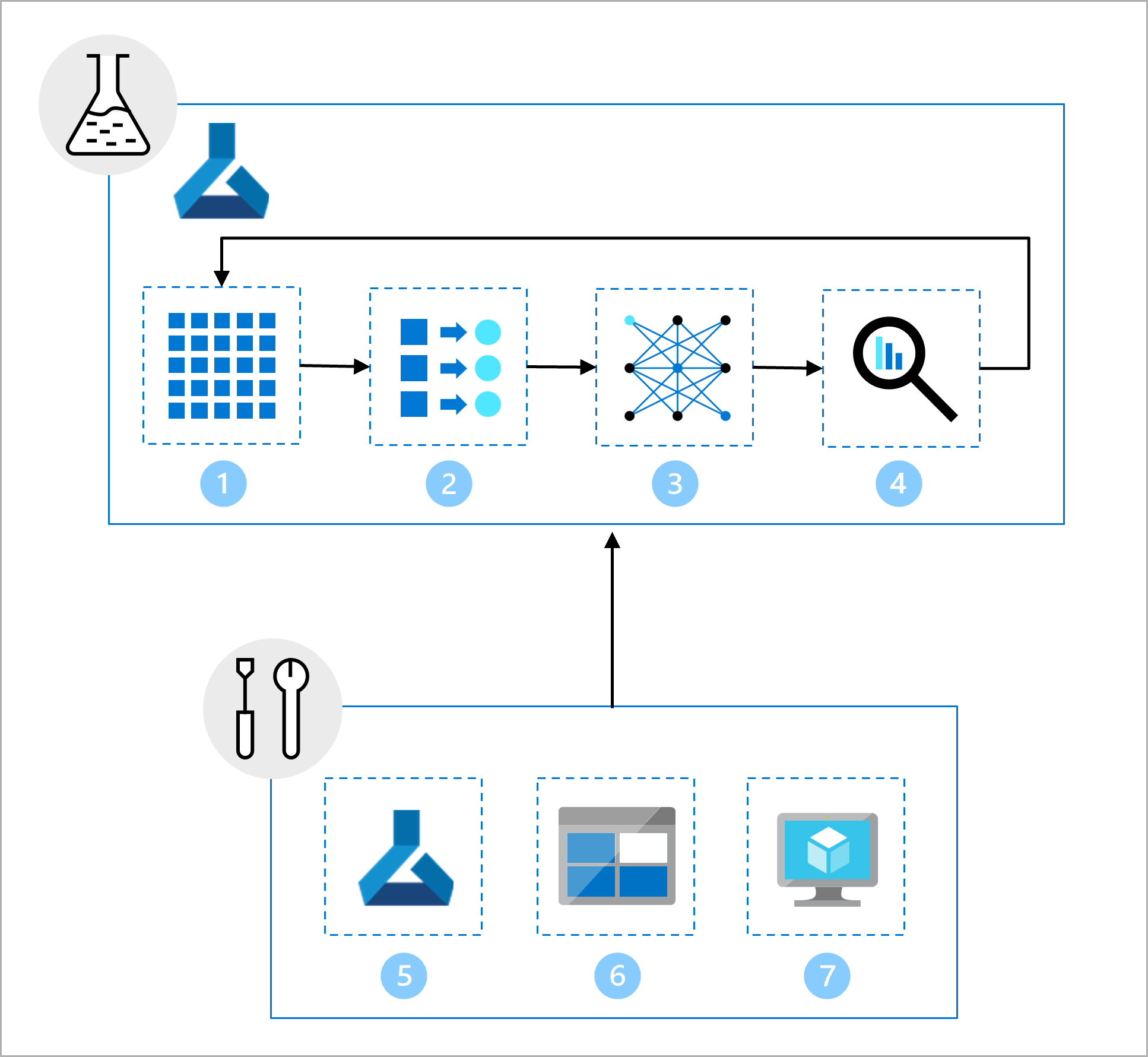
데이터 과학 팀은 모델 개발에 노력하고 있습니다. 다음 작업을 포함하는 Jupyter Notebook을 제공합니다.
- 데이터를 읽고 탐색합니다.
- 기능 엔지니어링 수행
- 모델을 학습시킵니다.
- 모델을 평가합니다.
설치의 일부로 인프라 팀은 다음을 만들었습니다.
- 데이터 과학 팀에서 탐색 및 실험에 사용할 수 있는 Azure Machine Learning 개발(개발) 작업 영역입니다.
- 데이터가 포함된 Azure Blob Storage 폴더를 참조하는 작업 영역의 데이터 자산입니다.
- Notebook 및 스크립트를 실행하는 데 필요한 컴퓨팅 리소스입니다.
MLOps에 대한 첫 번째 작업은 모델 개발을 쉽게 자동화할 수 있도록 데이터 과학자로부터 작업을 변환하는 것입니다. 데이터 과학 팀은 Jupyter Notebook에서 작업한 반면, 스크립트를 사용하고 Azure Machine Learning 작업을 사용하여 실행해야 합니다. 작업의 입력은 Azure Machine Learning 작업 영역에 연결된 Azure Blob Storage에 있는 데이터를 가리키는 인프라 팀에서 만든 데이터 자산입니다.