Azure Synapse Analytics에서 Spark 사용
Python 또는 Scala 스크립트의 코드, JAR(Java 보관 파일)로 컴파일된 Java 코드 등 다양한 종류의 애플리케이션을 Spark에서 실행할 수 있습니다. Spark는 일반적으로 다음과 같은 두 가지 종류의 워크로드에서 사용됩니다.
- 데이터를 수집, 정리, 변환하기 위한 일괄 처리 또는 스트림 처리 작업으로, 자동화된 파이프라인의 일부로 실행되는 경우가 많습니다.
- 데이터를 검색, 분석, 시각화하는 대화형 분석 세션입니다.
Notebook에서 Spark 코드 실행
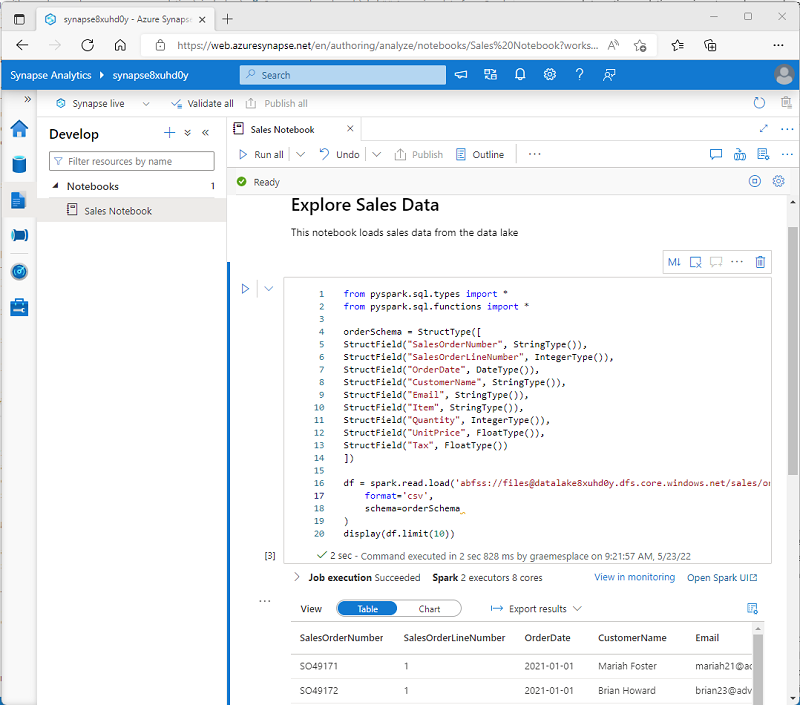
Azure Synapse Studio에는 Spark 작업을 위한 통합 Notebook 인터페이스가 포함되어 있습니다. Notebook은 데이터 과학자 및 데이터 분석가가 일반적으로 사용하는 Markdown 노트와 코드를 결합하는 직관적인 방법을 제공합니다. Azure Synapse Studio 내에 통합된 Notebook 환경의 디자인과 분위기는 널리 사용되는 오픈 소스 Notbook 플랫폼인 Jupyter Notebook과 비슷합니다.
참고
Notebook은 일반적으로 대화형으로 사용되는 반면, 자동화된 파이프라인에 포함되고 무인 스크립트로 실행할 수 있습니다.
Notebook은 각각 코드 또는 Markdown을 포함하는 하나 이상의 셀로 구성됩니다. Notebook의 코드 셀에는 다음을 포함하여 생산성을 높이는 데 도움이 되는 몇 가지 기능이 있습니다.
- 구문 강조 표시 및 오류 지원
- 코드 자동 완성
- 대화형 데이터 시각화
- 결과 내보내기 기능
팁
Azure Synapse Analytics에서 Notebook을 사용하는 방법에 대한 자세한 내용은 Azure Synapse Analytics 설명서의 Azure Synapse Analytics에서 Synapse Notebook 만들기, 개발, 유지 관리 문서를 참조하세요.
Synapse Spark 풀에서 데이터 액세스
Azure Synapse Analytics에서 Spark를 사용하여 다음을 비롯한 다양한 소스의 데이터를 사용할 수 있습니다.
- Azure Synapse Analytics 작업 영역에 대한 기본 스토리지 계정을 기반으로 하는 데이터 레이크입니다.
- 작업 영역에서 연결된 서비스로 정의된 스토리지를 기반으로 하는 데이터 레이크입니다.
- 작업 영역의 전용 또는 서버리스 SQL 풀입니다.
- Azure SQL 또는 SQL Server 데이터베이스(SQL Server용 Spark 커넥터 사용)
- 연결된 서비스로 정의되고 Cosmos DB용 Azure Synapse Link를 사용하여 구성된 Azure Cosmos DB 분석 데이터베이스입니다.
- 작업 영역에서 연결된 서비스로 정의된 Azure Data Explorer Kusto 데이터베이스입니다.
- 작업 영역에서 연결된 서비스로 정의된 외부 Hive 메타스토어입니다.
Spark의 가장 일반적인 용도 중 하나는 데이터 레이크의 데이터로 작업하는 것입니다. 여기서는 구분된 텍스트, Parquet, Avro 등을 포함하여 일반적으로 사용되는 여러 형식으로 파일을 읽고 쓸 수 있습니다.