Apache Spark 알아보기
Apache Spark는 클러스터의 여러 처리 노드에서 작업을 조정하여 대규모 데이터 분석을 지원하는 분산 데이터 처리 프레임워크입니다.
Spark 작동 방식
Apache Spark 애플리케이션은 클러스터의 독립 프로세스 집합으로 실행되며 기본 프로그램(드라이버 프로그램이라고 함)에서 SparkContext 개체에 의해 조정됩니다. SparkContext는 Apache Hadoop YARN 구현을 사용하여 애플리케이션 간에 리소스를 할당하는 클러스터 관리자에 연결합니다. 일단 연결되면 Spark는 애플리케이션 코드를 실행하기 위해 클러스터의 노드에서 실행기를 얻습니다.
SparkContext는 클러스터 노드에서 주 함수 및 병렬 작업을 실행한 다음 작업 결과를 수집합니다. 노드는 파일 시스템에서 데이터를 읽고 쓰고 메모리 내 변환된 데이터를 RDD(복원력 있는 분산 데이터 세트)로 캐시합니다.
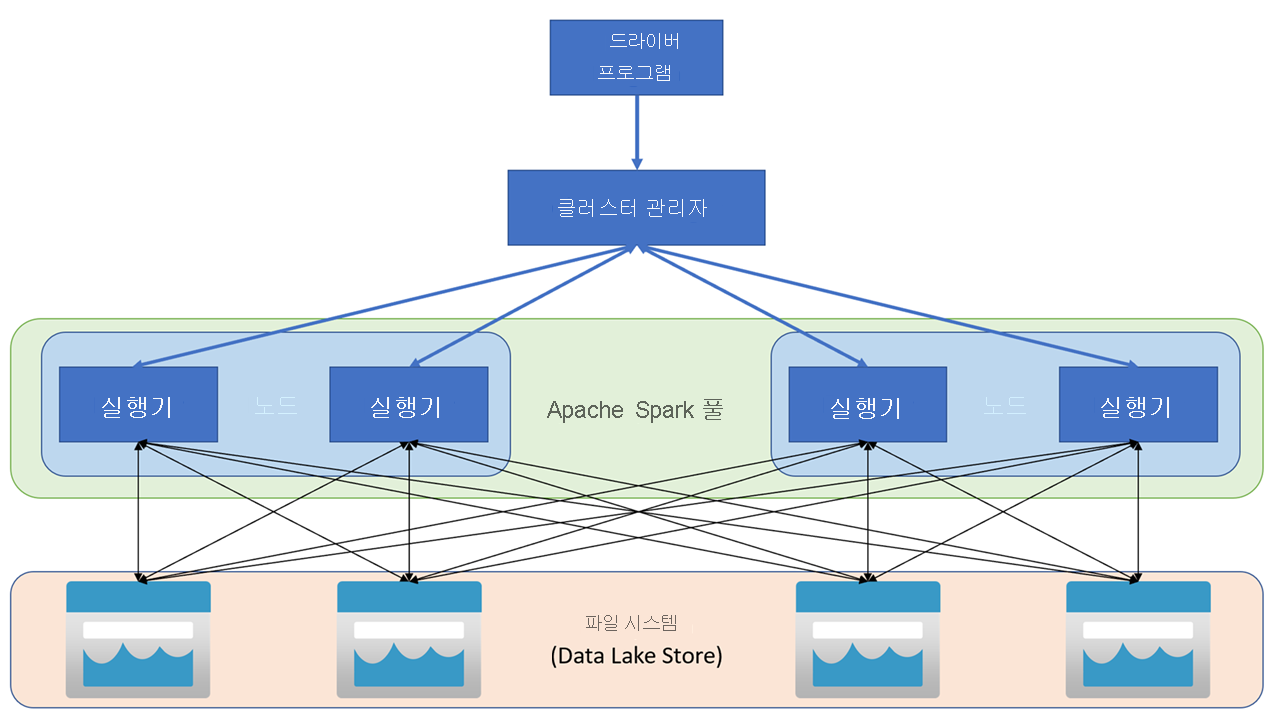
SparkContext는 애플리케이션을 DAG(방향성 비순환 그래프)로 변환하는 작업을 담당합니다. 그래프는 노드의 실행기 프로세스 내에서 실행되는 개별 작업으로 구성됩니다. 각 애플리케이션은 전체 애플리케이션의 기간에 대해 유지하고 여러 스레드에서 작업을 실행하는 자체 실행기 프로세스를 가져옵니다.
Azure Synapse Analytics의 Spark 풀
Azure Synapse Analytics에서 클러스터는 Spark 작업에 대한 런타임을 제공하는 Spark 풀로 구현됩니다. Azure Portal을 사용하여 Azure Synapse Analytics 작업 영역 에서 또는 Azure Synapse Studio에서 하나 이상의 Spark 풀을 만들 수 있습니다. Spark 풀을 정의할 때 다음을 포함하여 풀에 대한 구성 옵션을 지정할 수 있습니다.
- Spark 풀의 이름입니다.
- 하드웨어 가속 GPU 사용 노드를 사용하는 옵션을 포함하여 풀의 노드에 사용되는 VM(가상 머신)의 크기입니다.
- 풀의 노드 수, 풀 크기가 고정되었는지 여부 또는 개별 노드를 온라인으로 동적으로 가져와 자동 스케일링할 수 있는지 여부입니다. 이 경우 활성 노드의 최소 및 최대 수를 지정할 수 있습니다.
- 풀에서 사용할 Spark 런타임의 버전입니다. Python, Java 및 설치되는 다른 구성 요소와 같은 개별 구성 요소의 버전입니다.
팁
Spark 풀 구성 옵션에 대한 자세한 내용은 Azure Synapse Analytics 설명서에서 Azure Synapse Analytics의 Apache Spark 풀 구성을 참조하세요.
Azure Synapse Analytics 작업 영역의 Spark 풀은 서버리스입니다. 요청 시 시작되고 유휴 상태일 때 중지됩니다.