연습 - 인바운드 네트워크 연결 확인 및 해결
이 시나리오에서는 네트워크 구성이 변경되었습니다. 백 엔드 풀의 가상 머신이 상태 프로브에 응답하지 않는다는 경고가 수신됩니다. 이제 해당 오류의 원인을 진단하고 해결해야 합니다.
이 연습에서는 스크립트를 사용하여 환경을 다시 구성하고 상태 프로브 오류를 발생시킵니다. 이 모듈에서 배운 기술을 사용하여 부하가 분산된 HTTP 서비스를 전체 작동으로 되돌립니다.
부하 분산 장치 다시 구성 및 다시 테스트
Azure Cloud Shell에서 리소스 그룹 이름을 설정합니다.
export RESOURCEGROUP=learn-ts-loadbalancer-rgsrc/scripts 폴더로 이동합니다.
cd ~/load-balancer/src/scripts다음 명령을 실행하여 부하 분산 장치, 네트워크 및 가상 머신을 다시 구성합니다. 이 스크립트는 나중에 진단하고 정정할 몇 가지 문제를 도입합니다.
bash reconfigure.sh다음 명령을 실행하여 src/stresstest 폴더로 이동합니다.
cd ~/load-balancer/src/stresstest<IP 주소>를 부하 분산 장치의 IP 주소로 바꾸는 스트레스 테스트를 다시 실행합니다. 해당 주소가 기억나지 않으면 src/scripts/findip.sh 스크립트를 다시 실행합니다.
dotnet run <ip address>이번에는 앱이 출력을 생성하지 않으며 “Load Balancer로 전송하는 중 오류가 발생했습니다. 작업이 취소되었습니다.”라는 메시지와 함께 시간 초과될 것입니다. Enter 키를 눌러 애플리케이션을 중지합니다.
Azure Portal에서 대시보드>dashboard-learn-ts-loadbalancer를 선택합니다.
상태 프로브 상태와 데이터 경로 가용성을 표시하는 대시보드를 검토합니다. 시간 범위를 지난 30분으로 변경해야 할 수도 있습니다. 두 메트릭이 모두 0으로 감소되어 다음 차트와 같이 표시됩니다.
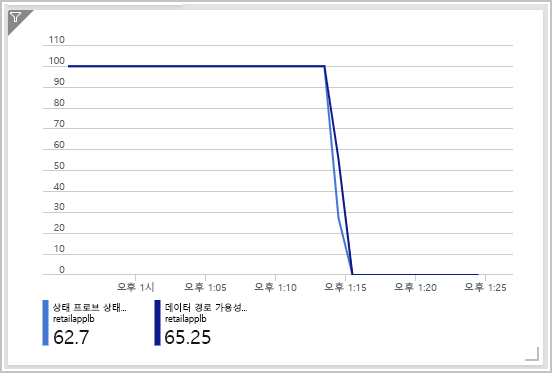
이 차트를 통해 가상 머신이 부하 분산 장치의 상태 프로브 요청에 응답하지 않는 것을 알 수 있습니다. 따라서 가상 머신이 비정상으로 표시되었습니다. 해당 가상 머신에서 실행되는 애플리케이션과 클라이언트 간에 사용 가능한 데이터 경로가 없습니다.
문제 진단 및 해결
첫 번째 단계는 가상 머신이 실행되고 있는지 확인하는 것입니다. 한 번에 하나씩, 가상 머신의 문제를 해결해 봅시다. appretailvm1을 먼저 살펴보겠습니다. appretailvm2는 나중에 검사할 것입니다.
appretailvm1 가상 머신 테스트
동일한 서브넷의 다른 가상 머신에서만 사용할 수 있는 프라이빗 주소를 가진 appretailvm1 또는 appretailvm2 가상 머신을 직접 ping할 수는 없습니다. 먼저 공용 IP 주소가 있고 동일한 서브넷에 있는 점프 상자에 연결합니다. 그런 다음, 점프 상자에서 가상 머신을 ping할 수 있습니다.
Cloud Shell로 돌아갑니다.
다음 명령을 실행하여 점프 상자 가상 머신의 IP 주소를 가져옵니다.
bash ~/load-balancer/src/scripts/jumpboxip.sh다음 명령을 실행하여 초기 설치 스크립트를 실행할 때 만든 암호를 가져옵니다. 다음 단계를 위해 이 암호를 복사합니다.
cd ~/load-balancer/src/scripts cat passwd.txt이전 명령 출력의 IP 주소와 암호를 사용하여 점프 상자에 로그인합니다. 다른 사용자 이름을 사용하는 경우 azureuser를 바꿉니다.
ssh azureuser@<jump box ip address>점프 상자에서 다음 명령을 실행하여 retailappvm1 가상 머신이 실행되고 있는지를 테스트합니다.
ping retailappvm1 -c 10retailappvm1 가상 머신이 응답하여, 실행되고 있음을 나타냅니다. 다음 단계는 이 가상 머신에서 웹앱이 실행되고 있는지를 확인하는 것입니다.
다음 명령을 실행하여 HTTP GET 요청을 retailappvm1 가상 머신으로 보냅니다.
curl -v http://retailappvm1이 명령도 성공합니다.
상태 프로브 및 라우팅 규칙 확인
retailappvm1 가상 머신이 작동하고, 해당 가상 머신에서 애플리케이션이 실행되고 있습니다. 백 엔드 풀의 가상 머신과 부하 분산 장치 간에 문제가 발생해야 합니다.
Azure Portal에서 모니터를 검색합니다.
모니터 - 개요 페이지에서 Service Health를 선택합니다.
Resource Health를 선택합니다.
리소스 종류 상자에서 부하 분산 장치를 선택합니다. 리소스 목록에서 retailapplb를 선택합니다.
부하 분산 장치 상태를 평가하는 동안 몇 분 정도 기다립니다.
상태 기록에서 최상위 이벤트를 펼쳐 권장 단계를 검토합니다. 해당 단계에서는 부하 분산 장치의 VIP(라우팅 규칙) 및 DIP(상태 프로브) 엔드포인트를 확인하도록 권장합니다.
learn-ts-loadbalancer-rg 리소스 그룹으로 이동하여 retailapplb를 선택합니다.
부하 분산 규칙>retailapprule을 선택합니다. 이 규칙은 프런트 엔드 IP 주소의 포트 80에서 TCP 트래픽을 수신하여 백 엔드 풀에서 선택된 가상 머신의 포트 80으로 보냅니다. 상태 프로브에서 사용하는 포트가 의심스러워 보이지만, 이 구성은 올바른 것 같습니다. 현재는 포트 85로 설정되어 있습니다.
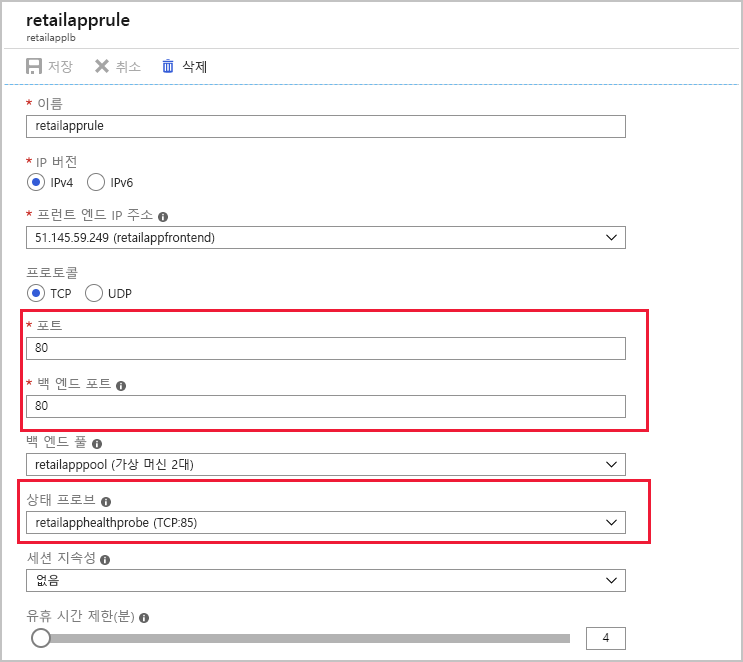
retailapprule 페이지를 닫습니다.
상태 프로브>retailapphealthprobe를 선택합니다.
포트를 85에서 80으로 다시 변경하고 저장을 선택합니다.
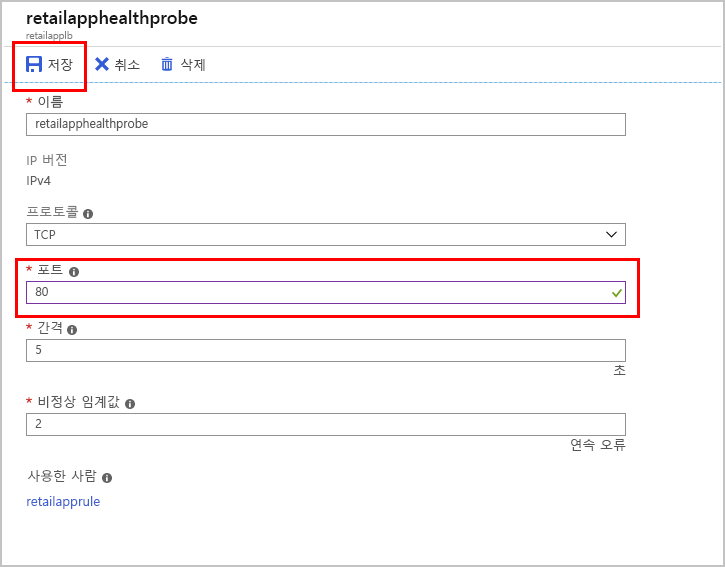
잠시 기다립니다.
Azure Portal 왼쪽에 있는 메뉴에서 대시보드를 선택합니다.
대시보드에서 상태 프로브 상태 및 데이터 경로 가용성 메트릭을 표시하는 차트를 선택합니다. 데이터 경로 가용성 메트릭은 100으로 증가했지만, 상태 프로브 상태 메트릭은 대략 50을 가리킵니다. 이제 부하 분산 장치에서 하나 이상의 가상 머신으로 이어진 경로를 사용할 수 있지만, 가상 머신의 50%만 정상으로 표시됩니다.
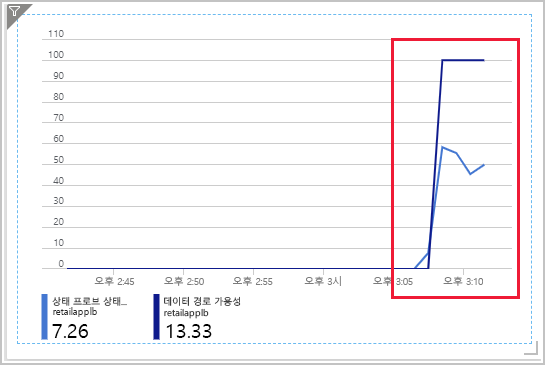
차트를 선택하여 Load Balancer에 대한 메트릭 페이지로 이동합니다. 이 페이지에서는 차트를 새로 고치고 특정 기간을 확대할 수 있습니다.
Cloud Shell에서 다음 명령을 실행하여 점프 상자를 종료합니다.
exit부하 분산 장치의 IP 주소를 사용하여 스트레스 테스트 애플리케이션을 다시 실행합니다.
cd ~/load-balancer/src/stresstest dotnet run <ip address>이전과 마찬가지로 테스트가 실패합니다. 이제 부하 분산 장치에서 하나 이상의 가상 머신으로 이어진 경로가 있지만, 가상 네트워크 외부에서 실행되는 클라이언트에서는 이 경로가 작동하지 않습니다. Enter 키를 눌러 스트레스 테스트 앱을 중지합니다.
서브넷의 NSG 규칙 확인
이 문제는 외부 트래픽을 차단하는 네트워크 보안 규칙 때문일 수 있습니다.
Azure Portal에서 learn-ts-loadbalancer-rg 리소스 그룹으로 이동합니다.
retailappnsg 네트워크 보안 그룹을 선택합니다. 이 보안 그룹은 가상 네트워크 통과가 허용되는 트래픽을 결정합니다.
인바운드 보안 규칙을 선택합니다. 가상 네트워크에서 실행되는 부하 분산 장치에서 들어오는 트래픽을 허용하는 규칙은 있지만 포트 80을 통해 가상 네트워크 외부에서 시작되는 트래픽을 허용하는 규칙은 없습니다.
추가를 선택합니다. 인바운드 보안 규칙 추가 창이 표시됩니다.
다음 설정을 입력하고 추가를 선택합니다.
속성 값 원본 모두 원본 포트 범위 * 대상 모두 서비스 사용자 지정 대상 포트 범위 80 프로토콜 TCP 작업 허용 우선 순위 100 이름 Port_80 설명 HTTP 포트 Cloud Shell에서 부하 분산 장치의 IP 주소를 사용하여 스트레스 테스트 애플리케이션을 다시 실행합니다.
cd ~/load-balancer/src/stresstest dotnet run <ip address>이제 애플리케이션이 실행되지만, retailappvm1 가상 머신의 응답만 수신됩니다. 애플리케이션을 2~3분 동안 실행합니다. Enter 키를 눌러 애플리케이션을 중지합니다.
Azure Portal에서 대시보드로 이동합니다.
평균 패킷 개수 메트릭 차트를 선택합니다. 최신 스트레스 테스트 애플리케이션 실행의 최댓값을 확인합니다. 이 값은 앞에서 두 가상 머신을 모두 사용할 수 있었을 때 기록된 값의 두 배 이상입니다. 이제 작동하는 시스템이 있지만, 작업 가상 머신이 오버로드될 위험이 있습니다.
appretailvm2 가상 머신 테스트
appretailvm2 가상 머신이 요청을 제대로 처리하지 못하는 것 같습니다. 가상 머신이 작동하는지 여부와 Load Balancer에서 가상 머신에 연결할 수 있는지를 확인해야 합니다.
Cloud Shell에서 이전 명령 출력의 IP 주소와 암호를 사용하여 점프 상자에 로그인합니다.
ssh azureuser@<jump box ip address>appretailvm2 가상 머신에 ping을 시도합니다.
ping retailappvm2 -c 10가상 머신이 응답하지 않고 ping 명령이 100% 패킷 손실을 보고합니다. retailappvm2 가상 머신이 실행되고 있지 않거나 네트워크에 문제가 있습니다.
Azure Portal에서 learn-ts-loadbalancer-rg 리소스 그룹으로 이동합니다.
retailappvm2 가상 머신을 선택합니다.
개요 페이지에는 가상 머신이 중지된 것으로 표시됩니다. 시작을 선택하고, 머신 실행이 시작될 때까지 기다립니다.
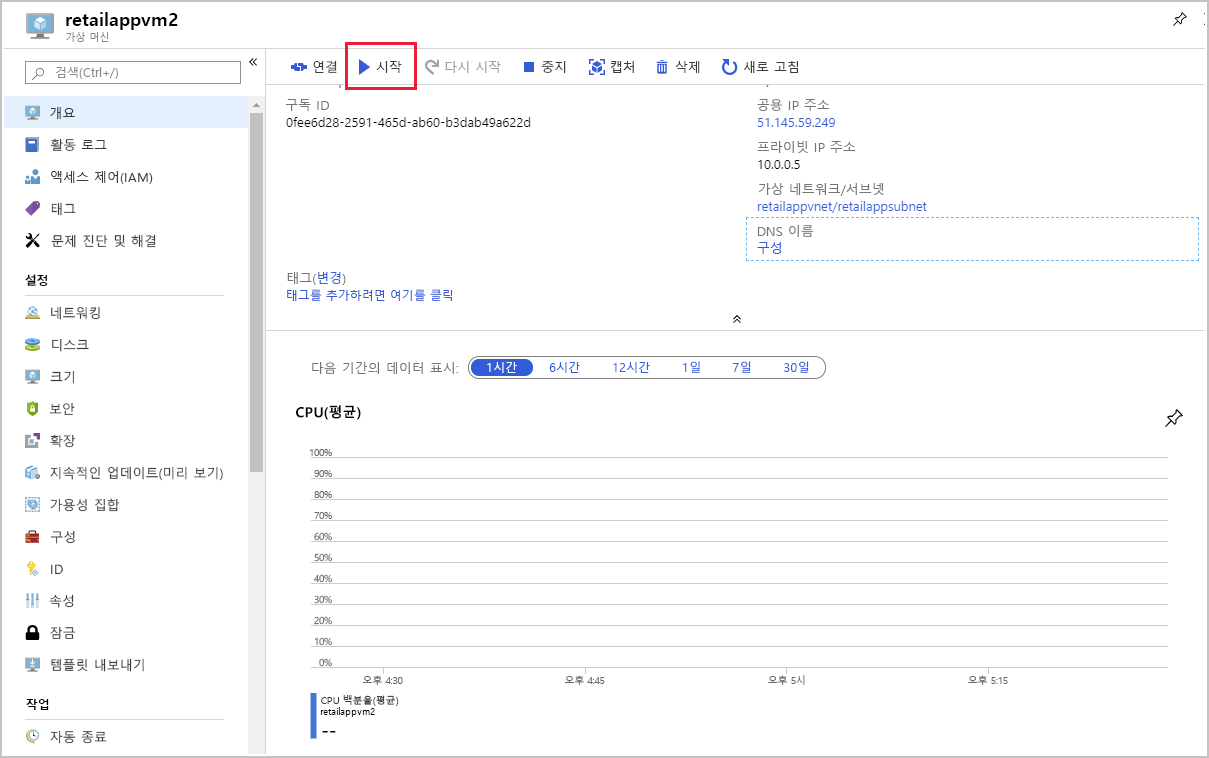
점프 상자에 연결된 Cloud Shell로 돌아가서 ping 명령을 반복합니다.
ping retailappvm2 -c 10이번에는 ping 작업이 성공합니다.
retailappvm2 가상 머신에서 실행되는 애플리케이션이 응답하는지를 테스트합니다.
wget retailappvm2이 명령은 시간 초과됩니다. 애플리케이션이 실행되고 있지 않거나 네트워크 문제가 있을 수 있습니다. Ctrl+C를 눌러 명령을 중지합니다.
점프 상자에서 retailappvm2 가상 머신에 로그인합니다. 메시지가 표시되면 앞에서 지정한 것과 동일한 암호를 입력합니다.
ssh azureuser@retailappvm2다음 명령을 실행하여 이 가상 머신의 애플리케이션을 테스트합니다.
wget retailappvm2명령이 성공적으로 실행되고 응답을 포함하는 index.html 파일을 만듭니다.
이 index.html 파일을 검사합니다.
cat index.html해당 파일에는 retailappvm2 메시지가 포함되며 이 가상 머신이 예상대로 응답했음을 나타냅니다.
retailappvm2 가상 머신에 대한 연결을 닫습니다.
exit점프 상자에 대한 연결을 닫습니다.
exitretailappvm2 가상 머신이 작동하고 앱이 실행되고 있지만, 가상 머신 외부에서 앱에 연결할 수 없습니다. 해당 이슈는 네트워크 문제를 나타냅니다.
Azure Portal에서 learn-ts-loadbalancer-rg 리소스 그룹으로 이동합니다.
retailappnicvm2nsg 네트워크 보안 그룹을 선택합니다.
인바운드 보안 규칙을 선택합니다.
네트워크 보안 그룹에 TCP 프로토콜을 사용하는 외부 트래픽을 모두 차단하는 인바운드 규칙이 있습니다. 해당 규칙이 포트 80을 여는 규칙보다 우선 순위가 낮기 때문에 우선 적용됩니다.
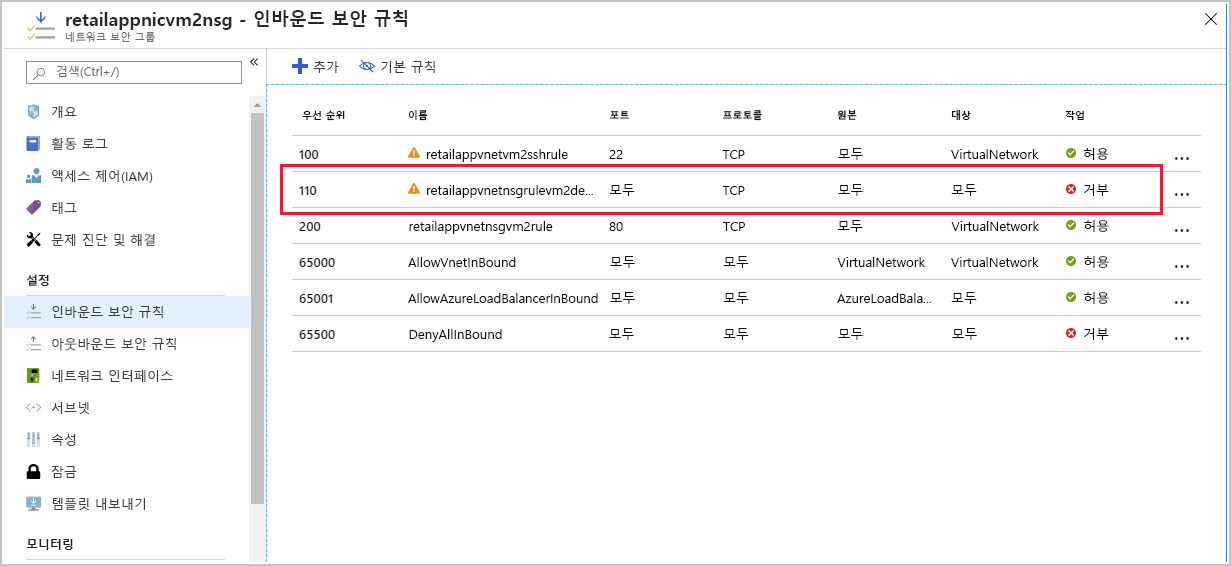
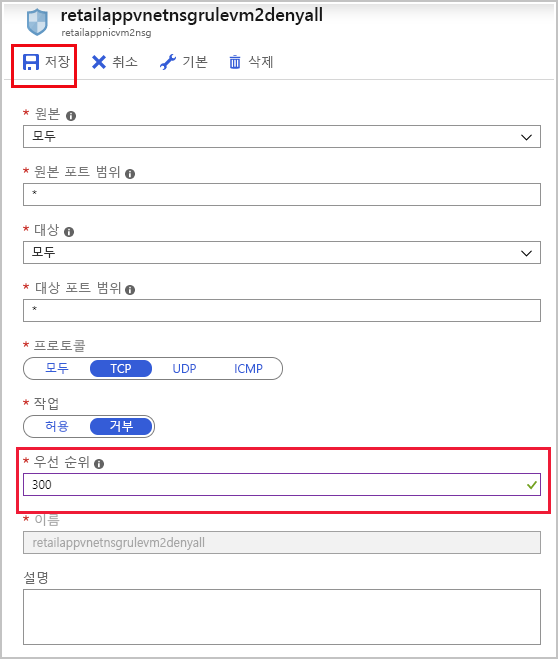
retailappvnetnsgrulevm2denyall 규칙을 선택하고 우선 순위를 300으로 변경한 다음, 저장을 선택합니다.
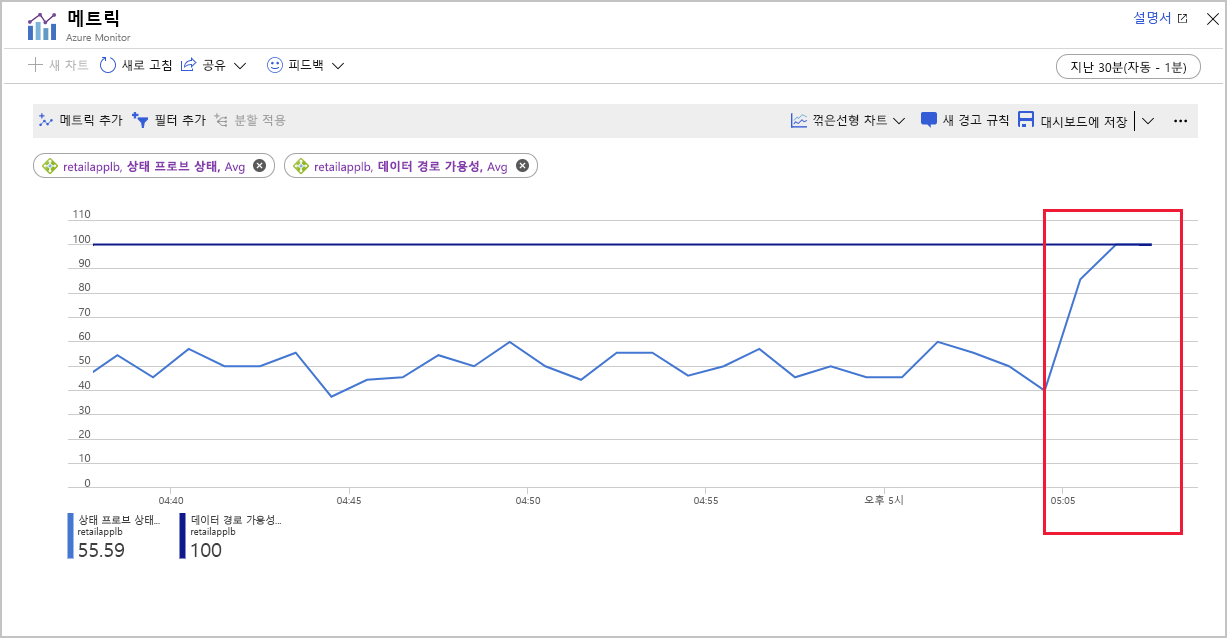
2분 동안 기다린 후 대시보드로 이동합니다.
상태 프로브 상태 메트릭을 표시하는 차트를 선택합니다. 이 메트릭의 값이 100으로 증가했습니다. 차트를 몇 번 새로 고쳐야 할 수도 있습니다.
Cloud Shell로 전환한 다음, 부하 분산 장치의 IP 주소를 사용하여 stresstest 애플리케이션을 다시 실행합니다.
cd ~/load-balancer/src/stresstest dotnet run <ip address>이제 retailappvm1 및 retailappvm2의 메시지가 표시됩니다. 시스템에 대한 전체 연결을 복원했습니다.
Enter 키를 눌러 애플리케이션을 중지합니다.
요약
이 연습을 시작할 때 가상 머신이 부하 분산 장치의 상태 프로브 요청에 응답하지 않는 것을 확인했습니다. 프로빙 및 데이터 경로 문제의 조합을 검색하고 해결했습니다.
- retailapprule 부하 분산 장치 규칙에서 상태 프로브에 사용되는 포트가 80이 아닌 85로 잘못 구성되었습니다. 포트 80을 사용하도록 규칙을 업데이트했습니다.
- retailappnsg 네트워크 보안 그룹에 포트 80의 트래픽을 허용하는 인바운드 보안 규칙이 없었습니다. 이 때문에 네트워크 보안 그룹이 상태 프로브를 차단했습니다. 포트 80의 트래픽을 허용하는 인바운드 보안 규칙을 추가했습니다.
- VM retailappvm2가 있는 것과 중지되었음을 확인했으며 해당 VM을 다시 시작했습니다.
- VM retailappvm2를 시작하고 앱이 실행되고 있음을 확인한 후에도 앱에 연결할 수 없었습니다. 네트워크 보안 그룹에 TCP 프로토콜의 네트워크 트래픽을 모두 차단하는 인바운드 규칙이 있었습니다. “모두 거부” 규칙이 포트 80의 트래픽을 허용하는 인바운드 보안 규칙보다 우선 적용되었습니다. “모두 거부” 규칙의 우선 순위를 포트 80 규칙보다 높게 변경했습니다. 이렇게 변경함으로써 포트 80에서 TCP의 인바운드 네트워크 트래픽이 허용되었습니다.
부하가 분산된 HTTP 서비스를 전체 작동으로 되돌렸습니다.