데이터 파일 분할
분할은 Spark가 작업자 노드에서 성능을 극대화할 수 있도록 하는 최적화 기술입니다. 불필요한 디스크 IO를 제거하여 쿼리에서 데이터를 필터링할 때 성능을 더 많이 향상할 수 있습니다.
출력 파일 분할
데이터 프레임을 분할된 파일 집합으로 저장하려면 데이터를 작성할 때 partitionBy 메서드를 사용합니다.
다음 예제에서는 파생된 Year 필드를 만듭니다. 그런 다음, 데이터를 분할하는 데 사용합니다.
from pyspark.sql.functions import year, col
# Load source data
df = spark.read.csv('/orders/*.csv', header=True, inferSchema=True)
# Add Year column
dated_df = df.withColumn("Year", year(col("OrderDate")))
# Partition by year
dated_df.write.partitionBy("Year").mode("overwrite").parquet("/data")
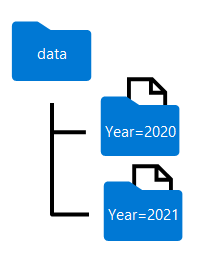
데이터 프레임을 분할할 때 생성된 폴더 이름은 다음과 같이 분할 열 이름과 값을 column=value 형식으로 포함합니다.
참고 항목
데이터를 여러 열로 분할하여 각 분할 키에 대한 폴더 계층 구조를 만들 수 있습니다. 예를 들어 폴더 계층 구조에 각 연도 값에 대한 폴더가 포함되도록 예제의 순서를 연도 및 월별로 분할할 수 있습니다. 그러면 각 월 값에 대한 하위 폴더가 포함됩니다.
쿼리에서 parquet 파일 필터링
parquet 파일에서 데이터 프레임으로 데이터를 읽을 때 계층 구조 폴더 내의 폴더에서 데이터를 끌어올 수 있습니다. 이 필터링 프로세스는 분할된 필드에 대해 명시적 값과 와일드카드를 사용하여 수행됩니다.
다음 예제에서 다음 코드는 2020년에 진행된 판매 주문을 가져옵니다.
orders_2020 = spark.read.parquet('/partitioned_data/Year=2020')
display(orders_2020.limit(5))
참고
파일 경로에 지정된 분할 열은 결과 데이터 프레임에서 생략됩니다. 예제 쿼리에서 생성된 결과에는 Year 열이 포함되지 않습니다. 모든 행은 2020년에서 가져옵니다.