Azure AI Search 푸시 API를 사용하여 모든 데이터 인덱싱
REST API는 Azure AI Search 인덱스로 데이터를 푸시하는 가장 유연한 방법입니다. 모든 프로그래밍 언어를 사용하거나 엔드포인트에 JSON 요청을 게시할 수 있는 앱과 대화형으로 사용할 수 있습니다.
여기서는 REST API를 효과적으로 사용하고 사용 가능한 작업을 탐색하는 방법을 알아보세요. 그런 다음, .NET Core 코드를 살펴보고 API를 통해 대량의 데이터 추가를 최적화하는 방법을 알아봅니다.
지원되는 REST API 작업
AI Search에서 제공하는 두 가지 지원되는 REST API가 있습니다. 검색 및 관리 API. 이 모듈에서는 검색의 5가지 기능에 대한 작업을 제공하는 검색 REST API에 중점을 둡니다.
| 기능 | 작업 |
|---|---|
| 인덱스 | 만들고, 삭제하고, 업데이트하고, 구성합니다. |
| 문서 | 가져오고, 추가하고, 업데이트하고, 삭제합니다. |
| 인덱서 | 제한된 데이터 원본에 대한 데이터 원본 및 일정 예약을 구성합니다. |
| 기술 집합 | 가져오고, 만들고, 삭제하고, 나열하고, 업데이트합니다. |
| 동의어 맵 | 가져오고, 만들고, 삭제하고, 나열하고, 업데이트합니다. |
검색 REST API를 호출하는 방법
검색 API를 호출하려면 다음을 수행해야 합니다.
- 검색 서비스에서 제공하는 HTTPS 엔드포인트(기본 포트 443을 통해)를 사용하려면 URI에 api-version을 포함해야 합니다.
- 요청 헤더에는 api-key 특성이 포함되어야 합니다.
엔드포인트, api-version, api-key를 찾으려면 Azure Portal로 이동합니다.

포털에서 검색 서비스로 이동한 다음, 검색 탐색기를 선택합니다. REST API 엔드포인트는 요청 URL 필드에 있습니다. URL의 첫 번째 부분은 엔드포인트(예: https://azsearchtest.search.windows.net)이며 쿼리 문자열은 api-version(예: api-version=2023-07-01-Preview)을 표시합니다.

왼쪽에서 api-key를 찾으려면 키를 선택합니다. REST API를 사용하여 인덱스 쿼리 이상의 작업을 수행하는 경우 기본 또는 보조 관리 키를 사용할 수 있습니다. 인덱스를 검색하기만 하면 되는 경우 쿼리 키를 만들고 사용할 수 있습니다.
인덱스의 데이터를 추가, 업데이트 또는 삭제하려면 관리 키를 사용해야 합니다.
인덱스로 데이터 추가
다음 형식의 인덱스 기능을 사용하여 HTTP POST 요청을 사용합니다.
POST https://[service name].search.windows.net/indexes/[index name]/docs/index?api-version=[api-version]
요청 본문은 REST 엔드포인트가 문서에 대해 수행할 작업, 작업을 적용할 문서, 사용할 데이터를 알려야 합니다.
JSON은 다음 형식이어야 합니다.
{
"value": [
{
"@search.action": "upload (default) | merge | mergeOrUpload | delete",
"key_field_name": "unique_key_of_document", (key/value pair for key field from index schema)
"field_name": field_value (key/value pairs matching index schema)
...
},
...
]
}
| 작업 | 설명 |
|---|---|
| upload | SQL의 upsert와 유사하게 문서가 만들어지거나 바뀝니다. |
| merge | 병합에서는 기존 문서를 지정한 필드로 업데이트합니다. 문서를 찾을 수 없으면 병합이 실패합니다. |
| mergeOrUpload | 병합은 기존 문서를 지정된 필드로 업데이트하고 문서가 없으면 업로드합니다. |
| delete | 전체 문서를 삭제합니다. key_field_name을 지정하기만 하면 됩니다. |
요청이 성공하면 API는 200 상태 코드를 반환합니다.
참고 항목
모든 응답 코드 및 오류 메시지의 전체 목록은 문서 추가, 업데이트 또는 삭제(Azure AI Search REST API)를 참조 하세요.
이 예제 JSON은 이전 단원에서 고객 레코드를 업로드합니다.
{
"value": [
{
"@search.action": "upload",
"id": "5fed1b38309495de1bc4f653",
"firstName": "Sims",
"lastName": "Arnold",
"isAlive": false,
"age": 35,
"address": {
"streetAddress": "Sumner Place",
"city": "Canoochee",
"state": "Palau",
"postalCode": "1558"
},
"phoneNumbers": [
{
"phoneNumber": {
"type": "home",
"number": "+1 (830) 465-2965"
}
},
{
"phoneNumber": {
"type": "home",
"number": "+1 (889) 439-3632"
}
}
]
}
]
}
값 배열에 원하는 만큼 문서를 추가할 수 있습니다. 그러나 최적의 성능을 위해 요청에서 문서를 최대 1,000개 또는 총 크기로 16MB까지 일괄 처리하는 것이 좋습니다.
.NET Core를 사용하여 모든 데이터 인덱싱
최상의 성능을 위해 최신 Azure.Search.Document 클라이언트 라이브러리(현재 버전 11)를 사용합니다. NuGet을 사용하여 클라이언트 라이브러리를 설치할 수 있습니다.
dotnet add package Azure.Search.Documents --version 11.4.0
인덱스의 성능은 다음 6가지 주요 요소를 기반으로 합니다.
- 검색 서비스 계층 및 사용하도록 설정한 복제본 및 파티션 수입니다.
- 인덱스 스키마의 복잡성입니다. 각 필드에 있는 속성(검색 가능, 패싯 가능, 정렬 가능)의 수를 줄입니다.
- 각 일괄 처리의 문서 수, 가장 적합한 크기는 인덱스 스키마 및 문서 크기에 따라 달라집니다.
- 접근 방식이 다중 스레드된 정도입니다.
- 오류 처리 및 제한입니다. 지수 백오프 재시도 전략을 사용합니다.
- 데이터가 있는 위치에서 검색 인덱스에 가깝게 데이터를 인덱싱해 보세요. 예를 들어 Azure 환경 내에서 업로드를 실행합니다.
최적의 일괄 처리 크기 해결
최상의 일괄 처리 크기를 계산하는 것이 성능을 향상시키는 핵심 요소이므로 코드에서 접근 방식을 살펴보겠습니다.
public static async Task TestBatchSizesAsync(SearchClient searchClient, int min = 100, int max = 1000, int step = 100, int numTries = 3)
{
DataGenerator dg = new DataGenerator();
Console.WriteLine("Batch Size \t Size in MB \t MB / Doc \t Time (ms) \t MB / Second");
for (int numDocs = min; numDocs <= max; numDocs += step)
{
List<TimeSpan> durations = new List<TimeSpan>();
double sizeInMb = 0.0;
for (int x = 0; x < numTries; x++)
{
List<Hotel> hotels = dg.GetHotels(numDocs, "large");
DateTime startTime = DateTime.Now;
await UploadDocumentsAsync(searchClient, hotels).ConfigureAwait(false);
DateTime endTime = DateTime.Now;
durations.Add(endTime - startTime);
sizeInMb = EstimateObjectSize(hotels);
}
var avgDuration = durations.Average(timeSpan => timeSpan.TotalMilliseconds);
var avgDurationInSeconds = avgDuration / 1000;
var mbPerSecond = sizeInMb / avgDurationInSeconds;
Console.WriteLine("{0} \t\t {1} \t\t {2} \t\t {3} \t {4}", numDocs, Math.Round(sizeInMb, 3), Math.Round(sizeInMb / numDocs, 3), Math.Round(avgDuration, 3), Math.Round(mbPerSecond, 3));
// Pausing 2 seconds to let the search service catch its breath
Thread.Sleep(2000);
}
Console.WriteLine();
}
이 방법은 일괄 처리 크기를 늘리고 유효한 응답을 받는 데 걸리는 시간을 모니터링하는 것입니다. 코드는 100개 문서 단계에서 100~1,000개까지 반복됩니다. 각 일괄 처리 크기에 대해 문서 크기, 응답을 가져오는 시간, MB당 평균 시간을 출력합니다. 이 코드를 실행하면 다음과 같은 결과가 제공됩니다.
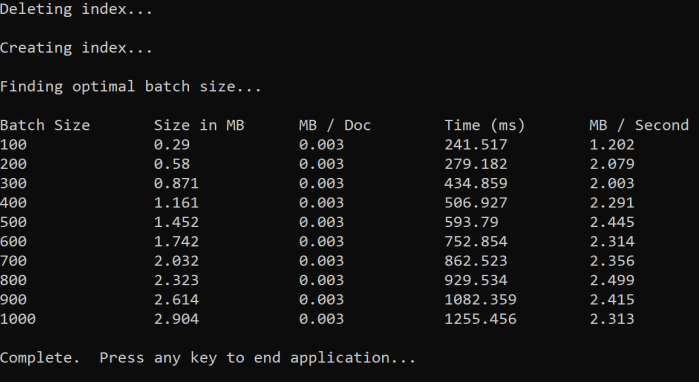
위의 예제에서 처리량에 가장 적합한 일괄 처리 크기는 초당 2.499MB, 일괄 처리당 문서 800개입니다.
지수 백오프 다시 시도 전략 구현
인덱스가 오버로드로 인해 요청을 제한하기 시작하면 503(과부하로 인해 거부된 요청) 또는 207(일부 문서가 일괄 처리에서 실패) 상태로 응답합니다. 이러한 응답을 처리해야 하며 좋은 전략은 백오프하는 것입니다. 백오프는 요청을 다시 시도하기 전에 잠시 일시 중지하는 것을 의미합니다. 각 오류에 대해 이 시간을 늘리면 기하급수적으로 백오프됩니다.
다음 코드를 살펴보세요.
// Implement exponential backoff
do
{
try
{
attempts++;
result = await searchClient.IndexDocumentsAsync(batch).ConfigureAwait(false);
var failedDocuments = result.Results.Where(r => r.Succeeded != true).ToList();
// handle partial failure
if (failedDocuments.Count > 0)
{
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
else
{
Console.WriteLine("[Batch starting at doc {0} had partial failure]", id);
Console.WriteLine("[Retrying {0} failed documents] \n", failedDocuments.Count);
// creating a batch of failed documents to retry
var failedDocumentKeys = failedDocuments.Select(doc => doc.Key).ToList();
hotels = hotels.Where(h => failedDocumentKeys.Contains(h.HotelId)).ToList();
batch = IndexDocumentsBatch.Upload(hotels);
Task.Delay(delay).Wait();
delay = delay * 2;
continue;
}
}
return result;
}
catch (RequestFailedException ex)
{
Console.WriteLine("[Batch starting at doc {0} failed]", id);
Console.WriteLine("[Retrying entire batch] \n");
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
Task.Delay(delay).Wait();
delay = delay * 2;
}
} while (true);
코드는 실패한 문서를 일괄 처리로 추적합니다. 오류가 발생하면 지연을 기다린 다음, 다음 오류에 대한 지연 시간을 두 배로 증분합니다.
마지막으로, 최대 재시도 횟수가 있으며 이 최대 수에 도달하면 프로그램이 존재합니다.
스레딩을 사용하여 성능 향상
위의 백오프 전략과 스레딩 방법을 결합하여 문서 업로드 앱을 완료할 수 있습니다. 다음 예제 코드를 살펴보세요.
public static async Task IndexDataAsync(SearchClient searchClient, List<Hotel> hotels, int batchSize, int numThreads)
{
int numDocs = hotels.Count;
Console.WriteLine("Uploading {0} documents...\n", numDocs.ToString());
DateTime startTime = DateTime.Now;
Console.WriteLine("Started at: {0} \n", startTime);
Console.WriteLine("Creating {0} threads...\n", numThreads);
// Creating a list to hold active tasks
List<Task<IndexDocumentsResult>> uploadTasks = new List<Task<IndexDocumentsResult>>();
for (int i = 0; i < numDocs; i += batchSize)
{
List<Hotel> hotelBatch = hotels.GetRange(i, batchSize);
var task = ExponentialBackoffAsync(searchClient, hotelBatch, i);
uploadTasks.Add(task);
Console.WriteLine("Sending a batch of {0} docs starting with doc {1}...\n", batchSize, i);
// Checking if we've hit the specified number of threads
if (uploadTasks.Count >= numThreads)
{
Task<IndexDocumentsResult> firstTaskFinished = await Task.WhenAny(uploadTasks);
Console.WriteLine("Finished a thread, kicking off another...");
uploadTasks.Remove(firstTaskFinished);
}
}
// waiting for the remaining results to finish
await Task.WhenAll(uploadTasks);
DateTime endTime = DateTime.Now;
TimeSpan runningTime = endTime - startTime;
Console.WriteLine("\nEnded at: {0} \n", endTime);
Console.WriteLine("Upload time total: {0}", runningTime);
double timePerBatch = Math.Round(runningTime.TotalMilliseconds / (numDocs / batchSize), 4);
Console.WriteLine("Upload time per batch: {0} ms", timePerBatch);
double timePerDoc = Math.Round(runningTime.TotalMilliseconds / numDocs, 4);
Console.WriteLine("Upload time per document: {0} ms \n", timePerDoc);
}
이 코드는 백오프 전략을 구현하는 함수 ExponentialBackoffAsync에 대한 비동기 호출을 사용합니다. 스레드를 사용하여 함수를 호출합니다(예: 프로세서에 있는 코어 수). 최대 스레드 수를 사용한 경우 코드는 모든 스레드가 완료되기를 기다립니다. 그런 다음, 모든 문서가 업로드될 때까지 새 스레드를 만듭니다.