Azure Data Factory를 사용하여 외부 데이터 원본의 데이터 인덱싱
Azure에 없는 외부 데이터를 추가하는 것은 조직의 검색 솔루션에서 일반적으로 필요합니다. Azure AI Search는 여러 가지 방법으로 데이터를 만들고 인덱스에 푸시할 수 있으므로 유연합니다.
ADF(Azure Data Factory)를 사용하여 검색 인덱스로 데이터 푸시
첫 번째 방법은 ADF를 사용하여 인덱스로 데이터를 푸시하기 위한 제로 코드 옵션입니다. ADF는 거의 100개의 다른 데이터 저장소에 대한 연결과 함께 제공됩니다. HTTP 및 REST와 같은 커넥터를 사용하면 무제한의 데이터 저장소를 연결할 수 있습니다. 이러한 데이터 저장소는 파이프라인에서 원본 또는 대상(복사 작업의 싱크라고 함)으로 사용됩니다.
Azure AI Search 인덱스 커넥터는 복사 작업에서 싱크로 사용할 수 있습니다.
검색 인덱스로 데이터를 푸시하는 ADF 파이프라인 만들기
사용하기 위해 수행해야 하는 단계와 검색 인덱스로 데이터를 푸시하는 ADF 파이프라인은 다음과 같습니다.
- 데이터를 저장하려는 모든 필드를 사용하여 Azure AI Search 인덱스 만들기
- 데이터 복사 단계를 사용하여 파이프라인을 만듭니다.
- 데이터가 있는 위치에 대한 데이터 원본 연결을 만듭니다.
- 검색 인덱스에 연결할 싱크를 만듭니다.
- 원본 데이터의 필드를 검색 인덱스로 매핑합니다.
- 파이프라인을 실행하여 데이터를 인덱스로 푸시합니다.
예를 들어 외부에서 호스트되는 JSON 형식의 고객 데이터를 사용한다고 상상해 보세요. 이러한 고객을 검색 인덱스로 복사하려고 합니다. JSON은 다음과 같은 형식입니다.
{
"_id": "5fed1b38309495de1bc4f653",
"firstName": "Sims",
"lastName": "Arnold",
"isAlive": false,
"age": 35,
"address": {
"streetAddress": "Sumner Place",
"city": "Canoochee",
"state": "Palau",
"postalCode": 1558
},
"phoneNumbers": [
{
"type": "home",
"number": "+1 (830) 465-2965"
},
{
"type": "home",
"number": "+1 (889) 439-3632"
}
]
}
검색 인덱스 만들기
이 정보를 저장할 Azure AI Search 서비스 및 인덱스 만들기 Azure AI Search 솔루션 만들기 모듈을 완료한 경우 이 작업을 수행하는 방법을 살펴보았습니다. 단계에 따라 검색 서비스를 만들지만 데이터 가져오기 지점에서 중지합니다. 인덱스로 데이터를 푸시하기 때문에 인덱서 또는 기술 세트를 만들 필요가 없습니다.
인덱스를 만들고 다음 필드 및 속성을 추가합니다.

지금은 ADF에서 인덱스를 만들 수 없으므로 먼저 인덱스를 만들어야 합니다.
ADF 데이터 복사 도구를 사용하여 파이프라인 만들기
Azure Data Factory Studio를 열고 Azure 구독 및 데이터 팩터리 이름을 선택합니다.

수집을 선택합니다.
다음을 선택합니다.
참고
데이터가 변경되고 인덱스가 최신 상태로 유지되어야 하는 경우 파이프라인을 예약하도록 선택할 수 있습니다. 이 예제에서는 데이터를 한 번 가져옵니다.
원본 연결된 서비스 만들기
원본 유형에서 HTTP를 선택합니다.
연결 옆에 있는 + 새 연결을 선택합니다.
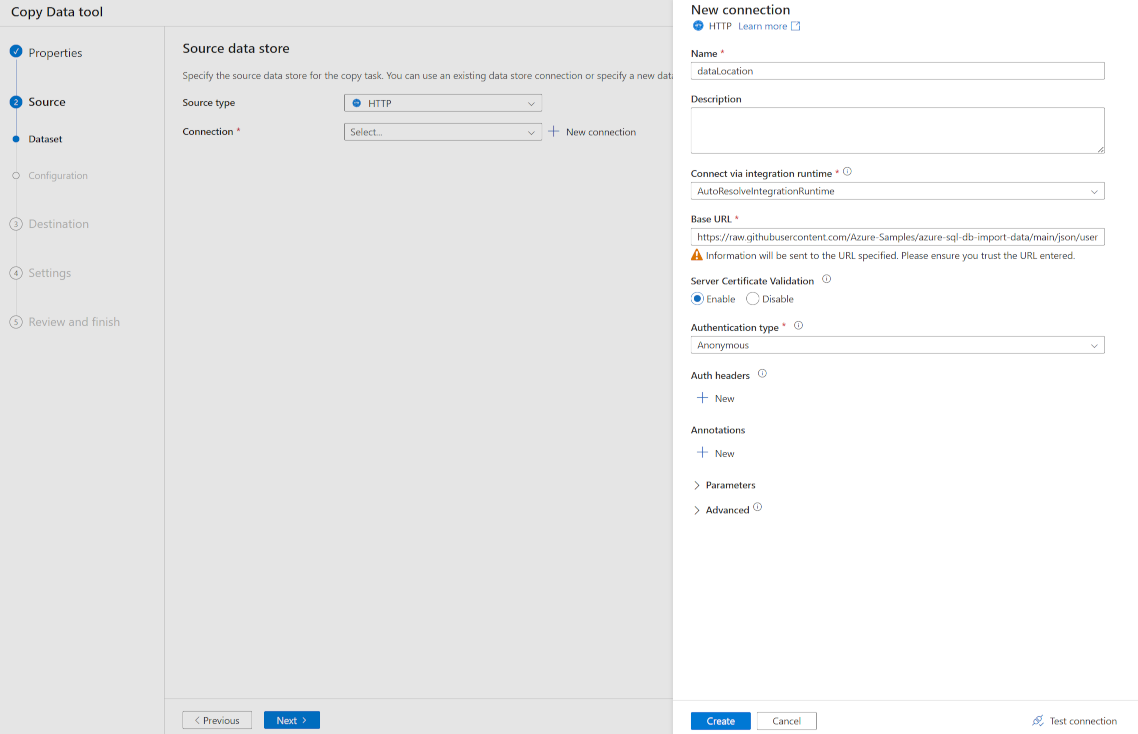
새 연결 창의 이름에 dataLocation을 입력합니다.
기본 URL에서 JSON 파일이 있는 위치를 입력합니다. 이 예제에서는 https://raw.githubusercontent.com/Azure-Samples/azure-sql-db-import-data/main/json/user1.json을 입력합니다.
인증 유형에서 익명을 선택합니다.
만들기를 선택합니다.
다음을 선택합니다.
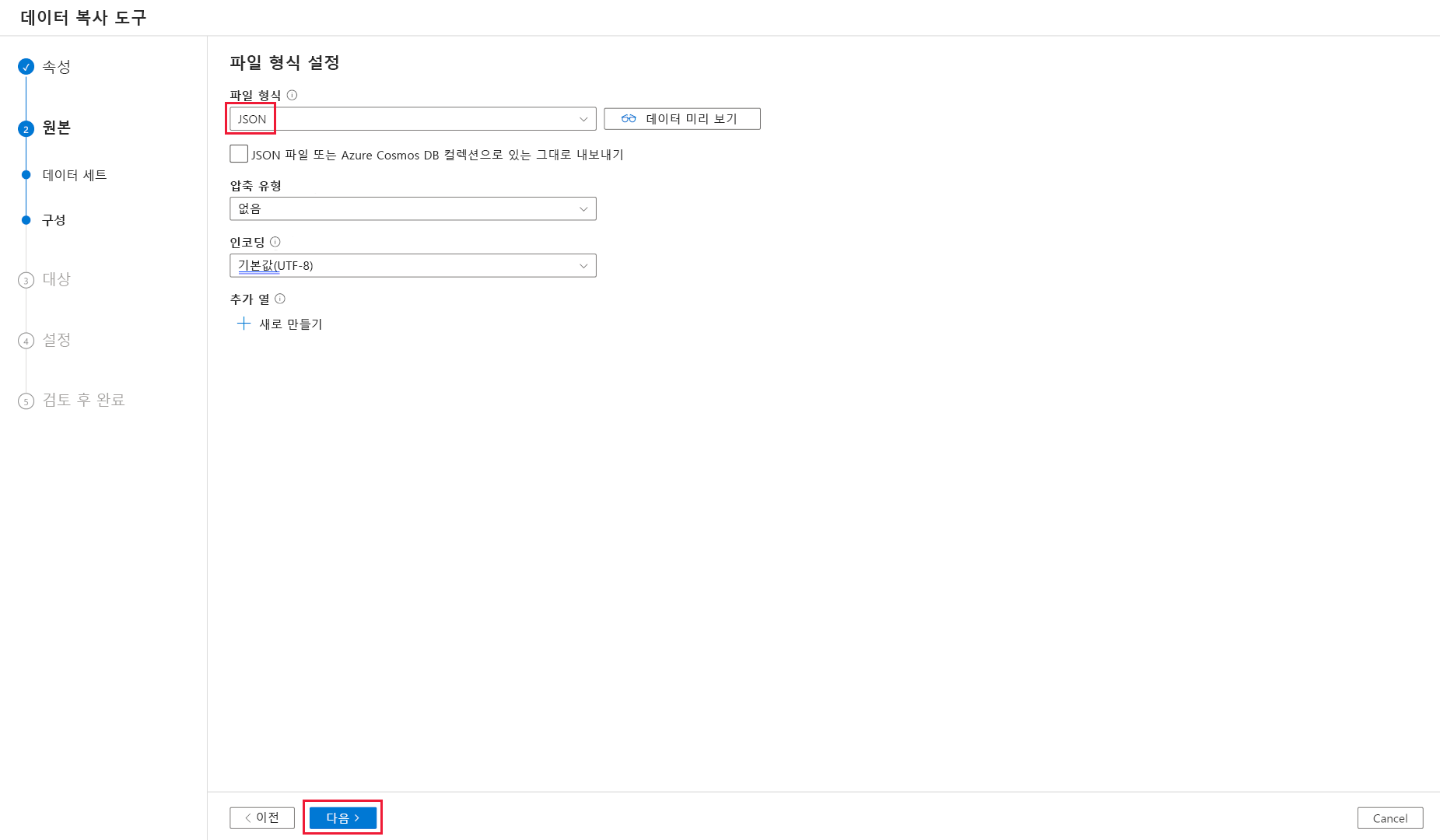
파일 형식에서 JSON을 선택합니다.
다음을 선택합니다.


대상 연결된 서비스 만들기
대상 유형에서 Azure Search를 선택합니다. 그런 다음 + 새 연결을 선택합니다.
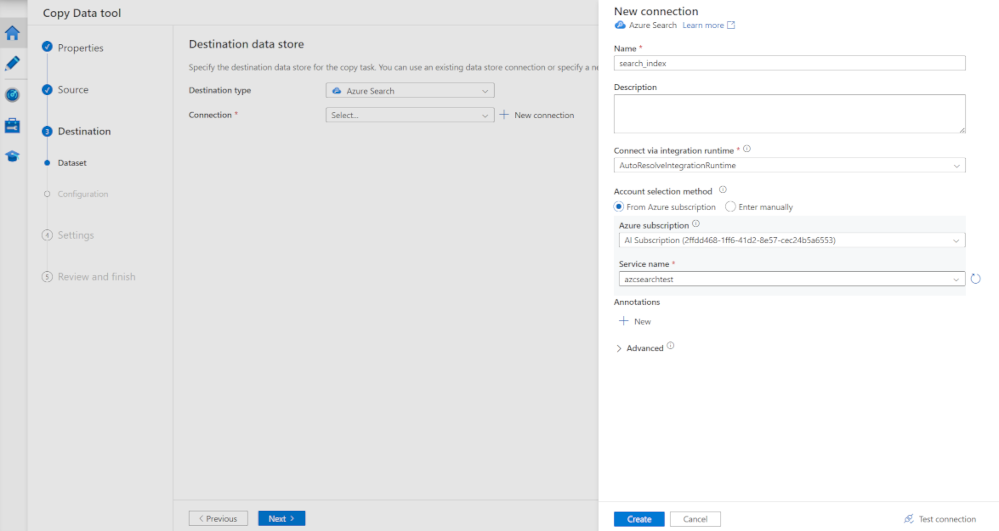
새 연결 창의 이름에 search_index를 입력합니다.
Azure 구독에서 Azure 구독을 선택합니다.
서비스 이름에서 Azure AI Search 서비스를 선택합니다.
만들기를 실행합니다.
대상 데이터 저장소 창의 대상에서 만든 검색 인덱스를 선택합니다.

원본 필드를 대상 필드에 매핑
다음을 선택합니다.
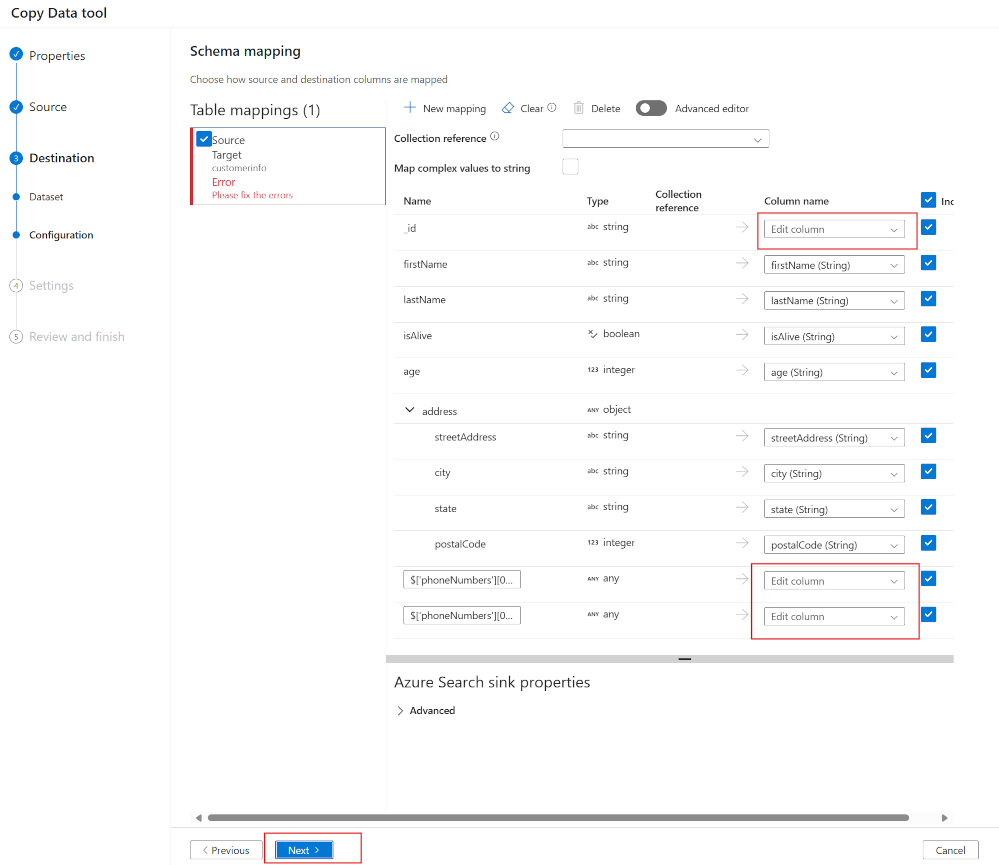
JSON 특성과 일치하는 필드 이름을 사용하여 인덱스를 만든 경우 ADF는 JSON을 검색 인덱스의 필드에 자동으로 매핑합니다.
위의 예제에서 JSON 문서의 세 필드는 인덱스 필드에 매핑해야 합니다.
필드를 매핑한 다음, 다음을 선택합니다.
설정 창의 작업 이름에서 jsonToSearchIndex를 입력합니다.
다음을 선택합니다.

파이프라인을 실행하여 데이터를 인덱스로 푸시
요약 창에서 다음을 선택합니다.
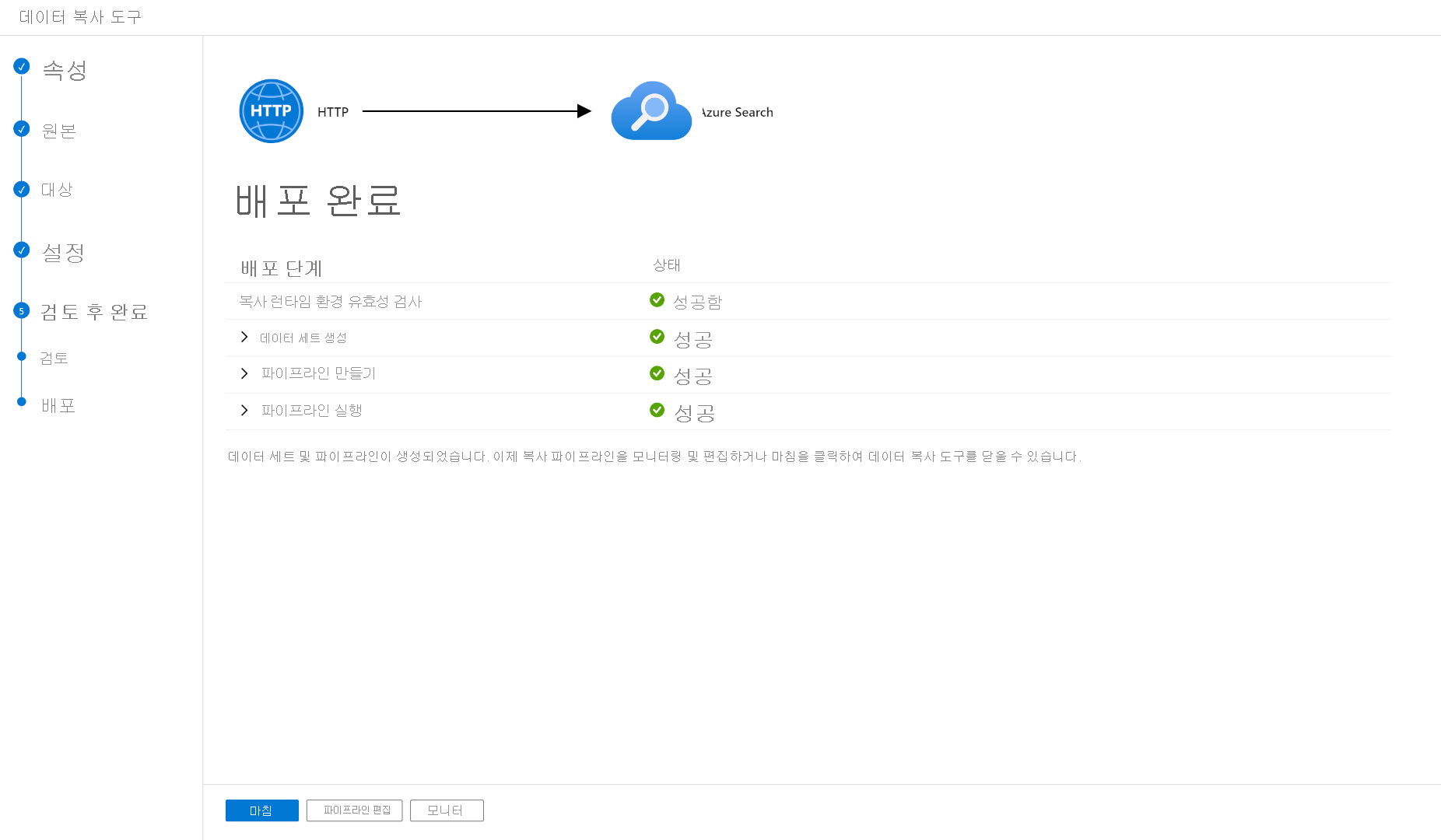
파이프라인의 유효성을 검사하고 배포한 후 마침을 선택합니다.

파이프라인이 배포되고 실행되었습니다. JSON 문서가 검색 인덱스로 추가됩니다. Azure Portal을 사용하여 검색 탐색기에서 검색을 실행할 수 있습니다. 가져온 JSON 데이터가 표시되어야 합니다.

다음 단계에 따라 데이터를 인덱스로 푸시하는 방법을 살펴보았습니다. 기본적으로 만든 파이프라인은 업데이트를 인덱스에 병합합니다. JSON 데이터를 수정하고 파이프라인을 다시 실행하면 검색 인덱스가 업데이트됩니다. 파이프라인을 실행할 때마다 데이터를 바꾸려는 경우에만 업로드하도록 쓰기 동작을 변경할 수 있습니다.
기본 제공 Azure AI Search를 연결된 서비스로 사용하는 제한 사항
현재 싱크로서의 Azure AI Search 연결된 서비스는 다음 필드만 지원합니다.
| Azure AI 검색 데이터 형식 |
|---|
| 문자열 |
| Int32 |
| Int64 |
| Double |
| Boolean |
| DataTimeOffset |
즉, ComplexTypes 및 배열은 현재 지원되지 않습니다. 위의 JSON 문서를 보면 고객의 전화 번호를 모두 매핑할 수 없습니다. 첫 번째 전화 번호만 매핑되었습니다.