연습 - 데이터 정리 및 준비
데이터 세트를 준비하려면 먼저 데이터 세트의 내용과 구조를 이해해야 합니다. 이전 랩에서는 미국 주요 항공사의 정시 도착 정보가 포함된 데이터 세트를 가져왔습니다. 이 데이터 세트에는 26개의 열과 수천 개의 행이 있으며, 각 행은 하나의 항공편을 나타내며 항공편의 출발지, 목적지 및 예정 출발 시간과 같은 정보를 포함하고 있습니다. 또한 데이터를 Jupyter Notebook에 로드하고, 간단한 Python 스크립트를 사용하여 Pandas DataFrame을 만들었습니다.
DataFrame은 레이블이 지정된 2차원 데이터 구조입니다. DataFrame의 열은 스프레드시트 또는 데이터베이스 테이블의 열처럼 서로 다른 형식일 수 있습니다. 또한 Pandas에서 가장 일반적으로 사용되는 개체입니다. 이 연습에서는 DataFrame과 그 안의 데이터를 더 자세히 검사합니다.
이전 섹션에서 만든 Azure Notebook으로 다시 전환합니다. Notebook을 닫은 경우 Microsoft Azure Notebooks 포털에 다시 로그인하고, Notebook을 열고, 셀 ->모두 실행을 사용하여 Notebook의 모든 셀을 다시 실행할 수 있습니다.
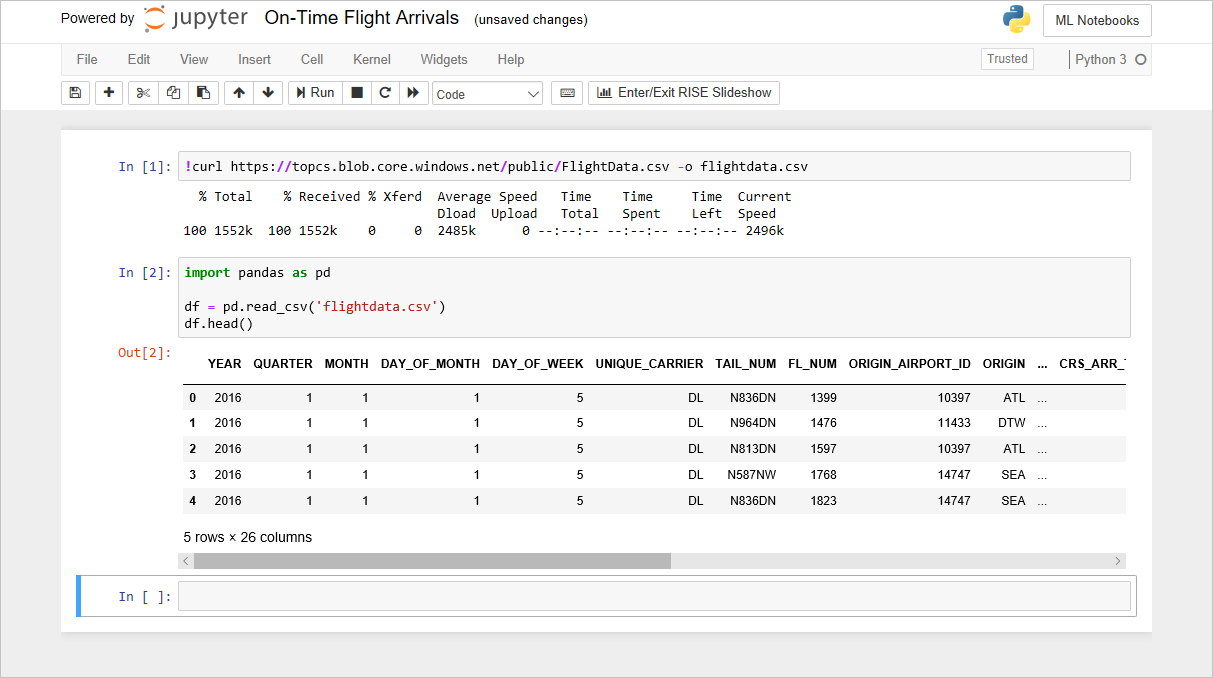
FlightData Notebook
이전 랩에서 Notebook에 추가한 코드는 flightdata.csv에서 DataFrame을 만들고, DataFrame.head를 호출하여 처음 5개의 행을 표시합니다. 일반적으로 데이터 세트에 대해 알려고 하는 첫 번째 항목 중 하나는 이 세트에 포함된 행의 수입니다. 수를 가져오려면 Notebook의 끝에 있는 빈 셀에 다음 명령문을 입력하고 실행합니다.
df.shapeDataFrame에 11,231개의 행과 26개의 열이 포함되어 있는지 확인합니다.

행 및 열 수 가져오기
이제 데이터 세트의 26개 열을 잠시 검사합니다. 여기에는 항공편의 운항 날짜(YEAR, MONTH 및 DAY_OF_MONTH), 출발지와 목적지(ORIGIN 및 DEST), 예정 출발 및 도착 시간(CRS_DEP_TIME 및 CRS_ARR_TIME), 예정 및 실제 도착 시간의 차이(ARR_DELAY, 분 단위) 및 항공편이 15분 이상 지연 도착되었는지 여부(ARR_DEL15)와 같은 중요한 정보가 포함되어 있습니다.
다음은 데이터 세트의 전체 열 목록입니다. 시간은 24시간 군사 형식으로 표현됩니다. 예를 들어 1130은 오전 11시 30분에 해당하고 1500은 오후 3시에 해당합니다.
열 설명 YEAR 비행한 연도 QUARTER 비행한 분기(1-4) MONTH 비행한 월(1-12) DAY_OF_MONTH 비행한 월의 날짜(1-31) DAY_OF_WEEK 비행한 요일(1 = 월요일, 2 = 화요일 등) UNIQUE_CARRIER 항공사 코드(예: DL) TAIL_NUM 항공기 식별 번호 FL_NUM 항공편 번호 ORIGIN_AIRPORT_ID 출발지 공항 ID ORIGIN 출발지 공항 코드(ATL, DFW, SEA 등) DEST_AIRPORT_ID 도착지 공항 ID DEST 도착지 공항 코드(ATL, DFW, SEA 등) CRS_DEP_TIME 예정 출발 시간 DEP_TIME 실제 출발 시간 DEP_DELAY 출발 지연 시간(분) DEP_DEL15 0 = 15분 미만 지연 출발, 1 = 15분 이상 지연 출발 CRS_ARR_TIME 예정 도착 시간 ARR_TIME 실제 도착 시간 ARR_DELAY 도착 지연 시간(분) ARR_DEL15 0 = 15분 미만 지연 도착, 1 = 15분 이상 지연 도착 CANCELLED 0 = 항공편 정상 운항, 1 = 항공편 취소 DIVERTED 0 = 항공편 순항, 1 = 항공편 회항 CRS_ELAPSED_TIME 예정 비행 시간(분) ACTUAL_ELAPSED_TIME 실제 비행 시간(분) DISTANCE 비행 거리(마일)
데이터 세트에는 일 년 내내 거의 균등한 날짜 분포가 포함되어 있으며, 이는 미니애폴리스에서 출발하는 항공편이 1월에 비해 7월에 겨울 폭풍으로 인해 지연될 가능성이 낮으므로 중요합니다. 그러나 이 데이터 세트는 "깨끗이 정리되어" 사용할 준비가 되어 있지 않습니다. 일부 Pandas 코드를 작성하여 정리해 보겠습니다.
기계 학습에 사용할 데이터 세트를 준비하는 데 있어 가장 중요한 측면 중 하나는 결과에 영향을 주지 않거나, 부정적인 방식으로 편향될 수 있거나, 다중 공선성(multicollinearity)이 생성될 수 있는 열을 필터링하면서 예측하려는 결과와 관련된 "기능" 열을 선택하는 것입니다. 또 다른 중요한 작업은 누락된 값이 있는 행 또는 열을 삭제하거나 의미 있는 값으로 바꿔서 누락된 해당 값을 제거하는 것입니다. 이 연습에서는 불필요한 열을 제거하고 나머지 열의 누락된 값을 바꿉니다.
일반적으로 과학자가 데이터 세트에서 가장 먼저 찾는 항목 중 하나는 누락된 값입니다. Pandas에는 누락된 값을 쉽게 확인할 수 있는 방법이 있습니다. 이를 시연하려면 Notebook의 끝에 있는 셀에서 다음 코드를 실행합니다.
df.isnull().values.any()출력이 "True"인지 확인합니다. 이 값은 데이터 세트의 어딘가에 하나 이상의 누락된 값이 있음을 나타냅니다.

누락된 값 확인
다음 단계는 누락된 값의 위치를 찾는 것입니다. 이렇게 하려면 다음 코드를 실행합니다.
df.isnull().sum()각 열에 대한 누락된 값의 수가 나열된 다음 출력이 표시되는지 확인합니다.
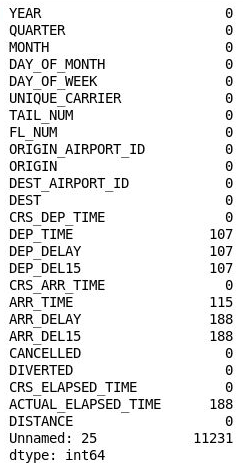
각 열의 누락된 값 수
흥미롭게도 26번째 열("이름 없음: 25")의 누락된 값 수는 데이터 세트의 행 수와 동일한 11,231개입니다. 이 열은 가져온 CSV 파일에 각 행의 끝에 쉼표가 포함되어 있어 실수로 만들어졌습니다. 이 열을 제거하려면 Notebook에 다음 코드를 추가하고 실행합니다.
df = df.drop('Unnamed: 25', axis=1) df.isnull().sum()출력을 검사하고 DataFrame에서 26번째 열이 사라졌는지 확인합니다.
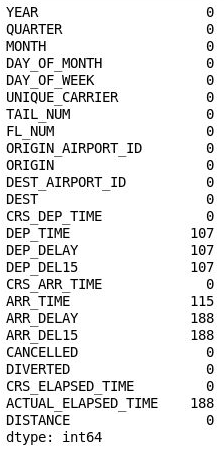
26번째 열이 제거된 DataFrame
DataFrame에는 여전히 누락된 값이 많이 포함되어 있지만, 이러한 값이 포함된 열은 현재 작성 중인 모델과 관련이 없으므로 일부 값은 유용하지 않습니다. 이 모델의 목표는 예약하려는 항공편이 정시에 도착할 수 있는지 여부를 예측하는 것입니다. 항공편이 늦게 도착될 가능성이 있음을 알 수 있으면 다른 항공편을 예약하도록 선택할 수 있습니다.
따라서 다음 단계는 예측 모델과 관련이 없는 열을 제거하기 위해 데이터 세트를 필터링하는 것입니다. 예를 들어 항공기 식별 번호는 항공편이 정시에 도착할지 여부와 거의 관련이 없으며, 항공권을 예약할 때 항공편이 취소, 회항 또는 지연될지 여부를 알 수 없습니다. 반면, 예정 출발 시간은 정시 도착과 많은 관련이 있을 수 있습니다. 대부분의 항공사에서 사용하는 허브 및 스포크 시스템에 따라 아침 항공편은 오후 또는 저녁 항공편보다 더 자주 정시에 운항되는 경향이 있습니다. 그리고 일부 주요 공항에서는 낮 동안에 교통량이 증가하여 나중의 항공편이 지연될 가능성이 높아집니다.
Pandas는 원하지 않는 열을 쉽게 필터링할 수 있는 방법을 제공합니다. Notebook의 끝에 있는 새 셀에서 다음 코드를 실행합니다.
df = df[["MONTH", "DAY_OF_MONTH", "DAY_OF_WEEK", "ORIGIN", "DEST", "CRS_DEP_TIME", "ARR_DEL15"]] df.isnull().sum()이제 출력에서 DataFrame에 모델과 관련된 열만 포함되고 누락된 값의 수가 크게 줄었음을 알 수 있습니다.
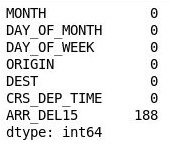
필터링된 DataFrame
이제 누락된 값이 포함된 유일한 열은 ARR_DEL15 열입니다. 이 열에서는 0을 사용하여 정시에 도착한 항공편을 식별하고, 그렇지 않은 항공편에 대해 1을 사용합니다. 다음 코드를 사용하여 누락된 값이 있는 처음 5개 행을 표시합니다.
df[df.isnull().values.any(axis=1)].head()Pandas는 Not a Number(숫자가 아님)를 나타내는
NaN을 사용하여 누락된 값을 나타냅니다. 출력에서 이러한 행의 ARR_DEL15 열에 실제로 누락된 값이 있음을 알 수 있습니다.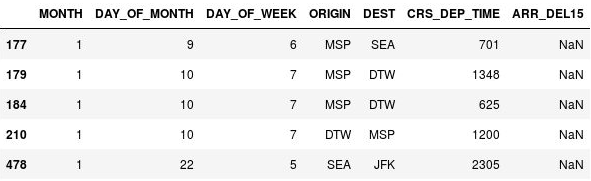
누락된 값이 있는 행
이러한 행에서 ARR_DEL15 값이 누락되는 이유는 모두 취소되거나 회항된 항공편에 해당하기 때문입니다. DataFrame에서 dropna를 호출하여 이러한 행을 제거할 수 있습니다. 그러나 취소되거나 다른 공항으로 회항된 항공편은 "늦음"으로 간주될 수 있으므로 filna 메서드를 사용하여 누락된 값을 1로 바꾸겠습니다.
다음 코드를 사용하여 ARR_DEL15 열의 누락된 값을 1s로 바꾸고 177~184번째 열을 표시합니다.
df = df.fillna({'ARR_DEL15': 1}) df.iloc[177:185]177, 179, 184번째 행의
NaN이 항공편이 늦게 도착했음을 나타내는 1로 바뀌었는지 확인합니다.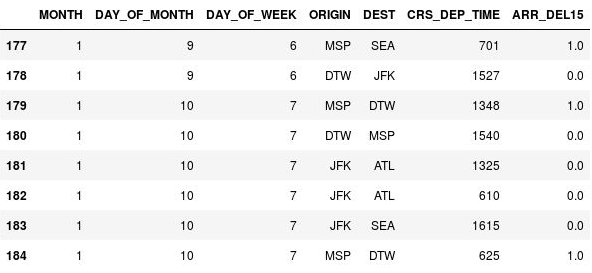
1로 바뀐 NaN
누락된 값이 바뀌었고 열 목록이 모델과 가장 관련이 있는 값으로 좁혀졌다는 점에서 데이터 세트는 이제 "깨끗이 정리된" 상태입니다. 그러나 아직 끝나지 않았습니다. 기계 학습에 사용할 데이터 세트를 준비하기 위한 작업이 더 많이 남아 있습니다.
사용 중인 데이터 세트의 CRS_DEP_TIME 열은 예정 출발 시간을 나타냅니다. 500개가 넘는 고유 값을 포함하고 있는 이 열의 숫자 세분성으로 인해 기계 학습 모델의 정확도에 부정적인 영향을 줄 수 있습니다. 이 문제는 범주화 또는 정량화라는 기술을 사용하여 해결할 수 있습니다. 이 열의 각 숫자를 100으로 나누고 가장 가까운 정수로 내림하면 어떻게 될까요? 1030은 10, 1925는 19 등으로 되며, 이 열에 최대 24개의 불연속 값이 남게 됩니다. 직관적으로, 이해할 수 있습니다. 항공편이 오전 10시 30분에 출발하든 오전 10시 40분에 출발하든 별로 중요하지 않기 때문입니다. 그러나 오전 10시 30분에 출발하는지 아니면 오후 5시 30분에 출발하는지는 매우 중요합니다.
또한 데이터 세트의 ORIGIN 및 DEST 열에는 범주형 기계 학습 값을 나타내는 공항 코드가 포함되어 있습니다. 이러한 열은 지표 변수를 포함하는 불연속 열(때로는 "더미" 변수라고도 함)로 변환되어야 합니다. 즉, 5개의 공항 코드가 포함된 ORIGIN 열은 공항당 하나씩 5개의 열로 변환되어야 하며, 각 열에는 해당 열이 나타내는 공항에서 출발했는지 여부를 나타내는 1과 0이 포함됩니다. DEST 열도 비슷한 방식으로 처리해야 합니다.
이 연습에서는 CRS_DEP_TIME 열의 시작 시간을 "범주화(bin)"하고, Pandas의 get_dummies 메서드를 사용하여 ORIGIN 및 DEST 열에서 지표 열을 만듭니다.
다음 명령을 사용하여 DataFrame의 처음 5개 행을 표시합니다.
df.head()CRS_DEP_TIME 열에 군사 형식 시간을 나타내는 0~2359의 값이 포함되어 있는지 확인합니다.
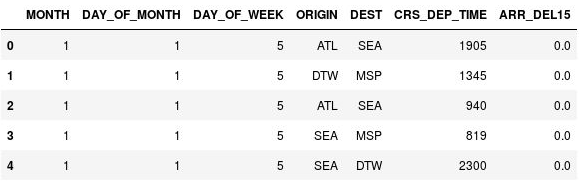
범주화되지 않은 출발 시간이 있는 DataFrame
다음 명령문을 사용하여 출발 시간을 범주화합니다.
import math for index, row in df.iterrows(): df.loc[index, 'CRS_DEP_TIME'] = math.floor(row['CRS_DEP_TIME'] / 100) df.head()CRS_DEP_TIME 열의 숫자가 이제 0~23의 범위에 속하는지 확인합니다.
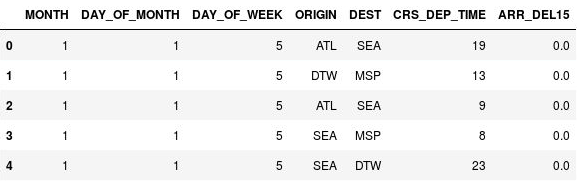
범주화된 출발 시간이 있는 DataFrame
이제 다음 명령문을 사용하여 ORIGIN 및 DEST 열에서 지표 열을 생성하는 한편, ORIGIN 및 DEST 열 자체를 삭제합니다.
df = pd.get_dummies(df, columns=['ORIGIN', 'DEST']) df.head()결과 DataFrame을 검사하고, ORIGIN 및 DEST 열이 원래 열에 있는 공항 코드에 해당하는 열로 바뀌었는지 확인합니다. 새 열에는 지정된 항공편이 해당 공항에서 출발했는지 또는 해당 공항으로 출발했는지 여부를 나타내는 1과 0이 있습니다.
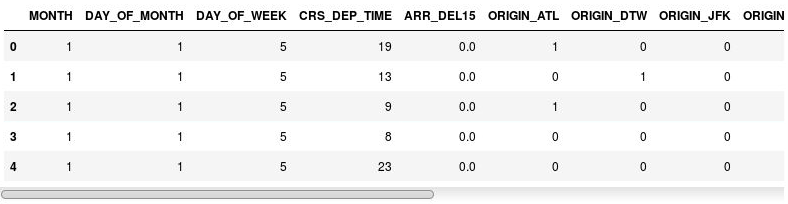
지표 열이 있는 DataFrame
파일 ->저장 및 검사점 명령을 사용하여 Notebook을 저장합니다.
데이터 세트가 시작할 때와 매우 다르게 보이지만 이제 기계 학습에 사용할 수 있도록 최적화되었습니다.