HDInsight 대화형 쿼리
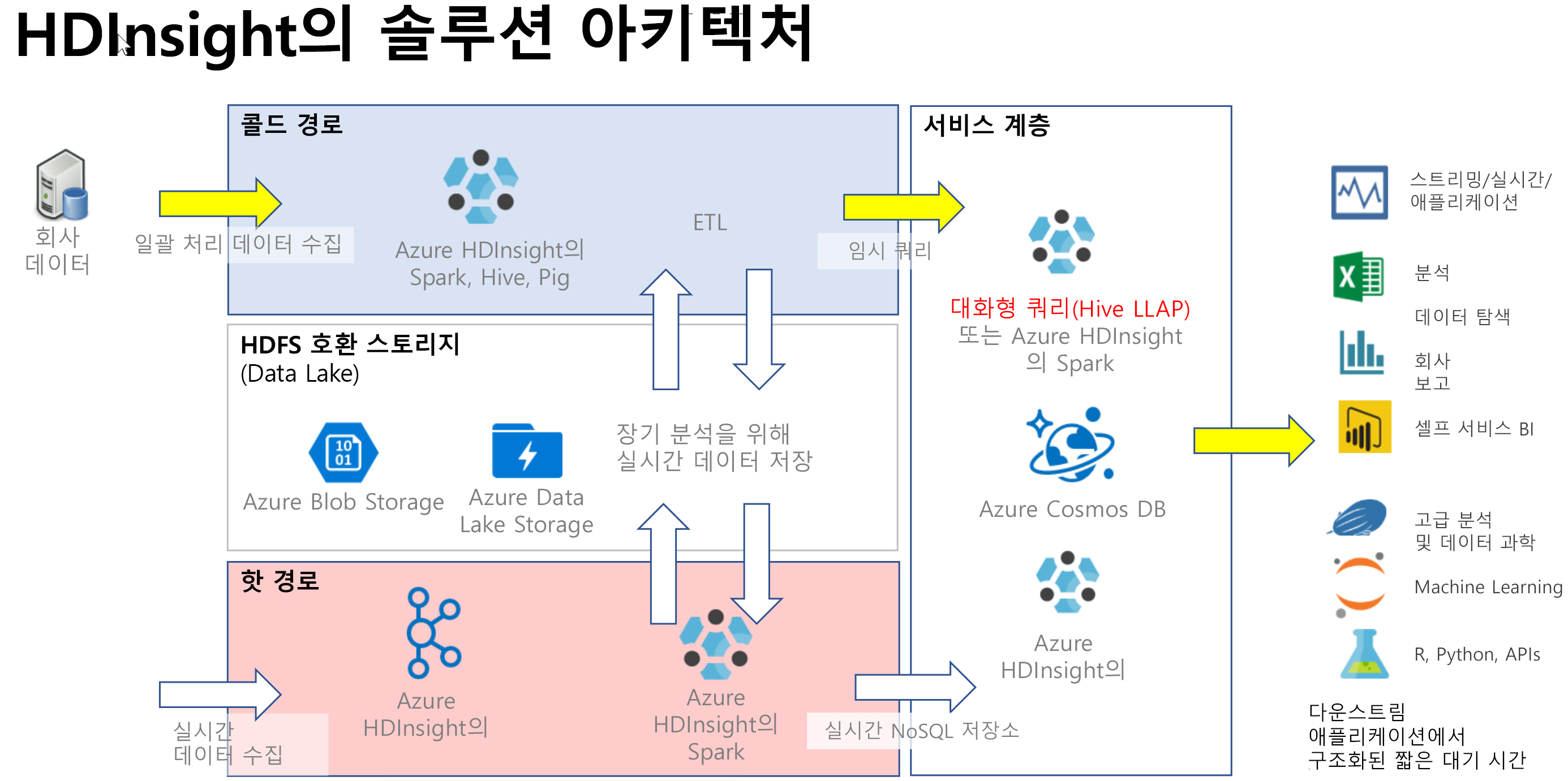
대화형 쿼리는 일반적으로 데이터가 테이블 형식이고 SQL 구문을 통해 빠르게 질문하고 대화형 응답을 받으려는 콜드 경로 시나리오에서 구현됩니다. 다음 다이어그램에서는 모든 HDInsight 콜드 경로 및 실행 부하 과다 경로 솔루션의 솔루션 아키텍처를 보여 주며 서비스 레이어의 Hive LLAP를 통해 대화형 쿼리를 처리하는 방법을 설명합니다. Hive를 통해 데이터를 수집할 수 있고, Hive LLAP를 통해 대화형 쿼리를 처리하고, Power BI 같은 다운스트림 애플리케이션에 출력을 제공할 수 있습니다.
Interactive Query 아키텍처
이제 Interactive Query 아키텍처를 자세히 살펴보겠습니다.
Interactive Query 사용자는 Data Analytics Studio, Zeppelin Notebook 및 Visual Studio Code와 같이 비즈니스 데이터에서 쿼리를 실행할 클라이언트를 다양한 ODBC 또는 JDBC 클라이언트 중에서 선택할 수 있습니다. 클라이언트에서 HiveQL 쿼리를 제출한 후 쿼리는 쿼리 계획, 최적화 및 보안 조정을 처리할 수 있는 HiveServer에 도착합니다. Hive는 클러스터의 분산된 노드에 걸쳐 분석 작업을 분할합니다. 쿼리는 하위 작업으로 분할되어 각 하위 작업을 처리하는 노드로 전송되며, 이 하위 작업은 추가로 분할되고 각 작업은 기본 비즈니스 데이터 스토리지 레이어에서 데이터를 읽습니다. 스토리지에서 검색된 데이터를 저장하고 모든 노드에서 데이터를 공유하는 공유된 메모리 내 캐시뿐만 아니라 시작 시간을 피하는 “always on” LLAP 디먼을 사용하므로 아키텍처가 최적화되어 있습니다.
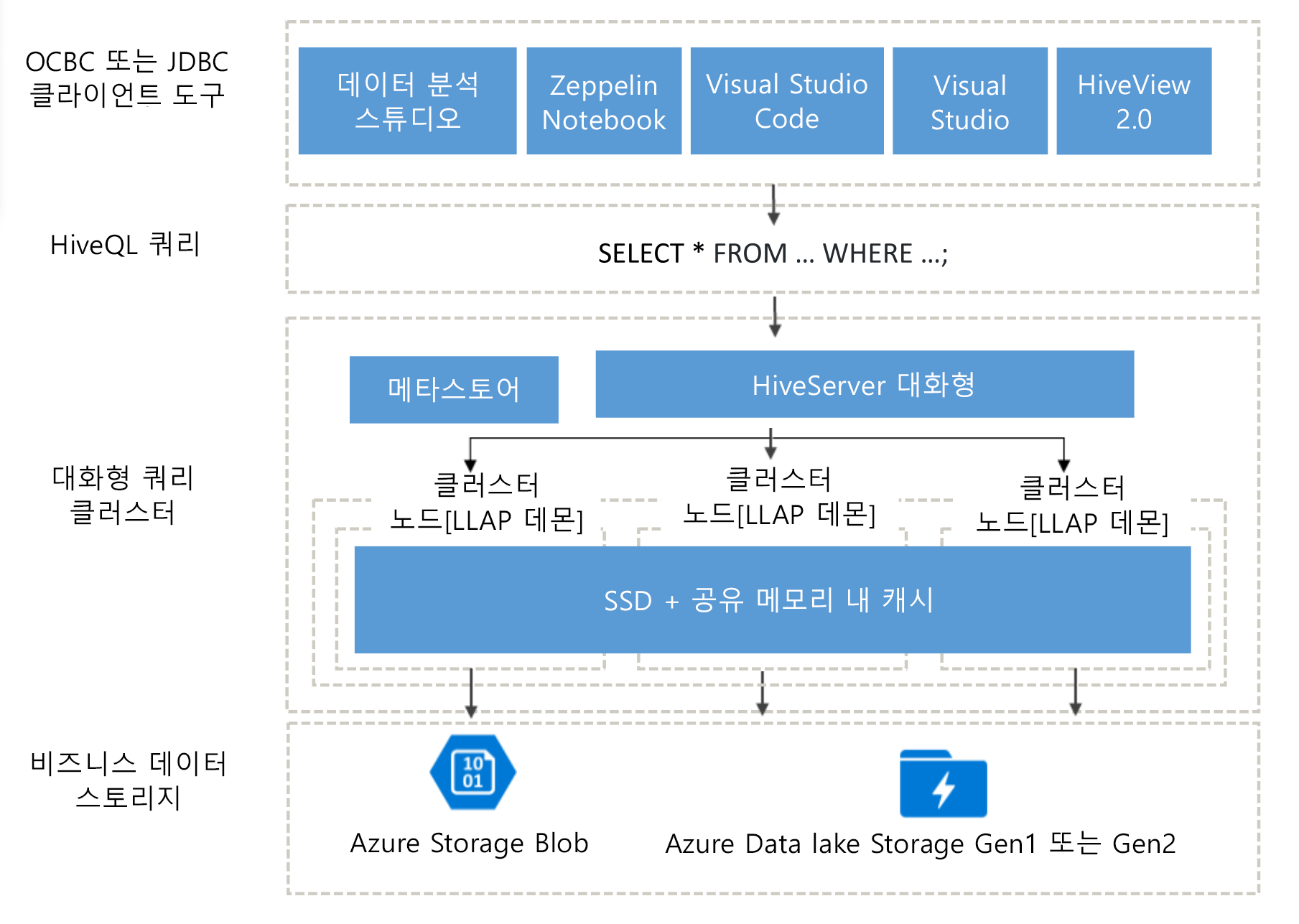
Interactive Query 클러스터에서 사용하는 SSD(반도체 드라이브)는 RAM과 SSD를 캐시에서 사용되는 큰 메모리 풀로 결합합니다. 이 리소스 조합을 사용하는 경우 일반적인 서버 프로필은 4배 더 많은 데이터를 캐시할 수 있으므로 더 큰 데이터 세트를 처리하고 더 많은 사용자를 지원할 수 있습니다. Interactive Query 캐시는 원격 저장소(Azure Storage)의 기본 데이터 변경 내용을 인식하므로 기본 데이터가 변경되고 사용자가 쿼리를 실행하면 추가 사용자 단계 없이도 업데이트된 데이터가 메모리에 로드됩니다.