HDInsight Interactive Query를 언제 사용해야 하나요?
비즈니스 분석가는 솔루션을 빌드하기 위해 만들 가장 적절한 유형의 HDInsight 클러스터를 결정해야 합니다. Interactive Query 클러스터는 SQL을 잘 알고 있는 비즈니스 분석가에게 특별히 유용할 수 있는 많은 기능과 상호 운용성 옵션을 제공합니다. 이 옵션은 비즈니스 인텔리전스 도구를 사용하기를 원하고 빠른 대화형 쿼리가 필요한 사용자에게 유용합니다. 다양한 파일 형식, 동시성 및 ACID(원자성, 일관성, 격리, 영속성) 트랜잭션 지원과 같은 다른 이점이 있습니다. 데이터에 대한 세부적인 행 및 열 수준 제어를 위한 Apache Ranger와의 통합도 물론 포함됩니다.
참고
이 모듈의 내용은 Hive 3.1 및 LLAP(Hive LLAP라고도 함)를 사용하는 HDInsight 4.0용으로 만든 Interactive Query 클러스터와 관련이 있습니다.
쿼리할 준비가 된 큰 데이터 세트가 있습니다.
Interactive Query 클러스터는 있는 그대로 쿼리하거나 변환을 최소화하여 쿼리할 수 있는 큰 데이터 세트에 가장 적합합니다. 데이터에서 다양한 쿼리를 수행하고 즉각적인 응답이 필요한 상황입니다. Interactive Query 클러스터는 장기 실행 일괄 처리 계산을 수행하도록 최적화되지 않았습니다. 대화형 쿼리는 다음 파일 형식을 지원합니다. ORC, Parquet, CSV, Avro, JSON, 텍스트 및 tsv.
SQL 같은 기능이 필요함
Azure Storage 및 Azure Data Lake Storage에 있는 빅 데이터에서 대화형 및 임시 1초 미만 대기 시간 쿼리를 수행해야 하며 SQL 같은 환경을 선호하는 경우 Azure HDInsight Interactive Query 클러스터가 적합합니다. 비즈니스 분석가는 SQL 테이블 및 SQL을 사용하여 쿼리를 만드는 방법을 잘 알고 있습니다. Apache Hadoop은 빅 데이터 분석을 수행하기 위한 강력한 도구입니다. Java 프로그래밍 기술이 약간 서툰 경우에는 Apache Hadoop의 MapReduce 프레임워크 및 해당 Java API가 차단기가 될 수 있습니다. 이 경우 HDInsight Interactive Query는 Apache Hadoop을 기반으로 빌드될 때 더 적합하지만 SQL 환경을 소유한 모든 사용자가 더 간단하게 사용할 수 있습니다. Interactive Query는 SQL 같은 Hive 테이블을 사용하여 데이터를 처리하고 HiveQL이라는 SQL 같은 쿼리 언어를 사용하여 데이터를 쿼리합니다. Hive 사용은 Apache Hadoop에서 MapReduce를 사용하여 데이터를 처리하는 것 보다 덜 복잡합니다. Hive를 사용하면 더 빠르고 효율적으로 회사에 솔루션을 출시할 수 있습니다.
인텔리전트 캐싱을 사용한 빠른 대화형 쿼리
Interactive Query 클러스터는 인텔리전트 캐싱 기술을 사용하여 동적 RAM, 로컬 클러스터 노드 SSD 및 원격 스토리지 시스템(예: Azure Blob 및 Azure Data Lake Storage Blob)에서 데이터를 계층화하여 빅 데이터에 대한 대화형 및 빠른 쿼리 결과를 달성할 수 있습니다. 고급 캐싱 기술의 한 가지 좋은 예는 CSV 데이터를 즉시 최적화된 메모리 내 형식으로 변환하여 캐싱이 동적으로 수행되고 쿼리를 통해 캐시되는 데이터를 결정하는 동적 텍스트 캐시입니다. 이 기능은 먼저 데이터를 로드하고 변환할 필요가 없음을 의미합니다. 데이터를 원래 형식으로 Azure Storage에 업로드하고 쿼리를 시작할 수 있습니다. 또한 쿼리가 두 번째로 실행될 때 성능이 향상됨을 의미합니다. 쿼리가 처음 실행될 때 Azure Storage 또는 Azure Data Lake Gen2의 비즈니스 데이터 스토리지 계층에서 데이터를 읽습니다. 그런 다음, 데이터는 클러스터의 공유된 메모리 내 캐시에 캐시됩니다. 다음에 쿼리가 실행되면 데이터는 공유된 메모리 내 캐시에서 검색되며 원격 스토리지 레이어에서 데이터를 검색하지 않아 시간이 절약됩니다.
인기 있는 도구를 사용하여 쿼리 실행
대화형 쿼리를 사용하면 Microsoft Power BI 및 Tableau와 같이 잘 알고 있는 BI 도구를 통해 빅 데이터를 쉽게 사용할 수 있습니다. 빅 데이터 분석은 종종 너무 어렵고 분석을 실행하는 데 익숙하지 않고 배우기 어려운 도구를 사용해야 하기 때문에 조직은 최종 사용자가 분석 시스템에서 충분한 가치를 얻을 수 없다는 점을 점점 더 우려하고 있습니다. HDInsight Interactive Query는 데이터에서 인사이트를 얻는 데 필요한 새로운 사용자 학습을 최소화하거나 없도록 하여 이 문제를 해결합니다. 사용자는 이미 사용하는 도구에서 SQL 같은 HiveQL 쿼리를 작성할 수 있습니다. 이 도구에는 Visual Studio Code, Power BI, Apache Zeppelin, Visual Studio, Ambari Hive View, Beeline, Data Analytics Studio 및 Hive ODBC가 포함됩니다. Hive 콘솔, Templeton, Azure 클래식 CLI 또는 Azure PowerShell을 사용하여 Interactive Query 클러스터에서 쿼리를 수행할 수는 없습니다.
트랜잭션 일관성 및 동시성 필요
세분화된 리소스 관리, 선점 및 쿼리와 사용자 전체에서 캐시된 데이터 공유를 도입한 Interactive Query는 동시 사용자를 쉽게 지원할 수 있습니다. HDInsight는 공유 Azure Storage에 여러 클러스터를 만들 수 있도록 지원합니다. Hive 메타스토어는 높은 수준의 동시성을 달성하는 데 도움이 됩니다. 클러스터 노드를 추가하거나 동일한 기본 데이터 및 메타데이터를 가리키는 클러스터를 추가하여 동시성을 확장할 수 있습니다. Interactive Query는 ACID(원자성, 일관성, 격리, 영속성) 데이터베이스 트랜잭션도 지원합니다. ACID 트랜잭션을 사용하면 여러 작업이 포함된 경우에도 트랜잭션이 단일 단위로 포함됩니다. 따라서 트랜잭션의 단일 작업이 실패하는 경우 전체 작업이 롤백될 수 있으며 이 덕분에 데이터의 일관성과 정확성이 유지됩니다.
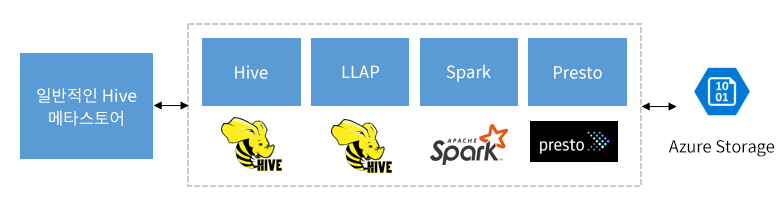
Spark, Hive, Presto 및 기타 빅 데이터 엔진을 보완할 수 있도록 빌드됨
HDInsight Interactive Query는 Apache Spark, Hive, Presto 등 널리 사용되는 빅 데이터 엔진에서 잘 작동하도록 디자인되었습니다. 사용자가 이 도구 중 하나를 선택하여 분석을 실행할 수 있기 때문에 이 유형의 쿼리가 특히 유용합니다. 사용자는 외부 테이블에 대한 HDInsight의 공유 데이터 및 메타데이터 아키텍처를 사용하여 동일하거나 서로 다른 엔진이 동일한 기본 데이터 및 메타데이터를 가리키는 여러 클러스터를 만들 수 있습니다. 더 이상 하나의 분석 기술로 제한되지 않으므로 이 기능은 강력한 개념입니다.