보조 클러스터에 데이터 복제
Kafka는 재해 복구, 고가용성 및 클라우드 하이브리드 시나리오에 대한 온-프레미스를 위해 여러 환경에 배포되는 경우가 많습니다. 이러한 시나리오에서는 Apache Kafka의 미러링 기능을 사용하여 하나의 Kafka 인스턴스에서 다른 인스턴스로 데이터를 복제해야 합니다. 미러링은 연속 프로세스로 실행되거나 한 클러스터에서 다른 클러스터로 데이터를 마이그레이션하는 방법으로 간헐적으로 사용될 수 있습니다.
미러링이 내결함성을 달성하는 수단으로 간주되어서는 안됩니다. 토픽 내의 항목에 대한 오프셋은 기본 및 보조 클러스터 간에 서로 다르므로 클라이언트에서는 이 두 가지를 서로 교환하여 사용할 수 없습니다.
미러링 작동 방식
미러링은 MirrorMaker 도구(Apache Kafka의 일부)를 사용하여 기본 클러스터의 토픽에서 레코드를 사용한 다음 보조 클러스터에 로컬 복사본을 만듭니다. MirrorMaker는 기본 클러스터에서 불러온 한 개 이상의 소비자와 로컬 보조 클러스터에 작성하는 프로듀서를 사용합니다.
재해 복구에 가장 유용한 미러링 설정은 여러 Azure 지역에서 Kafka 클러스터를 활용하는 것입니다. 이를 위해 클러스터가 있는 가상 네트워크는 함께 피어링됩니다.
다음 다이어그램에서는 미러링 프로세스와 클러스터 간 통신 흐름을 보여줍니다.
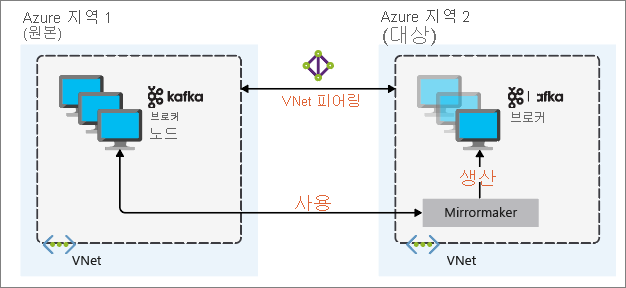
기본 및 보조 클러스터는 노드와 파티션 수에 따라 다를 수 있으며 토픽 내의 오프셋도 다릅니다. 미러링은 분할에 사용되는 키 값을 유지하므로 레코드 순서는 키 기준으로 유지됩니다.
네트워크 경계를 넘은 미러링
다른 네트워크의 Kafka 클러스터 간에 미러링해야 하는 경우 다음과 같은 추가 고려 사항이 있습니다.
- 게이트웨이: 네트워크는 TCP/IP 수준에서 통신할 수 있어야 합니다.
- 서버 주소 지정: IP 주소 또는 정규화된 도메인 이름을 사용하여 클러스터 노드의 주소를 지정하도록 선택할 수 있습니다.
- IP 주소: IP 주소 광고를 사용하도록 Kafka 클러스터를 구성하는 경우 broker 노드의 IP 주소 및 zookeeper 노드의 IP 주소를 사용하여 미러링 설정을 진행할 수 있습니다.
- 도메인 이름: IP 주소 광고에 대해 Kafka 클러스터를 구성하지 않으면 클러스터는 FQDN(정규화된 도메인 이름)을 사용하여 서로 연결할 수 있어야 합니다. 이렇게 하려면 요청을 다른 네트워크로 전달하도록 구성된 Domain Name System(DNS)서버가 각 네트워크에 필요할 수 있습니다. Azure Virtual Network를 만들 때 네트워크에서 제공되는 자동 DNS를 사용하는 대신 사용자 지정 DNS 서버와 해당 서버의 IP 주소를 지정해야 합니다. 가상 네트워크를 만든 후에는 해당 IP 주소를 사용하는 Azure Virtual Machine을 만든 다음 DNS 소프트웨어를 설치하고 구성해야 합니다.
경고
HDInsight를 Virtual Network에 설치하기 전에 사용자 지정 DNS 서버를 만들고 구성합니다. Virtual Network에 구성된 DNS 서버를 사용하기 위해 HDInsight를 추가로 구성할 필요는 없습니다.